
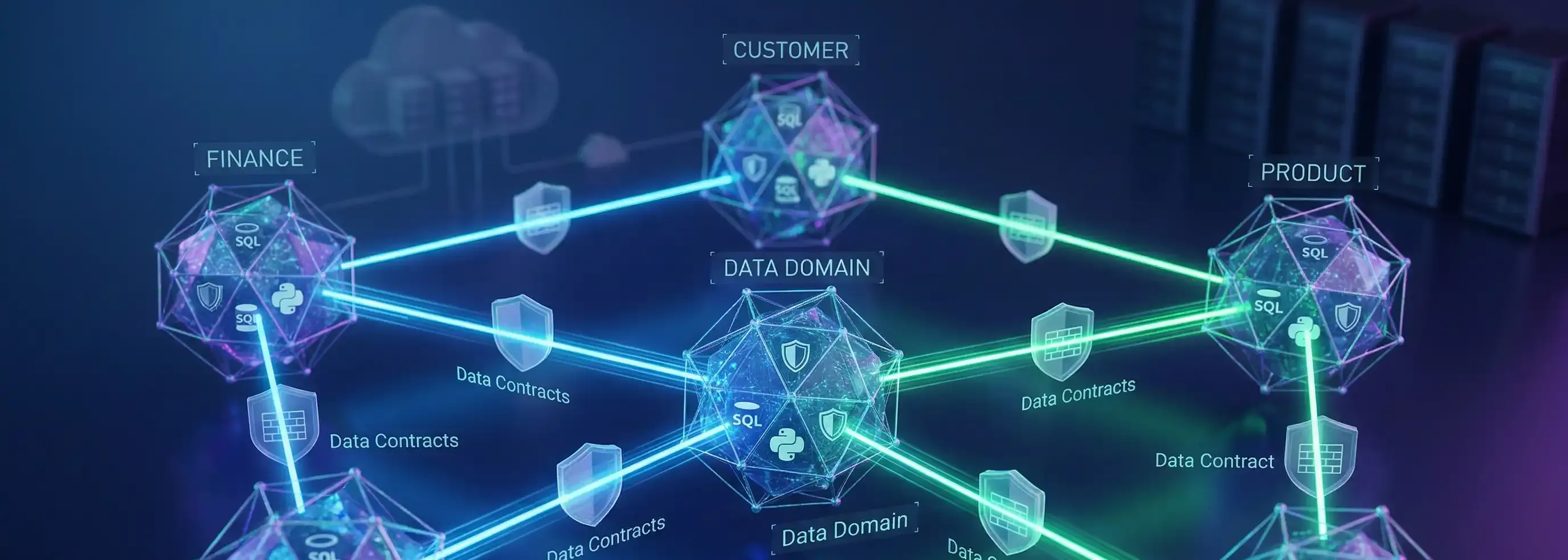

Arquitetura de Data Mesh para Governança de Dados Sensívei
Um estudo sobre como descentralizar a propriedade dos dados sem perder o controle de segurança, utilizando Python e contratos de dados automatizados.
Tags de Tecnologia:
#DataMesh #DataEngineering #DataGovernance #Python #DataSecurity #DataContracts #ZeroTrust #CloudComputing #ETL #Compliance
- Introdução: O Paradoxo da Escala de Dados
Na última década, a centralização de dados em Data Lakes e Data Warehouses monolíticos foram a norma. À medida que as organizações cresceram, esse modelo centralizado frequentemente se torna um gargalo operacional. Enquanto os proprietários de negócios (os "domínios") ficam desconectados da qualidade e da responsabilidade dos dados que geram, suas centrais de dados sofrem verdadeiras sobrecargas.
A Data Mesh, introduzida por Zhamak Dehghani, propõs a seguinte mudança: tratar os dados não como um subproduto de um processo, mas como um produto, cuja propriedade e governança devem ser descentralizadas para as equipes de domínio que melhor os conhecem (ex: Finanças, RH, Vendas) o que favoreceu na origem do big data.
Com o barateamento do armazenamento de dados, o problema se tornou a segurança deles. Como permitimos que a equipe de Finanças gerencie seus próprios dados sem comprometer a conformidade com a LGPD/GDPR, ou sem criar silos inacessíveis para o restante da empresa?
Este artigo propõe uma arquitetura de Data Mesh segura, onde a governança de dados sensíveis não é imposta por uma equipe central, mas automatizada e verificável no nível do pipeline, utilizando Python e Contratos de Dados Automatizados.
- O Desafio: Descentralização com Segurança (Zero-Trust)
Quando descentralizamos a propriedade, o risco de fragmentação e vulnerabilidade aumenta. Sem diretrizes claras, cada domínio pode adotar padrões de nomenclatura diferentes, níveis de criptografia incompatíveis ou, pior, falhar na identificação de Dados Pessoais Sensíveis (PII).
Para que o Data Mesh funcione, precisamos de um modelo de Governança Federada: as regras são globais (definidas centralmente), mas a execução é local (implementada pelo domínio). O objetivo é alcançar uma arquitetura Zero-Trust Data, onde o acesso não é presumido, mas concedido dinamicamente com base em políticas e contratos definidos.
- A Arquitetura Proposta: Data Mesh com "Computational Governance"
Nesta arquitetura, a governança deixa de ser um documento PDF e se torna código executável ("Computational Governance"). A peça-chave é o Contrato de Dados.
- O que é um Contrato de Dados Automatizado?
Um Contrato de Dados (Data Contract) é uma especificação formal, legível por máquina (frequentemente em YAML ou JSON), que define:
Esquema: Os nomes, tipos de dados e constraints das colunas.
Semântica: A descrição e o propósito de cada campo.
Segurança e Conformidade: Identificação de campos PII, níveis de classificação de segurança (ex: Público, Confidencial, Secreto) e as regras de mascaramento aplicáveis (ex: "Anonymize", "Hash").
SLAs de Dados: Garantias de atualização, completude e integridade.
Implementação Técnica: O Workflow Python
Para operacionalizar esses contratos, utilizamos o ecossistema Python, que é a linguagem de facto da engenharia de dados moderna. O workflow é dividido em três estágios principais dentro de cada pipeline de domínio.
1. Definição do Contrato (YAML)
Cada produto de dados (ex: finance.transactions_v1) possui um arquivo de contrato associado, mantido no repositório do domínio, mas validado por uma ferramenta de CI/CD global.
YAML
# finance_contract.yaml
dataset_id: finance.transactions_v1
owner: finance_team@company.com
schema:
- name: transaction_id
type: string
classification: public
- name: customer_id
type: string
classification: sensitive
PII_type: national_id
security_rule: hash_sha256 # Regra de mascaramento
- name: amount
type: decimal(10,2)
classification: public
constraint: "> 0"
status: active
2. Validação do Pipeline na Ingestão (Python)
Antes que os dados sensíveis sejam gravados no armazenamento persistente (ex: um S3 Bucket ou Google BigQuery) do domínio, o pipeline Python verifica se a carga de entrada corresponde ao esquema e às constraints definidas no contrato.
Utilizamos bibliotecas Python como Pydantic ou frameworks de validação como Great Expectations para automatizar esse processo.
Python
# Trecho de código conceitual (Python)
from data_contract_sdk import validate_contract_and_mask, load_contract
# 1. Carregar o contrato formal
contract = load_contract("finance_contract.yaml")
# 2. Ler os dados brutos (Raw/Bronze)
df_raw = spark.read.format("csv").load("s3://finance/raw/transactions/")
# 3. Aplicar a validação e o mascaramento computacional
# O SDK interno lê a regra 'hash_sha256' para 'customer_id' e aplica automaticamente.
df_secure = validate_contract_and_mask(df_raw, contract)
# 4. Gravar os dados seguros (Trusted/Silver)
df_secure.write.mode("append").saveAsTable("finance.transactions_v1")
3. Execução Automatizada da Política de Segurança
O pipeline Python não valida apenas o esquema; ele executa a segurança. Quando o contrato identifica uma coluna como sensível (PII_type: national_id), o pipeline utiliza uma biblioteca de segurança corporativa para aplicar a regra de mascaramento correspondente (ex: hashing SHA256 ou tokenização) antes da gravação.
Isso garante que os dados em repouso no armazenamento de domínio já estejam protegidos, reduzindo o risco de exposição acidental.
Governança Federada e Catálogo de Dados
Para que o restante da organização possa descobrir e consumir esses dados com segurança, utilizamos um Catálogo de Dados Centralizado (como o DataHub, Amundsen, ou GCP Dataplex).
Os pipelines de domínio, ao executarem com sucesso, publicam metadados no catálogo central.
Os metadados incluem o esquema validado e as tags de classificação de segurança extraídas diretamente do Contrato de Dados.
A equipe de segurança central monitora o catálogo para garantir que todos os domínios estejam publicando dados em conformidade.
Conclusão e Benefícios
Ao adotar uma arquitetura de Data Mesh federada com governança computacional baseada em Python e Contratos de Dados Automatizados, as organizações podem resolver o paradoxo da escala de dados.
Benefícios Chave:
Agilidade e Propriedade: As equipes de domínio têm autonomia para criar e iterar seus produtos de dados sem depender de uma fila de TI central.
Segurança Incorporada: A governança deixa de ser reativa e se torna preventiva, executada no nível do código em cada pipeline.
Conformidade Escalável: As regras de LGPD/GDPR são aplicadas consistentemente através de contratos padronizados, independentemente do volume de dados ou do número de equipes.
Transparência e Confiabilidade: Os consumidores de dados podem confiar na qualidade e na definição dos dados que descobrem no catálogo, pois o esquema é validado pelo contrato.
A descentralização não precisa significar caos. Com as ferramentas certas e uma abordagem de governança computacional, a Data Mesh fornece o framework para um ecossistema de dados verdadeiramente escalável e seguro.




