


Como criar projetos inteligentes com Python e IA : Analise de Reunião
Como criar projetos inteligentes com Python e IA
Sabe aquele momento em que você está numa reunião cheia de assuntos, recebe um monte de tarefas e ideias, e depois não lembra quase nada do que foi falado? Pois é, acontece com muita gente! Se você já passou por isso, esse artigo vai te ajudar. Vou te mostrar um jeito simples de criar um analisador de reuniões, que vai te livrar daquele aperto de ter que perguntar tudo de novo para alguém.
A primeira ideia que vem à cabeça é gravar a reunião, certo? Mas aí você pode pensar: “Ah, mas eu já faço isso! Se esquecer de algo, é só voltar no vídeo e procurar.” Só que, convenhamos, quem é que lembra o minuto exato em que aquela informação apareceu? E se foi lá no finalzinho, depois de quase uma hora? Fica difícil, né? Gravar ajuda, mas não resolve tudo.
A proposta de hoje é te ensinar a montar um modelo onde você só precisa enviar a gravação da reunião e a sua dúvida. O sistema vai te responder e ainda mostrar o trecho do vídeo onde a resposta aparece. Bem prático, né? Então, vamos nessa!
Tópicos
- 💡 Como faremos?
- 🛠️ Ferramentas utilizadas
- 🤖 Integração com múltiplos modelos
- 🌎 Aplicações no mundo real
- 👨💻 Colocando a mão na massa
- 📝 Explicação
- 🔗 Links importantes
- ✅ Conclusão
💡 Como faremos?
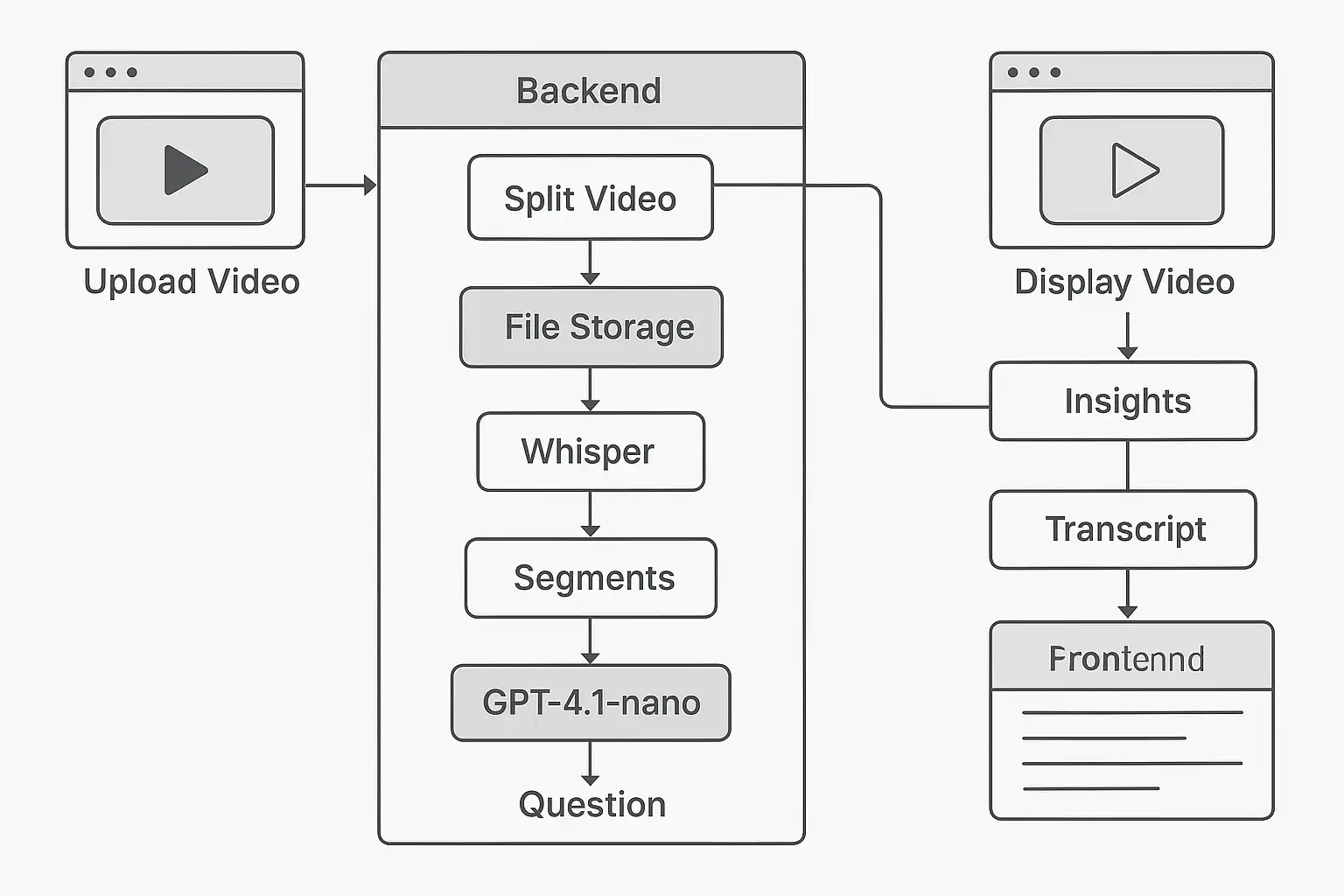
A ideia aqui é mostrar, de um jeito bem direto, como transformar qualquer gravação de reunião em um material fácil de consultar. Não queremos só transcrever o que foi falado, mas sim te dar a possibilidade de fazer perguntas específicas sobre o assunto e receber respostas certinhas, com a indicação de onde aquela informação aparece no vídeo. Para isso, vamos juntar técnicas de áudio e vídeo com inteligência artificial, criando um processo automático que vai desde o envio do vídeo até a criação de informações úteis e respostas com contexto.
Primeiro, você envia o vídeo da reunião. Depois, o sistema divide o arquivo em pedaços menores, para não passar do limite de 25mb da OpenAI, caso o vídeo seja muito grande. Isso garante que cada parte seja processada sem problemas. Cada pedaço é enviado para um sistema de transcrição, que transforma o áudio em texto e marca os momentos em que cada frase foi dita. Em seguida, todo esse texto é juntado e enviado para um modelo de linguagem, que consegue responder perguntas e fazer resumos, sempre mostrando os trechos do vídeo como referência. O resultado é uma ferramenta poderosa, que transforma horas de gravação em respostas rápidas e precisas, facilitando a vida de quem precisa revisar ou consultar informações importantes.
Neste artigo, você vai ver que, mesmo usando tecnologias avançadas, o projeto pode ser feito com poucas linhas de código e ferramentas que não custam caro. A ideia é mostrar que qualquer pessoa, mesmo sem saber muito sobre inteligência artificial, pode criar uma solução como essa e usar no dia a dia. Vamos juntos mostrar que a IA pode ser usada em tarefas comuns e como ela pode ajudar na organização e produtividade.
🛠️ Ferramentas utilizadas
Para construir nosso analisador de reuniões inteligente, vamos utilizar um conjunto de ferramentas, que se complementam. entre as bibliotecas utilizadas,
- Flask: que é responsável por criar a interface web do nosso sistema, permitindo que qualquer pessoa possa acessar a aplicação pelo navegador, sem precisar instalar nada.
- Werkzeug: que garante que os arquivos sejam salvos de forma segura.
- Ffmpeg: uma ferramenta poderosa para manipulação de áudio e vídeo. Com ela, conseguimos dividir vídeos grandes em partes menores, facilitando o processamento e evitando erros de limite de tamanho.
Para a transcrição do áudio, utilizamos a API Whisper da OpenAI, que é capaz de converter fala em texto com alta precisão, além de identificar os momentos em que cada frase foi dita. Isso é essencial para que possamos referenciar os trechos do vídeo nas respostas. Por fim, para gerar os insights e responder às perguntas, usamos o modelo de linguagem GPT-4.1-nano, também da OpenAI, que entende o contexto da reunião e produz respostas claras, citando os timestamps relevantes.
Com esse conjunto de ferramentas, conseguimos criar uma solução robusta, escalável e fácil de usar, que pode ser adaptada para diferentes necessidades e cenários.
🤖 Integração com múltiplos modelos
O que torna esse projeto especial é justamente a integração de vários modelos de inteligência artificial, cada um focado em uma tarefa diferente. Em vez de apostar tudo em uma única solução para todo o processo, a ideia é juntar o que cada tecnologia tem de melhor em cada etapa, garantindo resultados mais certeiros. Esse jeito modular de montar o sistema também facilita muito caso você queira trocar ou atualizar alguma parte, seja porque surgiu uma novidade ou porque suas necessidades mudaram.
O primeiro modelo que entra em ação é o Whisper, da OpenAI, que faz a transcrição do áudio do vídeo. Ele foi treinado para entender diferentes idiomas, sotaques e até ruídos de fundo, então funciona bem para reuniões gravadas em ambientes variados. Além de transformar a fala em texto, o Whisper ainda informa o tempo de início e fim de cada trecho, o que é essencial para conseguir apontar exatamente onde aquela informação aparece no vídeo.
Depois que a transcrição está pronta, entra o modelo de linguagem GPT-4.1-nano, também da OpenAI. Ele entende perguntas feitas em linguagem natural, analisa o conteúdo da transcrição e gera respostas detalhadas, sempre mostrando em que momento do vídeo aquela informação foi dita. Essa combinação de modelos faz com que o sistema vá muito além de só transcrever, oferecendo uma experiência interativa e personalizada para quem usa.
Outro ponto legal é que a arquitetura do projeto já foi pensada para aceitar outros modelos no futuro. Dá para melhorar a transcrição, incluir tradução automática, ou até analisar sentimentos e emoções presentes na reunião. Essa flexibilidade é um dos grandes trunfos da solução, porque ela pode evoluir junto com as novidades do mercado e as necessidades de quem usa.
🌎 Aplicações no mundo real
O legal dessa solução é que ela não serve só para reuniões de trabalho. Dá para usar em várias situações do dia a dia, trazendo vantagens para profissionais de áreas bem diferentes. Por exemplo, professores podem gravar as aulas e oferecer transcrições automáticas para os alunos, o que facilita a revisão do conteúdo e ainda ajuda quem tem deficiência auditiva. Advogados podem analisar audiências e depoimentos, achando rapidinho os trechos que interessam para cada caso. Jornalistas também ganham tempo ao transcrever entrevistas longas e buscar informações específicas sem precisar ouvir tudo de novo.
No atendimento ao cliente, as empresas podem gravar ligações e usar o sistema para encontrar rapidamente reclamações, elogios ou pedidos importantes, melhorando o serviço. Em universidades, pesquisadores podem analisar grupos focais, seminários e defesas de tese, tirando insights valiosos de horas de gravação. Até em situações pessoais, como palestras, workshops ou eventos de família, a ferramenta pode ajudar a registrar e consultar informações importantes.
Outro ponto bacana é que dá para integrar essa solução com outras plataformas, como sistemas de gestão de projetos, agendas eletrônicas e aplicativos de mensagens. Assim, tudo o que for extraído das reuniões pode ser organizado, compartilhado e usado para tomar decisões, aumentando a produtividade e evitando esquecimentos ou retrabalho. No fim das contas, as possibilidades de uso são quase infinitas, e a ferramenta pode ser adaptada para qualquer pessoa ou empresa que precise lidar com muitos áudios ou vídeos.
👨💻 Colocando a mão na massa
Agora que você já entendeu o conceito e as ferramentas envolvidas, é hora de colocar a mão na massa e construir o seu próprio analisador de reuniões. O primeiro passo é garantir que você tenha o Python instalado em seu computador, além das bibliotecas necessárias.
requirements.txt
blinker==1.9.0
certifi==2025.4.26
charset-normalizer==3.4.2
click==8.2.0
colorama==0.4.6
dotenv==0.9.9
ffmpeg-python==0.2.0
Flask==3.1.1
future==1.0.0
idna==3.10
itsdangerous==2.2.0
Jinja2==3.1.6
MarkupSafe==3.0.2
python-dotenv==1.1.0
requests==2.32.3
urllib3==2.4.0
Werkzeug==3.1.3
Seguindo o seguinte comando.
(venv) pip install -r ./requirements.txt
Com o ambiente preparado, você pode criar a estrutura do projeto, organizando os arquivos em pastas como uploads (para armazenar os vídeos) e incluindo o arquivo .env com suas chaves de acesso à OpenAI. seguindo a seguinte estrutura
C:.
│ .env
│ app.py
│ requirements.txt
│
├───templates
│ index.html
│
└───uploads
No frontend, você pode utilizar HTML, CSS e JavaScript para criar uma interface amigável, permitindo que o usuário faça upload do vídeo, visualize o player, acompanhe o progresso da análise e consulte os insights e a transcrição gerados automaticamente. Devido ao tamanho do codigo httml + css irei disponibilizalo no GitHub para poderem analisar.
Começando pelo basico vamos fazer as importações necessarias.
import os
import math
from flask import Flask, request, jsonify, render_template, send_from_directory
import requests
from dotenv import load_dotenv
from werkzeug.utils import secure_filename
import ffmpeg
Com as importações feitas, vamos fazer as configurações inicias do nosso ambiente.
load_dotenv()
app = Flask(__name__)
app.secret_key = os.getenv('SECRET_KEY', 'segredo')
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
UPLOAD_FOLDER = 'uploads'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
MAX_FILE_SIZE_MB = 25
Com isso podemos começar a criar nossas rotas. A primeira sendo nossa pagina inicial onde iremos interagir com tudo.
@app.route('/')
def home():
return render_template('index.html')
De forma bem simples, ele vai procurar nos seus arquivos a pasta 'templates' e dela procurar e reenderizar nosso index.
Agora para podemos começar a utilizar, precisamos do video para enviarmos para nossa IA.
@app.route('/upload', methods=['POST'])
def upload():
if 'file' not in request.files:
return jsonify({'success': False, 'error': 'Nenhum arquivo enviado.'}), 400
file = request.files['file']
if file.filename == '':
return jsonify({'success': False, 'error': 'Nome de arquivo vazio.'}), 400
filename = secure_filename(file.filename)
file_path = os.path.join(UPLOAD_FOLDER, filename)
file.save(file_path)
return jsonify({'success': True, 'filename': filename, 'file_path': file_path})
E com o video armazenado podemos cortalo em quantos pedaços forem necessario para enviar para a OpenAI transcrever
def split_video_ffmpeg(input_path, max_size_mb=25):
file_size = os.path.getsize(input_path)
max_size = max_size_mb * 1024 * 1024
if file_size <= max_size:
return [input_path]
probe = ffmpeg.probe(input_path)
duration = float(probe['format']['duration'])
num_parts = math.ceil(file_size / max_size)
part_duration = duration / num_parts
part_paths = []
for i in range(num_parts):
start = i * part_duration
output_path = f"{input_path}_part{i+1}.mp4"
(
ffmpeg
.input(input_path, ss=start, t=part_duration)
.output(output_path, c='copy')
.run(overwrite_output=True, quiet=True)
)
part_paths.append(output_path)
return part_paths
Agora vamos enviar para a OpenIA nos retornar a transcrição da nossa reuniao.
def transcribe_with_openai(video_path):
url = "https://api.openai.com/v1/audio/transcriptions"
headers = {"Authorization": f"Bearer {OPENAI_API_KEY}"}
files = {"file": open(video_path, "rb")}
data = {
"model": "whisper-1",
"response_format": "verbose_json"
}
response = requests.post(url, headers=headers, files=files, data=data, timeout=120)
response.raise_for_status()
return response.json()
Apos enviarmos iremos receber varios pedaços da nossa transcrição, então para facilitar vamos junta-los novamente para ficar em juntos e em ordem.
def transcribe_large_video(video_path):
part_paths = split_video_ffmpeg(video_path)
all_segments = []
time_offset = 0.0
for part_path in part_paths:
result = transcribe_with_openai(part_path)
segments = result.get("segments", [])
for seg in segments:
seg_copy = seg.copy()
seg_copy["start"] += time_offset
seg_copy["end"] += time_offset
all_segments.append(seg_copy)
if segments:
time_offset = all_segments[-1]["end"]
if part_path != video_path:
os.remove(part_path)
return all_segments
Com toda a transcrição em maos, podemos gerar nosso pronpt que vai usar o a transcrição como fonte e sempre nos retornar o momento onde isso foi feito.
def ask_openai(segments, question):
transcript_with_times = "\n".join(
f"[{seg['start']:.2f}-{seg['end']:.2f}] {seg['text']}" for seg in segments
)
if question:
prompt = (
"Abaixo está a transcrição de um vídeo, com timestamps. "
"Ao responder, sempre que possível, cite o(s) timestamp(s) relevante(s) entre colchetes. "
f"\n\nTranscrição:\n{transcript_with_times}\n\nPergunta: {question}"
)
else:
prompt = (
"Abaixo está a transcrição de um vídeo, com timestamps. "
"Resuma os principais pontos do vídeo, citando os timestamps relevantes."
f"\n\nTranscrição:\n{transcript_with_times}"
)
url = "https://api.openai.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {OPENAI_API_KEY}",
"Content-Type": "application/json"
}
data = {
"model": "gpt-4.1-nano",
"messages": [
{"role": "system", "content": "Você é um assistente que responde perguntas sobre a transcrição de um vídeo, sempre citando os timestamps relevantes."},
{"role": "user", "content": prompt}
]
}
try:
response = requests.post(url, headers=headers, json=data, timeout=60)
response.raise_for_status()
return response.json()["choices"][0]["message"]["content"]
except Exception as e:
print("Erro ao chamar OpenAI:", e)
return "Erro ao processar a pergunta ou gerar insights."
Agora vamos criar a função que vai unir tudo que fizemos até agora e enviar para a OpenIA e retorna em um formato simples que possa ser visualisado na WEB.
@app.route('/analyze', methods=['POST'])
def analyze():
data = request.get_json()
file_path = data.get('file_path')
question = data.get('question', '').strip()
if not file_path or not os.path.exists(file_path):
return jsonify({'success': False, 'error': 'Arquivo de vídeo não encontrado.'}), 400
segments = transcribe_large_video(file_path)
insights = ask_openai(segments, question)
return jsonify({
'success': True,
'insights': insights,
'transcription': segments,
'timestamps': []
})
e para rodarmos pasta finalizar o codigo com.
app.run()
No terminal iremos dar o sequinte comando e acessar nossa pagina local: 127.0.0.1:5000
python app.py
E pronto nosso analisador de reuniao esta pronto para ser usado.

Enviando nosso video ele vai nos retorna o insight da pergunta e sua transcrição caso necessario.


📝 Explicação
Vamos detalhar o funcionamento do sistema, para que você entenda cada etapa do processo. Tudo começa quando o usuário acessa a página principal da aplicação e faz o upload de um vídeo de reunião. O backend recebe esse arquivo e o armazena em uma pasta específica. Se o vídeo for muito grande, ele é automaticamente dividido em partes menores usando o ffmpeg, garantindo que cada pedaço possa ser processado pela API da OpenAI sem ultrapassar o limite de tamanho.
Em seguida, cada parte do vídeo é enviada para o modelo Whisper, que transcreve o áudio e retorna uma lista de segmentos, cada um com o texto falado e o tempo em que foi dito. O sistema então ajusta os tempos de cada segmento para garantir que a transcrição final esteja sincronizada com o vídeo original. Depois de juntar todos os segmentos, o texto completo é enviado para o modelo GPT-4.1-nano, junto com a pergunta do usuário. O modelo analisa o conteúdo, gera uma resposta detalhada e cita os trechos do vídeo como referência.
Por fim, o frontend exibe o vídeo, os insights gerados e a transcrição completa, permitindo que o usuário clique nos timestamps para ir diretamente ao momento desejado no vídeo. Todo o processo é automatizado e transparente para o usuário, que só precisa fazer o upload do vídeo e aguardar alguns minutos para receber as informações organizadas e fáceis de consultar. Esse fluxo garante praticidade, precisão e economia de tempo, tornando a revisão de reuniões muito mais eficiente.
🔗 Links importantes
Para facilitar sua jornada, separei alguns links essenciais que vão te ajudar a entender melhor as ferramentas utilizadas e a aprofundar seus conhecimentos:
- Documentação do Flask
- Site oficial do ffmpeg
- API Whisper da OpenAI
- API GPT da OpenAI
- Python-dotenv
- Werkzeug Secure Filename
- Diretório
✅ Conclusão
E chegamos ao fim deste artigo! Espero que você tenha visto como dá para transformar uma simples gravação de reunião em um material super útil, usando ferramentas modernas e que cabem no bolso. Com a combinação de Python, Flask, ffmpeg e os modelos da OpenAI, criamos uma solução que transcreve, analisa e responde perguntas sobre qualquer vídeo, sempre mostrando o momento exato em que cada informação foi dita.
Mais do que uma aplicação técnica, esse projeto mostra como a inteligência artificial pode ser usada no dia a dia para resolver problemas reais, aumentar a produtividade e facilitar a vida de profissionais de todas as áreas. O segredo é entender como as informações fluem, escolher as ferramentas certas e juntar tudo de um jeito que funcione bem. Com um pouco de dedicação e curiosidade, você pode adaptar e melhorar essa solução para atender às suas necessidades, se tornando cada vez mais independente e inovador.
Deixe seu Upvote e seu comentario sobre aque achou desse artigo.





Resp: Dio Community
Incrivelmente foi fazer a IA sempre trazer o timestamp junto com as respostas, antes só viam o insight sem nada e quando viam o time viam em formato diferente kkkkkk
Depois de testar vários pronpts conseguir achar um que retornava sempre no mesmo padrão
Excelente artigo, Lucas! Você conseguiu explicar de forma clara e prática como desenvolver um analisador inteligente de reuniões usando Python e IA, integrando ferramentas como Flask, ffmpeg e os modelos da OpenAI Whisper e GPT-4.1-nano. A descrição detalhada do fluxo, desde o upload do vídeo, passando pela divisão em partes menores, transcrição, até a geração de respostas contextuais com timestamps, torna o processo acessível e inspirador para quem deseja automatizar tarefas reais.
Na DIO, valorizamos muito projetos que aplicam IA para aumentar a produtividade e simplificar processos cotidianos, e sua solução é um exemplo perfeito disso.
Quais foram os maiores desafios técnicos que você enfrentou ao lidar com a sincronização dos timestamps e a divisão do vídeo?
Excelente artigo!