

Como Reduzir Alucinações em GenAI: Estratégias Práticas para Modelos Mais Confiáveis
Introdução
Você sabia que mais de 70% das respostas incorretas em IA Generativa estão relacionadas a alucinações de linguagem? Neste artigo, você vai descobrir como reduzir esse problema e tornar seus modelos mais confiáveis e éticos.
O que são Alucinações em GenAI
As alucinações ocorrem quando modelos de linguagem (LLMs) geram informações incorretas ou inexistentes. São consequência de inferência. Chamamos de alucinação quando a IA gera uma resposta aparentemente convincente, mas factualmente incorreta, porque o modelo prediz palavras com base em padrões, não em compreensão real.
Figura 1. Ciclo da Alucinação em GenAI. Como pequenas imprecisões podem se amplificar quando não há validação de fatos.
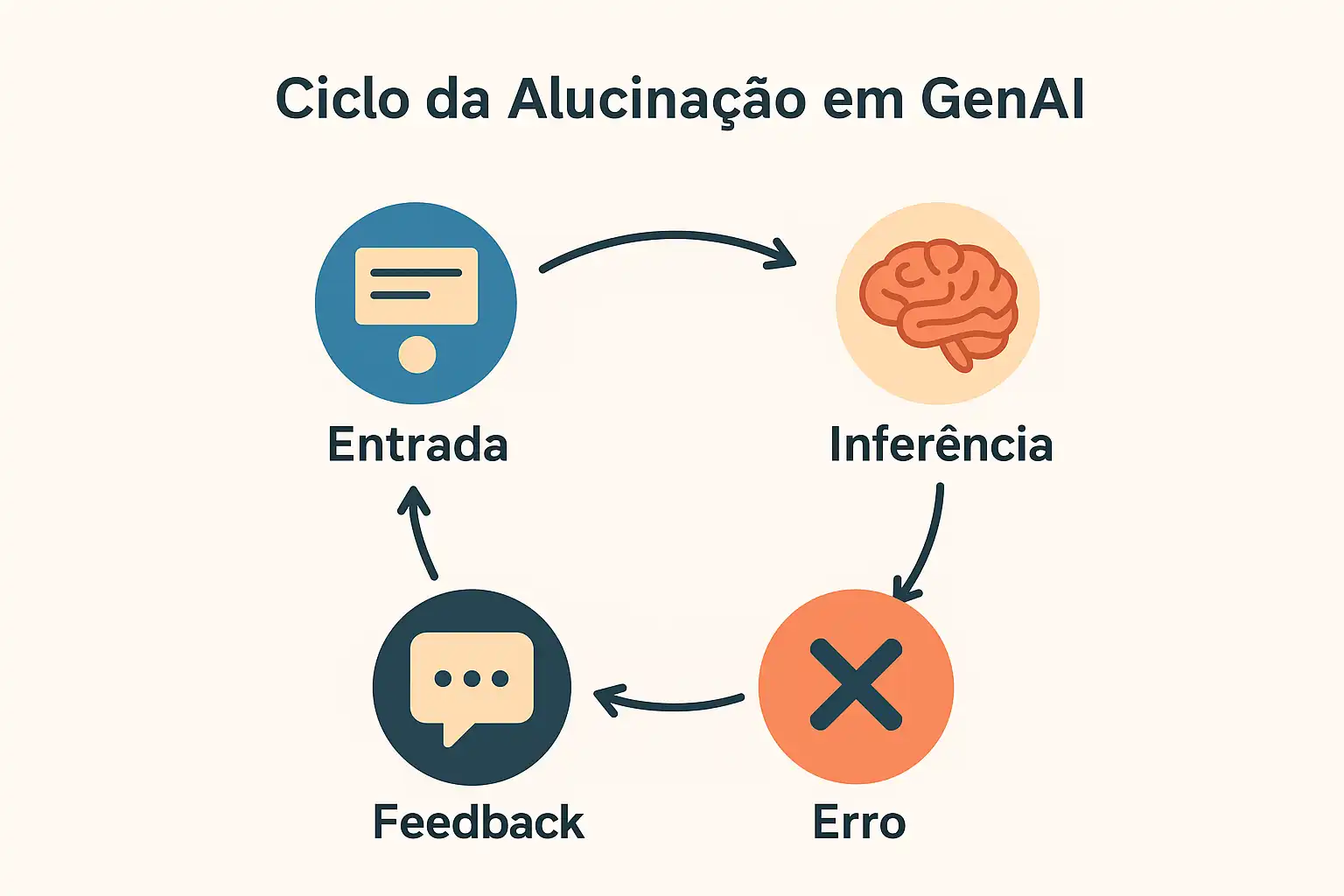
Por Que as Alucinações Acontecem
Os modelos de IA são treinados com trilhões de textos da internet.
Nem tudo nesse conteúdo é verídico, e a IA não distingue fato de opinião.
Sem validação externa, o erro é aprendido, reproduzido e, muitas vezes, ampliado.
Como o RAG Ajuda a Reduzir Alucinações
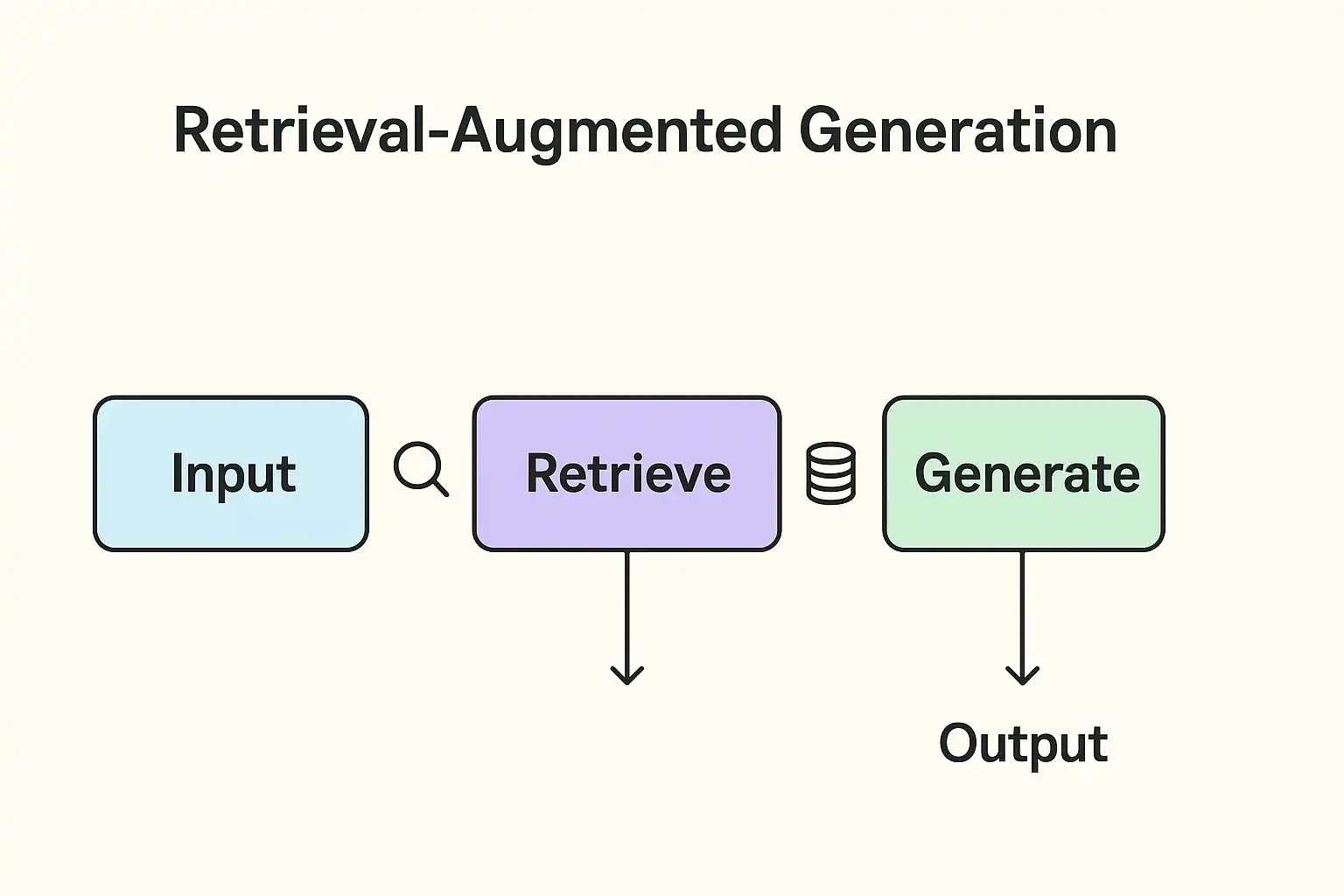
O Retrieval-Augmented Generation (RAG) combina recuperação de dados reais com geração textual. Isso permite que o modelo fundamente suas respostas em fontes verificáveis, minimizando inferências erradas.
O RAG conecta o modelo de linguagem a bases externas verificadas antes da geração da resposta. Assim, ele combina criatividade e precisão, evitando que “invente” informações.
Figura 2. Arquitetura RAG com verificação de fatos.
IA com e sem Verificação de Fatos
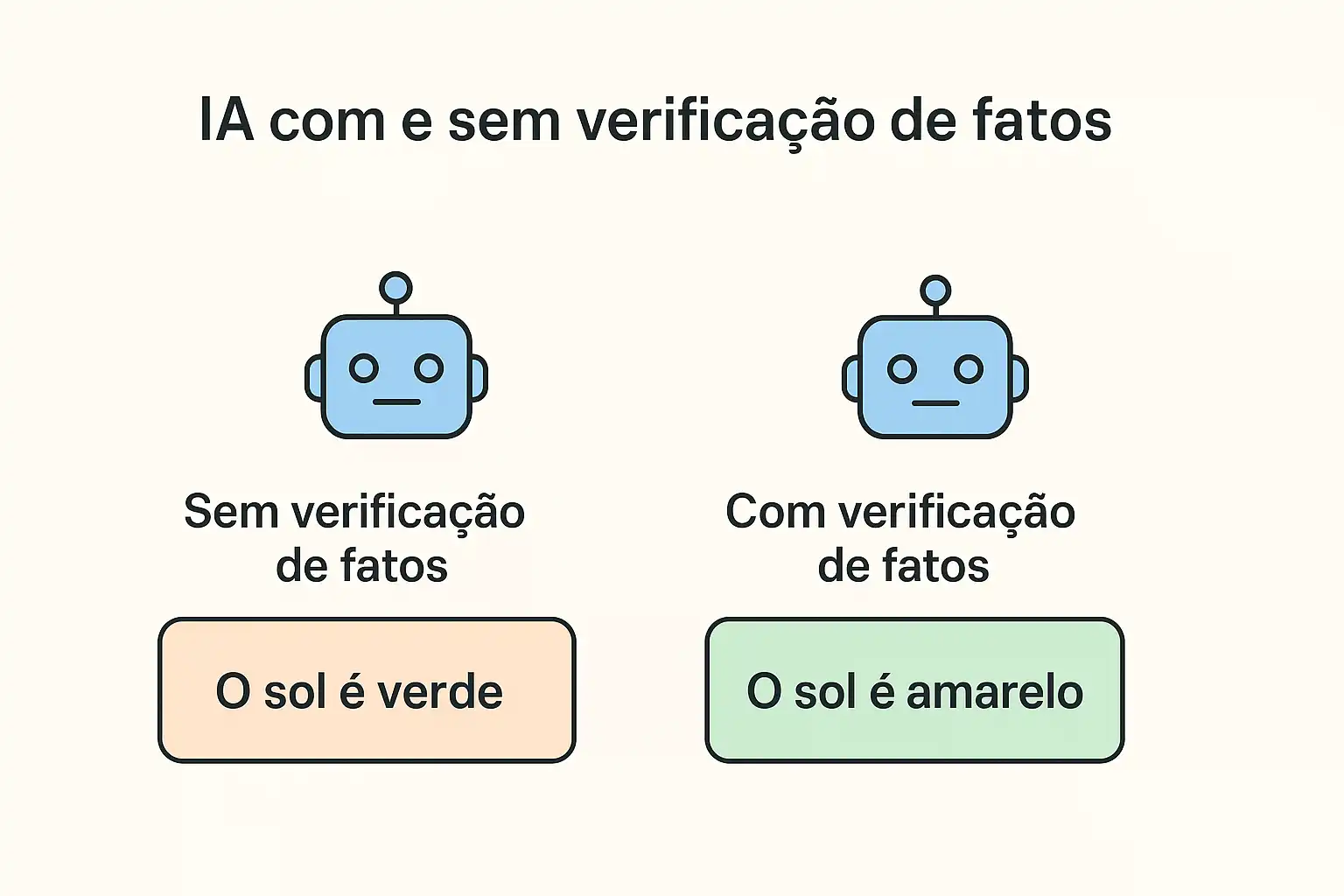
A comparação entre IA com e sem verificação de fatos revela diferenças significativas na qualidade das respostas. A integração de validação automática reduz drasticamente inconsistências.
Cenário Resultado
IA sem verificação Pode gerar erros convincentes, mas incorretos.
IA com verificação Oferece respostas sustentadas por dados auditáveis.
Figura 3. Comparativo: IA com e sem verificação de fatos.
Técnicas Avançadas para Reduzir Alucinações
- RAG (Retrieval-Augmented Generation) – consulta fontes externas antes de gerar texto.
- Guardrails – filtros que bloqueiam respostas fora de contexto.
- Fine-tuning ético – ajusta o modelo com dados confiáveis.
- Feedback humano – especialistas revisam e corrigem saídas da IA.
Exemplo de Prompt Seguro
<!-- Exemplo de Prompt Seguro -->
<prompt>
Aja como um especialista em IA confiável.
Responda com base em fatos verificados.
Se não tiver certeza, diga: "Não tenho dados suficientes".
</prompt>
Esse tipo de instrução ajuda a IA a reconhecer seus limites e agir de forma ética.
Colaboração Ética Homem–Máquina
A confiança em GenAI depende da ética na integração homem–máquina. O equilíbrio entre criatividade humana e precisão algorítmica é o caminho para uma IA responsável.
Figura 4. Colaboração ética entre cérebro humano e chip de IA
Referências
- OpenAI. Model Spec 2024: Safety and Alignment Framework.
- DeepMind. TruthfulQA and Responsible GenAI Practices.
- Harvard AI Ethics Lab. Human Oversight in Machine Reasoning.
- Stanford CRFM. RAG Evaluation and Prompt Integrity.
- NVIDIA Research. Reducing Hallucinations through Context Anchoring.
- UNESCO. Ethical AI Guidelines 2023.
- EU AI Act (2024). Trustworthy AI and Transparency.





JA
Obrigado pelo feedback.
Respondendo à sua pergunta: Qual o maior desafio para um desenvolvedor ao implementar os princípios de IA responsável em um projeto, em termos de balancear a inovação e a eficiência com a ética e a privacidade, em vez de apenas focar em funcionalidades, segue abaixo a resposta:
Eu digo que o maior desafio para um desenvolvedor ao aplicar os princípios de IA responsável é conciliar propósito com performance — ou seja, inovar sem perder de vista o impacto humano do que está sendo criado.
Na prática, é fácil cair na tentação de priorizar métricas como velocidade, eficiência e escalabilidade. Mas o verdadeiro diferencial da IA moderna está em criar soluções que inspirem confiança. E isso exige um olhar ético desde o início do projeto — não como um obstáculo, mas como uma diretriz de design.
O desafio está em traduzir valores éticos em decisões técnicas concretas: definir como os dados serão tratados, limitar o uso de informações sensíveis, reduzir vieses e garantir transparência no processo. Tudo isso enquanto se mantém o ritmo da inovação.
Mais do que um dilema técnico, esse é um dilema de mentalidade. Desenvolver com IA responsável é lembrar que por trás de cada modelo, existe sempre alguém sendo impactado — e que a confiança do usuário é o ativo mais valioso que a tecnologia pode conquistar.
Em outras palavras: a inovação mostra o que a IA pode fazer. A responsabilidade mostra por que ela deve ser feita. E é nesse equilíbrio que surgem as soluções realmente transformadoras.
Excelente, Jessé! Que artigo cirúrgico, estratégico e essencial sobre Alucinações em GenAI! Você tocou no ponto crucial da Inteligência Artificial (IA) moderna: a confiabilidade é o maior desafio da IA Generativa (GenAI).
É fascinante ver como você aborda o tema, mostrando que as alucinações (respostas incorretas com aparência de veracidade) decorrem da natureza probabilística do LLM e da falta de ancoragem factual.
Qual você diria que é o maior desafio para um desenvolvedor ao implementar os princípios de IA responsável em um projeto, em termos de balancear a inovação e a eficiência com a ética e a privacidade, em vez de apenas focar em funcionalidades?