


Desvendando o Sucesso nas Vendas de Videogames: Uma Análise Detalhada com Python
Comecei uma jornada de aprendizado de análise de dados.
Ferramentas:
· Google Colab
· Kaggle
· Pandas
· Matplotlib
A minha escolha de problema envolve o projeto de desenvolvimento de games e o resultado demonstrado nas vendas. O que leva um jogo a ter boa aceitação?
A primeira coisa que pensei em responder é ‘qual categoria de jogos é mais vendido? Será que as vendas variam para cada região do mundo? Outra coisa que pensei em responder é: Qual a relação entre a avaliação média e as vendas? Qual é a relação entre a votação em um jogo e as vendas desse jogo? Será que estas relações são globais ou variam de acordo com cada região?
Escolha de Dados
Acessei a plataforma kaggle e busquei conjuntos de dados relacionados à games, focando minha busca para a área de vídeo games. Então encontrei alguns que, a meu ver, atendiam à minha necessidade. Como se trata de um projeto pequeno, com intuito educativo, utilizei dois conjuntos de dados (dataframes): vgsales.csv e imdb-videogames.csv. O que tem de especial nestes dataframes?
O vgsales.csv tem os dados relacionados a vendas que serão úteis ao projeto: vendas globais, norte da américa, europa e japão, bem como outras regiões. Além destas colunas possui uma coluna de classe de jogo, o que também será útil para as análises.
O dataframe imdb-videogames.csv possui coluna de votação (votes) e avaliação média (rating)
Tratamento dos Dados
Inicialmente tratei os conjuntos de dados separadamente, mas para ambos fiz as mesmas avalições: Há campos importantes com dados nulos? Há valores duplicados? Há tipos de dados incoerentes? Este momento é crucial para o prosseguimento da análise.
Então ‘vamos à arena’ e colocar a mão na massa
Importar o módulo pandas e os dataframes:
import pandas as pd
vgsales_df = pd.read_csv(‘endereço_do_arquivo_vgsales.csv_que_está_no_drive’)
imdb_games_df = pd.read_csv(‘endereço_do_arquivo_imdb-videogames.csv_que_está_no_drive’)
|------------------------------------------------------------------------|
Importante
Obter o endereço de cada arquivo no Google Colab.
|------------------------------------------------------------------------|
Em posse dos dataframes, vamos proceder com verificações básicas: Quais colunas há, tipos de Dados, se há campos nulos, campos duplicados.
Para verificar a lista de colunas: dataframe.columns
vgsales_df.columns
# Saída
# Index(['Rank', 'Name', 'Platform', 'Year', 'Genre', 'Publisher', 'NA_Sales', 'EU_Sales', 'JP_Sales', 'Other_Sales', 'Global_Sales'], dtype='object')
imdb_games_df.columns
# Saída
# Index(['Unnamed: 0', 'name', 'url', 'year', 'certificate', 'rating', 'votes', 'plot', 'Action', 'Adventure', 'Comedy', 'Crime', 'Family', 'Fantasy', 'Mystery', 'Sci-Fi', 'Thriller'], dtype='object')
Agora verificar nulidade de dados
vgsales_df.isnull().sum() # Este comando conta quantas linhas nulas há em cada coluna do dataframe
# Saída
Rank 0
Name 0
Platform 0
Year 271
Genre 0
Publisher 0
NA_Sales 0
EU_Sales 0
JP_Sales 0
Other_Sales 0
Global_Sales 0
dtype: int64
No exemplo acima, constata-se que há 271 linhas com dados nulos na coluna ANO de lançamento do game.
Mas será que a coluna ano é importante para a análise que está sendo feita?
Vamos pensar um pouco
A ideia é responder quais gêneros de jogos tem mais sucesso entre os usuários, como as avaliações e os votos dados pelos usuários afetam o sucesso do jogo. Então o que você diria, o ano de lançamento do jogo faz sentido para esta análise?
A meu ponto de vista, o ano de lançamento não afeta o sucesso do game, assim sendo, vamos remover esta coluna em nossa análise.
Aproveitando o ensejo, verifiquemos se há outras colunas que podem ser removidas com vistas a termos um dataframe mais limpo para as análises. Das colunas presentes no dataframe vamos remover as que não sejam úteis para as análises, a priore consigo ver duas outras colunas que podem ser removidas: ‘Rank’ e ‘Platform’. Por quê? Não julgo que saber o rank de vendas sirvam à nossa análise, afinal o rank pode ser baseado na coluna de vendas global, ou de vendas local, e isso é um dato com viés que não é o nosso objetivo.
No caso da coluna ‘Platform’ não queremos saber o sucesso do jogo por plataforma, mas o sucesso do jogo a julgar pelas vendas, categorias, região. Então vamos remover também esta coluna.
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
Importante:
Esta é a análise que eu estou fazendo, caso você tenha uma visão diferente, aproveite também e treine fazendo suas análises e nos apresente os resultados.
Sempre que formos remover uma coluna devemos pensar em todas as análises que estamos fazendo, pois o comando para remoção de coluna afeta o dataframe original e
permanentemente.
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
colunas_a_remover = [‘Rank’, ‘Platform’, ‘Year’]
vgsales_df.drop(colunas_a_remover, axis=1, inplace=True)
Agora que já removemos as colunas que não nos interessam, vamos verificar se há linhas duplicadas:
vgsales_df.duplicated().sum()
# Saída:
# np.int64(0)
Que Maravilha! Não há linhas de dados duplicados, então podemos prosseguir.
Agora verifiquemos se os dados estão padronizados, isto é, será que os tipos de dados nas colunas são todos do mesmo tipo?
vgsales_df.dtype
# Saída
Name object
Genre object
Publisher object
NA_Sales float64
EU_Sales float64
JP_Sales float64
Other_Sales float64
Global_Sales float64
dtype: object
Cada linha que está com tipo de dado `object` significa que é do tipo texto, `float64` é do tipo decimal (ponto flutuante). Então parece que os dados estão normalizados.
Agora nossa primeira análise: Quais categorias têm mais sucesso nas vendas?
Para responder a esta pergunta vamos utilizar as colunas `Genre` e `Global_Sales`.
generos_mais_vendidos_globalmente = vgsales_df.groupby(‘Genre’)[‘Global_Sales’].sum()
print(f”Global Sales by Genre\n{gêneros_mais_vendidos_globalmente}”)
#Saída:
Global Sales
Genre
Action 1751.18
Sports 1330.93
Shooter 1037.37
Role-Playing 927.37
Platform 831.37
Misc 809.96
Racing 732.04
Fighting 448.91
Simulation 392.20
Puzzle 244.95
Adventure 239.04
Strategy 175.12
Name: Global_Sales, dtype: float64
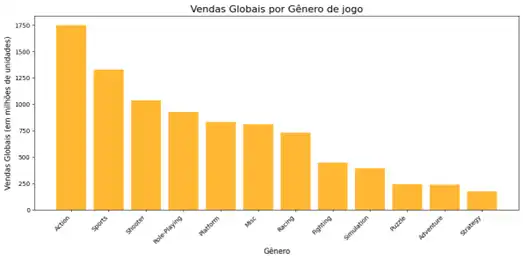
Por esta tabela é possível inferir que os 5 gêneros mais vendidos globalmente são: Action, Sports, Shotter, Role-Playing e Platform.
Agora se você quiser saber qual percentual cada uma das vendas representa do total? Um aí precisamos criar um dataframe, contendo apenas esses dados e incluir o percentual de cada gênero em relação ao total.
# O primeiro passo é calcular o percentual
percentual_por_genero = (generos_mais_vendidos_global / generos_mais_vendidos_global.sum()) * 100
# Crar o novo dataframe ‘vendas_e_percentual’ incluindo a coluna percentual
vendas_e_percentual = gêneros_mais_vendidos_global.reset_index(name=’Vendas Globais (un)’)
vendas_e_percentual[‘Percentual (%)’] = percentual_por_genero.values
# Ordenar a visualização de modo descendente
vendas_e_percentual = vendas_e_percentual.sort_values(by=’Vendas Globais (un)’, ascending=False)
# Formatar a coluna percentual para apresentação de apenas 2 casas decimais
vendas_e_percentual[‘Percentual (%)’] = vendas_e_percentual[‘Percentual (%)’].map(lambda x: f’{x:.2f}’)
# Apresentação dos dados
print(vendas_e_percentual)
# Saída
Genre Vendas Globais (un) Percentual (%)
0 Action 1751.18 19.63
1 Sports 1330.93 14.92
2 Shooter 1037.37 11.63
3 Role-Playing 927.37 10.40
4 Platform 831.37 9.32
5 Misc 809.96 9.08
6 Racing 732.04 8.21
7 Fighting 448.91 5.03
8 Simulation 392.20 4.40
9 Puzzle 244.95 2.75
10 Adventure 239.04 2.68
11 Strategy 175.12 1.96
Agora para compararmos os resultados globais com os regionais, podemos fazer as mesmas análises para as vendas no North America (NA), Europa (EU), Japain (JP). Eu fiz essas análises, mas vou deixar como desafio para o leitor.
Agora fiz outra análise, quantidade de vendas de jogos pelos publicadores dos jogos, para isso usei as colunas ‘Publisher’ e ‘Global_Sales’
```python
# Agrupamento dos dados
publishers_global_sales = vgsales_df.groupby(‘Publisher’)[‘Global_Sales’].sum()
# Ordenação dos dados
Publishers_global_sales = publishers_global_sales.sort_values(ascending=False)
# Apresentação dos dados
print(f”\nTop publishers games Global Sales\n{publishers_global_sales}”)
# Saída
Top publishers games Global Sales
Publisher
Nintendo 1786.56
Electronic Arts 1110.32
Activision 727.46
Sony Computer Entertainment 607.50
Ubisoft 474.72
...
Epic Games 0.01
UIG Entertainment 0.01
Commseed 0.01
Ascaron Entertainment 0.01
Boost On 0.01
Name: Global_Sales, Length: 578, dtype: float64
Perceba a quantidade de linhas apresentadas, entretanto, é possível perceber que há resultados insignificantes para nossa apresentação, não quer dizer que tais publicadores de jogos não sejam bons ou que não sejam famosos, mas para o período analisado, ou a amostra de games presente no dataframe não contenha os dados relacionados a tal publicador. A exemplo disso tem a Epic Games, é uma grande empresa de lançamento de jogos, entretanto no dataframe aparece apenas com 0.01 milhões de unidades vendidas. Então mãos pegar apenas os top 10? No pandas tem um método que mostra apenas as primeiras linhas de um dataframe `df.head()`. Este método sem nenhum parâmetro passado mostrará apenas as 5 primeiras linhas, mas nós queremos o top 10, então passaremos o argumento da quantidade de linhas que desejamos apresentar:
print(f”Top publishers games Global Sales\n {publishers_global_sales.head(10)}”)
# Saída
Top publishers games Global Sales
Publisher
Nintendo 1786.56
Electronic Arts 1110.32
Activision 727.46
Sony Computer Entertainment 607.50
Ubisoft 474.72
Take-Two Interactive 399.54
THQ 340.77
Konami Digital Entertainment 283.64
Sega 272.99
Namco Bandai Games 254.09
Name: Global_Sales, dtype: float64
Agora como forma de exercício, tente apresentar uma coluna com a participação percentual de cada publisher nas vendas de games globalmente e por região.
Apresentação dos resultados graficamente
Grafico de Barras
Claro que todo mundo gosta de gráficos em seus relatórios, não é? As tabelas acima já mostram bem os resultados: Quais os gêneros de jogos mais vendidos? Quais os Publisher com maior volume de vendas? Mas os gráficos dão um brilho a mais nos dados, não é? Vamos tentar mostrar a relação gênero x quantidade de vendas em gráfico de barras e gênero x percentual global em gráfico de setores (pizza).
Para isso utilizaremos o módulo `matplotlib`.
import matplolib.pyplot as plt
# Criação do gráfico de barras
plt.figure(figsize=(12,6))
plt.bar(vendas_e_percentual[‘Genre’], vendas_e_percentual[‘Globals Sales (un)’], color=’orange’, alpha=0.7)
# Adicionando titulo e rótulos para melhor leitura
plt.title(‘Vendas Globais por Gênero de jogo’, fontsize=16)
plt.xlabel(‘Gênero’, fontsize=12)
plt.ylable(‘Vendas Globais (em milhões de unidades)’, fontsize=12)
plt.xticks(rotation=45, há=’right’) # Rotaciona os rótulos para não ficarem sobrepostos
plt.tight_layout() # Ajusta o layout para evitar cortes
plt.show()
Agora o gráfico de setores (pizza)
# Definir os dados e os rótulos do gráfico
vendas = vendas_e_percentual[‘Globals Sales (un)’]
gêneros = vendas_e_percentual[‘Genre’]
plt.figure(figsize(10, 10)) # Define o tamanho do gráfico
plt.pie(vendas, labels=gêneros, autopct=’%1.1f%%’, startangle=140) # O parâmetro autopct formata os percentuais para mostrar uma casa decimal.
plt.axis(‘equal’) # Garante que o gráfico seja um cículo perfeito
plt.show()
# SAÍDA:

A verdade é que os dois gráficos demonstra exatamente o mesmo resultado, a única diferença é que um mostra os valores em milhões de unidades e o outro em percentual.
Em busca de mais respostas
Seguindo a análise vamos ver se as avaliações dos críticos influenciam o sucesso do jugo, e vamos ver se estes resultados são refletidos na votação dos usuários. Para isso vamos utilizar o dataframe imdb_games_df, vamos proceder com os mesmos passos de tratamento dos dados
imdb_games_df.isnull().sum()
# Saída
Unnamed: 0
name 0
url 0
year 267
certificate 12900
rating 9203
votes 9203
plot 0
Action 0
Adventure 0
Comedy 0
Crime 0
Family 0
Fantasy 0
Mystery 0
Sci-Fi 0
Thriller 0
dtype: int64
As colunas year, certificate, plot e unamed e todas as colunas que categorizam os jogos, neste momento não fazem sentido para nossa análise, então vamos removê-las.
colunas_para_remover = ['Unnamed: 0', 'url', 'year', 'certificate', 'plot','Action', 'Adventure','Comedy', 'Crime', 'Family', 'Fantasy', 'Mystery', 'Sci-Fi', 'Thriller']
imdb_games_df = imdb_games_df.drop(colunas_para_remover, axis=1, inplace=True)
Como queremos associar notas dos jogos (rating) com as vendas e a votação dos usuários no jogos à quantidade de vendas, então precisamos unir os dois dataframes: vendas e imdb. Fazer isso chama-se fazer um merge entre os dataframes.
Mas antes de fazermos o merge precisamos notar se há alguma coluna comum entre os dataframes, pois o merge utilizará esta coluna em comum na união dos dados. No caso dos nossos dataframes temos a coluna Name, então faremos o merge por essa coluna.
No caso há uma divergência, que é o rótulo das colunas, então se faz necessária a correção. Vamos adequar o nome da coluna de acordo com o dataframe que já trabalhamos, nela a coluna ‘name’ está com a primeira letra maiúscula então, vamos mudar no dataframe imdb
imdb_games_df = imdb_games_df.rename(‘name’:’Name’)
Agora proceder com a união dos dataframes
vendas_com_notas_df = vgsales_df.merge(imdb_games_df, on=”Name”, how=’inner’)
#remover duplicados
vendas_com_notas_df.drop_duplicates(subset='Name', keep='first', inplace=True)
# agora vamos verificar como está o dataframe
vendas_com_notas_df.head()
# SAÌDA
Rank Name Genre Publisher NA_Sales EU_Sales JP_Sales Other_Sales Global_Sales rating votes
0 Wii Sports Sports Nintendo 41.49 29.02 3.77 8.46 82.74 7.7 3,883
1 Super Mario Bros. Platform Nintendo 29.08 3.58 6.81 0.77 40.24 8.9 6,207
2 Mario Kart Wii Racing Nintendo 15.85 12.88 3.79 3.31 35.82 8.4 3,925
3 Wii Sports Resort Sports Nintendo 15.75 11.01 3.28 2.96 33.00 7.8 1,435
4 Tetris Puzzle Nintendo 23.20 2.26 4.22 0.58 30.26 8.4 147
Agora para buscar a resposta da terceira pergunta: Por que um jogo vende bem? Iremos utilizar as colunas: vendas, rating e votes. A ideia é: Será que avaliações de especialistas (críticos) influencia o sucesso de um jogo? Será que a votação dos usuários afeta o sucesso de um jogo?
Para começar vamos traçar a correção entre as vendas globais e o rating do jogo, julgo que a coluna rating seja resultado da avaliações dos críticos/especialistas em jogos. O módulo pandas possui um método que é uma função estatística que verifica como uma variável cresce em `correlação` com outra.
# Rodando a correlação entre Global_sales e Rating
correlação_global_sales_x_rating = vendas_com_notas_df[‘rating’].corr(vendas_com_notas_df[‘Global_Sales’])
print(f"A correlação entre rating e Global_Sales e: {correlacao_global_sales_x_rating}")
# Saída
A correlação entre rating e Global_Sales e: 0.1931805387751386
Está é uma correlação positiva (sim existe alguma correlação) entretanto fraca, o que pode significar que a opinião de especialistas/críticos influencia pouco nas vendas globais de games.
Agora vamos ver a correlação entre a votação de usuários e as vendas globais. Contudo há uma dificuldade, neste dataframe a coluna votos não está no tipo adequado para utilizar a função de correlação. Para usar a correlação é necessário que ambas as colunas precisam ser do tipo numérico, se você verificar o tipo de dado atual na coluna ‘votes’ irá perceber que é do tipo `object`, isto é ‘texto’, então vamos fazer o casting para numérico
# Casting do tipo de dados da coluna votes object -> numeric
Vendas_com_notas_df[‘votes’] = pd.to_numeric(vendas_com_notas_df[‘votes’], erros=’coerce’)
#verificando o tipo de dados
Print(vendas_com_notas_df[‘votes’].dtypes)
# Saída
Float64
Agora sim, podemos traçar a correlação entre as variáveis
correlacao_votes = vendas_com_notas_df[‘votes’].corr(vendas_com_notas_df[‘Global_Sales’])
print(f"A correlação entre votes e Global_Sales é: {correlacao_votos}")
# Saída
A correlação entre votes e Global_Sales é: 0.27151468262644346
Como funciona a correlação?
É um valor entre -1 e 1, quanto mais próximo das extremidades mais fraca ou mais forte é a correlação, caso a correlação esteja nas extremidades, é dito como correlações perfeitas. Se a correlação for 0, quer dizer que não há correlação. Se abaixo de 0, então é uma correlação fraca, caso contrário é uma correlação forte e a intensidade da correlação é dada pela proximidade da extremidade.
Olha só que interessante este resultado, a correlação entre votes e Global_Sales é positivamente fraca, entretanto é mais forte que entre rating e Global_Sales, isso indica que os usuários levam mais em consideração a experiência de outros usuários que a opinião de críticos e profissionais da área de games.
Quero frisar que esta análise eu fiz em relação a vendas globais, será que a correlação regional é mais forte que a global? Será que há outros tipos de correlações, fica a dica de novas análises para se fazer.
Então meus caros este foi o meu primeiro projeto de análise de dados, espero que ajude vocês a começarem seus estudos nessa área extremamente cativante.





Confesso que as ideias vieram surgindo e se eu permitisse até agora estaria fazendo o projeto, pq toda hora surge uma ideia. A minha maior dificuldade é entender a documentação do Pandas e do Matplotlib, acho muito confusa, mas isso é uma opinião particular, tive de recorrer ao Gemini várias vezes para descomplicar a ferramenta.
Como sou iniciante na área, tive de perguntar muito, discuti com a IA como se fosse um parceiro de projeto e juntos discutimos ideias e soluções, e no final, estou conseguindo colocar em prática a máxima: "Imperfeito feito, vence perfeito nunca feito" e está aí.
Antonio, seu projeto sobre a análise de vendas de videogames é uma excelente aplicação prática dos conceitos de análise de dados, e você conseguiu descomplicar a jornada ao detalhar todas as etapas, desde o tratamento dos dados até as análises de correlação. O modo como você aborda o processo de limpeza e análise, como a remoção de colunas desnecessárias e o uso de gráficos, facilita o entendimento e demonstra a importância de se preparar os dados de forma cuidadosa antes de realizar qualquer análise.
Na DIO, acreditamos que a habilidade de transformar dados brutos em insights valiosos é essencial para qualquer profissional de dados. E, como você destacou, ao entender como diferentes variáveis se relacionam, conseguimos criar estratégias mais assertivas, não só para empresas, mas para qualquer área que precise de dados para tomar decisões.
Qual foi o maior desafio que você encontrou ao trabalhar com grandes conjuntos de dados, como esse de vendas de videogames, e como você conseguiu superá-lo?