

Entendendo os Modelos de Aprendizado Profundo: Da Base às Arquiteturas Avançadas
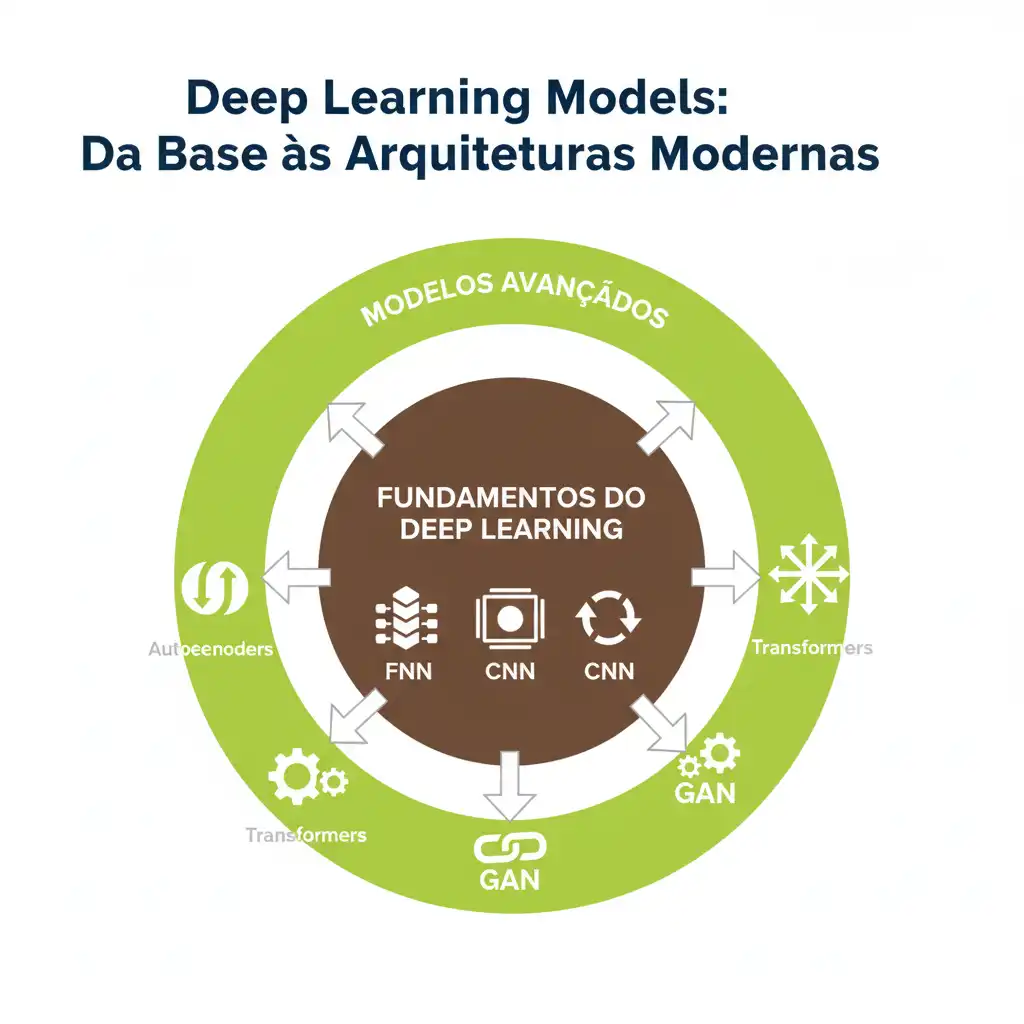
O aprendizado profundo (ou deep learning) revolucionou a forma como máquinas entendem dados. Desde reconhecimento de imagens até geração de texto, os modelos de deep learning estão por trás das maiores inovações da IA moderna. Mas como esses modelos se relacionam entre si? O que diferencia uma rede neural simples de um Transformer poderoso?
A imagem intitulada “Deep Learning Models” oferece uma visão organizada e visualmente intuitiva dessa evolução — mostrando como os modelos fundamentais dão origem às arquiteturas mais avançadas. Vamos explorar cada camada desse diagrama e entender seu papel no ecossistema do aprendizado profundo.
🟤 Camada Interna: Os Pilares do Deep Learning
No centro do diagrama estão três dos modelos mais básicos — mas também mais importantes — do aprendizado profundo:
1. Redes Neurais Feedforward (FNN)
São as redes neurais mais simples: os dados fluem apenas em uma direção — da entrada, passando pelas camadas ocultas, até a saída. São a base teórica para quase todos os outros modelos.
✅ Aplicações: Classificação de imagens simples, previsão de vendas, detecção de padrões básicos.
💡 Pense nelas como o “ABC” do deep learning.
2. Redes Neurais Convolucionais (CNN)
Projetadas especificamente para lidar com dados estruturados em grade — como imagens e vídeos. Usam filtros convolucionais para extrair características espaciais automaticamente.
✅ Aplicações: Reconhecimento facial, diagnóstico médico por imagem, detecção de objetos em vídeos.
💡 Se você já viu um sistema de reconhecimento de rostos, provavelmente estava usando uma CNN.
3. Redes Neurais Recorrentes (RNN)
Idealizadas para dados sequenciais — como textos, áudios ou séries temporais. Diferentemente das FNNs, elas têm memória: o estado de uma etapa influencia a próxima.
✅ Aplicações: Tradução automática, reconhecimento de fala, análise de sentimentos em textos.
💡 São as redes que “lembram” o contexto — perfeitas para linguagem e tempo.
🟢 Camada Externa: Modelos Avançados e Especializados
Ao redor desses pilares, encontramos modelos mais sofisticados — muitos deles derivados ou inspirados nas arquiteturas básicas, mas adaptados para tarefas específicas ou mais complexas.
4. Autoencoders
Modelos não supervisionados que aprendem a compactar e reconstruir dados. Úteis para reduzir dimensionalidade, detectar anomalias ou gerar representações latentes.
✅ Aplicações: Compressão de imagens, detecção de fraudes, pré-treinamento de modelos.
💡 Imagine um modelo que “aprende a resumir” seus dados sem precisar de rótulos.
5. LSTM (Long Short-Term Memory)
Uma evolução das RNNs, projetada para resolver o problema do “esquecimento” em sequências longas. Usa portas para controlar o fluxo de informação.
✅ Aplicações: Previsão de séries temporais financeiras, geração de músicas, chatbots mais contextuais.
💡 É como uma RNN com “memória de longo prazo” — essencial para tarefas que exigem compreensão de contexto distante.
6. GANs (Generative Adversarial Networks)
Dois modelos competindo: um gerador (cria dados falsos) e um discriminador (distingue reais de falsos). Juntos, aprendem a gerar dados realistas.
✅ Aplicações: Geração de imagens realistas, criação de arte, síntese de voz, aumento de dados.
💡 São os “artistas digitais” da IA — capazes de criar o que nunca existiu.
7. Transformers
Revolutionaram o campo da linguagem natural. Em vez de depender de sequências lineares (como RNNs), usam mecanismos de autoatenção para entender relações entre todas as partes da entrada simultaneamente.
✅ Aplicações: Tradução automática (Google Translate), assistentes virtuais (ChatGPT, Gemini), sumarização de textos.
💡 São os modelos por trás da “era da linguagem generativa” — e hoje são aplicados até em visão computacional!
💡 Por Que Essa Estrutura Importa?
Esse diagrama não é só uma lista de nomes — ele representa uma evolução lógica:
Os modelos fundamentais (FNN, CNN, RNN) são os blocos de construção. Os modelos avançados (Autoencoders, LSTM, GANs, Transformers) são extensões ou especializações desses blocos, criadas para resolver problemas mais complexos ou específicos.
Entender essa hierarquia ajuda a:
- Escolher o modelo certo para cada problema.
- Saber onde começar ao aprender deep learning.
- Compreender como os modelos modernos (como GPT ou Stable Diffusion) foram construídos a partir de ideias mais antigas.
📌 Conclusão
O aprendizado profundo não é uma caixa mágica — é uma estrutura bem organizada de ideias, evoluções e adaptações. A imagem “Deep Learning Models” serve como um mapa conceptual poderoso para navegar nesse universo.
Se você está começando, comece pelos pilares: FNN, CNN e RNN. Depois, explore as camadas externas — Autoencoders, LSTM, GANs e Transformers — e veja como cada uma resolve desafios únicos.
E lembre-se: não importa quão avançado seja o modelo — ele sempre tem raízes nos fundamentos.






Excelente, Ronaldo! Que artigo incrível e super completo sobre Modelos de Aprendizado Profundo! É fascinante ver como você aborda o tema, mostrando que o Deep Learning (DL) é uma evolução lógica que revolucionou o reconhecimento de imagens, a linguagem e a recomendação.
Qual você diria que é o maior desafio para um desenvolvedor ao implementar os princípios de IA responsável em um projeto, em termos de balancear a inovação e a eficiência com a ética e a privacidade, em vez de apenas focar em funcionalidades?