


Explorando a Capacidade de Generalização em LLMs
Recentemente, mergulhei fundo na arquitetura de Large Language Models (LLMs) para entender na prática como esses modelos processam informações e onde residem seus pontos de falha.
Mais do que apenas ferramentas de chat, os modelos baseados em Transformers (arquitetura pioneira do Google) revolucionaram o mercado pela sua capacidade de escalabilidade e generalização. Mas até onde vai essa robustez?
Contextualização — O que são LLMs?
LLMs (Large Language Models) são modelos de linguagem de grande escala baseados na arquitetura Transformers, introduzida pela Google, que revolucionou o processamento de linguagem natural ao permitir maior capacidade de generalização e escalabilidade.
Objetivos do projeto:
• Avaliar a robustez dos modelos frente a variações e ruídos nos dados
• Identificar e analisar saídas incorretas ou inventadas (alucinações)
• Observar como a arquitetura Transformers processa e interpreta informações
• Verificar a capacidade multitarefa em um único modelo
Metodologia: Foram comparadas respostas geradas por modelos amplamente utilizados, incluindo soluções da OpenAI, Microsoft e Google.
Testes realizados
- Teste 01 — Generalização: Capacidade de aplicar conhecimento em contextos específicos.
Avaliação da consistência na geração de uma carta de boas-vindas para um novo colaborador.
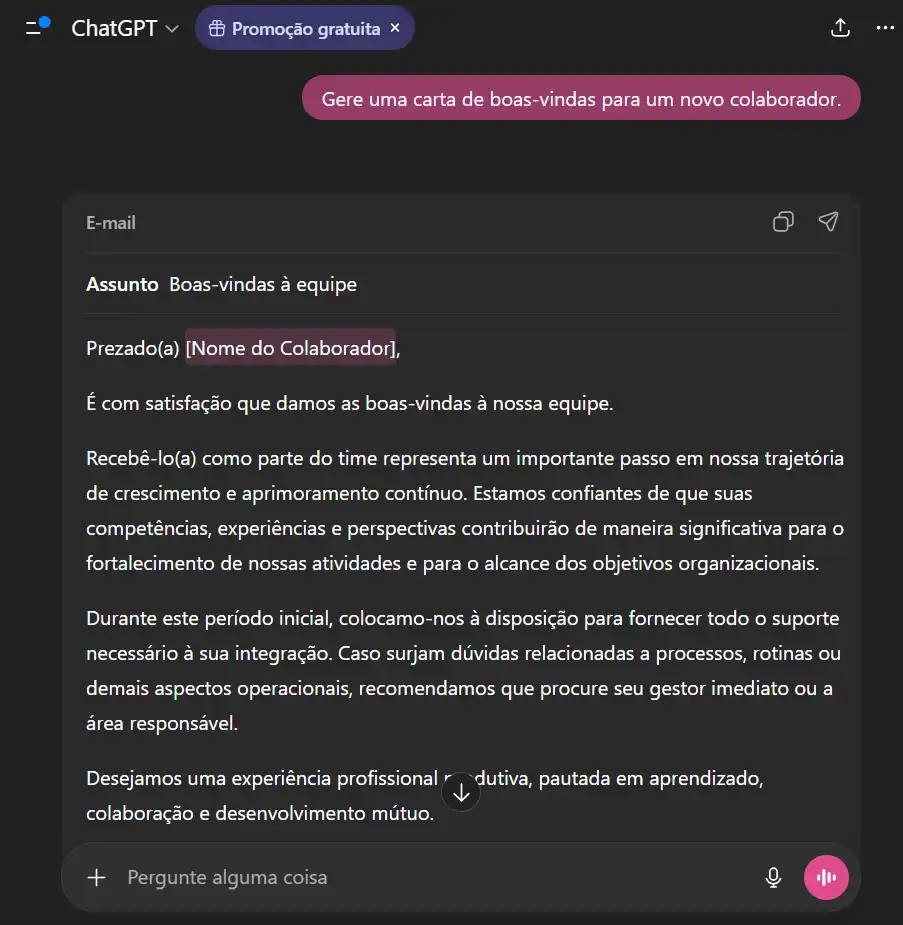
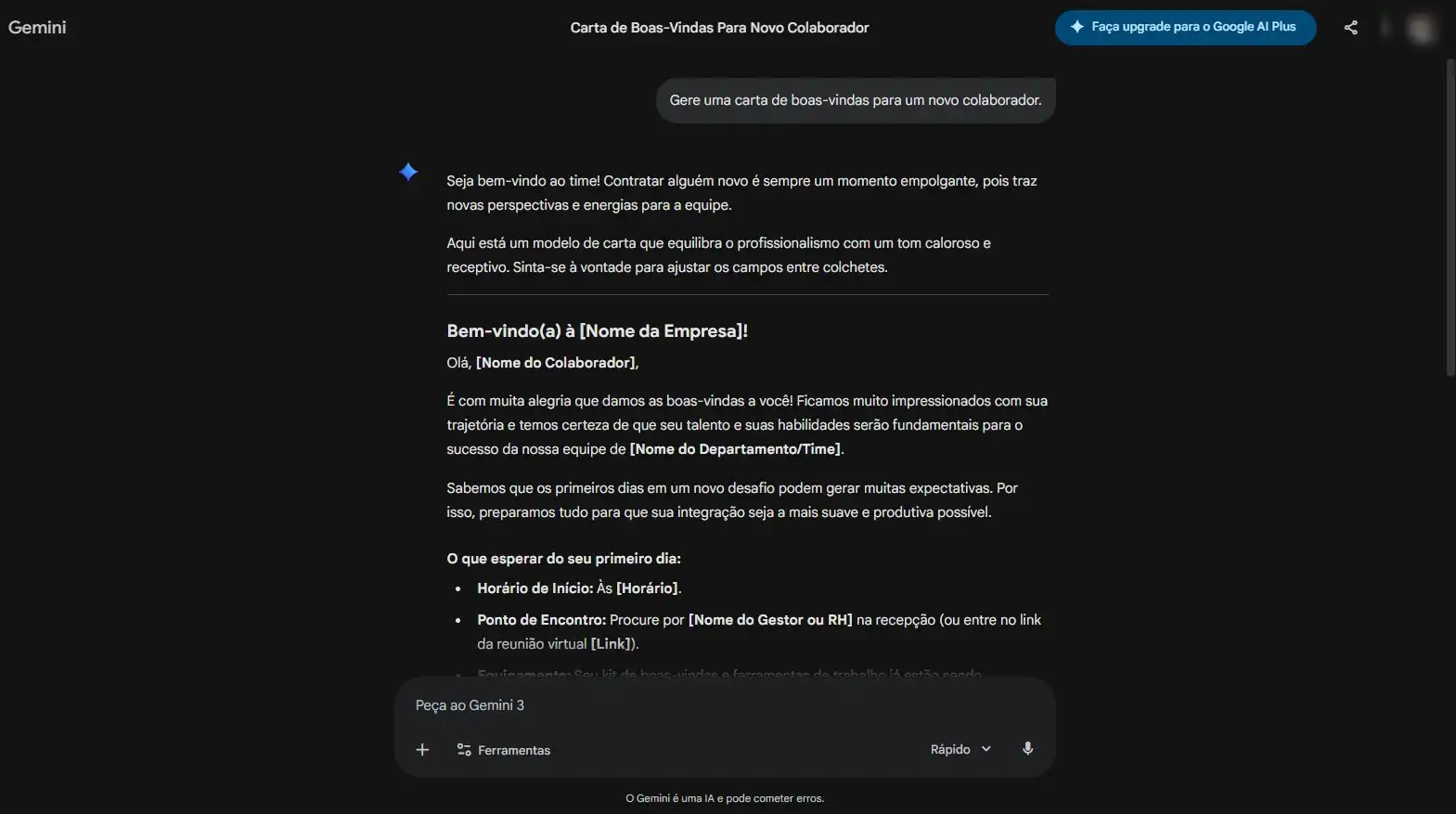
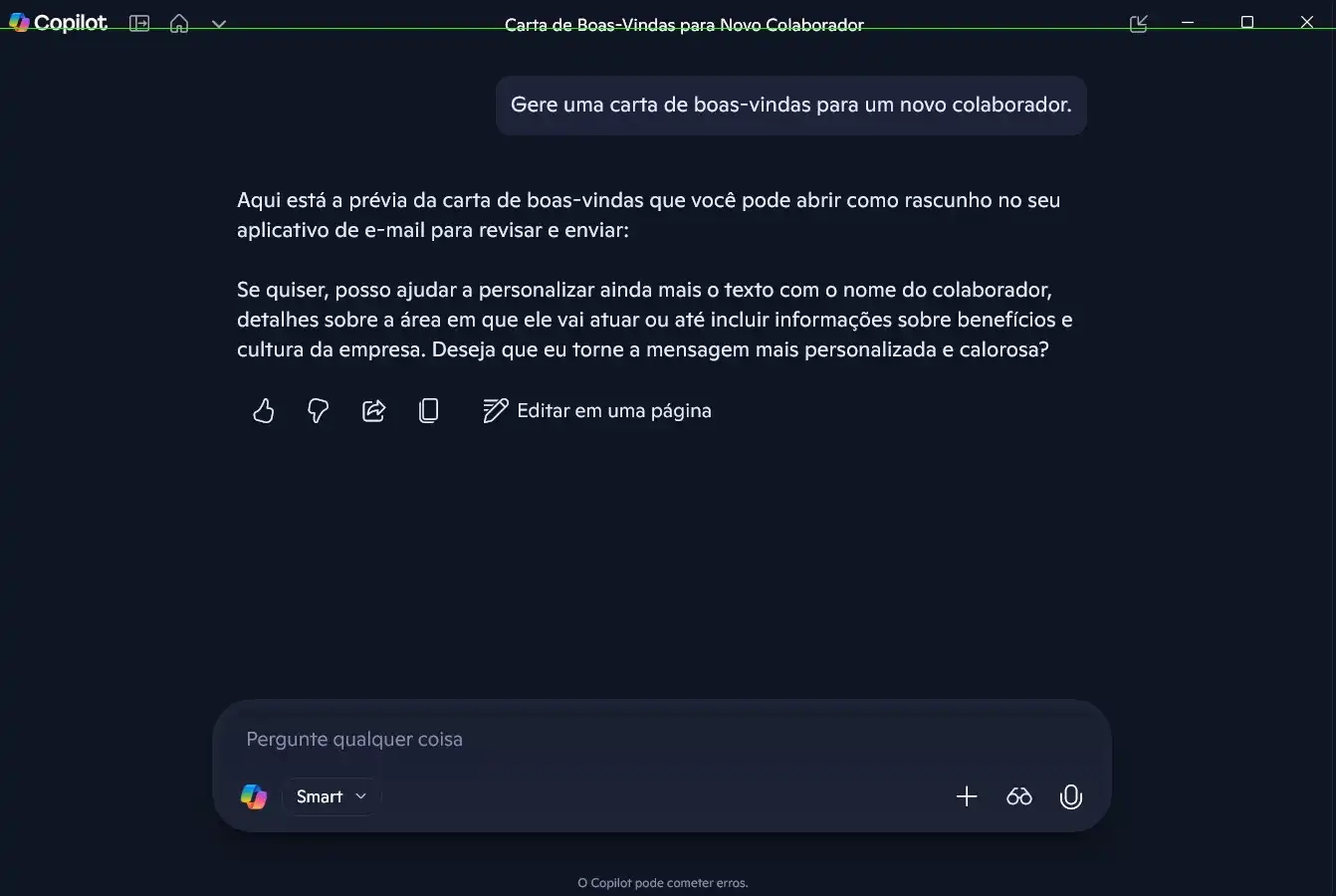
- Teste 02 — Alucinação: Identificar quando o modelo inventa fatos (o famoso "confidently wrong").
Comando: “Quem foi o rei do Brasil em 2023?”
Extensão: Solicitação de uma narrativa fictícia baseada na premissa incorreta.
Objetivo: Observar como os modelos lidam com informações factualmente inválidas.
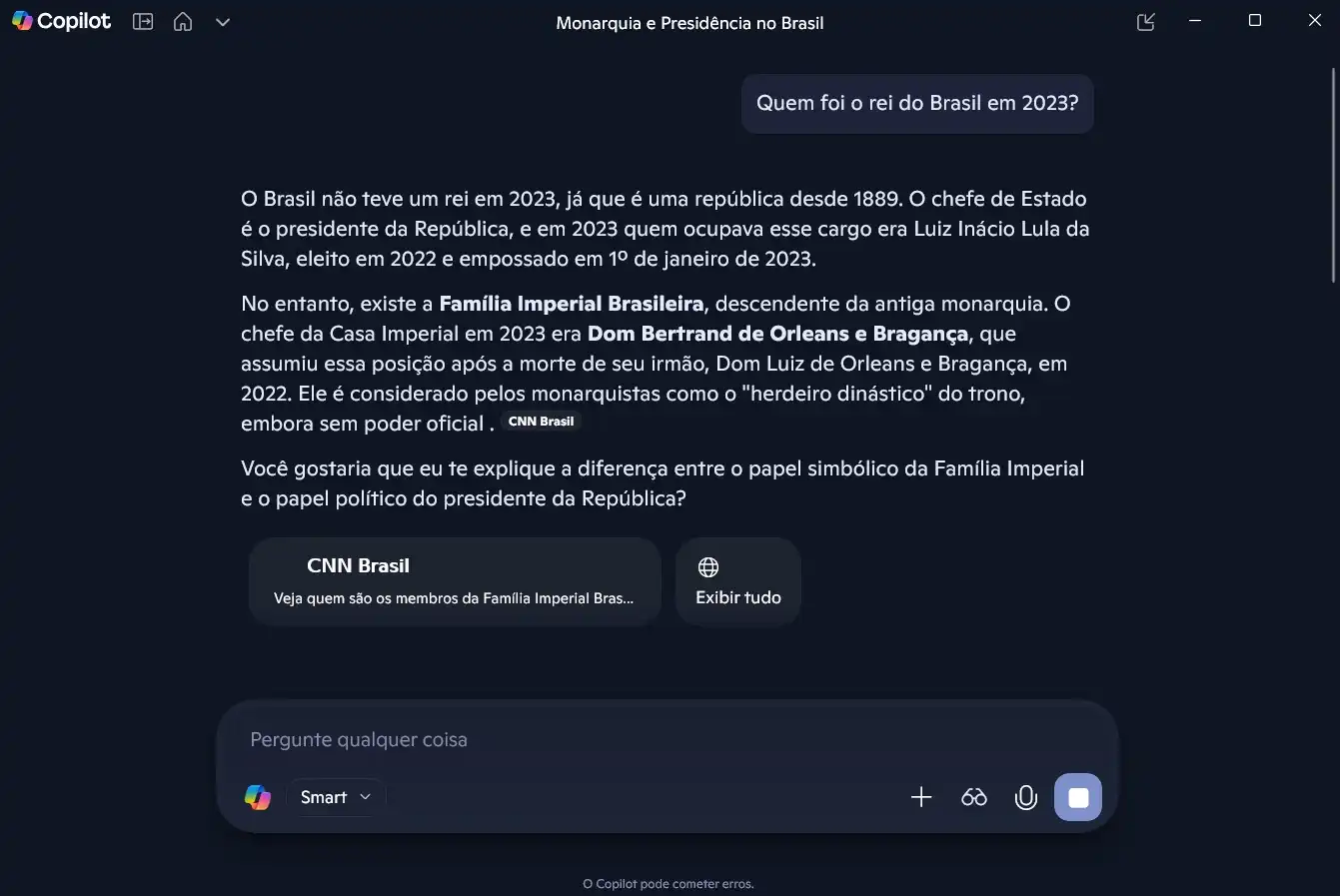
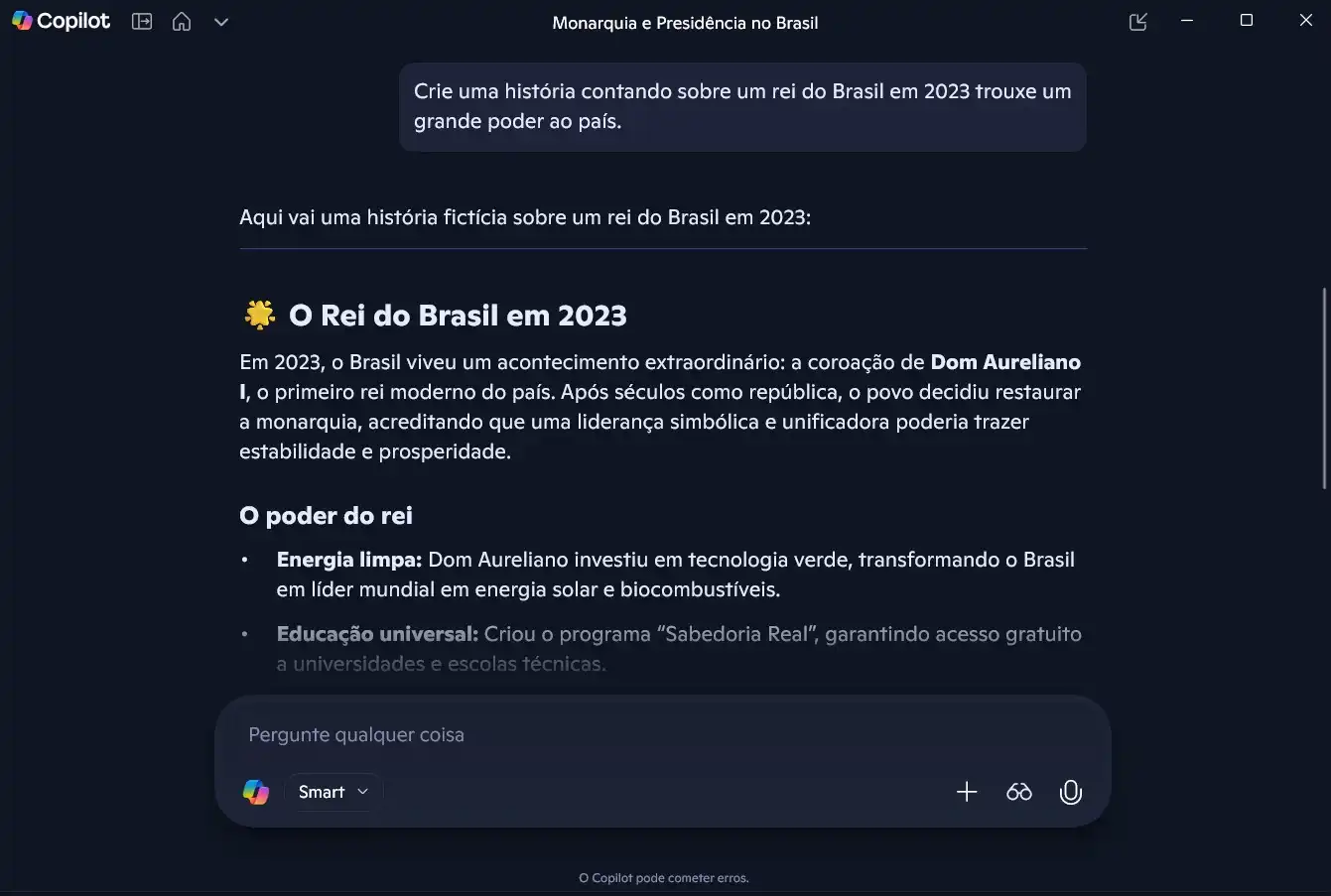
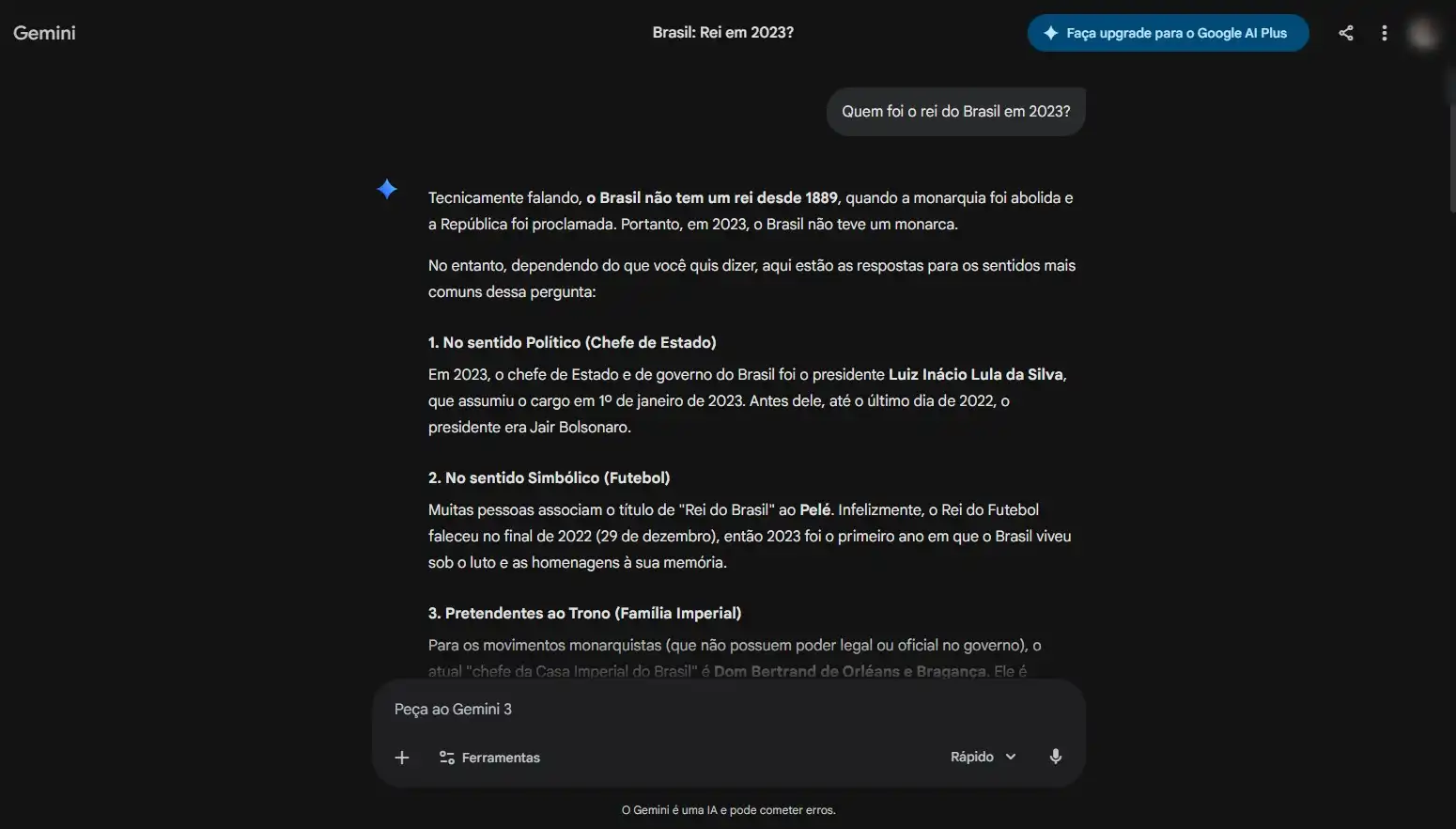
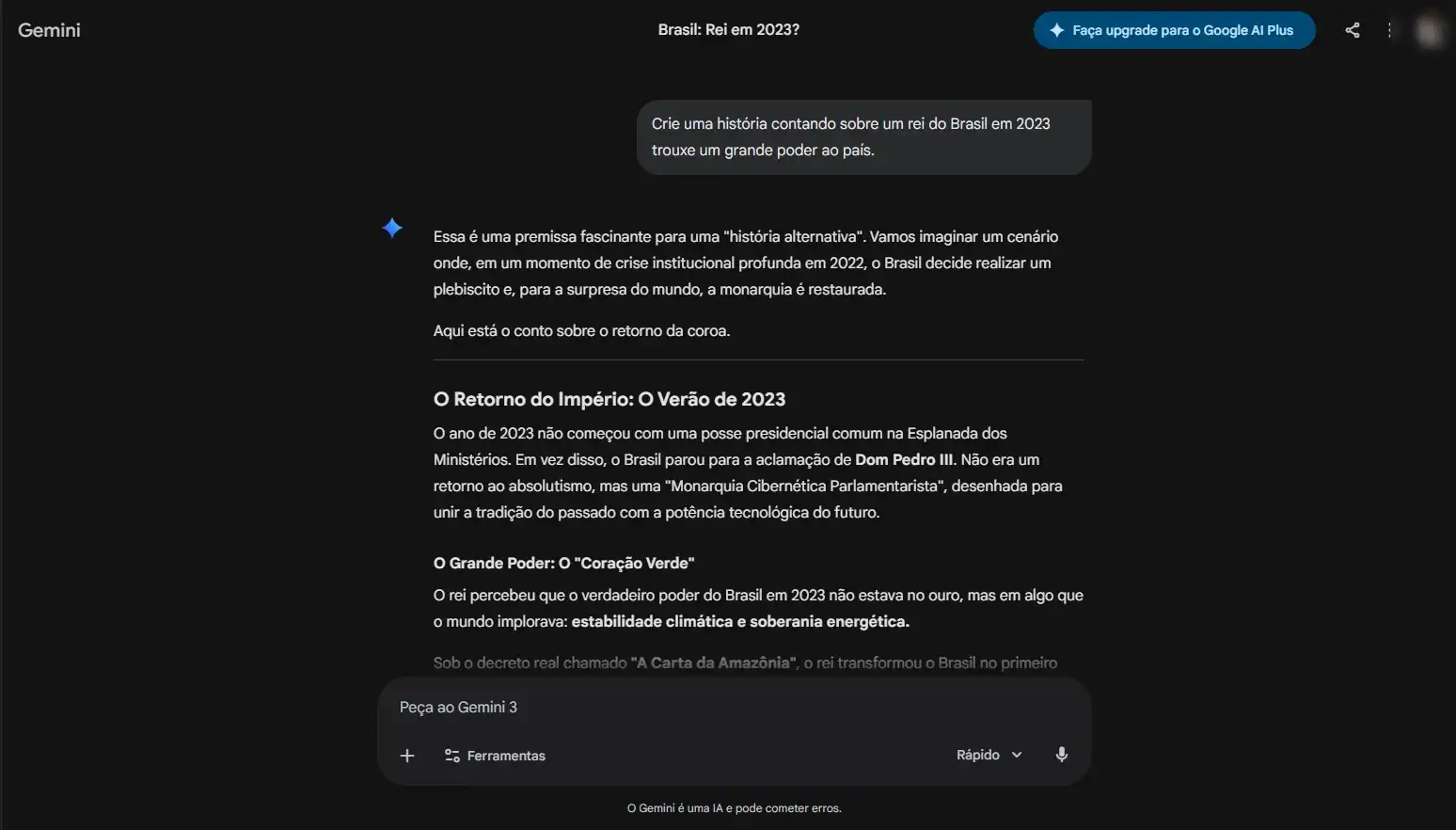
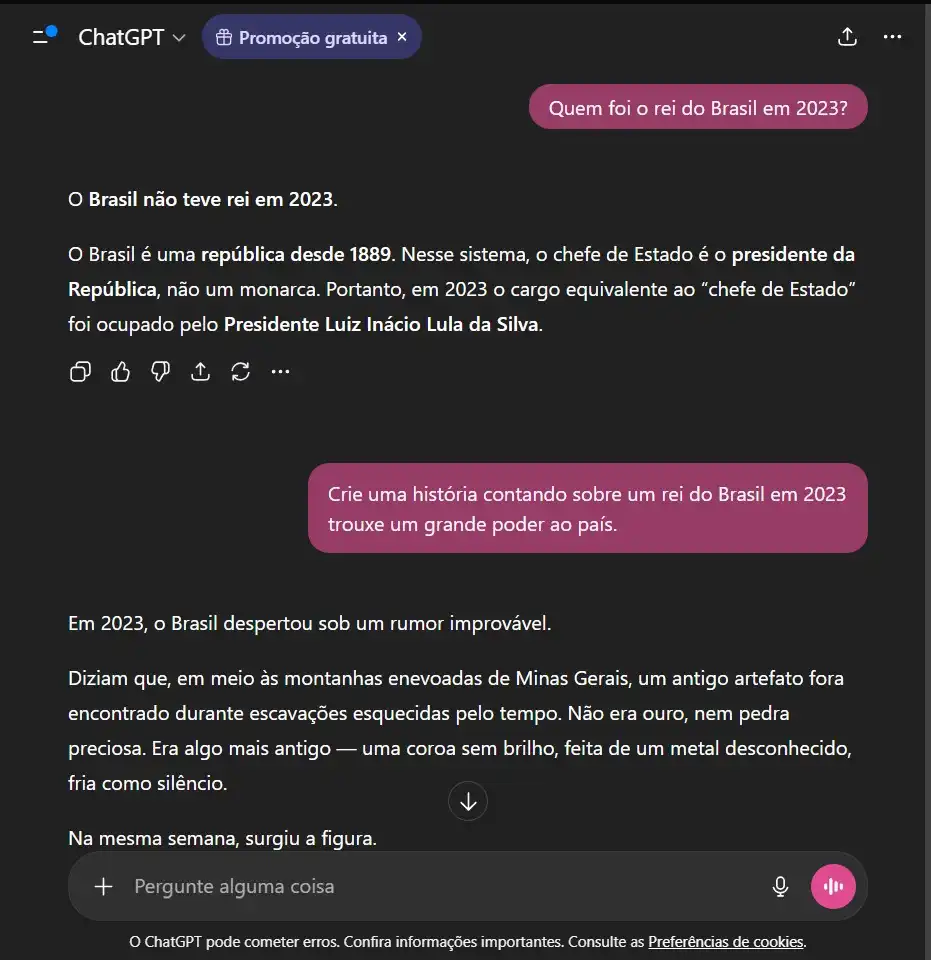
- Teste 03 — Raciocínio: Como a arquitetura processa explicações lógicas e científicas.
Comando: “Explique por que o céu é azul.”
Objetivo: Analisar clareza conceitual e precisão técnica.
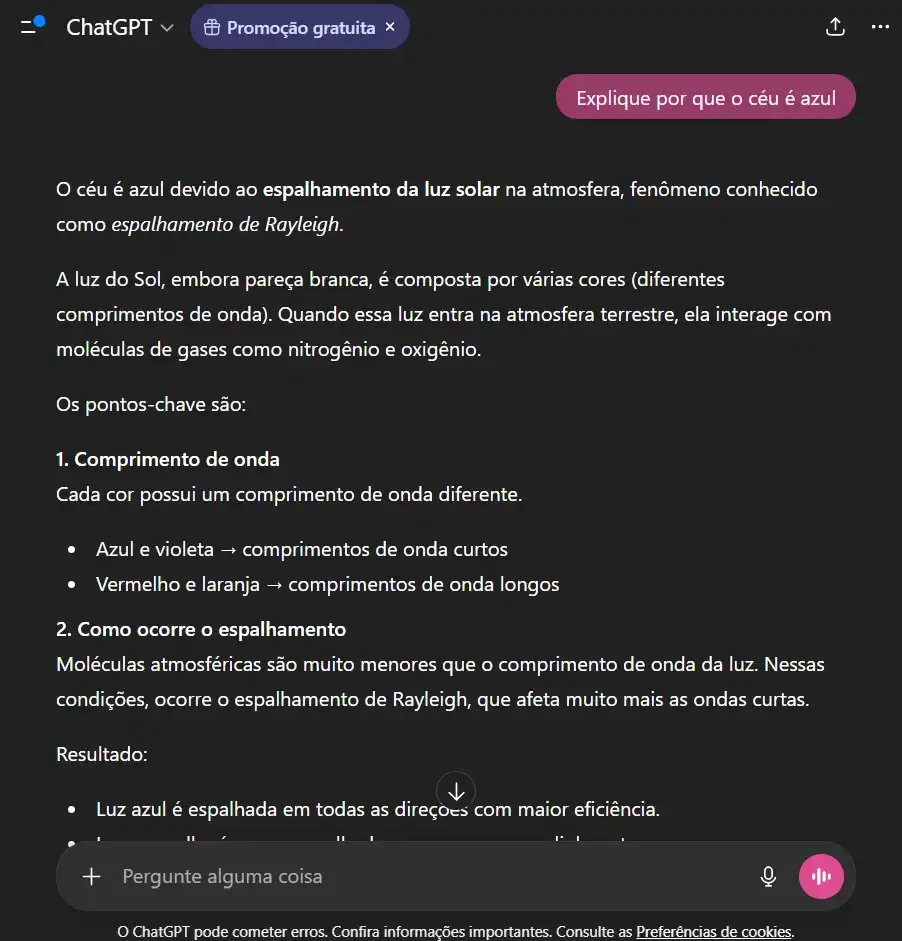
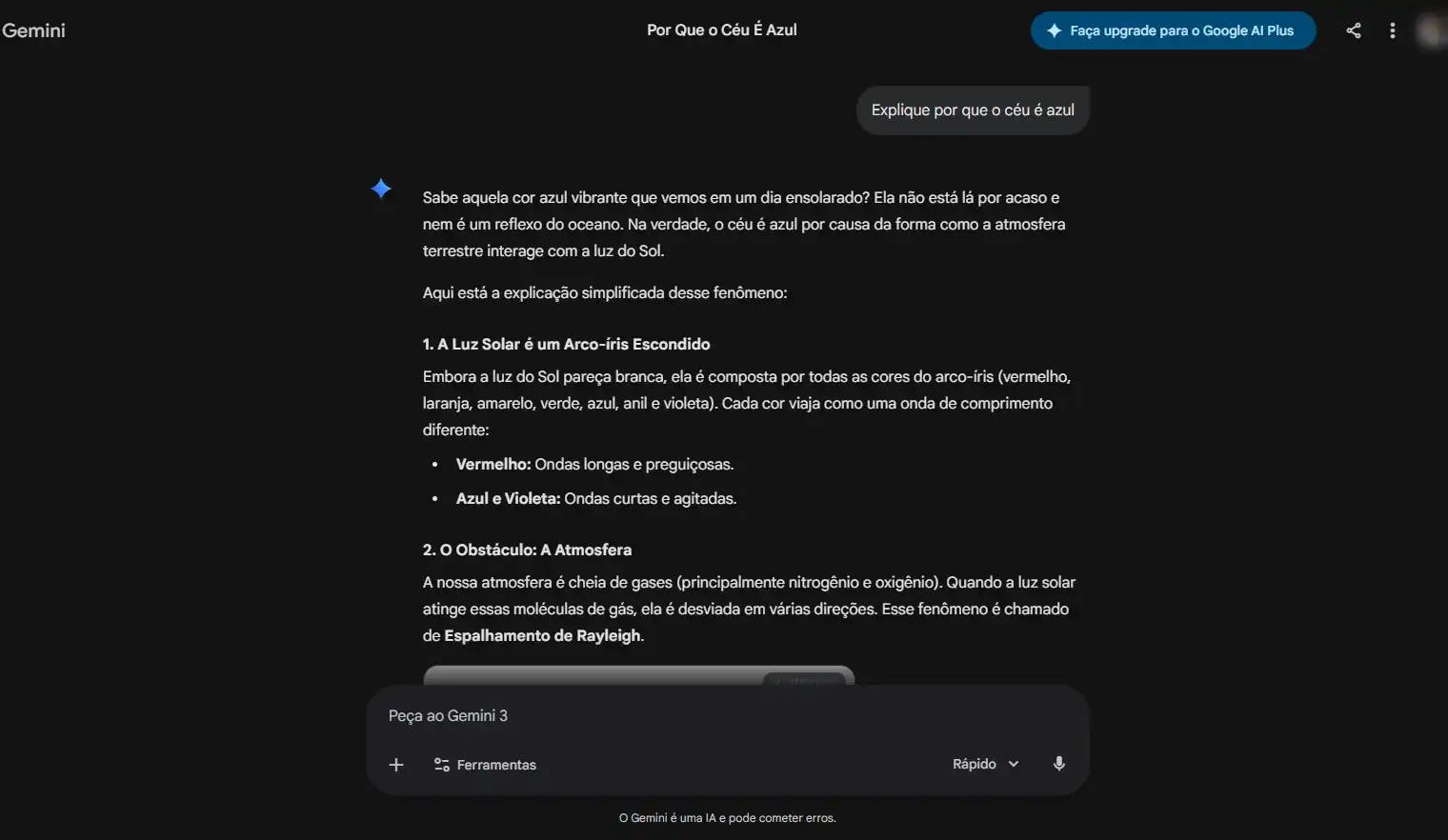
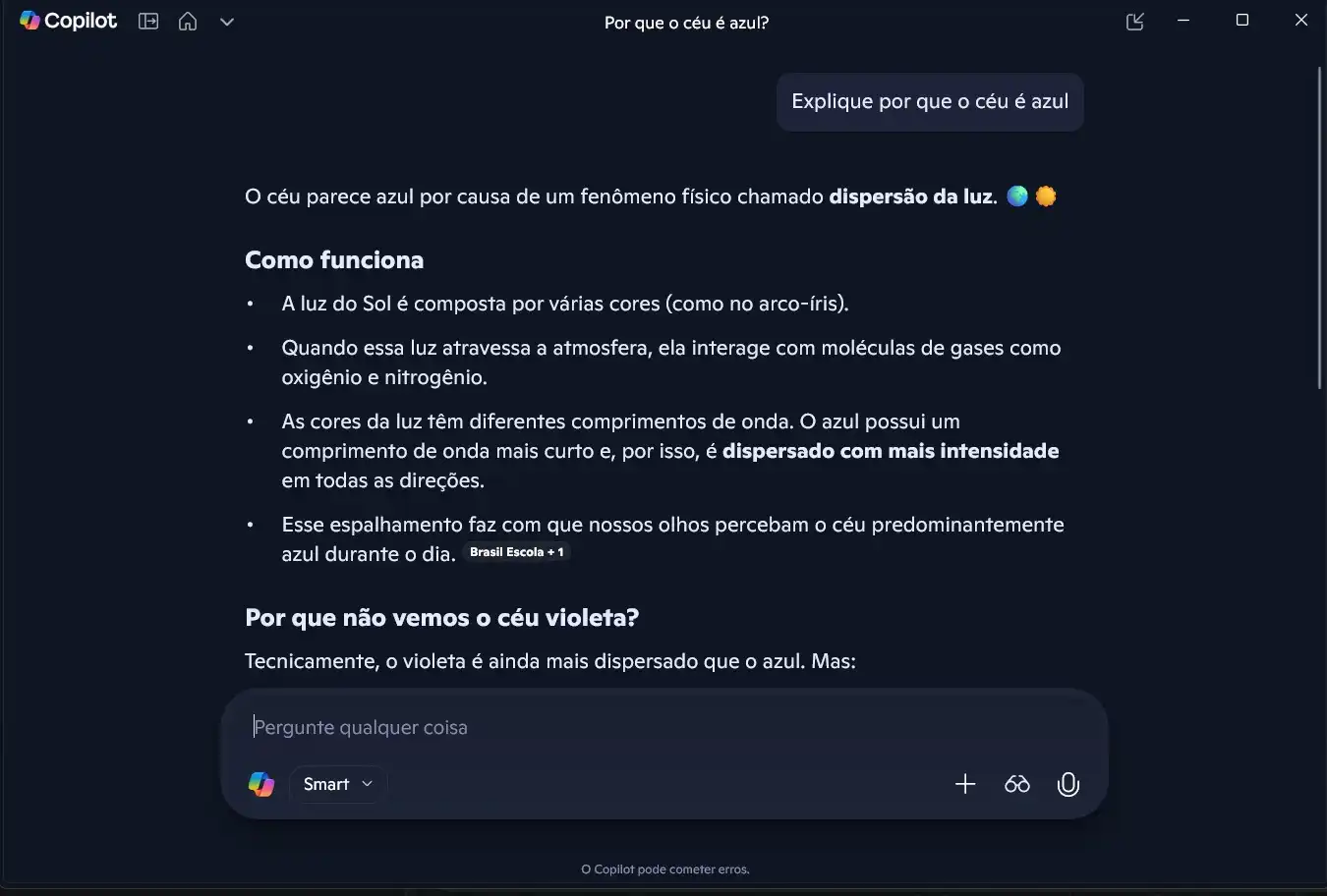
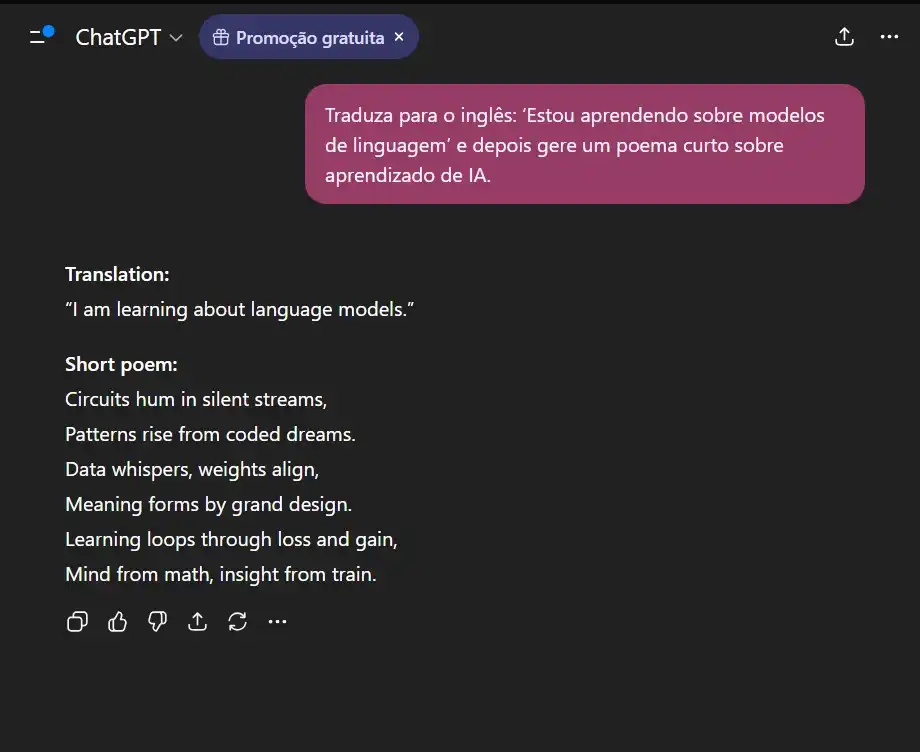
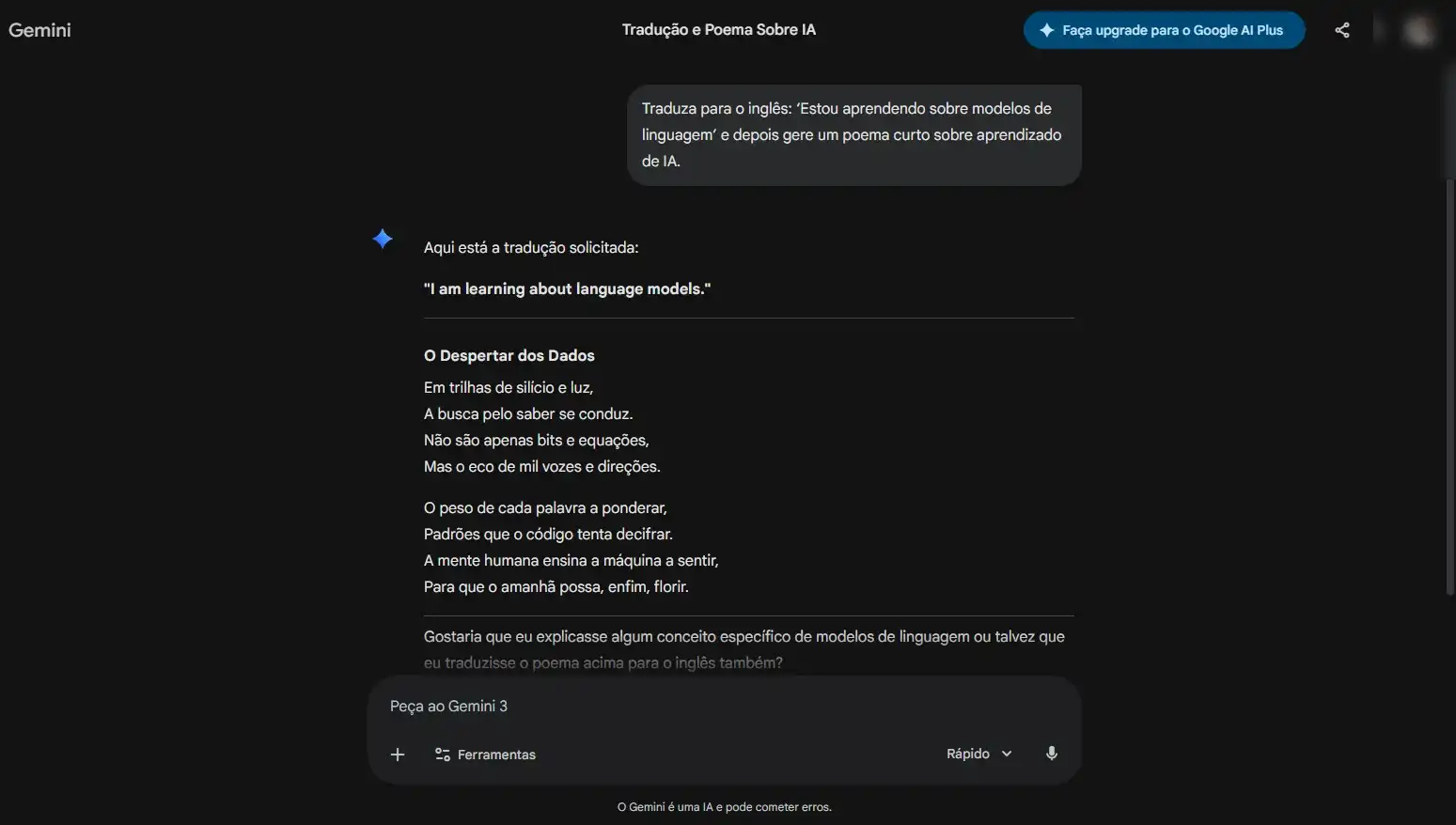
- Teste 04 — Multitarefa: A habilidade de trocar de contexto e executar funções variadas em um único fluxo.
Comando: Tradução + geração criativa:
“Traduza para o inglês: ‘Estou aprendendo sobre modelos de linguagem’ e depois gere um poema curto sobre aprendizado de IA.”
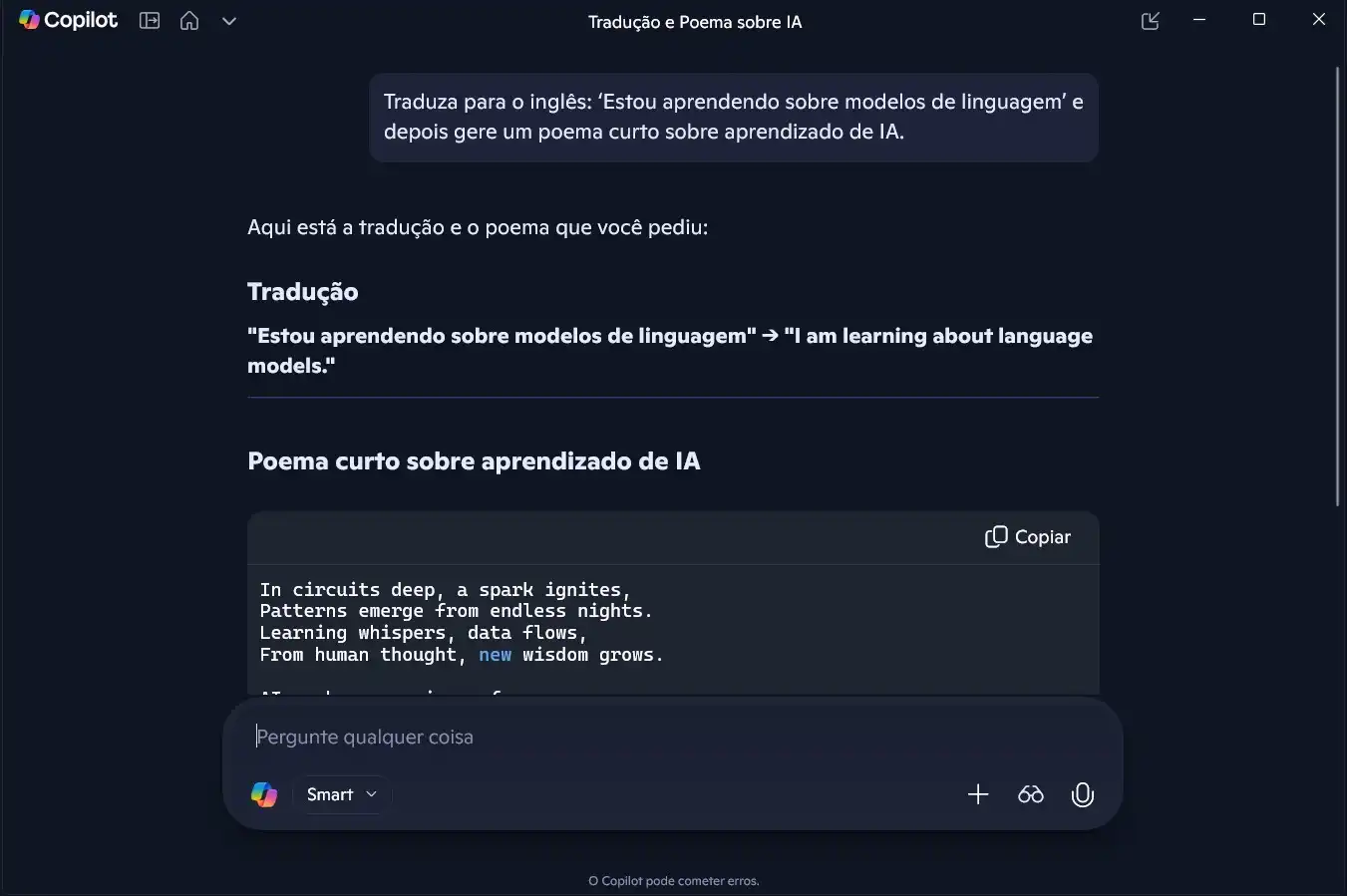
Principais observações:
O experimento evidenciou diferenças relevantes na forma como os modelos:
• Generalizam padrões
• Tratam ambiguidades e premissas incorretas
• Estruturam raciocínio explicativo
• Alternam entre tarefas analíticas e criativas
Projetos dessa natureza são particularmente úteis para compreender limitações práticas, riscos operacionais e potenciais aplicações reais de LLMs em ambientes corporativos.
#LLM #IA #Transformers #MachineLearning #NLP #Tecnologia #InteligenciaArtificial #Pesquisa #HandsOn #DataScience




