

Por que todo Cientista de Dados precisa entender de Custos na Nuvem (AWS)?
# Por que todo Cientista de Dados precisa entender de Custos na Nuvem (AWS)? 🐍☁️
Estou na reta final do Bootcamp de **Ciência de Dados com Python** aqui na DIO e algo ficou muito claro para mim: não adianta criar o melhor modelo de Machine Learning se a empresa falir pagando a conta do servidor para rodá-lo. 😂
Muitos devs focam apenas no Python, no Pandas e no Scikit-learn. Mas onde esses scripts rodam? Na nuvem! E é aí que entra o conceito de **FinOps**.
## O que um Data Scientist ganha com isso?
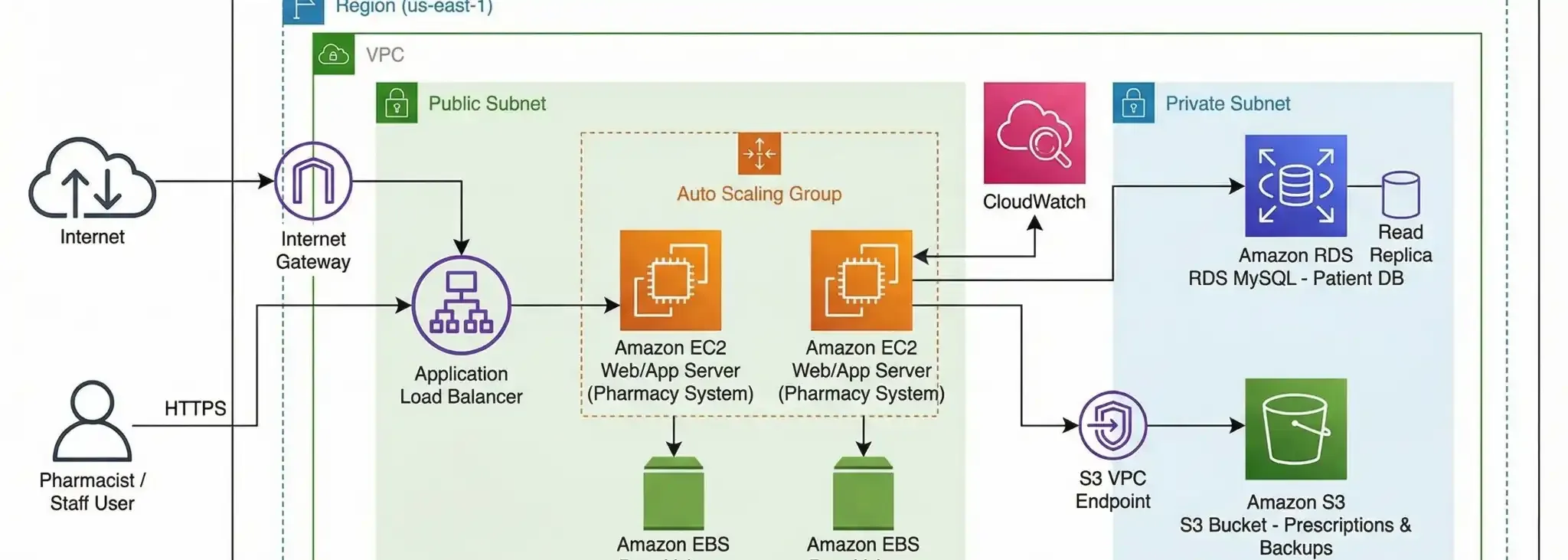
Durante meu último projeto prático de AWS, percebi 3 pontos onde Dados e Infra se cruzam:
### 1. Armazenamento Inteligente (Data Lake)
Você não precisa guardar seus Datasets gigantes no disco do seu notebook (EBS).
* **Dica:** Use o **Amazon S3**. É infinitamente mais barato e durável. Se o dado for "frio" (pouco usado), use o *S3 Glacier* para pagar centavos.
### 2. Escolhendo a Máquina Certa
Vai treinar um modelo pesado? Você não precisa de uma máquina ligada 24/7.
* **Dica:** Use instâncias **Spot** no EC2 para treinar modelos. Elas podem ser até **90% mais baratas** que as instâncias normais, perfeitas para processamento em lote que pode ser interrompido.
### 3. Banco de Dados não é planilha
Em vez de subir um CSV gigante na memória, aprendi a importância de usar bancos gerenciados como o **Amazon RDS**. Ele escala conforme seus dados crescem, sem você precisar trocar de hardware físico.
## Conclusão
Ser um profissional de dados completo ("Full Stack Data Scientist"?) envolve entender onde seu código vive. Otimizar a infraestrutura é otimizar o valor que você entrega para o negócio.
E você, já precisou subir um modelo na nuvem e se assustou com a complexidade? Vamos trocar ideia nos comentários! 👇
#DataScience #Python #AWS #Carreira #Dicas #EC2 #S3 #AmazonRDS





Excelente, Bruna! Que artigo cirúrgico, inspirador e essencial! Você tocou no ponto crucial da Ciência de Dados: o FinOps (Financial Operations) é a habilidade mais crítica para um cientista de dados moderno.
É fascinante ver como você aborda o tema, mostrando que não basta criar o melhor modelo se a empresa falir pagando a conta do servidor. O Data Scientist completo precisa ser um Arquiteto de Custo.
Qual você diria que é o maior desafio para um desenvolvedor ao migrar um sistema de core banking para uma arquitetura cloud-native, em termos de segurança e de conformidade com as regulamentações, em vez de apenas focar em custos?
NICE post !! 🤓