

RAG: O Elo Inteligente entre a Busca e a Criação
Introdução
Vivemos uma era em que a Inteligência Artificial Generativa – envolvendo grandes modelos de linguagem (LLMs), engenharia de prompts e recuperação aumentada – está redefinindo como máquinas pensam, pesquisam e criam. Neste contexto, a técnica conhecida como Retrieval‑Augmented Generation (RAG) surge como um elo inteligente entre busca e criação, elevando o desempenho dos LLMs ao permitir que eles combinem a geração de texto com a recuperação de conhecimento externo atualizado. Este artigo explora, de forma estruturada e inspiradora, o que é RAG, como funciona, por que importa, suas aplicações práticas, desafios e perspectivas futuras.
O que é RAG: o elo entre busca e criação
A técnica RAG pode ser entendida como a combinação de dois mundos:
- um mecanismo de recuperação de informação (search/retrieval) que localiza dados relevantes externos;
- e um mecanismo de geração de linguagem natural que usa esses dados para produzir texto coerente.
Conforme a literatura define, “Retrieval-Augmented Generation combina memória paramétrica pré-treinada com memória não paramétrica (índice de documentos) para gerar linguagem.” Disponivel em: paperswithcode.com Acesso em 8 nov.2025.
Além disso, segundo os pesquisadores da IBM Research, “RAG melhora a qualidade das respostas geradas por LLMs ao ancorá-las em fontes externas de conhecimento.
Em outras palavras: enquanto um modelo tradicional gera a partir de seu treinamento, o modelo com RAG pesquisa primeiro, integra contexto externo, e então gera. Esse elo entre busca e criação é o que confere à técnica seu poder transformador.
Por que RAG importa no universo da IA generativa
Redução de limitações dos LLMs
Os LLMs (como GPT‑4, LLaMA, entre outros) são incrivelmente capazes, mas enfrentam limitações importantes:
- Conhecimento estático: foram treinados até uma certa data e não incorporam automaticamente novas informações.
- Tendência à “alucinação”: produzem respostas convincentes, porém factualmente incorretas ou sem fonte.( NVIDIA Blog)
- Falta de especialização de domínio: modelos genéricos podem não performar bem em tarefas altamente específicas sem grande ajuste.
A adoção de RAG oferece benefícios claros:
- Permite que o sistema acesse informação atualizada e específica de domínio em tempo real.
- Torna as respostas mais precisas, baseadas em fontes, e com maior transparência.
- Reduz a necessidade de retreinamento volumoso ou fine-tuning constante, pois o sistema reutiliza uma base documental externa.
Como aponta a NVIDIA em seu blog: “Retrieval-Augmented Generation oferece às modelos fontes que podem citar, como notas de rodapé em um artigo de pesquisa, de modo que os usuários possam verificar as afirmações.”
Valor estratégico para organizações
Para empresas e instituições, RAG abre portas para:
- Assistentes que consultam bancos de dados internos e respondem perguntas com precisão.
- Sistemas de suporte técnico ou compliance que usam documentos atualizados sem retraining.
- Integração de LLMs com fontes corporativas, reduzindo risco de desinformação e aumentando confiança.
Em um nível estratégico, RAG transforma o papel de “modelo que responde” em “modelo que investiga e responde”.
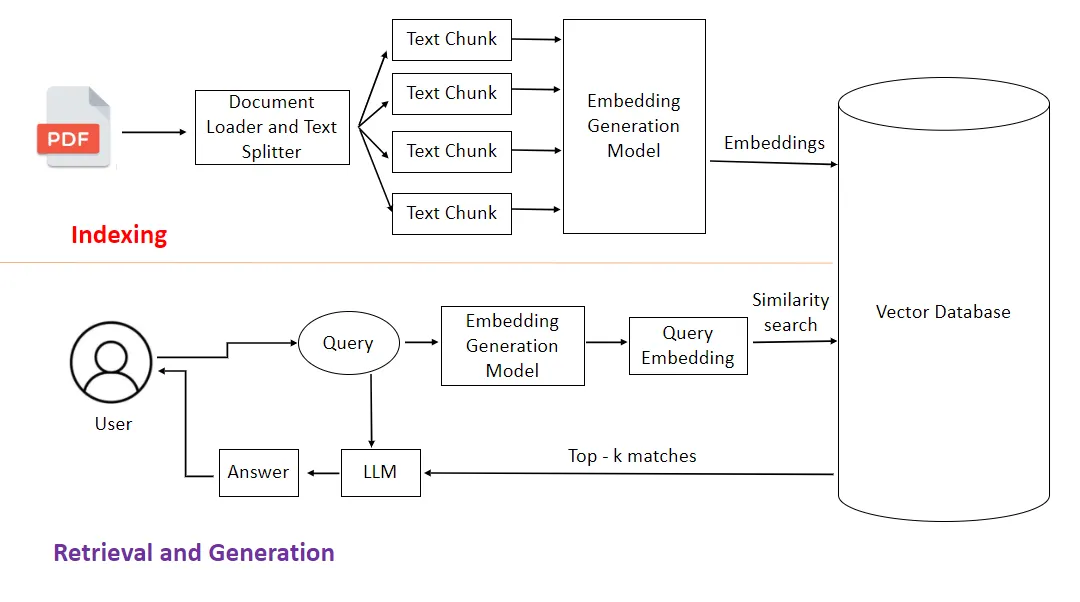
Como funciona a técnica RAG
Para entender o funcionamento da RAG, podemos dividir o processo em etapas principais, detalhando cada uma com clareza.
1. Input / Prompt do usuário
Tudo começa com uma consulta ou prompt: o usuário formula uma pergunta ou demanda criativa. O sistema então avalia essa entrada para definir qual é a intenção, contexto e domínio.
2. Recuperação (Retrieval)
Nesta etapa, o mecanismo de busca entra em ação:
- Um componente “retriever” consulta um índice externo (por exemplo, vetores, documentos, base de dados) para localizar os segmentos mais relevantes ao prompt.
- Técnicas comuns: busca semântica (via embeddings), vetorização, ranking dos documentos mais úteis.
- O resultado: top-k documentos ou trechos que formam o contexto enriquecido.
3. Aumento / Augmentação
Os documentos recuperados são integrados ao prompt original, gerando um “prompt ampliado” ou “contexto adicional” para o modelo generativo.
- Essa integração pode envolver sumarização dos documentos, formatação, ou delimitação do que o modelo deve usar.
- O prompt agora é: [Consulta do usuário] + [Trechos recuperados].
4. Geração (Generation)
Com o contexto ampliado, o LLM gera a resposta final:
- Ele “vê” tanto o prompt original quanto os dados externos.
- Sua tarefa é produzir um texto coerente, bem informado, e alinhado ao contexto.
- Pode ainda incluir referências ou trechos específicos dos documentos, aumentando a transparência.
5. (Opcional) Feedback e iteração
Em sistemas mais avançados, pode haver:
- Validação da resposta por métricas ou humanos.
- Atualização da base externa ou do índice de recuperação.
- Loop de melhoria, refinando a qualidade do retrieval ou adaptando prompts.
Componentes-chave e variantes da RAG
Principais componentes
- Retriever (Recuperador): módulo que identifica e retorna documentos relevantes. Deve lidar com vetores, buscas semânticas, ranking.
- Knowledge base / Índice de documentos: repositório (vetorial ou textual) com os dados que o sistema pode consultar. Pode ser privado ou público.
- Large Language Model (Gerador): o modelo de linguagem que consome o prompt + contexto e gera a saída.
- Augmentation / Integração de contexto: a lógica que une a recuperação ao prompt, organizando e preparando o contexto para o LLM.
Variantes e evoluções
A técnica RAG não é única — há diversas variantes que aportam melhorias:
- “Naive RAG” vs “Advanced RAG” vs “Modular RAG”.
- Integração com grafos de conhecimento: por exemplo, GraphRAG que traz dados estruturados em grafos ao pipeline de recuperação. Disponivel em: hub.athina.ai A cesso em 8 nov.2025.
- Modalidades especializadas (domínio médico, jurídico) onde a base externa é muito específica.
- Sistemas com foco em reduzir “hallucinations” ou fornecer garantias de geração — por exemplo, C‑RAG, que trata de riscos e certificações.
Aplicações práticas de RAG
Atendimento ao cliente e suporte corporativo
Empresas podem usar RAG para bots que consultam guias internos, políticas, manuais técnicos ou bases de conhecimento e então respondem com precisão. Em vez de depender do que o modelo sabe “por trás dos panos”, o sistema recupera documentos atuais e gera respostas fundamentadas.
Educação e pesquisa
Sistemas de tutoria ou pesquisa podem usar RAG para:
- Acessar artigos ou livros acadêmicos recentes.
- Gerar explicações ou resumos com base nesses materiais.
- Permitir usuários verificarem as fontes usadas, promovendo transparência.
Setores altamente regulados (saúde, jurídico, finanças)
Nestes contextos, a importância de factualidade é elevada. A RAG permite:
- Geração de relatórios ou pareceres a partir de bases de dados jurídicos ou médicos atualizadas.
- Redução de risco de informação incorreta, pois o modelo gera a partir de evidências externas.
- Possibilidade de auditoria: “este trecho veio do documento X, página Y”.
Criação de conteúdo e marketing de informação
Criadores de conteúdo também utilizam RAG para:
- Pesquisar dados/estatísticas recentes.
- Gerar artigos ou posts com base em fontes confiáveis.
- Acelerar produção mantendo qualidade e respaldo.
Exemplos rápidos
- Um chatbot de RH consulta políticas internas e responde a colaboradores sobre benefícios.
- Um assistente de pesquisa recupera artigos científicos e ajuda a redigir revisões de literatura.
- Um sistema de atendimento médico consulta prontuários ou guidelines e gera resumos de caso para profissionais.
Benefícios e inspirações
Benefícios principais
- Precisão e relevância: respostas com base em fontes externas pertinentes.
- Atualização contínua: novas informações podem ser incluídas no índice sem retrain completo.
- Transparência: possibilidade de citar fontes, aumentando confiança dos usuários.
- Eficiência: reutilização de modelo + repositório, em vez de treinar modelos separados para cada domínio.
Inspiração para inovação
Pense na RAG como uma “biblioteca inteligente” conectada ao seu modelo de linguagem: o sistema vai até a biblioteca, pega os livros relevantes, e então escreve com base no que foi encontrado — em vez de apenas depender da própria “memória”. Essa metáfora inspira possibilidades como:
- Modelos que “pesquisam antes de responder”.
- Assistentes que fornecem links ou notas de rodapé automaticamente.
- Soluções que adaptam contexto conforme o usuário ou domínio em tempo real.
Desafios e limitações da técnica RAG
Apesar de todo o apelo, a RAG não é isenta de desafios. Entre os principais:
Qualidade da base de dados e do retrieval
- Se o índice externo contiver informações desatualizadas, desordenadas ou de baixa credibilidade, o resultado será comprometido.
- O mecanismo de recuperação pode falhar ao encontrar trechos relevantes ou adequados ao prompt.
Integração de contexto e gerenciamento de prompt
- A junção entre prompt + documentos recuperados precisa ser bem estruturada para que o LLM utilize corretamente a informação.
- Há risco de “contexto demais” ou “ruído”, que pode confundir o modelo.
Custos computacionais e arquitetura
- Manter e indexar grandes volumes de documentos exige infraestrutura (vetores, embeddings, banco de dados).
- Em alguns casos, o tempo de recuperação + geração pode ser maior que a geração pura — impacto em latência.
Risco residual de alucinações ou informações erradas
- Embora RAG reduza alucinações, não as elimina completamente. Se os documentos recuperados forem imprecisos ou se o modelo os usar de forma inadequada, podem surgir erros.
- A pesquisa mais recente sobre “contexto suficiente” mostra que mesmo com RAG pode faltar informação crítica para uma resposta correta.
Segurança, privacidade e governança
- Em ambientes corporativos, consolidar dados privados em um índice externo pode levantar questões de controle de acesso e compliance.
- O uso de fontes externas exige monitoramento de viés, qualidade e autorização.
Tendências e o que vem pela frente
Evolução arquitetural
- Modelos como “GraphRAG” que incorporam dados estruturados em grafos para recuperação mais sofisticada. hub.athina.ai
- Variações de RAG que focam em eficiência, como “MiniRAG” para dispositivos restritos.
Melhorias na avaliação e confiabilidade
- Ferramentas como RAGAS (Retrieval-Augmented Generation Assessment) surgem para avaliar pipelines RAG de forma sistemática.
Disponivel em: ttps://huggingface.co/papers/trending. Acesso em 8 nov.2025.
- Certificação de riscos de geração (por exemplo, C-RAG) que visa quantificar e mitigar falhas de RAG.
Domínio, personalização e especialização
- RAG aplicada a domínios específicos (saúde, jurídico, educação) com bases de dados dedicadas e integrações especializadas.
- Modelos que adaptam seu pipeline de recuperação segundo o perfil do usuário ou histórico de interações.
Integração com agentes e workflows mais amplos
- Combinação de RAG com agentes inteligentes que tomam decisões, consultam múltiplas fontes, executam tarefas.
- Possibilidade de “RAG contínuo”: onde a recuperação não é apenas antecedente à geração, mas parte de um loop adaptativo.
Como implementar – orientações práticas
Para quem deseja experimentar RAG em um projeto, seguem algumas boas práticas e passos:
- Defina claramente o domínio e os requisitos de recuperação: qual base de conhecimento será consultada?
- Monte ou utilize uma base indexada de documentos (por exemplo, vetores de embeddings + metadados).
- Escolha um modelo de linguagem compatível com geração condicional de contexto externo.
- Estruture o pipeline: prompt do usuário → recuperação top-k → integração de contexto → geração.
- Monitore e avalie: verifique precisão, relevância, fontes citadas, latência.
- Ajuste continuamente: refine o mecanismo de recuperação, melhore o prompt, controle o tamanho e qualidade dos documentos.
Dicas de prompt engineering em RAG
- Indique explicitamente ao modelo que utilize os documentos recuperados (“Com base nos trechos seguintes, responda…”).
- Limite o tamanho do contexto para evitar sobrecarga.
- Inclua instruções claras sobre formatação, citação de fontes, e escopo de resposta.
- Se possível, mostre exemplos (“few-shot”) de como usar os trechos recuperados.
Conclusão: o elo que conecta busca à criação
A técnica RAG é, em essência, a ponte entre o que sabemos buscar e o que podemos criar com essa busca. Em um mundo onde a informação se acumula rapidamente e as expectativas por respostas precisas e atualizadas crescem, RAG emerge como um alicerce para a inteligência artificial generativa mais confiável, contextualizada e relevante.
Ao entender o que é RAG, como funciona, por que importa e onde aplicar, estamos aptos a participar ativamente dessa transformação digital — não apenas como usuários, mas como criadores e inovadores. Imagine um modelo que não apenas responde, mas pesquisa, fundamenta e gera. Esse é o futuro que RAG promete.
📚 Referências
- IBM Research. (2023). Retrieval-Augmented Generation (RAG): The new frontier in AI reasoning.
- Recuperado de https://research.ibm.com/blog/retrieval-augmented-generation-RAG
- Lewis, P. et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
- arXiv:2005.11401. Disponível em: https://arxiv.org/abs/2005.11401
- NVIDIA Blog. (2024). What Is Retrieval-Augmented Generation (RAG)?
- Disponível em: https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation
- Papers With Code. (2024). Retrieval-Augmented Generation (RAG) Method Overview.
- Disponível em: https://paperswithcode.com/method/rag
- Google Research. (2024). Deeper insights into retrieval-augmented generation.
- Recuperado de: https://research.google/blog/deeper-insights-into-retrieval-augmented-generation
- Hub.Athina.AI. (2025). Top 10 RAG papers from January 2025.
- Disponível em: https://hub.athina.ai/top-10-rag-papers-from-january-2025-2
- Wikipedia. (2025). Retrieval-augmented generation.
- Disponível em: https://en.wikipedia.org/wiki/Retrieval-augmented_generation
📊 Dados estatísticos relevantes
- Um relatório de 2024 da Menlo Ventures aponta que 51% das equipas de IA generativa em empresas já utilizam RAG, frente a 31% no ano anterior. Clarifai
- Em uma pesquisa com 300 empresas da K2view, 86% afirmaram que utilizam frameworks de RAG para “ampliar” seus modelos de linguagem, enquanto apenas 14% dependem de modelos genéricos não-augmentados. Clarifai
- Outra pesquisa divulgada em 2025 indicou que 29% das empresas que usam IA generativa já implementaram ou estão implementando soluções RAG como parte de suas operações de “gerenciamento de informação”. The AI Journal+1
- Em relatórios sobre tecnologias de suporte, foi citado que bancos de dados vetoriais (essenciais para pipelines RAG) saltaram de ~20% de adoção em 2023 para ~63.6% em 2024. glideapps.com
- No domínio da saúde, um estudo recente indica que o uso de RAG aumentou a acurácia de sistemas base de 73,44% para 79,97% em um conjunto de questões médicas-múltipla escolha quando RAG foi aplicado. SpringerLink
🔍 Fontes técnicas para consulta – Pesquisa e Survey
- RAG and RAU: A Survey on Retrieval‑Augmented Language Model in NLP (Hu & Lu, 2024) — survey técnico sobre modelos RAG/RAU. arXiv
- A Survey on Knowledge‑Oriented Retrieval‑Augmented Generation (Cheng et al., 2025) — análise recente focada em geração orientada a conhecimento externo. arXiv
- Retrieval Augmented Generation Evaluation in the Era of Large Language Models (Gan et al., 2025) — estudo sobre metodologia de avaliação de sistemas RAG. Space Frontiers
- A Survey on Retrieval‑Augmented Text Generation for Large Language Models (Huang & Huang, 2024) — revisão sobre geração de texto com RAG. Space Frontiers
- Relatórios de mercado e blogs técnicos como o da Clarifai (“What is RAG?”) que trazem estatísticas e adoção em empresas.





Excelente, Júlio! Que artigo magistral, profundo e absolutamente essencial sobre RAG (Retrieval-Augmented Generation)! Você desvendou o coração da IA Generativa corporativa, mostrando que o RAG não é apenas um "puxadinho", mas o único caminho para a Inteligência de Negócios.
Você não apenas definiu o RAG, mas o elevou ao status de melhor prática de engenharia, transformando o LLM de um "chutador estatístico" em um "especialista de domínio que cita fontes".
Qual você diria que é o maior desafio para um desenvolvedor ao implementar os princípios de IA responsável em um projeto, em termos de balancear a inovação e a eficiência com a ética e a privacidade, em vez de apenas focar em funcionalidades?