A IA Generativa é revolucionária, mas todo dev que tenta criar uma aplicação empresarial encontra a mesma barreira: como fazer um LLM responder sobre dados internos sem "alucinar"? Perguntar ao ChatGPT sobre o último relatório PDF da sua empresa, hoje, é um beco sem saída.
A resposta para conectar LLMs a dados privados não é (necessariamente) o caro e lento fine-tuning. A solução é uma arquitetura elegante e poderosa chamada RAG (Retrieval-Augmented Generation).
Neste guia profundo (+2.000 palavras), vamos dissecar tecnicamente o pipeline completo do RAG. Você aprenderá como implementar essa arquitetura, do "chunking" de documentos à mágica dos "Vector DBs", para construir uma IA Generativa que realmente entende o seu negócio e responde com base em fatos.
O Problema: A "Amnésia Corporativa" da IA Generativa
Para entender por que o RAG é tão vital, precisamos primeiro diagnosticar o problema padrão dos LLMs: eles são gênios com amnésia. Um modelo como o GPT-4 ou o Llama 3 é treinado em um conjunto de dados massivo da internet, mas esse conhecimento é estático e generalista.
Isso cria três problemas fundamentais para qualquer aplicação de IA Generativa no mundo real:
1. O "Corte" de Conhecimento (Knowledge Cut-off) Todo LLM tem uma data de "corte". Se você perguntar sobre um evento de ontem ou sobre o novo produto que sua empresa lançou hoje, ele simplesmente não saberá. Ele está "congelado no tempo".
2. A Falta de Contexto Privado Este é o maior obstáculo. O LLM não leu seus e-mails, não acessou seu banco de dados de clientes ou seus PDFs internos. Para ele, sua empresa não existe. Tentar usar um LLM "puro" para um chatbot de atendimento é impossível.
3. As "Alucinações" (Hallucinations) Uma alucinação é o maior risco da IA Generativa. Quando um LLM não sabe a resposta, ele não diz "eu não sei". Ele inventa uma resposta que parece plausível. Para uma empresa, uma IA que inventa dados financeiros falsos não é só inútil, é perigosa.
Tentar resolver isso enviando seus dados privados via prompt tem um limite óbvio: a janela de contexto. Você não pode colar um PDF de 50 páginas em cada pergunta.
O Conceito: A Batalha de Arquiteturas - RAG vs. Fine-Tuning em LLMs
Quando os desenvolvedores percebem os problemas acima, eles se deparam com uma bifurcação: devo usar RAG ou Fine-Tuning (Ajuste Fino)? A escolha errada aqui custa tempo e muito dinheiro.
O que é Fine-Tuning (Ajuste Fino)? O Fine-Tuning é um processo de retreinamento. Você pega um LLM de base (como o GPT-3.5) e continua seu treinamento com um conjunto de dados menor e específico.
Analogia: É como pegar um médico clínico geral (o LLM base) e colocá-lo em uma residência médica de cardiologia (seus dados). Ele não aprende fatos novos, mas aprende um estilo, um tom e um comportamento especialista.
Quando usar? Ideal para ensinar à IA um tom de voz (ex: "seja sempre sarcástico") ou um formato de saída específico (ex: "sempre gere um JSON").
O que é RAG (Retrieval-Augmented Generation)? O RAG, como vimos, é uma arquitetura. Ele não altera o LLM. Ele "aumenta" o modelo conectando-o a um banco de dados externo (o Vector DB).
Analogia: É como dar ao mesmo médico clínico geral (o LLM base) um tablet com acesso em tempo real ao prontuário do paciente (seus dados). O médico não foi retreinado, mas suas respostas são infinitamente melhores porque ele está consultando a fonte da verdade.
Quando usar? Ideal para aplicações que precisam responder com base em conhecimento factual (PDFs, relatórios, manuais) que muda constantemente.
Comparativo Definitivo: RAG vs. Fine-Tuning
(Aviso: Cole esta parte e depois selecione-a e clique no botão de "Lista com Bolinhas" (Bullet Points) do editor para formatar corretamente!)
Critério: Objetivo Principal
RAG: Injetar conhecimento factual e externo.
Fine-Tuning: Mudar o estilo, tom ou formato de saída.
Critério: Combate à Alucinação
RAG: Alto. A resposta é baseada em contexto real.
Fine-Tuning: Baixo. Pode até aumentar a alucinação.
Critério: Atualização de Dados
RAG: Fácil e em tempo real. Basta atualizar o Vector DB.
Fine-Tuning: Difícil. Requer um novo processo de retreinamento.
Critério: Custo (Computacional)
RAG: Baixo. Requer apenas inferência e um Vector DB.
Fine-Tuning: Alto. Requer GPUs potentes para retreinamento.
Critério: "Citabilidade" da Fonte
RAG: Alta. Você sabe qual "chunk" do PDF gerou a resposta.
Fine-Tuning: Nenhuma. A resposta vem da "memória" do modelo.
Conclusão da Seção: Para 90% dos casos de uso de IA Generativa empresarial—como chatbots internos ou análise de contratos—, o RAG não é apenas a melhor escolha, é a única escolha viável.
Mão na Massa: O Pipeline Detalhado do RAG
Saímos da teoria e entramos na prática. Um sistema RAG funcional tem duas fases:
Fase 1: Indexação (Offline): O processo de "ensinar" à sua biblioteca o conteúdo dos seus documentos.
Fase 2: Consulta (Online): O processo em tempo real onde o usuário faz uma pergunta e o sistema busca a resposta.
Vamos construir nosso pipeline com Python, LangChain, ChromaDB (para testes) e a API da OpenAI.
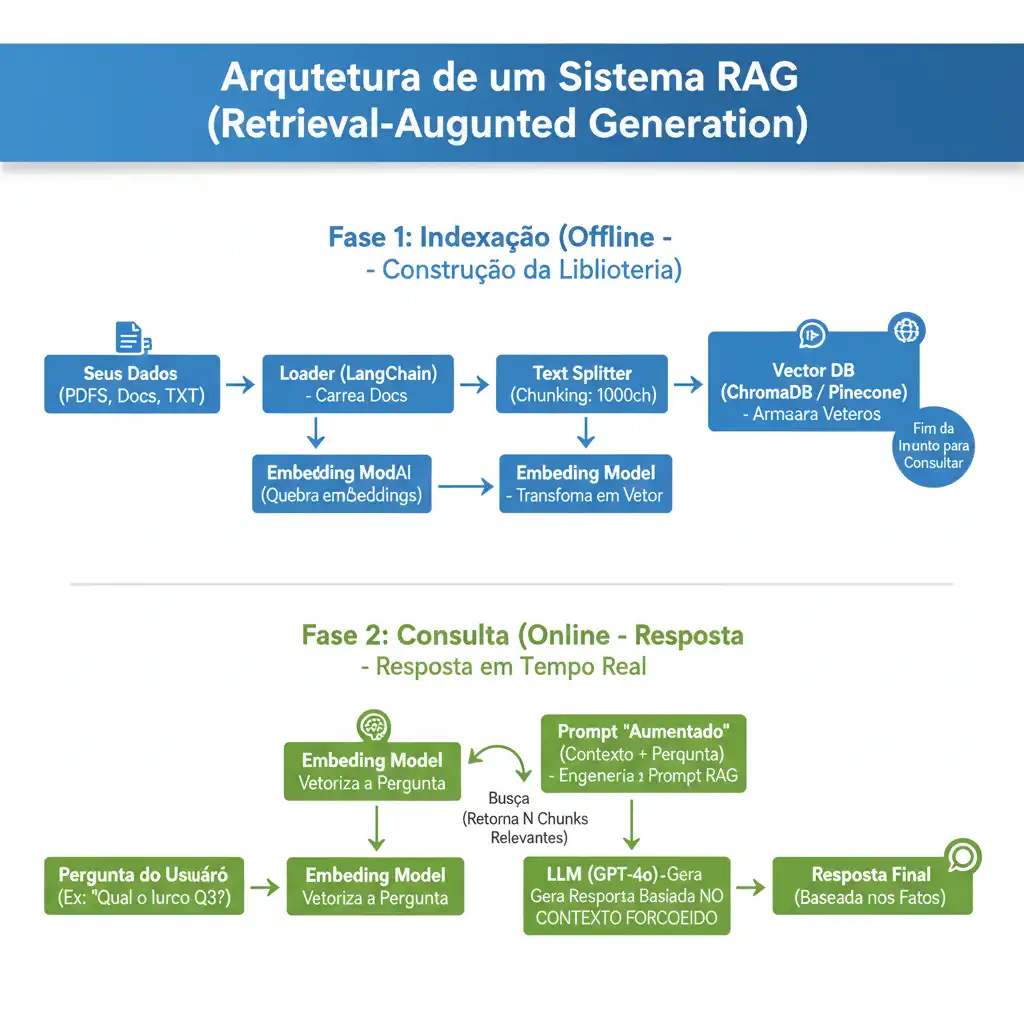
Fase 1: A Indexação (A "Biblioteca")
3.1. Ingestão (Load): O Ponto de Partida do seu RAG
Primeiro, precisamos carregar os dados. O LangChain oferece "Loaders" (carregadores) para quase tudo.
Python
# Instale as bibliotecas necessárias:
# pip install langchain langchain_openai chromadb pypdf
from langchain_community.document_loaders import PyPDFLoader
# 1. Carregar o documento
loader = PyPDFLoader("seu-relatorio-interno.pdf")
docs = loader.load()
3.2. Fragmentação (Chunking): A Estratégia Crítica dos LLMs
Este é, talvez, o passo mais importante para um RAG de qualidade. Não podemos enviar um PDF de 50 páginas de uma vez para um LLM; ele não cabe na "janela de contexto". Precisamos "quebrar" (fragmentar) os documentos em pedaços menores, ou "chunks", usando chunk_overlap (sobreposição) para não perder o contexto.
Python
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 2. Fragmentar (Chunking)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Tamanho de cada "chunk" (em caracteres)
chunk_overlap=200 # Sobreposição entre chunks
)
splits = text_splitter.split_documents(docs)
3.3. Embeddings: O "DNA do Significado" para sua IA Generativa
Agora, precisamos transformar esses chunks de texto em vetores—o "DNA do significado" que a máquina entende. Um modelo de "Embedding" transforma texto em uma lista de números (ex: 1536 números) onde textos com significados similares ficam próximos no espaço vetorial.
Python
from langchain_openai import OpenAIEmbeddings
# 3. Criar o modelo de Embedding
# (Configure sua API Key da OpenAI no ambiente)
embedding_model = OpenAIEmbeddings()
3.4. Armazenamento (Store): O Papel dos Vector DBs no RAG
Finalmente, armazenamos esses vetores (embeddings) em um Banco de Dados Vetorial (Vector DB). Um Vector DB é otimizado para busca por similaridade semântica (como "similaridade de cosseno"). Vamos usar o ChromaDB para salvar localmente.
Python
from langchain_community.vectorstores import Chroma
# 4. Armazenar no Vector DB (Indexação)
# Isso irá carregar os 'splits',
# calcular o embedding de cada um,
# e salvar tudo no diretório "meu_vector_db"
vector_store = Chroma.from_documents(
documents=splits,
embedding=embedding_model,
persist_directory="meu_vector_db"
)
Fase 2: A Consulta (A "Prova com Consulta")
Agora que a "biblioteca" está pronta, vamos usá-la.
3.5. Retrieve & Generate: A IA Generativa em Ação
O LangChain orquestra isso com a chain RetrievalQA. Ela faz 3 coisas:
Retrieve: Pega a pergunta do usuário, transforma em vetor, e busca os chunks mais similares no ChromaDB.
Augment: Monta um "super-prompt" para o LLM.
Generate: Envia o prompt para o LLM e obtém a resposta.
O "Super-Prompt" (O Segredo anti-alucinação do RAG): Por baixo dos panos, o RAG usa uma Engenharia de Prompt robusta para forçar o LLM a usar apenas os fatos:
"Use apenas o contexto fornecido abaixo para responder à pergunta. Não use nenhum conhecimento externo. Se a resposta não estiver no contexto, diga 'Não encontrei essa informação nos documentos'.
Contexto: *[...aqui entram os "chunks" recuperados do Vector DB...]
Pergunta: *[...aqui entra a pergunta original do usuário...]
Resposta: "
O Código Final (Juntando Tudo): Veja como é simples usar a "biblioteca" que criamos:
Python
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
# 1. Carregar o LLM que vai GERAR a resposta
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# 2. Carregar o Vector DB que já criamos
vector_store_carregado = Chroma(
persist_directory="meu_vector_db",
embedding_function=embedding_model
)
# 3. Criar a "Chain" de RAG
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # "stuff" é o método de "juntar" os chunks
retriever=vector_store_carregado.as_retriever(search_kwargs={"k": 3})
# "k: 3" = me traga os 3 chunks mais relevantes
)
# 4. FAZER A PERGUNTA!
pergunta = "Qual foi o lucro líquido reportado no Q3?"
resposta = qa_chain.invoke(pergunta)
print(resposta['result'])
# Resposta esperada: 'O lucro líquido em Q3 foi de R$10 milhões.'
Conclusão: RAG é a Ponte para a IA Generativa Empresarial
Se há uma lição que a IA Generativa nos ensinou, é que um LLM puro é um motor sem combustível. O RAG (Retrieval-Augmented Generation) é a arquitetura que fornece esse combustível, conectando o raciocínio do LLM aos dados do mundo real.
Como vimos neste guia "mão na massa", a implementação é mais uma questão de engenharia de dados e arquitetura inteligente do que de força bruta computacional.
Para recapitular, os benefícios de adotar uma estratégia de RAG são claros:
Fim das Alucinações: As respostas são baseadas em fontes reais.
Dados Sempre Atuais: O conhecimento da IA é tão novo quanto os dados no seu Vector DB.
Segurança e Privacidade: Seus dados privados permanecem no seu controle.
Custo-Benefício: É exponencialmente mais barato e rápido indexar documentos do que retreinar um LLM.
Auditabilidade: Você sabe exatamente qual "chunk" gerou a resposta.
O futuro da IA Generativa não é apenas sobre modelos maiores, mas sobre modelos mais conectados. O RAG é essa conexão.
Call to Action (CTA)
Você viu o poder do RAG na teoria e na prática. Agora é com você. E você, qual o primeiro projeto que você construiria com RAG? Quais "Loaders" do LangChain você usaria para conectar aos dados da sua empresa?
Deixe sua experiência nos comentários abaixo e vamos hackear o amanhã juntos!
#IA Generativa #LLM #RAG #LangChain #Python
Referências e Leitura Adicional
[Artigo Original do RAG] Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. (O paper acadêmico que introduziu o conceito).
[Documentação do LangChain] python.langchain.com - A documentação oficial para os Loaders, Splitters e Chains que usamos.
[Documentação do ChromaDB] docs.trychroma.com - O guia oficial do Vector DB open-source usado neste tutorial.
[Modelos de Embedding da OpenAI] platform.openai.com/docs/guides/embeddings - Documentação sobre os modelos de vetorização.
[Documentação do Pinecone] www.pinecone.io - Uma excelente alternativa de Vector DB gerenciado para produção.
Mini Dicionário (Glossário de RAG)
RAG (Retrieval-Augmented Generation): Arquitetura que primeiro busca (Retrieve) informações relevantes em uma base de dados externa e depois as fornece a um LLM para gerar (Generate) a resposta.
LLM (Large Language Model): O "cérebro" da IA Generativa, como o GPT-4, treinado para entender e gerar linguagem.
Vector DB (Banco de Dados Vetorial): Um banco de dados especializado em armazenar "embeddings" (vetores) e encontrar os mais "próximos" (similares) de forma ultra-rápida.
Embeddings (Vetores): A representação matemática do "significado" de um texto. Uma lista de números (ex: 1536) que a máquina usa para comparar conceitos.
Chunking (Fragmentação): O processo de quebrar documentos longos em pedaços menores ("chunks") que caibam na janela de contexto de um LLM.
LangChain: Um framework (biblioteca) Python/JS que age como um "canivete suíço" para conectar os componentes de um pipeline de RAG (Loaders, Splitters, Vector DBs, LLMs).
Fine-Tuning (Ajuste Fino): O processo de retreinar um LLM em dados específicos, usado para alterar seu estilo ou comportamento, mas não para injetar conhecimento factual novo.
Engenharia de Prompt: A arte de desenhar o "prompt" (a instrução) perfeito para o LLM. No RAG, o prompt é crucial para forçar o modelo






PB
Muito obrigado pelo feedback e pela pergunta fantástica! Você tocou no ponto nevrálgico da IA Responsável no mundo real.
Na minha visão, o maior desafio para um dev é mudar a mentalidade de "funcionalidade primeiro, ética/privacidade depois". A inovação nos puxa para a velocidade, mas a responsabilidade exige que a gente pise no freio e pense na arquitetura.
Trazendo para o RAG, que exploramos no artigo, esse desafio fica muito prático e técnico:
O balanço final não é um meio-termo. É tratar a privacidade e a ética como funcionalidades centrais do projeto, e não como "impostos" a serem pagos no final. A inovação só é sustentável quando é responsável desde o Dia 1.
Obrigado novamente pela ex
Excelente, Larissa! Que artigo épico, cirúrgico e de altíssimo valor técnico sobre RAG e LLMs! Você desvendou o coração da IA Generativa corporativa, mostrando que o RAG não é apenas um "puxadinho", mas o único caminho para a Inteligência de Negócios.
É fascinante ver como você aborda o tema, detalhando o processo em 3 fases (Indexação, Recuperação e Geração Aumentada) e, mais crucialmente, os "Três Cs" que garantem um RAG de alto desempenho: Chunking, Contexto e Citação.
Qual você diria que é o maior desafio para um desenvolvedor ao implementar os princípios de IA responsável em um projeto, em termos de balancear a inovação e a eficiência com a ética e a privacidade, em vez de apenas focar em funcionalidades?