

Reduzindo 31 horas de workload para 12 minutos: Web scraping paralelizado pela AWS.
Ultimamente, eu venho procurando evoluir conceitos relacionados a engenharia de Software e computação no geral, conforme eu vou vivendo minha vida, acabo me deparando com conceitos, objetos, situações, problemas e questões que me fazem enxergar novas formas de me comunicar com um computador. Atualmente, eu venho desenvolvendo um projeto relacionado a ciclo de engenharia de dados e software e eu me deparei em um Scraping de duas etapas de mais de 3000 empresas:
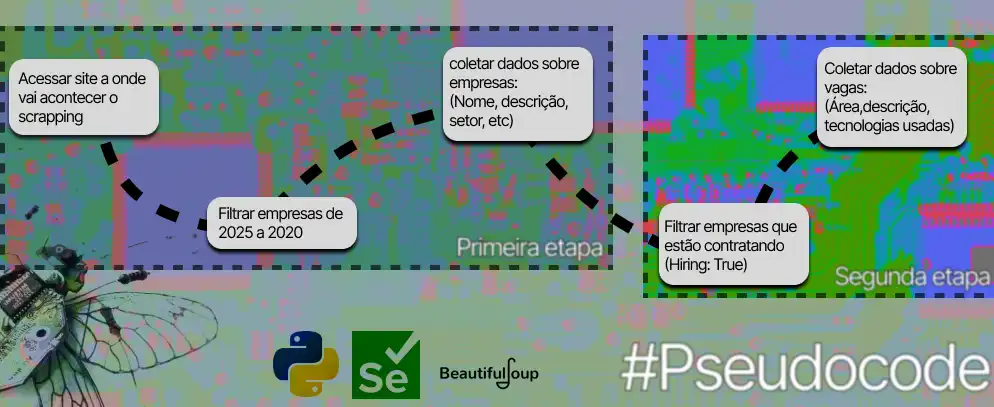 Problemas e soluções
Problemas e soluções
A primeira etapa foi tranquila, consegui acessar os dados via Fetch utilizando DevTools, foram:
- 3440 empresas listadas na primeira etapa
- 1140 empresas com o filtro da segunda etapa
Porém, enquanto na primeira etapa foi utilizado Fetch, a segunda era feita por renderização do site, ou seja, eu não acessava os dados por uma API e sim acessava pelo HTML da página, dentro destas 1140 empresas, existiam N vagas de empregos relacionadas. Rodando um script básico, com empresas que possuíam apenas UMA vaga, demorava por volta de 70 segundos para:
- meu script abrir
- ele iniciar o navegador
- ele pegar as vagas e salvar
a cada acréscimo de vaga são por volta de 15 segundos a mais
a formula então é:
Segundos = (Nº de empresas x Segundos script ) + (Vagas adicionais x acréscimo de segundos)

eu iria necessitar utilizar o meu PC por 31 horas ininterruptas, talvez eu até poderia utilizar o meu computador, mas isso definitivamente iria fazer com que o meu workload demorasse além dessas 31 horas, também existem outros problemas relacionados a este approach (e se a minha energia acabasse, ou por algum motivo meu pc desligasse?). vendo esse problema, encontrei uma solução simples e eficaz. Utilizar uma arquitetura serverless na AWS, basicamente:
Paralelismo, serviços em nuvem e a solução de meus problemas
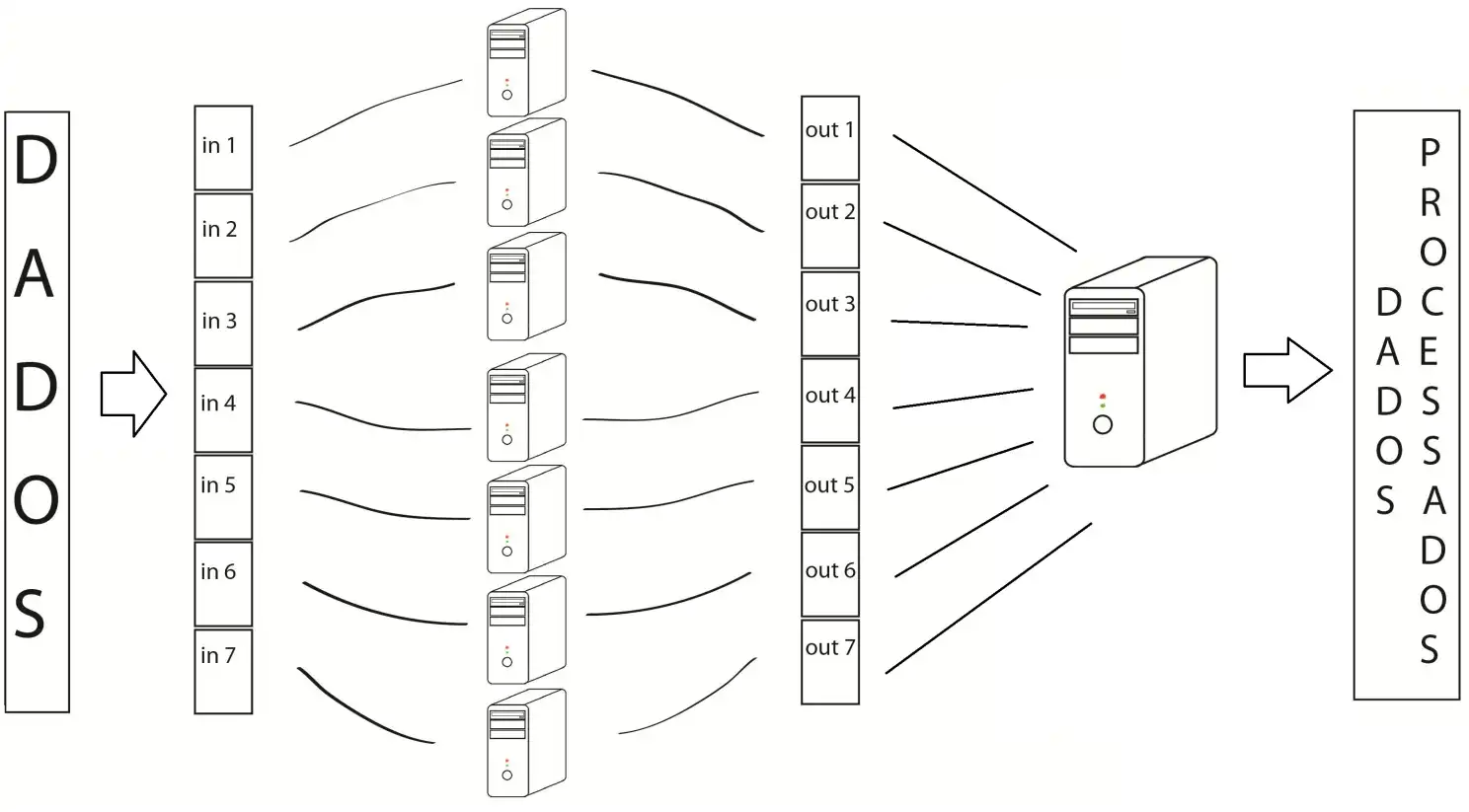
Existiam duas questões nessa minha ideia de utilizar a nuvem pra resolver o meu problema:
- Qual arquitetura utilizar?
- Como fazer isso sem nenhum gasto? (Eu estou desempregado ;P)
Paralelismo
é um conceito bastante atribuído a processamento de dados, basicamente você separa o seu esforço computacional em micro partes para rodarem em conjunto, o AWS Lambda cuidava de cada empresa de forma simultânea, então ao invés de eu estar utilizando poder computacional de um computador 1 por vez, eu acabei utilizando, teoricamente, 155 computadores!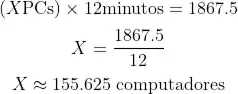
Com o paralelismo, o tempo total caiu de 31h para cerca de 12 minutos.
Custos
a outra questão era se isso é viável na AWS, por sorte, Free tiers da AWS são bem generosos para projetos de pequeno porte (seja educacional ou empresarial.)
- 1 MILHÃO de requisições na Lambda (fiz 1140)
- 1 Milhão de entidades na queue do SQS (fiz 1140)
- 2000 requisições REST + 5 GB de armazenamento (fiz 1140 requisições + 10mb de .json
tirando o fato de fazer 1140 POSTS (metade das requisições), toda a usabilidade foi bem simples e estes valores são mensais, ou seja, todo mês você pode repetir estes valores citados acima (tirando o 5GB de armazenamento).
Você que está lendo isso, eu aconselho fortemente você aproveitar esses tipos de serviços!
Conclusão
O fato de eu escrever isso é para engajar você leitor, a pensar em formas diferentes para resolver problemas do nosso dia a dia. Trade-offs são muitos discutidos em termos de engenharia de software, e no momento atual em que vivemos existem diversas abordagens que são simples, porém que possam resolver grandes problemas, parece que existe algo em minha vida que procura demonstrar que Less = More. Quanto mais eu estudo mais eu percebo que qualquer tipo de over engineering por muitas vezes não fazem sentido, não creio que abordagens mais técnicas devem ser descartadas, mas a habilidade de você determinar problemas com exatidão, sabendo separar do simples ao complexo é extremamente valioso.
Por fim, deixo um video do Augusto Galego abordando sobre simplicidade em engenharia de software, e também um repositório sobre como eu enviei entidades para o Simple Queue Service da AWS!
Meu LinkedIn (vamos se conectar!)
:)






É o que eu sempre digo, João!
As IAs, clouds etc nos ajudam muito, mas às vezes são quase impotentes se não tem uma mente brilhante por trás como a sua.
É uma injustiça que alguém com esses talentos como você não esteja empregado.
Quanto à AWS (e até outras clouds), me pergunto como você conseguiu utilizar o Free tiers da AWS sem nehum custo, pois quando fiz, pra fazer alguns bootcamps aqui na DIO, a AWS me cobrou sem eu estar utilizando nada, pois eu ainda estava projetando as coisas e organizando no Notion como seria a utilização do Free tiers da AWS em cada Bootcamp.
Então desisti de vários bootcamps da Dio que envolvam Cloud exatamente por essa frustração, pois também estou desempregado. Se você puder me dizer em uma msg restrita no meu linkedin como fez pra conseguir não ser de fato cobrado na AWS eu te agradeceria demais. Acho que nem artigo detalhado sobre esse assunto "Free tiers" (Seja de qual cloud for) existe aqui na DIO (se souber de algum me avisa, ou então até te encorajo a escrever um... rsrsr). Ainda não sou universitário, mas se fosse talvez facilitasse esse lado de poder utilizar as clouds de forma mais barata ou gratuita...
Parabéns por este excelente artigo e parabéns atrasado pelo dia dos professores, porque te considero um!
Abraço e excelente fds!
Minhas redes:
🔗Linkedin
😼Github
Excelente, João! Que artigo incrível e super completo sobre Web Scraping Paralelizado pela AWS! É fascinante ver como você aborda o tema, mostrando que a engenharia de software não é apenas sobre coding, mas sobre resolução de problemas e visão de arquitetura para otimizar workloads complexos.
Qual você diria que é o maior desafio para um desenvolvedor ao utilizar uma ferramenta de IA generativa (como o ChatGPT ou o Gemini) em seu workflow, em termos de confiança e de segurança (já que a IA pode gerar código com bugs ou vulnerabilidades), em vez de apenas focar em fazer o software funcionar?