

Tarefas simples, porém chatas e programação como uma mão amiga
- #Flask
- #Automação
- #Python
- #REST
- #JavaScript
Uma realidade comum é a dificuldade em administrar o tempo entre suas diferentes necessidades - estudos, trabalho, afazeres, família e afins tendem a conflitar no cotidiano - e por isso muitas áreas acabam por não terem a atenção devida. E por muitas vezes, infelizmente o estudo tem de ser deixado de lado.
Para alguém que trabalha e tem outros afazeres, estudar pode ter de ser posto em segundo plano; sendo até mesmo comum pessoas não tendo tempo para estudar uma linguagem de programação, por exemplo, para ter de estudar outro assunto que esteja em uma prioridade maior no curto prazo. Por isso, é necessário certo jogo de cintura para lidar com as adversidades.
Por isso, com certa petulância no uso dos termos, uma solução inteligente seria aplicar a utilidade do que é estudado ao dia a dia.

Demandas ou oportunidades?
É utópico imaginar que essa é uma oportunidade fácil de ser seguida, a realidade tende a lembrar que a facilidade e conforto são a exceção; porém, quando possível implementar esse pensamento no cotidiano, bons frutos podem ser colhidos no longo prazo. É evidente que possibilidades estão a todo o momento surgindo e padecendo e muitos não a percebem: várias pessoas estudam dados e nem consideram usar seus conhecimentos para no tempo livre analisar seu trabalho (dados e informações são jogadas a todo momento) e tarefas a todo momento surgem e podem ser automatizadas.
Houve a necessidade de se baixar um arquivo que estava disponível no site https://archive.org (um arquivo legal, obviamente). Baixar o arquivo não passou de uma tarefa banal: procurar o repositório adequado, escolher a forma de download e terminar a operação para baixar o arquivo desejado.
Isso por si apenas, não exige ou justifica nenhum algoritmo para automatizar essa operação, porém uma ferramenta auxiliadora é útil quando outras variáveis são postas junto à equação. Suponhamos que essa seja uma tarefa que deva ser repetida mais de uma vez, agora temos novas questões a serem consideradas:
- A tarefa de se achar um repositório adequado se torna mais cansativa, agora é necessário buscar fontes adequadas que devem ser analisadas a partir de variáveis qualitativas e quantitativas.
- Verificar os links listados para download.
- Analisar e escolher a opção que melhor se adequa à necessidade.
Fora isso, também é necessário entender diversos outros detalhes: muita informação é disposta de uma só vez no site, muitas distrações, e etc.
Nesse caso, uma oportunidade
Os problemas foram mapeados, e agora, uma necessidade foi posta para forçar uma oportunidade. Para não ser muito abstrato, é possível se dizer que foi feita uma simulação, o tomemos como um estudo de caso, e foi imaginada uma solução para ela. Nesse caso, foi feita da seguinte forma:
- Problemática:
A repetição da tarefa simples supracitada se tornava mais difícil, muito por conta da poluição visual e alta exposição às informações mais diversas.
- Solução imaginada (lembrando que foi feita para fins de estudo):
A partir da URL da página, trazer os links de forma mais limpa para o usuário.
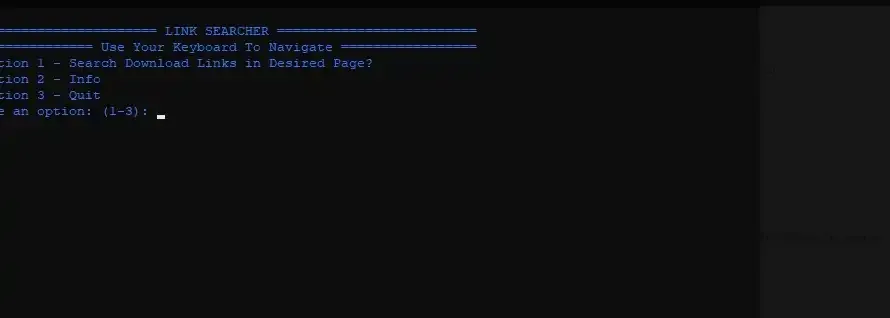
E pronto, uma ideia surgiu! de início, apenas como um passa tempo. Fiz um projeto extremamente simples orientado à linha de comanda e free-software:
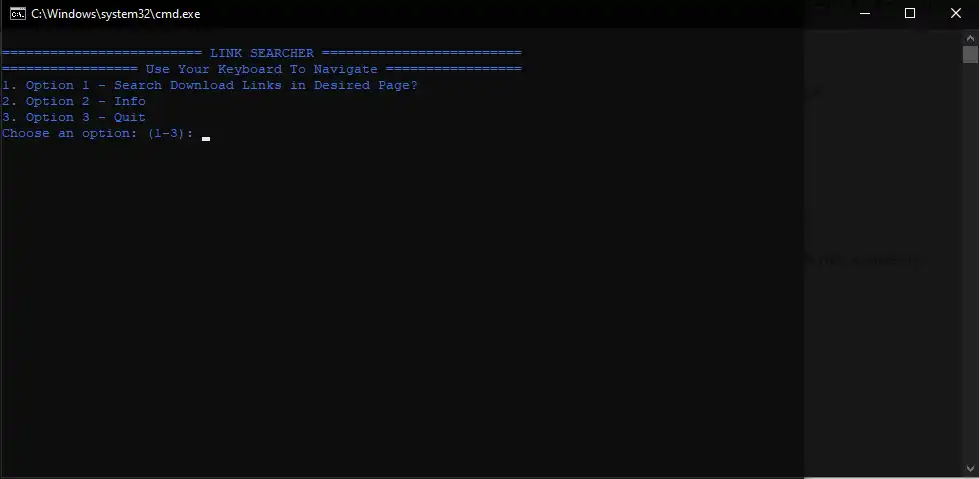
Seu funcionamento era simples e se baseava em executar o algoritmo, escolher e opção e informar o URL da página. Após isso os links eram retornados, então bastava selecioná-los que eles fariam download automaticamente.
Repositório desse código disponível em https://github.com/Dum2601/LINK-SEARCHER-archive.org-.git
Com ele, foi possível consolidar conhecimentos que antes apenas eram repetidos em teoria (bibliotecas, análise de paginas, requisições API e mais). Então o código ficou um tempo parado, porém com a promessa de melhora. Essa promessa foi cumprida após o início dos estudos em bibliotecas que permitiam comunicação com o front-end.
O funcionamento era o mesmo, porém agora eram divididos em rotas que eram enviadas ao front-end; o front-end por sua vez foi feito de forma simples com HTML para a marcação e Javascript para o consumo da API criada em Python e algumas funcionalidades da página e um CSS simples.
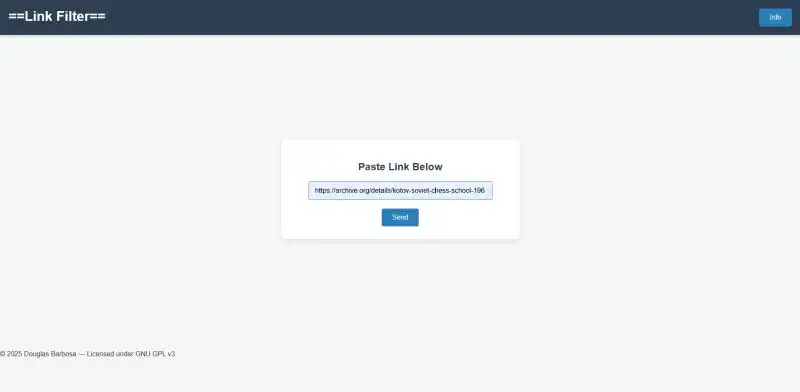
Programa disponível em https://github.com/Dum2601/archive.org_searcher.git
Então com uma simples "necessidade" em aprimorar um défit humano, um pequeno projeto teve um rascunho postado. E não veja isso apenas como um simples projeto, há mais por trás: uma base a se partir, um código para a comunidade, algo para o portfólio.
Perceba na imagem algumas questões a serem resolvidas: CSS "cru", funcionalidades a se implementar, acesso apenas a partir de execução manual...
Isso, na data da publicação (09/09/2025), ainda está presente. O projeto foi apenas algo rápido para evoluir, porém não é algo que vá parar por agora, porém também não sozinho: é encorajada a contribuição (melhorias visuais, implementações para desktop, bibliotecas e afins...).
Enfim...
Um simples questionamento levou a um desenvolvedor que está iniciando projetos mais profundos a conseguir trazer melhoria em uma tarefa repetitiva, ao mesmo tempo em que trás para si melhorias em seus conhecimentos. Com isso, é possível perceber que momentos, muitas vezes como triviais, podem ser de grande utilizada quando aproveitados.





Douglas, adorei acompanhar a forma como você transformou uma tarefa repetitiva e “simples” em uma oportunidade de aprendizado e automação. Seu relato mostra de forma clara como curiosidade, criatividade prática e aplicação do conhecimento teórico podem se unir para gerar soluções úteis, mesmo em pequenos projetos. Gostei particularmente de como você destacou a evolução do projeto: de uma linha de comando básica para uma API em Python com front-end em HTML/JS, tornando a ferramenta mais funcional e acessível.
Na DIO valorizamos histórias assim, que conectam estudo, prática e portfólio. O trecho em que você comenta sobre transformar um problema trivial em aprendizado consolidado e código para a comunidade resume perfeitamente o impacto que pequenos projetos podem ter na formação de um desenvolvedor.
Me conta: olhando para frente, você pretende expandir o projeto com novas funcionalidades e automações ou usar essa experiência como base para explorar novos tipos de integração com dados e front-end?