

Visualização de Dados com Python
Olá, dev!
A Ciência de Dados é uma área que tem crescido muito nestes últimos anos, resultado da enorme gama de dados que geramos diariamente.
Uma das formas de apresentar estes dados é por meio de gráficos, que resumem toda a informação de uma análise em uma figura.
Este artigo trata da visualização de dados, focando na sua geração pela linguagem Python, muito popular na área de Ciência de Dados.
Sumário
1. Introdução
2. Ciência de Dados
3. Python para Ciência de Dados
4. Visualização de Dados
5. Storytelling com Dados
6. Conclusão
7. Referências
1 – Introdução
Atualmente, nesse nosso mundo super conectado, todas as pessoas, empresas e atividades geram dados, mesmo sem querer nem saber.
Esta gama imensa de dados está sendo usada pelas empresas e governos para gerar informações importantes que embasam suas tomadas de decisões.
A Ciência de Dados é uma área que tem crescido muito nestes últimos anos e, com a chegada dominante da Inteligência Artificial, vai crescer ainda mais e resultar em mais e melhores informações que podem tornar o mundo melhor.
Muitas vezes, os resultados da análise destes dados são apresentados na forma de gráficos, pois eles facilitam a descoberta de padrões nos dados e resumem toda a informação gerada em uma figura.
Desta forma, os gráficos permitem que os resultados gerenciais sejam melhor entendidos por quem precisa apenas de uma informação resumida sobre determinados cenários para tomar uma decisão.
Este artigo trata da visualização gráfica de dados, focando na sua geração pela linguagem Python, a mais popular entre os profissionais de Ciência de Dados.
2 – Ciência de Dados

A popularização do computador e do celular, aliada à disponibilidade da Internet, aumentou a quantidade de dados gerados pela população e pelas atividades digitais nos últimos anos.
Os consumidores deixam seus dados nas atividades realizadas, como compras online e publicações em redes sociais, já as empresas armazenam dados dos seus clientes e das operações realizadas por eles.
As empresas já descobriram que a análise dessa enorme quantidade de dados permite a visão de cenários favoráveis e desfavoráveis para auxiliar em uma melhor tomada de decisões gerenciais.
Estas decisões irão direcionar a busca pelo sucesso de seus negócios, incluindo também a análise do comportamento do mercado e dos seus concorrentes.
Segundo Joel Grus [1], a Ciência de Dados se encontra na interseção dos conhecimentos mostrados no gráfico famoso abaixo:

Ou seja, ela se envolve conhecimentos de matemática e estatística, habilidades de hacker e competência significativa. No seu livro, o autor trata apenas das áreas de habilidade de hacker e de matemática e estatística.
As outras áreas mostradas no gráfico são: Aprendizado de máquina, pesquisa tradicional e uma zona de perigo, que envolve apenas as habilidades de hacker e a competência significativa.
A Ciência de Dados (Data Science) é uma área relativamente nova que surgiu dessa gama de dados digitais gerados nas operações das empresas (Big Data), da necessidade de análise deles (BI – Business Intelligence).
Estas tarefas requerem profissionais capacitados para usar estes dados, transformá-los em informações úteis para análise de situações e previsão de cenários futuros (Machine Learning e Deep Learning).
Segundo Sam Lau [2], o ciclo de vida de ciência de dados é composto pelas atividades relacionadas ao uso adequado destes dados, que são seguidas pela grande maioria dos projetos de dados. Este ciclo de vida pode ser dividido em 4 etapas (ver figura abaixo):
• Fazer uma pergunta;
• Obter os dados;
• Entender os Dados;
• Entender o Mundo.

Descrevendo cada etapa, temos:
Fazer uma pergunta - As perguntas orientam as análises descritivas, exploratórias, inferenciais e preditivas. A ideia é reduzir uma pergunta ampla a outra que possa ser respondida com dados, objetivando determinar os dados necessários, os padrões a serem procurados e como interpretar os resultados.
Obter os dados - Definição de protocolos precisos para coletar os dados, observando a qualidade destes dados, podendo modificar sua estrutura, limpar os valores e transformar medições para se preparar para a análise.
Entender os dados - Etapa altamente iterativa, com o exame cuidadoso dos dados, com uma análise exploratória, elaboração de gráficos, para descobrir padrões e resumir os dados visualmente, continuando a procurar padrões e tendências, usando estatísticas resumidas e construindo modelos estatísticos, como regressão linear e logística.
Entender o Mundo - É preciso quantificar o quanto as tendências que encontramos se generalizam além de nossos dados. Pode ser preciso fazer inferências sobre o mundo ou previsões para observações futuras.
As atividades realizadas nestas etapas podem ser resumidas como aquisição de dados, limpeza, exploração, análises formais, para chegar a conclusões sólidas.
Na prática, as atividades relacionadas à Ciência de Dados podem ser resumidas no pipeline de dados, mostrado na figura a seguir.
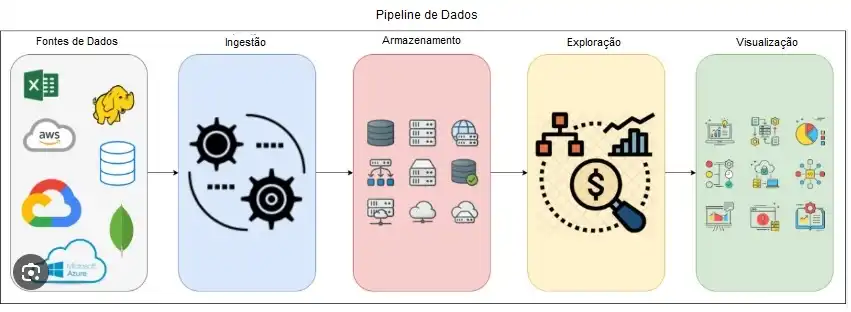
Neste pipeline, os data warehouses e datalakes fazem parte das atividades de armazenamento dos dados. Nas fases de ingestão de dados e de armazenamento, os dados passam pelas atividades de extração (E), transformação (T) e carga (L, de load), estão os modelos ETL e ELT, que diferem na ordem da aplicação da carga e transformação, representados na figura abaixo.

Para realizar todas as atividades envolvidas com a Ciência de Dados, foram criadas várias profissões, muitas delas realizadas por uma mesma pessoa. Segundo o artigo do portal Engenharia 360 [3], as mais conhecidas são:
Engenheiro de Dados – trabalha na coleta, armazenamento, qualidade dos dados e operacionaliza o modelo de dados, se concentrando na limpeza e tratamento dos dados, repassando-os para o Analista de Dados.
Analista de Dados – atua na transformação dos dados, em informações e geração de insights, geralmente em conjunto com uma equipe da empresa que entende da inteligência do negócio. É responsável pela visualização dos dados e geração de insights.
Cientista de Dados – cria os modelos de aprendizado de máquina e inferências estatísticas a partir dos dados tratados, sendo responsável pela análise estatística, machine learning e criação de modelos estatísticos.
3 – Python para Ciência de Dados

Segundo artigo da Alura [4], a linguagem Python foi criada pelo programador holandês Guido van Rossum e teve sua primeira versão lançada em 1991.
Ela é uma linguagem de programação de uso geral, podendo ser usada para criar uma grande variedade de aplicações diferentes, como na construção de sites, testes de software, automação de tarefas e até em machine learning.
Por sua versatilidade e facilidade de uso, Python se tornou uma das linguagens de programação mais populares do mundo nos últimos anos.
Algumas de suas principais características são:
• linguagem de alto nível, de sintaxe simples, fácil de aprender, lembrando a língua inglesa;
• linguagem interpretada, não gera arquivo executável por compilação;
• Multiparadigma: procedural, funcional e orientado a objetos;
• Multiplataforma, podendo ser executada em Windows, linux e iOS;
• Código aberto, com uma comunidade global enorme e ativa;
• Usada por empresas gigantes da tecnologia;
• possui tipagem dinâmica e forte;
• É a linguagem mais popular em Ciência de Dados.
As aplicações mais comuns de Python são:
• Automação de atividades no computador e na Internet;
• Desenvolvimento de programas;
• Criação de sites;
• Ciência de Dados e IA;
• Análise de Dados.
Embora Python possa ser usada para o desenvolvimento de aplicativos, por meio da biblioteca Kivi, ela ainda não é competitiva em relação a outras linguagens comumente usadas para isso, como Java, Kotlin e Swift.
Bibliotecas de Python mais usadas em Ciências de Dados
De acordo com artigo da DSA [5], a linguagem Python oferece milhares de bibliotecas, que são conjuntos de códigos prontos que podem ser utilizados para resolver problemas específicos em diversas categorias.
A seguir, são listadas as bibliotecas de Python mais usadas em Ciências de Dados, separadas por categorias:
Bibliotecas para manipulação de dados e estatística

Pandas - fornece estruturas de dados de alto nível, permite agrupar, filtrar e combinar dados, trabalha com dados estruturados até séries temporais, suporta diversos formatos diferentes (como JSON, CSV e Excel), pode com mais de um banco de dados ao mesmo tempo.
NumPy (Numerical Python) – usada para cálculos numéricos e científicos, com manipulação de matrizes de alto desempenho. Alguns objetos do Pandas (series e dataframe) dependem de matrizes NumPy para todos os cálculos matemáticos.
Ela ainda permite a integração com diversas bibliotecas Python, bem como com outras linguagens de programação, como FORTRAN, C e C++.
SciPy - baseada em NumPy, contém ferramentas para resolver problemas de álgebra linear, teoria da probabilidade, cálculo integral etc.
Bibliotecas para machine learning
Scikit-learn - módulo baseado no NumPy e SciPy, fornece algoritmos para tarefas de aprendizado de máquina e mineração de dados, como clustering, regressão, classificação, redução de dimensionalidade e seleção de modelo.
PyCaret - ferramenta low-code para machine learning, realizando diversas tarefas do pipeline de machine learning e oferecendo suporte à GPU.
Bibliotecas para deep learning

TensorFlow - framework popular, fácil de aprender, gratuita e open source; trabalha com aplicações de identificação de objetos, reconhecimento de fala, controle de fluxo de dados e ciência de dados, principalmente para criação e testes;
PyTorch - permite executar cálculos de tensores com aceleração de GPU, criar grafos computacionais dinâmicos e calcular gradientes automaticamente, além de oferecer uma API rica para redes neurais.
Theano - utilizada com grande quantidade de dados, acelera muito o processamento dos dados e é capaz de analisar, descrever, otimizar e manipular várias expressões matemáticas ao mesmo tempo, utilizando matrizes multidimensionais, sendo chamada de compilador otimizador.
Keras – roda sobre o TensorFlow e Theano, é usada para trabalhar com redes neurais, possui código aberto e é muito utilizada na inteligência artificial.
Bibliotecas para processamento de linguagem natural (PLN)
NLTK - plataforma completa que permite processar e analisar texto de várias maneiras, extrair informações etc.
SpaCy - biblioteca com ótimos exemplos, documentação da API e aplicativos de demonstração, tem suporte a quase 30 idiomas, é robusta e de alta precisão.
Bibliotecas para data e web scraping
Scrapy - cria robôs (bots) que varrem páginas da web e coletam dados estruturados, além extrair dados de APIs.
Beautiful Soup - biblioteca de mineração e extração de dados HTML e XML, usada para raspar dados de páginas web.
Bibliotecas para data apps e banco de dados
Streamlit - cria aplicativos de dados (data apps) para exploração e manipulação e visualização de dados e machine learning.
SQLAlchemy - ferramentas de banco de dados que ajudam a acessar data warehouses com eficiência.
Bibliotecas para automação
PyAutoGUI - utiliza scripts Python para controlar mouse e teclado, automatizando interações com outros aplicativos. É compatível com Windows, macOS e Linux.
Selenium - usada para se conectar com diferentes navegadores e automatizar suas interações, executando testes para simular a interação com o usuário, encontrar eventuais falhas e garantir um bom desempenho ao software.
Bibliotecas para visualização de dados

Matplotlib – permite criar diagramas e gráficos 2D (como histogramas, gráficos de dispersão. gráficos de coordenadas não cartesianas) e construção de dashboards.
Seaborn - API de alto nível baseada em matplotlib, permitindo tipos complexos de visualizações, como séries temporais, diagramas conjuntos e diagramas de violino.
Plotly - permite construir gráficos sofisticados, como gráficos de contorno, gráficos ternários e gráficos 3D. Pode trabalhar em aplicativos da web interativos.
Dash - baseado no Plotly, permite construir dashboards de alto nível integrando código Python, HTML e CSS.
Bokeh - cria visualizações interativas e escalonáveis em um navegador usando JavaScript.
Pydot - interface para o Graphviz, permitindo gerar grafos complexos orientados e não orientados, usados em redes neurais e árvores de decisão.
4 – Visualização de Dados

Segundo Desireé [6], os cientistas de dados criam visualizações de dados para entender os dados e explicar as análises para outras pessoas. Um gráfico deve ter uma mensagem, e é trabalho deles comunicá-la da forma mais clara possível.
É importante escolher um gráfico adequado ao tipo de dados plotados, bem como escolher escalas para eixos, lidar com grandes quantidades de dados com suavização e agregação, facilitar comparações significativas, incorporar o design ao estudo e adicionar informações contextuais.
A visualização de dados está situada diretamente na interseção de análise, design e engenharia de software. É difícil encontrar um profissional que domine estas 3 áreas ao mesmo tempo.
Para criar um gráfico, é importante ter em mente:
• Como nosso cérebro percebe e processa informações;
• Como os padrões de acessibilidade estabelecidos pelas normas internacionais se aplicam à visualização de dados;
• Como escolher as cores e fontes certas para as visualizações;
• O processo de design e desenvolvimento para criar uma ótima visualização de um banco de dados.
Agora, com o gráfico por fazer, você precisa ser capaz de vender sua história para o seu público e isso envolve combinar os elementos certos na ordem certa para chamar a atenção do seu público e mantê-lo engajado o suficiente para se perguntar o que vem a seguir.
Segundo Elizabeth [7], criar visuais de dados impressionantes é certamente uma arte. No entanto, a ciência pode orientar o fluxo de informações com 7 princípios para transformar dados em visuais informativos impressionantes:
• Equilíbrio de Design - Equilíbrio refere-se aos elementos projetados de sua visualização de dados sendo distribuídos igualmente em seus gráficos;
• Ênfase dos principais insights - Você precisa chamar a atenção do seu público para os principais pontos de dados usando cores contraste, cores diferentes, espaço negativo, tamanho e formas;
• Mostrar movimento claro - Um design desordenado fará com que os olhos do seu público passem por todo o seu enredo sem um ponto claro onde eles devem pousar ou como eles devem se mover para criar uma absorção coesa de informações. Evite essa confusão criando um fluxo claro de informações;
• Utilize padrões para destacar insights - Os padrões são desenvolvidos quando os elementos de design são repetidos, podendo ser cores, tipos de gráficos ou os elementos usados nesses gráficos;
• Use Proporção - Proporção refere-se ao tamanho dos elementos plotados em suas visualizações, para indicar o peso da significância de diferentes conjuntos de dados e a relação entre os seus valores;
• Dê variedade ao seu público - Assistir a mesma coisa repetidas vezes cria tédio. Use elementos de design diferentes, interessantes e relevantes para quebrar a tendência de repetição;
• Indique o seu tema - O tema da sua apresentação é a ideia dominante que unifica todos os elementos das visualizações de dados. Deixe isso claro para o seu público com consistência e um padrão claro.
Tipos de gráficos usados em visualização de dados
Segundo Cole [8], os tipos de gráficos usados na visualização de dados variam de tipos comuns até alguns mais sofisticados, usados para aplicações específicas, mas que podem ter um efeito contrário à clareza que os dados exigem para serem bem representados.
Os tipos mais comuns de gráficos são mostrados a seguir:

5 – Storytelling com Dados
De acordo com Cole [8], é muito comum a gente ver gráficos ruins em apresentações. Com o avanço da tecnologia, qualquer um pode fazer um gráfico no Excel, ou em ferramentas semelhantes, escolhendo um gráfico pré-disponibilizado e carregando seus dados.
Na ausência de habilidades naturais ou treinamento neste espaço, muitas vezes, confiamos nestas ferramentas para fazer nosso gráfico. No entanto, a vontade de mostrar mais do que o necessário pode resultar em uma visualização muito carregada e confusa para o público.
Muitas vezes, essas ferramentas podem nos levar a gráficos muito ruins para o entendimento dos dados, como gráficos 3D, cores sem sentido, gráficos de pizza ou de rosquinha (ver figura abaixo).

Existem melhores práticas para se criar uma visualização adequada. Há uma história em seus dados, mas suas ferramentas não sabem disso. É aí que entra você - o analista ou comunicador das informações - para dar vida a essa história, com contexto e visual.
Ser capaz de contar histórias com dados é uma habilidade que está se tornando cada vez mais importante em nosso mundo de aumento de dados e desejo por tomada de decisão dirigida. Uma visualização de dados eficaz pode significar a diferença entre sucesso e fracasso de um projeto.
Parte de desafio é que a visualização de dados é uma etapa única no processo analítico, muitas vezes, a única parte do processo analítico que seu público vê.
A seguir, são listadas 6 lições principais para fazer apresentações de impacto e de sucesso:
1. Entenda o contexto
2. Escolha uma exibição visual apropriada
3. Elimine a desordem
4. Concentre a atenção onde quiser
5. Pense como um designer
6. Conte uma história
Cada lição é detalhada a seguir:
1. Entenda o contexto - Quem é o seu público? O que você precisa que eles saibam ou façam?
2. Escolha uma exibição visual apropriada - Qual é a melhor maneira de mostrar os dados que você deseja comunicar? Existem vários tipos de recursos visuais usados para comunicar dados nos diversos ambientes.
3. Elimine a desordem - Cada elemento que você adicionar a uma página (ou tela) em branco ocupa uma carga cognitiva de seu público. É preciso remover os elementos que atrapalham o entendimento deles.
4. Concentre a atenção onde quiser - É muito importante levar em consideração a visão e a memória que atuarão para enquadrar a importância de atributos de pré-atenção como tamanho, cor e posição na página.
5. Pense como um designer - A forma segue a função. Esse ditado do design de produto tem uma aplicação clara na comunicação com dados. Primeiro pense na função de um elemento do seu gráfico, só depois, na forma de apresentá-lo.
6. Conte uma história - As histórias ressoam e permanecem conosco de maneiras que os dados sozinhos não conseguem. Uma história tem um começo claro, meio e fim. O seu gráfico deve atentar para contar esta história.
Como melhorar os seus gráficos
É muito importante eliminar a desordem dos gráficos, principalmente removendo o excesso de informações ou clareando outros elementos importantes (item 3 da lista acima).
Com base no gráfico original mostrado abaixo, vamos seguir o passo a passo da remoção de elementos que causam desordem para melhorá-lo. As figuras fazem parte do livro [8].

1. Remover a borda do gráfico

2. Remover linhas de grade

3. Remover marcadores de dados

4. Limpar rótulos de eixo

5. Rotular dados diretamente

6. Aproveitar cores consistentes

A figura abaixo mostra a comparação entre a versão inicial do gráfico e a versão final, após as alterações realizadas:

6 - Conclusão
Diariamente, uma enorme gama de dados é criada por nós, pelas nossas atividades, pelos serviços oferecidos pelas empresas e pelos sensores espalhados em todos os equipamentos conectados.
Estes dados são usados pelas empresas e governos para melhorar suas tomadas de decisões visando o crescimento dos negócios e um melhor atendimento à população.
Uma das formas de apresentar o resultado das análises destes dados é por meio de gráficos. A visualização de dados facilita a descoberta de padrões e resume a informação gerada em uma figura, ideal para quem precisa tomar decisões gerenciais e não dispõe de tempo para uma explicação detalhada.
Este artigo descreveu brevemente a área de Ciência de Dados, suas atividades e as profissões que surgiram para transformar os dados em informações gerenciais úteis.
Foi apresentada a linguagem Python, a mais popular para quem trabalha com análise de dados, listando as bibliotecas maia populares do Python para se trabalhar com Ciência de Dados.
Foi apresentada uma introdução à visualização de dados, com dicas de melhores práticas, os tipos de gráficos mais comuns usados na área e um exemplo passo a passo de como aplicar técnicas para melhorar a aparência e o entendimento de um gráfico.
Finalmente, foi mostrado como apresentar um gráfico ao público de forma a contar uma história sobre os dados, com início, meio e fim, que gerou a figura que o público vê na sua frente.
Eu sou fã da visualização gráfica e acredito que essa é uma forma quase universal de apresentar resultados de análises complexas, pois ela mostra características dos dados, comparações de valores e da sua qualidade, localização e tendências temporais.
Ou seja, tem tudo a ver com negócios e ciência, mas também tem muito a ver com arte!
7 – Referências

[1] Joel Grus, Data Science from Scratch, 2nd Edition, O’Reilly, Sebastopol, 2019.
[2] Sam Lau et al., Learning Data Science, Early Release, O’Reilly, Sebastopol, 2023.
[3] Engenharia 360, Descubra as diferenças entre Analistas, Engenheiros e Cientistas de dados. Disponível em: <https://engenharia360.com/analistas-engenheiros-e-cientistas-de-dados/>. Acesso em: 29/06/2023
[4] Alura, O que é Python? História, Sintaxe e um Guia para iniciar na Linguagem. Disponível em: <https://www.alura.com.br/artigos/python?gclid=Cj0KCQjwtO-kBhDIARIsAL6Lorc-AJufMYsawN2nnfdTFF7tZW0P2V43ucIIWUEK3Qdw7dv4IdlzBXUaAqOiEALw_wcB>. Acesso em: 29/06/2023
[5] Data Science Academy, Top 25 Bibliotecas Python Para Data Science. Disponível em: <https://blog.dsacademy.com.br/top-25-bibliotecas-python-para-data_science/>. Acesso em: 29/06/2023
[6] Desireé Abbott, Everyday Data Visualization, Manning Publications, 2023.
[7] Elizabeth Clarke, Beginner’s Guide to Data Visualization, Kenneth M. Fornari, 2022.
[8] Cole Nussbaumer Knaflic, Storytelling with Data, John Wiley & Sons, Hopboken, 2015.






Obrigado, Luiz!
Ele não vai concorrer aos prêmios do concurso, porque tive problemas e não consegui publicá-lo dentro do prazo. Mesmo assim, ainda é um artigo!
E já estava quase pronto, só fiz concluí-lo e publicá-lo!
Ótimo artigo Fernando! Você fez um artigo completo e apresentou conceitos importantes e complexos da área de dados de maneira didática.
As imagens facilitam a leitura e fixação do conteúdo tão importante para quem deseja atuar na área ou simplesmente deseja saber mais.
Parabéns!