


A Autópsia de um Dashboard: Dissecando a Mente da Máquina com Power BI

Introdução: A Noite em que Desmontei Meu Dashboard para Entender a Mente da Máquina
Quando comecei no mundo dos dados, meu objetivo era simples: transformar planilhas e tabelas estáticas em visuais interativos. A sensação de conectar uma fonte de dados no Power BI e ver um gráfico de barras nascer na tela era, para mim, uma espécie de mágica. Se os números batiam e o design era limpo, eu considerava o projeto um sucesso. Meu primeiro grande orgulho foi um dashboard que construí por iniciativa própria, usando dados abertos da minha cidade, Recife. Era uma análise sobre a infraestrutura urbana. Ele tinha mapas com geolocalização, gráficos de evolução temporal, filtros por bairros e categorias e funcionava. Era meu pequeno troféu, a prova de que eu estava no caminho certo.
O problema, o verdadeiro desafio, começou quando tentei dar "o próximo passo". Eu queria adicionar uma nova camada de análise, um cálculo mais complexo que cruzaria dados de diferentes fontes para gerar um "score de qualidade" para cada bairro. Parecia uma ótima ideia. E foi aí que o castelo de cartas desmoronou.
Ao adicionar essa nova funcionalidade, o dashboard, que antes era apenas um pouco lento, tornou-se agonizante. Cada clique levava uma eternidade. Os visuais gaguejavam para renderizar. O que antes era uma ferramenta de exploração de dados virou uma peça de museu digital: bonito de se ver, mas impossível de tocar. Não era mais uma questão de paciência; o dashboard tinha se tornado funcionalmente inútil.
A frustração foi imensa. Eu revisei minhas fórmulas DAX dezenas de vezes. Verifiquei os relacionamentos no modelo. Nada parecia obviamente "errado". Eu tinha seguido os tutoriais, aplicado o que aprendera. Por que algo que funcionava bem quebrou de forma tão espetacular ao adicionar apenas mais uma peça? Senti que havia um conhecimento fundamental que eu simplesmente não possuía. Frustrado, em uma noite de sábado, decidi fazer algo drástico. Abri meu projeto, olhei para aquela tela lenta e disfuncional, respirei fundo e apaguei tudo. Comecei do zero, com uma página em branco.
Minha missão não era mais reconstruir o dashboard, mas entendê-lo. Comecei a adicionar os elementos de volta, um de cada vez, de forma metódica. Primeiro, apenas as tabelas, e medi o desempenho. Depois, um relacionamento de cada vez. Em seguida, as medidas DAX, começando pelas mais simples. E, por fim, os visuais, um a um. E, lentamente, as pistas começaram a aparecer.
A primeira revelação veio do modelo. Percebi que um único relacionamento mal configurado entre duas tabelas muito grandes agia como uma âncora, atrasando todo o resto. A segunda veio de uma medida DAX. Reescrevi a mesma fórmula de três maneiras diferentes e vi, com espanto, que uma delas era quase 10 vezes mais rápida que as outras, embora o resultado final fosse idêntico. A pista final estava nos próprios gráficos: um determinado tipo de visual exigia um esforço computacional desproporcional em comparação com os outros.
Naquela noite, eu não consertei apenas um dashboard. Eu descobri uma verdade fundamental: a performance não é um recurso que se "adiciona" no final do projeto. Ela é uma consequência direta da "qualidade" de cada pequena decisão que tomamos desde o início.
Entendi que otimizar não era sobre aplicar um truque secreto de especialista. Era sobre construir de forma consciente, com a intenção de facilitar o trabalho do motor do Power BI. Era sobre entender como a máquina "pensa" para que pudéssemos "conversar" com ela em sua língua mais fluente. Percebi que essa construção consciente se apoia em três pilares essenciais, os mesmos que a minha experiência acidental havia me revelado:
- A Fundação (O Modelo de Dados): A forma como organizamos as tabelas e seus relacionamentos é a base sobre a qual toda a velocidade será construída ou destruída.
- A Conversa (A Linguagem DAX): A maneira como escrevemos nossas fórmulas determina se nossa pergunta à máquina será um sussurro claro ou um grito confuso.
- A Apresentação (Os Visuais): A escolha e configuração dos elementos na tela definem o "custo" final da interação para o usuário e para o sistema.
Este artigo é o mapa que eu mesmo desenhei naquela noite de descoberta. É a formalização daquele processo de desconstrução e aprendizado, um guia para você, que talvez esteja sentindo a mesma frustração que eu senti. Vamos juntos explorar esses pilares para construir dashboards não apenas para que funcionem, mas para que pensem na velocidade que suas ideias merecem.

Estudo de Caso Prático: Construindo o Dashboard de Arborização do Recife
Nesta seção, vamos recriar passo a passo o dashboard que mencionei na introdução. Aquele que foi meu "pequeno troféu de conquista". Nossa missão será construir um painel para analisar os dados de plantio de árvores na cidade do Recife.
Passo 1: A Fonte dos Dados
Tudo começa com os dados. Para este projeto, utilizamos um dataset público do portal Dados Abertos do Recife (dados.recife.pe.gov.br). O arquivo que usaremos como base é o de Arborização, que contém informações sobre cada árvore plantada pela prefeitura.
- Dataset (exemplo): arborizacao-recife.csv
- Colunas Principais que usaremos: data_plantio, latitude, longitude, bairro, especie_arvore, nome_popular.
Passo 2: Conexão e Limpeza no Power Query (Linguagem M)
A primeira etapa, e a mais fundamental para a otimização, acontece no Power Query. Aqui, vamos nos conectar aos dados, limpá-los e, mais importante, começar a estruturar nosso modelo estrela.
Abaixo está o código M que pode ser colado em uma "Consulta Nula" no Editor Avançado do Power Query.
// =========================================================================
// 1. CARGA E LIMPEZA DA TABELA FATO (fArvores)
// =========================================================================
let
// Conecta ao arquivo CSV local. Mude o caminho do arquivo conforme necessário.
Fonte = Csv.Document(File.Contents("C:\Caminho\Para\Seu\Arquivo\arborizacao-recife.csv"),[Delimiter=",", Columns=10, Encoding=65001, QuoteStyle=QuoteStyle.None]),
// Promove a primeira linha para ser o cabeçalho das colunas.
#"Cabeçalhos Promovidos" = Table.PromoteHeaders(Fonte, [PromoteAllScalars=true]),
// Altera os tipos de dados para otimizar o modelo.
// Esta é uma etapa CRÍTICA de performance.
#"Tipos Alterados" = Table.TransformColumnTypes(#"Cabeçalhos Promovidos",{
{"processo_numero", type text},
{"data_plantio", type date}, // Convertido para Data, não Data/Hora
{"bairro", type text},
{"latitude", type number}, // Usar 'Número Decimal' se precisar de alta precisão
{"longitude", type number},
{"especie_arvore", type text},
{"nome_popular", type text},
{"tipo_equipamento", type text},
{"endereco_plantio", type text},
{"complemento_plantio", type text}
}),
// Remove colunas que não serão usadas na análise para deixar o modelo mais leve.
#"Colunas Removidas" = Table.RemoveColumns(#"Tipos Alterados",{"processo_numero", "tipo_equipamento", "endereco_plantio", "complemento_plantio"}),
// Filtra linhas com dados essenciais ausentes (ex: sem data ou geolocalização).
#"Linhas Filtradas" = Table.SelectRows(#"Colunas Removidas", each [data_plantio] <> null and [latitude] <> null and [longitude] <> null),
// Renomeia a consulta final para fArvores (Tabela Fato).
fArvores = #"Linhas Filtradas"
in
fArvores
O código acima executa a limpeza essencial. Ele define os tipos de dados corretos – um passo crucial, pois colunas de data/hora ou números decimais desnecessários consomem muito mais memória. Além disso, removemos colunas que não seriam utilizadas na análise e filtramos linhas com informações vitais ausentes, garantindo a qualidade e a leveza da nossa tabela principal, que chamamos de fArvores.
Criando as Dimensões (ainda no Power Query):
Com a tabela fato limpa, criamos nossas tabelas de dimensão. Isso é feito referenciando a consulta fArvores, selecionando a coluna desejada e removendo as duplicatas. É um processo rápido que estrutura nosso modelo para máxima performance.
a) Dimensão dBairro
let
Fonte = fArvores, // Referencia nossa tabela fato já tratada
#"Coluna Bairro Selecionada" = Table.SelectColumns(Fonte,{"bairro"}),
#"Duplicatas Removidas" = Table.Distinct(#"Coluna Bairro Selecionada")
in
#"Duplicatas Removidas"
b) Dimensão dEspecie
let
Fonte = fArvores,
#"Colunas de Espécie Selecionadas" = Table.SelectColumns(Fonte,{"especie_arvore", "nome_popular"}),
#"Duplicatas Removidas" = Table.Distinct(#"Colunas de Espécie Selecionadas")
in
#"Duplicatas Removidas"
c) Dimensão dCalendario
Para análises temporais, nunca confie nas datas automáticas. Criar uma tabela calendário dedicada é a prática de ouro.
let
// Define o período da tabela calendário com base nas datas min/max da tabela fato.
DataInicio = List.Min(fArvores[data_plantio]),
DataFim = List.Max(fArvores[data_plantio]),
NumeroDeDias = Duration.Days(DataFim - DataInicio) + 1,
ListaDatas = List.Dates(DataInicio, NumeroDeDias, #duration(1, 0, 0, 0)),
// Converte a lista de datas para uma tabela.
TabelaDatas = Table.FromList(ListaDatas, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Colunas Renomeadas" = Table.RenameColumns(TabelaDatas,{{"Column1", "Data"}}),
#"Tipo Alterado" = Table.TransformColumnTypes(#"Colunas Renomeadas",{{"Data", type date}}),
// Insere colunas úteis para a análise temporal.
#"Ano Inserido" = Table.AddColumn(#"Tipo Alterado", "Ano", each Date.Year([Data]), Int64.Type),
#"Mês Inserido" = Table.AddColumn(#"Ano Inserido", "Mês", each Date.Month([Data]), Int64.Type),
#"Nome do Mês Inserido" = Table.AddColumn(#"Mês Inserido", "Nome Mês", each Date.ToText([Data], "MMMM", "pt-BR"), type text),
#"Ano-Mês Inserido" = Table.AddColumn(#"Nome do Mês Inserido", "Ano-Mês", each Date.ToText([Data], "yyyy-MM", "pt-BR"), type text),
#"Trimestre Inserido" = Table.AddColumn(#"Ano-Mês Inserido", "Trimestre", each "T" & Text.From(Date.QuarterOfYear([Data])), type text)
in
#"Trimestre Inserido"
passo 3: Modelagem de Dados e Medidas DAX
a) O modelo estrela:
Após carregar as consultas para o Power BI, vamos à aba 'Modelo'. Aqui, conectamos nossas tabelas de dimensão à tabela fato. O resultado é um Esquema Estrela limpo e otimizado, onde todas as perguntas (filtros) fluem das dimensões para os fatos.
- dCalendario[Data] se conecta a fArvores[data_plantio]
- dBairro[bairro] se conecta a fArvores[bairro]
- dEspecie[especie_arvore] se conecta a fArvores[especie_arvore]
b) As medidas DAX:
Com o modelo correto, nossas fórmulas DAX se tornam simples e poderosas. Criamos uma tabela dedicada chamada _Medidas para mantê-las organizadas.
// Medida base para contar o número de árvores plantadas.
Total de Árvores Plantadas = COUNTROWS( fArvores )
// Medida para contagem acumulada no ano.
Árvores Plantadas no Ano = TOTALYTD( [Total de Árvores Plantadas], dCalendario[Data] )
// Medida de inteligência de tempo para comparar com o ano anterior.
Árvores Ano Anterior =
CALCULATE(
[Total de Árvores Plantadas],
SAMEPERIODLASTYEAR( dCalendario[Data] )
)
// Medida para calcular o crescimento percentual.
Crescimento Plantio % =
DIVIDE(
[Total de Árvores Plantadas] - [Árvores Ano Anterior],
[Árvores Ano Anterior]
)
passo 4: A apresentação dos visuais
Na tela de 'Relatório', finalmente damos vida aos dados, usando nossas medidas e dimensões para responder às perguntas iniciais:
- Mapa (Visual "Mapa"): Usamos latitude e longitude da fArvores. O campo "Tamanho da Bolha" é alimentado pela medida [Total de Árvores Plantadas].
- Gráfico de Evolução Temporal (Visual "Gráfico de Linhas"): No eixo X, usamos Ano-Mês da dCalendario. No eixo Y, [Total de Árvores Plantadas] e [Árvores Ano Anterior].
- Filtros (Visual "Segmentação de Dados"): Criamos filtros para dCalendario[Ano], dBairro[bairro] e dEspecie[nome_popular].
- KPIs Principais (Visual "Cartão"): Cartões para [Total de Árvores Plantadas] e [Crescimento Plantio %].
Ao seguir esta estrutura, o dashboard final não apenas funciona, ele é rápido. Cada interação é fluida porque construímos sobre uma fundação sólida, provando que a otimização começa muito antes do primeiro gráfico ser desenhado.
Pilar Zero: A Fonte da Verdade – Otimização na Origem com SQL
Naquela noite em que desmontei meu dashboard, descobri os três pilares da otimização dentro do Power BI: o Modelo, o DAX e os Visuais. Consertei o relatório, e ele ficou rápido. Mas, dias depois, uma nova e ainda mais profunda revelação me ocorreu: eu tinha passado semanas otimizando a minha "cozinha" (o Power BI), mas nunca parei para pensar na "fazenda" de onde vinham meus ingredientes (o banco de dados).
Eu estava forçando o Power BI a fazer um trabalho pesado, filtrar milhões de linhas, juntar tabelas, fazer cálculos complexos, que poderia, e deveria, ter sido feito muito antes, na própria fonte dos dados. A verdadeira jornada do Neurocientista de Dados não começa no Power BI, mas no banco de dados. O princípio é simples e poderoso: faça o trabalho pesado o mais cedo possível.
Quando a fonte dos seus dados é um banco de dados relacional (como SQL Server, PostgreSQL, Oracle, etc.), a linguagem SQL é o seu instrumento de otimização mais potente. Delegar o trabalho para o banco de dados é como pedir a um chef especialista para preparar os ingredientes para você, em vez de jogar um caminhão de vegetais sujos na sua bancada para você se virar sozinho.
0.1 - A Linguagem da Fonte: SQL e a Mágica do "Empurrão" (Query Folding)
O Power BI, através do seu motor de transformação de dados (o Power Query), é inteligente. Ele tenta "conversar" com a sua fonte de dados na língua nativa dela. Quando a fonte é um banco de dados, essa língua é o SQL. O processo de traduzir os cliques que você faz no Power Query em uma consulta SQL que é executada pelo banco de dados se chama Query Folding (Dobra de Consulta).
Quando a dobra de consulta funciona, o trabalho é "empurrado" (pushed down) para o banco de dados, que é um especialista em processar grandes volumes de dados.
Exemplo Prático: Imagine que nossa tabela de arborização do Recife, em vez de um CSV, fosse uma tabela gigantesca com 20 milhões de linhas em um SQL Server. A tarefa é simples: mostrar o total de Ipês plantados no bairro de Boa Vista.
- O Jeito Ineficiente (sem dobra de consulta): O Power BI importa os 20 milhões de linhas para a memória do seu computador. Só então ele aplica os filtros para bairro e espécie. É um desperdício colossal de tempo e recursos.
- O Jeito Inteligente (com dobra de consulta): Ao aplicar os filtros no Power Query, ele traduz suas ações para o SQL:
SELECT * FROM dbo.Arborizacao WHERE Bairro = 'Boa Vista' AND Especie = 'Ipê'
Essa instrução é enviada ao SQL Server. O servidor, que é otimizado para isso, encontra as poucas centenas de linhas relevantes e envia apenas esse pequeno resultado para o Power BI. A diferença é entre esperar minutos e segundos.
Na Prática: No Power Query, após uma etapa de transformação, clique com o botão direito sobre ela. Se a opção "Exibir Consulta Nativa" estiver habilitada, a mágica está acontecendo!
0.2 - O Bisturi do SQL: Técnicas Essenciais para Otimização na Fonte
Para garantir que a conversa com o banco de dados seja a mais eficiente possível, usamos o SQL para sermos explícitos sobre o que queremos. As três técnicas principais são:
- Filtragem Precoce com WHERE: É a otimização mais poderosa. Nunca traga dados que você não vai usar. A cláusula WHERE é o seu primeiro e mais importante comando. Antes de pensar em qualquer outra coisa, pergunte-se: "De quais anos eu preciso? De quais categorias? De quais regiões?".
- Junções Eficientes com JOIN: Juntar tabelas (Merge) no Power Query pode quebrar a dobra de consulta. Bancos de dados, por outro lado, nasceram para fazer JOINs. Se você precisa cruzar a sua tabela de fatos com clientes, produtos e localidades, faça isso no SQL. O JOIN no banco de dados será sempre ordens de magnitude mais rápido.
- Pré-Agregação com GROUP BY: Essa técnica muda o jogo. Por que trazer a conta de supermercado detalhada se o seu relatório só precisa do valor total? Se o seu dashboard mostra vendas por mês, não há motivo para importar os dados por dia ou por segundo.
0.3 - A Receita Completa: A Consulta SQL Definitiva
Vamos unir todas as técnicas em uma única consulta SQL "de elite" para o nosso estudo de caso. Imagine que, além da tabela de plantio, temos uma tabela de Zonas da cidade, e queremos ver o total de árvores plantadas por zona e por ano.
Em vez de carregar as tabelas separadamente, nós iríamos em "Obter dados > SQL Server", e na caixa de "Instrução SQL", colaríamos:
-- Consulta SQL otimizada para o Power BI
SELECT
Z.Nome_Zona,
YEAR(A.data_plantio) AS Ano_Plantio,
COUNT(A.id_arvore) AS Total_Arvores
FROM
dbo.Arborizacao AS A
-- 1. JUNÇÃO EFICIENTE: Juntamos com a tabela de Zonas
INNER JOIN
dbo.Zonas AS Z ON A.bairro = Z.Bairro
-- 2. FILTRAGEM PRECOCE: Pegamos apenas dados a partir de 2023
WHERE
A.data_plantio >= '2023-01-01'
-- 3. PRÉ-AGREGAÇÃO: Agrupamos para ter o resultado já sumarizado
GROUP BY
Z.Nome_Zona,
YEAR(A.data_plantio)
ORDER BY
Nome_Zona,
Ano_Plantio;
O Power BI receberia uma tabela pequena, já sumarizada e pronta para ser usada, com três colunas (Nome_Zona, Ano_Plantio, Total_Arvores), em vez de duas tabelas gigantes que ele teria que processar.
0.4 - Formalizando a Lógica: O Poder das VIEWs
A melhor prática não é nem mesmo colar esse código SQL dentro do Power BI. O ideal é que essa lógica de negócio seja "formalizada" no próprio banco de dados. Para isso, usamos VIEWs (Exibições).
Uma VIEW é simplesmente uma consulta SQL salva no banco de dados que se comporta como uma tabela virtual. O administrador do banco de dados pode criar uma VIEW chamada vw_TotalArvoresPorZonaAno com a consulta acima. Para o analista no Power BI, o trabalho fica incrivelmente simples: ele se conecta ao banco de dados e seleciona a "tabela" vw_TotalArvoresPorZonaAno, que já vem pré-otimizada, limpa e pronta para uso.
Resumo do Pilar Zero: Otimize na Fonte
Com os dados já pré-otimizados pela força do SQL, a tarefa do nosso cérebro de BI (o Modelo de Dados no Power BI) se torna imensamente mais fácil. A otimização não começa com um clique no Power BI; ela começa com uma conversa inteligente com a fonte dos dados.
Agora, com este conjunto de informações enxuto e performático em mãos, vamos entrar no Pilar I: A Fundação e ver como arquitetar esses dados da melhor forma possível dentro do nosso relatório.
Pilar I: A Fundação – Arquitetando a Memória do Dashboard
No Pilar Zero, agimos na fonte, usando o SQL para garantir que os dados chegassem ao Power BI já limpos e enxutos. Acreditava que a batalha pela performance estava ganha. No entanto, ao montar meu dashboard, a lentidão persistia. Foi aí que encontrei a primeira grande pista dentro do Power BI: mesmo com os melhores dados, uma fundação mal arquitetada pode comprometer todo o projeto. A falha era estrutural. Neste capítulo, vamos construir essa fundação.
É tentador pular esta etapa. A parte divertida é criar os gráficos. A modelagem parece um trabalho de bastidor, tedioso. No entanto, o que aprendi da maneira mais difícil foi que 90% da performance de um dashboard nasce ou morre aqui. Tentar consertar a lentidão de um dashboard apenas com DAX ou visuais, sem ter um modelo sólido, é como tentar consertar as rachaduras de um prédio pintando as paredes. A falha é estrutural. Neste capítulo, vamos construir essa fundação. Vamos entender os princípios de uma arquitetura de dados que não apenas funciona, mas que foi projetada para ser rápida, eficiente e, acima de tudo, para "pensar" da mesma forma que o motor do Power BI.
1.1 - O Cérebro Organizado: Apresentando o Esquema Estrela (Star Schema)
A primeira mudança de mentalidade é parar de pensar no Power BI como uma super planilha. Um erro comum de iniciante é importar uma única tabela gigantesca. A abordagem profissional é o Esquema Estrela (Star Schema).
O conceito é elegantemente simples e se baseia na separação de papéis:
- Tabela Fato (A Ocorrência): A tabela central. Ela armazena os eventos e os números. No nosso estudo de caso, a fArvores é a nossa tabela fato. Cada linha representa um evento: uma árvore foi plantada.
- Tabelas Dimensão (O Contexto): Orbitam a tabela fato. Elas armazenam o contexto descritivo: quem, o quê, onde, quando, como. No nosso caso, dCalendario, dBairro e dEspecie são nossas dimensões.
Essa estrutura organiza a informação de uma maneira lógica, quase como o cérebro humano, que armazena fatos e os conecta a contextos para dar-lhes significado. A aplicação prática disso no Power Query é direta e fundamental. Para criar nossas dimensões, nós usamos a tabela fato como fonte, garantindo a integridade dos dados.
Na Prática: O Código M para Criar uma Dimensão
Para criar nossa dimensão dBairro, por exemplo, o processo no Power Query é referenciar a consulta fArvores, selecionar a coluna "bairro" e remover as duplicatas. O código gerado é simples e poderoso:
// Código M para a dimensão de Bairros (dBairro)
let
// 1. Referencia a consulta da Fato já tratada
Fonte = fArvores,
// 2. Seleciona apenas a coluna que será a dimensão
#"Outras Colunas Removidas" = Table.SelectColumns(Fonte,{"bairro"}),
// 3. Remove as duplicatas para criar uma lista única
#"Duplicatas Removidas" = Table.Distinct(#"Outras Colunas Removidas")
in
#"Duplicatas Removidas"
Este pequeno processo é um dos atos mais impactantes que você pode realizar para a performance do seu modelo.
1.2 - A Peça Mestra: A Dimensão Calendário Dedicada
Se há uma única otimização que separa um modelo amador de um profissional, é a criação de uma Tabela Calendário dedicada. O Power BI oferece um recurso de "Data/Hora Automática" que, embora conveniente, cria múltiplas tabelas ocultas que "incham" o modelo e o tornam mais lento. Além da performance, uma tabela calendário explícita é um pré-requisito para a maioria das poderosas funções de Inteligência de Tempo do DAX.
Na Prática: O Código M para uma Tabela Calendário Dinâmica
A seguir, o código M completo para criar uma calendário robusta e dinâmica no Power Query, que se adapta automaticamente ao período de tempo da sua tabela de fatos.
// Código M para uma Tabela Calendário dinâmica e em português
let
DataInicio = List.Min(fArvores[data_plantio]),
DataFim = List.Max(fArvores[data_plantio]),
NumeroDeDias = Duration.Days(DataFim - DataInicio) + 1,
ListaDatas = List.Dates(DataInicio, NumeroDeDias, #duration(1, 0, 0, 0)),
TabelaDatas = Table.FromList(ListaDatas, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Colunas Renomeadas" = Table.RenameColumns(TabelaDatas,{{"Column1", "Data"}}),
#"Tipo Alterado" = Table.TransformColumnTypes(#"Colunas Renomeadas",{{"Data", type date}}),
#"Ano Inserido" = Table.AddColumn(#"Tipo Alterado", "Ano", each Date.Year([Data]), Int64.Type),
#"Trimestre Inserido" = Table.AddColumn(#"Ano Inserido", "Trimestre", each "T" & Text.From(Date.QuarterOfYear([Data])), type text),
#"Mês Inserido" = Table.AddColumn(#"Trimestre Inserido", "Mês", each Date.Month([Data]), Int64.Type),
#"Nome do Mês Inserido" = Table.AddColumn(#"Mês Inserido", "Nome Mês", each Date.ToText([Data], "MMMM", "pt-BR"), type text),
#"Dia da Semana Inserido" = Table.AddColumn(#"Nome do Mês Inserido", "Dia da Semana", each Date.DayOfWeekName([Data], "pt-BR"), type text)
in
#"Dia da Semana Inserido"
1.3 - As Conexões Neurais: Relacionamentos e Cardinalidade
As conexões que criamos entre as tabelas são as sinapses do cérebro do nosso dashboard. Se forem claras e diretas (Um-para-Muitos, com direção de filtro Única), a informação flui instantaneamente. Filtros devem fluir "para baixo", das dimensões para os fatos.
Na Prática: Lidando com Múltiplas Datas (USERELATIONSHIP)
E quando a teoria encontra um desafio prático? Imagine que nossa tabela fArvores tem duas datas: [data_plantio] e [data_inspecao]. No modelo, só podemos ter um relacionamento ativo com a dCalendario (com [data_plantio]). Para analisar pela data de inspeção, ativamos o relacionamento inativo temporariamente via DAX:
// Medida DAX para usar um relacionamento inativo
Árvores Inspecionadas na Data =
CALCULATE(
[Total de Árvores Plantadas],
USERELATIONSHIP( fArvores[data_inspecao], dCalendario[Data] )
)
1.4 - Por Dentro da Mente da Máquina: O Motor VertiPaq
Para entender por que tudo isso funciona, precisamos conhecer o motor do Power BI: o VertiPaq. É um motor de banco de dados colunar, o que significa que ele é mestre em comprimir colunas com poucos valores únicos (baixa cardinalidade). Ao criar dimensões, nós damos exatamente o que o VertiPaq ama: tabelas fato com colunas de chaves repetidas (altamente compressíveis) e tabelas de dimensão pequenas com os valores únicos. Essa arquitetura foi projetada para funcionar em perfeita harmonia com o motor.
Na Prática: Espionando o VertiPaq com DAX Studio
Isso não é apenas teoria. Com ferramentas externas como o DAX Studio, podemos provar o impacto de nossas decisões. Ao conectar o DAX Studio ao nosso modelo e executar uma consulta de diagnóstico (DMV), podemos ver o "peso" de cada coluna na memória.
-- Consulta para ser executada no DAX Studio para ver o tamanho das colunas
SELECT
TABLE_NAME,
COLUMN_NAME,
CARDINALITY,
DICTIONARY_SIZE_IN_BYTES
FROM
$SYSTEM.DBSCHEMA_COLUMNS
ORDER BY
DICTIONARY_SIZE_IN_BYTES DESC
A execução deste código revelaria, por exemplo, que uma coluna de ID único com milhões de valores é muito mais "cara" para a memória do que as colunas de chaves que usamos em nosso modelo estrela. Para quem deseja uma imersão completa neste tópico, os trabalhos de Marco Russo e Alberto Ferrari, da SQLBI, são a referência mundial.
Com esta fundação arquitetônica sólida, não estamos mais lutando contra a máquina. Estamos trabalhando com ela. Estamos facilitando sua tarefa para que ela, em troca, nos entregue a performance que precisamos para que o nosso pensamento flua sem interrupções. Agora que o alicerce está pronto, podemos começar a construir a nossa conversa com os dados.
Pilar II: A Conversa – Dominando a Linguagem do Insight com DAX
Um modelo de dados perfeitamente arquitetado é como um cérebro genial e organizado, mas silencioso. Para extrair o conhecimento que ele contém, precisamos saber fazer as perguntas certas. No universo do Power BI, essa linguagem de conversação é o DAX (Data Analysis Expressions). Muitos iniciantes (e eu me incluía nesse grupo) tratam o DAX como uma linguagem de fórmulas do Excel anabolizada. Criamos colunas calculadas, fazemos somas simples e nos damos por satisfeitos. Mas a verdadeira potência do DAX, e a chave para sua performance, está em entender que ele não é apenas sobre fórmulas; é sobre contexto.
Uma pergunta clara e bem formulada (uma medida DAX eficiente) recebe uma resposta instantânea. Uma pergunta confusa e prolixa (uma medida DAX ineficiente) força o motor do Power BI a um esforço enorme, resultando naqueles segundos de espera que quebram o fluxo de pensamento do usuário. Nesta seção, vamos aprender a arte da conversa eficiente.
2.1 - A Gramática Fundamental: Contexto de Filtro vs. Contexto de Linha
Este é o conceito mais importante de todo o universo DAX. Uma vez que você entende a diferença entre esses dois contextos, tudo passa a fazer sentido.
- Contexto de Filtro (O "O Quê" e "Onde"): Pense no Contexto de Filtro como o conjunto de filtros ativos em um visual no seu relatório. Quando você clica em "2024" em um filtro de ano ou no bairro "Casa Amarela" em um mapa, você está criando um Contexto de Filtro. Ele diz à sua medida DAX: "Calcule, mas apenas para os dados que correspondem a Ano = 2024 E Bairro = 'Casa Amarela'". É o ambiente ao redor da sua fórmula. Ele é criado pela interação do usuário no relatório.
- Contexto de Linha (O "Qual"): Pense no Contexto de Linha como um dedo que aponta para uma única linha de uma tabela e pergunta: "O que está acontecendo nesta linha específica?". Ele é criado automaticamente quando você cria uma coluna calculada ou quando usa funções iteradoras (aquelas que terminam com "X", como SUMX, FILTER, ADDCOLUMNS). Sozinho, o Contexto de Linha não filtra nada; ele apenas tem consciência da linha atual.
A falha em entender essa diferença leva a erros e a uma performance terrível. O superpoder do DAX está na função que faz a ponte entre esses dois mundos: CALCULATE.
2.2 - A Função Mestra: Desmistificando CALCULATE
CALCULATE é a função mais importante e poderosa do DAX. Por quê? Porque ela é a única que pode modificar o Contexto de Filtro.
Sua sintaxe é simples: CALCULATE( <expressão>, <filtro1>, <filtro2>, ... ).
O que ela faz é genial:
- Ela avalia os filtros que você passa como argumento.
- Ela modifica o contexto de filtro atual do relatório com base nesses novos filtros.
- Ela calcula a <expressão> nesse novo contexto modificado.
Na Prática: Usando CALCULATE no nosso Estudo de Caso
Nossa medida base é Total de Árvores Plantadas = COUNTROWS( fArvores ). Se quisermos saber quantas dessas árvores eram da espécie "Ipê Amarelo", não precisamos filtrar a tabela inteira. Nós simplesmente pedimos à CALCULATE para modificar o contexto:
// Medida que modifica o contexto de filtro
Total de Ipês Amarelos Plantados =
CALCULATE(
[Total de Árvores Plantadas],
dEspecie[especie_arvore] = "Ipê Amarelo"
)
Esta fórmula é incrivelmente rápida porque nosso modelo estrela permite que CALCULATE aplique um filtro na pequena dimensão dEspecie, que então se propaga para a tabela fArvores de forma otimizada.
2.3 - Padrões de Otimização: A Receita para um DAX Rápido
Agora, vamos ver alguns padrões práticos para escrever um DAX limpo e performático.
O Poder das Variáveis (VAR)
- O Problema: Repetir o mesmo cálculo complexo várias vezes dentro de uma única medida. Isso força o Power BI a fazer o mesmo trabalho duas ou mais vezes.
- A Solução: Usar variáveis para armazenar o resultado de um cálculo e reutilizá-lo. Isso melhora a performance e torna o código infinitamente mais legível.
Na Prática: Calculando o Crescimento de Plantio
A nossa medida [Crescimento Plantio %] é um exemplo perfeito.
// Versão com Variáveis: mais limpa e performática
Crescimento Plantio % =
VAR ArvoresAnoAtual = [Total de Árvores Plantadas]
VAR ArvoresAnoAnterior = CALCULATE( [Total de Árvores Plantadas], SAMEPERIODLASTYEAR( dCalendario[Data] ) )
RETURN
DIVIDE(
ArvoresAnoAtual - ArvoresAnoAnterior,
ArvoresAnoAnterior
)
Aqui, calculamos o total do ano anterior uma única vez e o armazenamos na variável ArvoresAnoAnterior, reutilizando-o no cálculo da divisão.
A Divisão Segura e Eficiente (DIVIDE)
- O Problema: Tentar dividir um número por zero, o que gera um erro no dashboard. A solução comum é usar um IF para checar se o denominador é zero.
- A Solução: Usar a função DIVIDE, que foi projetada exatamente para isso. Ela é mais otimizada e já lida com o erro de divisão por zero automaticamente, retornando BLANK() ou um resultado alternativo que você pode especificar.
Na Prática: Observe a linha RETURN da nossa medida anterior.
// Jeito Lento e Verboso com IF
// RETURN IF( ArvoresAnoAnterior = 0, BLANK(), (ArvoresAnoAtual - ArvoresAnoAnterior) / ArvoresAnoAnterior )
// Jeito Rápido e Limpo com DIVIDE
RETURN DIVIDE( ArvoresAnoAtual - ArvoresAnoAnterior, ArvoresAnoAnterior )
A Armadilha dos Iteradores (SUMX, FILTER, etc.)
- O Problema: Usar uma função iteradora que força um contexto de linha quando uma simples agregação no contexto de filtro atual seria suficiente. Lembre-se, iterar sobre uma tabela de milhões de linhas é uma operação cara.
- A Solução: Entenda quando eles são necessários. Você precisa de um SUMX quando precisa fazer um cálculo linha a linha antes de somar o resultado final. Por exemplo, SUMX( TabelaVendas, TabelaVendas[Quantidade] * TabelaVendas[Preço Unitário] ).
No nosso caso, para simplesmente contar árvores, COUNTROWS( fArvores ) é muito mais rápido do que COUNTX( FILTER( fArvores, ... ), ... ) porque não precisa criar um contexto de linha.
2.4 - Resumo do Pilar II: A Arte da Conversa Eficiente
- Dominar o DAX não é decorar funções. É um exercício de clareza de pensamento. Para ter uma conversa rápida e eficiente com seus dados:
- Pense em Contexto: Sempre se pergunte: "Estou trabalhando em um contexto de filtro ou de linha?". CALCULATE é sua ferramenta para manipular o primeiro.
- Seja Limpo e Direto: Use variáveis (VAR) para organizar seus pensamentos e a função DIVIDE para cálculos seguros.
Respeite o Custo da Iteração: Só use funções "X" quando o cálculo linha a linha for indispensável.
Com nossa fundação sólida (Pilar I) e nossa conversa com os dados se tornando clara e eficiente (Pilar II), estamos prontos para o próximo passo: apresentar esses insights de uma forma que cative, em vez de sobrecarregar, o cérebro do nosso usuário.
Pilar III: A Apresentação – Projetando para a Economia da Atenção
Conseguimos. Nosso modelo de dados é uma obra de arte arquitetônica. Nossas medidas DAX são poemas de eficiência. Mas, ao abrir o dashboard, o usuário ainda enfrenta uma tela que pisca, gagueja e demora para carregar. Como isso é possível?
A verdade é que mesmo o motor mais rápido do mundo sofrerá se o instruirmos a desenhar uma obra de arte excessivamente complexa em uma fração de segundo. A otimização da camada visual é o último passo, e talvez o mais subestimado, para alcançar um desempenho verdadeiramente instantâneo. Nossa missão aqui é minimizar dois custos: o Custo de Renderização (o trabalho que a máquina faz para desenhar os gráficos) e a Carga Cognitiva (o trabalho que o cérebro do usuário faz para entender a informação). Vamos mergulhar nas ferramentas e técnicas para dominar essa arte.
3.1 - O Eletroencefalograma do Dashboard: Dominando o Analisador de Desempenho
Nossa principal ferramenta de diagnóstico neste pilar é o Analisador de Desempenho. Ele é o nosso "eletroencefalograma", um instrumento que nos permite ver exatamente quais elementos (visuais) do nosso dashboard estão "pensando demais" e consumindo tempo precioso.
Na Prática: Um Check-up no Nosso Dashboard de Arborização
Vamos usar o Analisador de Desempenho para investigar nosso próprio projeto do Recife.
- Abra a Ferramenta: No Power BI Desktop, vá para a faixa de opções "Otimizar" e clique em "Analisador de Desempenho". Um novo painel se abrirá à direita.
- Inicie a Gravação: Clique em "Iniciar gravação" e, em seguida, em "Atualizar visuais". O Power BI irá recarregar todos os elementos da página e registrar o tempo que cada um levou.Inicie a Gravação: Clique em "Iniciar gravação" e, em seguida, em "Atualizar visuais". O Power BI irá recarregar todos os elementos da página e registrar o tempo que cada um levou.
- Leia os resultados: Para cada visual na sua página, o analisador mostrará o tempo de carregamento dividido em três categorias:
- Consulta DAX: O tempo que o motor DAX levou para calcular os números. Se este valor for alto, os problemas estão no seu modelo ou nas suas medidas (Pilares I e II).
- Exibição do visual: O tempo que a máquina levou para efetivamente desenhar o gráfico na tela. Este é o nosso foco principal neste pilar.
- Outros: O tempo de espera, geralmente causado por outras operações ou visuais sendo carregados ao mesmo tempo.
Ao executar isso no nosso dashboard, provavelmente descobriríamos que o mapa de geolocalização com milhares de pontos individuais tem o maior tempo de "Exibição do visual". Esta é a nossa primeira pista para a otimização.
3.2 - A Psicologia da Escolha: Nem Todo Visual Nasce Igual
A escolha de um gráfico não deve ser apenas estética; é uma decisão de performance. O cérebro humano e o motor do Power BI têm suas preferências.
Os "Vilões" da Performance:
- Visuais de Alta Cardinalidade: Gráficos que precisam plotar um número enorme de pontos de dados únicos (como nosso mapa com cada árvore individual, gráficos de dispersão com milhares de pontos, ou tabelas com muitas colunas e rolagem infinita) são inerentemente lentos para renderizar.
- Visuais Personalizados: Visuais da AppSource podem ser fantásticos, mas nem todos são otimizados. Sempre teste o desempenho de um novo visual personalizado antes de adotá-lo em seus relatórios principais.
Os "Heróis" da Performance:
- Cartões (Cards) e KPIs: Extremamente rápidos. Eles executam uma consulta simples e exibem um único número.
- Gráficos de Barras e Colunas: Geralmente muito rápidos e, do ponto de vista da neurociência, são a forma mais eficaz para o cérebro humano comparar valores.
- Tabelas e Matrizes: Podem ser muito rápidas, desde que você não tente exibir dezenas de colunas e milhares de linhas de uma vez. A paginação é sua amiga.
Na Prática: No nosso dashboard, ao invés de exibir todas as árvores no mapa por padrão, podemos começar mostrando um Mapa Coroplético (ou de Formas), que colore os bairros pela intensidade de plantios. É um visual muito mais leve. Os pontos individuais só apareceriam ao aplicar um filtro ou um drill-through em um bairro específico.
3.3 - A Arte da Curadoria: Menos é Mais Rápido
A regra de ouro da performance visual é brutalmente simples: quanto menos objetos na tela, mais rápido o relatório. Cada elemento (um gráfico, um filtro, uma imagem, uma caixa de texto) adiciona um pequeno custo de renderização. Juntos, eles podem levar a uma lentidão significativa.
Nosso trabalho como "neurocientistas de dados" é sermos curadores impiedosos, garantindo que cada pixel na tela sirva a um propósito claro e imediato.
Na Prática: Técnicas Avançadas de Curadoria
- Dicas de Ferramenta (Tooltips) Personalizadas: Em vez de adicionar um gráfico de detalhes na página, crie uma nova página de "tooltip" e configure seu gráfico principal para mostrá-la ao passar o mouse. A informação detalhada só é carregada sob demanda.
- Obter Detalhes (Drill-through): A melhor maneira de evitar telas poluídas. Mantenha sua página principal com os KPIs de alto nível e configure um "drill-through" para uma página secundária com as tabelas de dados brutos e detalhes granulares.
- Marcadores (Bookmarks) para Controlar a Visibilidade: Esta é uma técnica poderosa. Em vez de colocar um mapa e uma tabela lado a lado, coloque-os no mesmo lugar, um sobre o outro. Crie dois botões ("Ver Mapa", "Ver Tabela") e dois marcadores. O primeiro marcador torna o mapa visível e a tabela invisível; o segundo faz o oposto. Assim, o Power BI só precisa renderizar um visual pesado de cada vez, cortando o tempo de carregamento pela metade.
3.4 - Resumo do Pilar III: Projetando para a Atenção Humana
Para construir uma apresentação que seja tão eficiente quanto nosso modelo e nosso DAX, devemos usar o Analisador de Desempenho como diagnóstico, escolher visuais conscientemente, reduzir o número de objetos na tela e usar técnicas avançadas para mostrar detalhes sob demanda. Com a fundação sólida, a conversa eficiente e uma apresentação limpa, completamos a jornada de otimização de performance. No entanto, um dashboard verdadeiramente profissional não é apenas rápido; ele precisa ser confiável e relevante para cada pessoa que o utiliza. E isso nos leva à próxima fase da nossa jornada de maturidade: a construção da Fortaleza da Confiança. Vamos falar de segurança.
Pilar IV: A Fortaleza – Governança e Segurança de Dados no Power BI
Até agora, nossa jornada como Neurocientistas de Dados focou em criar uma experiência fluida e instantânea. Construímos um dashboard rápido, eficiente e que "pensa" com o usuário. Mas há uma pergunta que ainda não respondemos: qual usuário?
O que acontece quando o CEO, um gerente regional e um analista júnior abrem o mesmo relatório? Eles devem ver a mesma coisa? A resposta, em 99% dos casos corporativos, é um sonoro "não". Um dashboard verdadeiramente inteligente não é apenas rápido; ele é contextualmente ciente. Ele entende quem o está acessando e se adapta, mostrando apenas os dados que são relevantes e permitidos para aquela pessoa.
Este pilar é sobre a construção dessa muralha invisível da confiança. Vamos explorar as camadas de segurança no Power BI, desde o controle de acesso mais básico até as regras dinâmicas que personalizam a visão de dados para cada indivíduo na organização.
4.1 - O Básico da Governança: Papéis no Workspace e Publicação de Apps
A primeira camada de segurança não está nos dados, mas no acesso ao próprio relatório. No Serviço do Power BI, temos duas formas principais de compartilhar conteúdo: diretamente de um Workspace ou através de um Aplicativo (App).
- Workspaces: Pense neles como a "oficina" dos desenvolvedores. É onde os relatórios, dashboards e conjuntos de dados são criados e colaborados. O acesso aqui é controlado por quatro papéis principais:
- Admin: Controle total. Pode adicionar e remover outros usuários, inclusive outros admins.
- Membro (Member): Pode publicar, editar e compartilhar conteúdo, mas não pode gerenciar os usuários do workspace.
- Contribuidor (Contributor): Pode publicar e editar conteúdo, mas não pode compartilhar ou publicar o aplicativo. É o papel ideal para desenvolvedores que não devem gerenciar a distribuição.
- Visualizador (Viewer): Apenas pode ver e interagir com o conteúdo existente, sem poder editar nada.
- Aplicativos (Apps): Esta é a forma correta e profissional de distribuir conteúdo para os usuários finais. Um App é uma "vitrine" polida que você publica a partir de um workspace. Ele oferece uma experiência de navegação mais limpa e, crucialmente, um controle de permissões mais refinado através dos "Públicos" (Audiences), permitindo que você mostre ou oculte diferentes relatórios para diferentes grupos de usuários.
4.2 - O Coração da Segurança: Segurança em Nível de Linha (RLS)
Esta é a técnica mais poderosa do nosso arsenal. A Segurança em Nível de Linha (RLS) permite que pessoas diferentes, acessando o exatamente mesmo relatório, vejam dados diferentes. A mágica acontece porque o Power BI filtra as linhas das tabelas dinamicamente com base em quem é o usuário.
Existem duas formas de implementar RLS: Estática e Dinâmica.
RLS Estática: A Abordagem por Grupos
Neste método, criamos "funções" (roles) com regras de filtro fixas para diferentes grupos de usuários.
Na Prática: Dividindo Recife por Zonas
Vamos imaginar que, no nosso projeto de arborização, a cidade é dividida em zonas de manutenção. O gestor da "Zona Norte" só pode ver os dados dos bairros dessa região.
- No Power BI Desktop, vá para a aba "Modelagem" e clique em "Gerenciar funções".
- Na janela que se abre, clique em "Criar". Dê à função o nome de Gestor_Zona_Norte.
- Selecione a nossa tabela de dimensão dBairro.
- Na caixa de expressão do filtro de tabela DAX, escreva a regra. Para ser realista, vamos usar bairros reais da Zona Norte do Recife:
[bairro] IN {"Casa Amarela", "Espinheiro", "Graças", "Tamarineira", "Jaqueira"}
5. Clique em "Salvar". Para testar, clique em "Exibir como" na mesma aba "Modelagem", marque a nova função Gestor_Zona_Norte e veja como o relatório inteiro se filtra automaticamente, mostrando dados apenas para esses bairros.
- Vantagem: Simples e rápido de configurar para poucos grupos.
- Desvantagem: Inviável de manter se você tiver dezenas ou centenas de regras diferentes.
RLS Dinâmica: A Abordagem Inteligente
Este é o padrão-ouro para segurança em nível corporativo. Criamos uma única regra que se adapta a qualquer usuário.
Na Prática: Cada Gestor Vê Apenas o Seu Bairro
Imagine que cada bairro do Recife tem um gestor, e cada gestor tem um e-mail corporativo. Queremos que, ao logar, o gestor veja apenas os dados do seu bairro.
1. Pré-requisito: Precisamos de uma "tabela de mapeamento" que diga qual e-mail gerencia qual bairro. Vamos imaginar que importamos uma tabela dGestores para o nosso modelo com duas colunas: [Email_Gestor] e [Bairro_Gerenciado].
2. Criação da Regra:
- Em "Gerenciar funções", crie uma única função chamada Regra_Gestor_de_Bairro.
- Desta vez, selecione a tabela dGestores para aplicar o filtro.
- Na caixa de expressão DAX, escreva a fórmula mágica:
[Email_Gestor] = USERPRINCIPALNAME()
3. A Mágica do DAX: A função USERPRINCIPALNAME() é especial. Quando publicada no Serviço do Power BI, ela retorna automaticamente o e-mail de login do usuário que está visualizando o relatório.
4. O Fluxo: O que acontece?
- O usuário gestor.boaviagem@empresa.com abre o relatório.
- A regra [Email_Gestor] = "gestor.boaviagem@empresa.com" é aplicada na tabela dGestores.
- A tabela dGestores é filtrada para mostrar apenas a linha onde consta o bairro "Boa Viagem".
- Como a dGestores está relacionada à dBairro (ou diretamente à fArvores), esse filtro se propaga por todo o modelo.
- O resultado é que o gestor só vê os dados de "Boa Viagem", de forma automática e segura.
- Vantagem: Infinitamente escalável. Para adicionar ou mudar permissões, você só precisa atualizar a tabela de mapeamento, sem nunca mais tocar no relatório do Power BI.
4.3 - Segurança em Nível de Objeto (OLS): Ocultando Colunas Sensíveis
E se o problema não for filtrar linhas, mas ocultar colunas ou tabelas inteiras? Imagine que nossa tabela fArvores tenha uma coluna [Custo_Unitario_Plantio]. Queremos que todos vejam os dados de plantio, mas que apenas o grupo "Financeiro" possa ver os custos.
Para isso, usamos a Segurança em Nível de Objeto (OLS).
É um conceito avançado e há um ponto crucial aqui: a OLS não pode ser configurada diretamente na interface do Power BI Desktop. Ela exige o uso de uma ferramenta externa, como o Tabular Editor, que se conecta ao seu modelo de dados e permite definir permissões em nível de coluna ou tabela para cada função. Este é um tópico que aprofundaremos no Pilar VI, sobre ferramentas externas.
4.4 - Resumo do Pilar IV: Construindo a Fortaleza da Confiança
A segurança dos dados não é uma etapa final, mas uma parte integrante do design do seu dashboard. Para construir uma solução robusta:
- Comece com a governança básica, definindo os papéis do Workspace e publicando o conteúdo através de Aplicativos.
- Implemente a Segurança em Nível de Linha (RLS) para garantir que os usuários vejam apenas os dados que lhes são pertinentes.
- Sempre que possível, opte pela RLS Dinâmica para criar uma solução escalável e de fácil manutenção.
- Para dados verdadeiramente sensíveis (colunas ou tabelas), explore a Segurança em Nível de Objeto (OLS) com ferramentas externas.
Com nosso dashboard não apenas rápido, mas também seguro e relevante para cada usuário, podemos agora nos preocupar com a próxima etapa do ciclo de vida de um projeto profissional: como o tiramos do nosso computador e o entregamos de forma controlada para toda a organização? É hora de falar sobre a linha de montagem do BI.
Pilar V: A Linha de Montagem – DevOps e o Ciclo de Vida do BI
Um dos maiores saltos de maturidade para um profissional de dados é perceber que seu trabalho não termina quando o dashboard está "pronto". Na verdade, é aí que o trabalho começa. A implantação de um relatório em um ambiente corporativo é como mover um cérebro de um laboratório para o mundo real. O processo precisa ser meticuloso, testado e à prova de falhas.
A abordagem de "salvar e publicar direto para todo mundo" é o equivalente a realizar uma cirurgia cerebral sem luvas. É arriscado e pouco profissional. A solução é adotar os princípios de DevOps (Desenvolvimento + Operações), uma filosofia do mundo do desenvolvimento de software que visa unificar o desenvolvimento, os testes e a implantação em um fluxo contínuo e automatizado.
Para nós, Neurocientistas de Dados, isso significa criar uma "linha de montagem" que garanta que cada nova versão do nosso dashboard seja implantada de forma suave e segura.
5.1 - Os Ambientes Isolados: DEV, TEST e PROD
- A prática fundamental do DevOps é a separação de ambientes. Nunca, em hipótese alguma, devemos desenvolver novas funcionalidades diretamente no relatório que os usuários finais estão acessando.
- Desenvolvimento (DEV): Este é o nosso laboratório, o nosso Power BI Desktop. É aqui que experimentamos, criamos novas medidas, testamos visuais e quebramos as coisas sem medo. O acesso a este ambiente é restrito à equipe de desenvolvimento.
- Teste (TEST): Este é o nosso "ensaio clínico". Uma vez que uma nova versão do dashboard está pronta no ambiente DEV, nós a publicamos em um workspace de Teste. Aqui, um grupo seleto de usuários-chave (os "beta testers") pode interagir com o relatório, validar os dados e procurar por bugs em um ambiente controlado que espelha o de produção.
- Produção (PROD): Esta é a "vida real". É o workspace final, de onde o Aplicativo (App) é publicado para todos os usuários da empresa. O conteúdo aqui é considerado estável, validado e confiável. Só promovemos uma versão para PROD depois que ela foi aprovada em TEST.
Essa separação garante que o usuário final nunca seja exposto a um relatório quebrado ou a dados incorretos, preservando a confiança na nossa solução de BI.
5.2 - A Esteira Automatizada: Pipelines de Implantação do Power BI
"Mas gerenciar três versões diferentes do mesmo relatório parece complicado e manual!", você pode pensar. E seria, se não fosse por uma das ferramentas mais poderosas do ecossistema Power BI Premium: os Pipelines de Implantação (Deployment Pipelines).
Um pipeline é uma esteira automatizada que move seu conteúdo entre os ambientes DEV, TEST e PROD com apenas alguns cliques.
Na Prática: Configurando Nosso Primeiro Pipeline
- Pré-requisito: Você precisa de uma licença Power BI Premium (por capacidade ou por usuário) e precisa ser admin de três workspaces (um para cada ambiente: Arborizacao_DEV, Arborizacao_TEST, Arborizacao_PROD).
- Criação do Pipeline: No Serviço do Power BI, no menu à esquerda, clique em "Pipelines de implantação" e em "Criar pipeline".
- Atribuição dos Workspaces: O pipeline terá três estágios visuais. Em cada um, você atribui o workspace correspondente (DEV, TEST, PROD).
- O fluxo de trabalho:
- Você publica a primeira versão do seu dashboard do Power BI Desktop para o workspace Arborizacao_DEV.
- No pipeline, você verá seu conteúdo no estágio de Desenvolvimento. Clique no botão "Implantar". O Power BI irá copiar automaticamente todo o conteúdo (relatório, conjunto de dados, etc.) para o workspace de Teste.
- A Mágica dos Parâmetros: Durante a implantação, você pode configurar regras para, por exemplo, mudar a fonte de dados automaticamente (apontar para um banco de dados de teste em vez do de desenvolvimento).
- Após a validação no ambiente de Teste, você volta ao pipeline e clica em "Implantar" novamente, movendo o conteúdo de TEST para PROD.
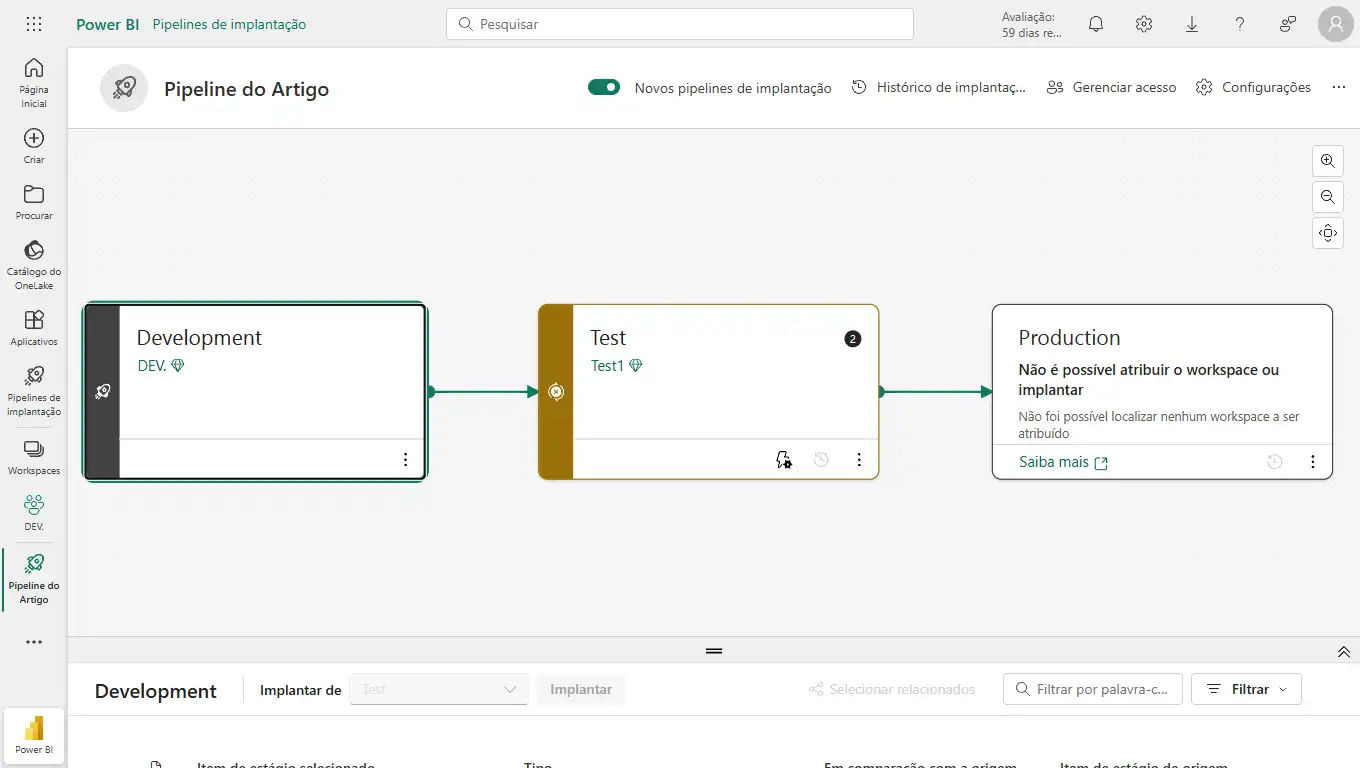
O pipeline compara o conteúdo entre os estágios, mostrando exatamente o que mudou, dando a você um controle total sobre o processo e eliminando o risco de erros manuais.
5.3 - A Fronteira Final: CI/CD e a Integração com Git
Este é o nível mais avançado de maturidade em DevOps para BI. Ele conecta tudo o que aprendemos.
Lembram do nosso Passo a Passo Profissional no início do artigo, quando salvamos nosso arquivo como um Projeto do Power BI (.pbip)? Aquele método transforma nosso relatório em arquivos de texto (model.bim, report.json). E o que fazemos com arquivos de texto no mundo do desenvolvimento de software? Nós os versionamos com Git.
O fluxo de trabalho de elite se parece com isto:
- Desenvolvimento Local: O analista faz uma alteração no seu dashboard no Power BI Desktop e salva o projeto .pbip.
- Versionamento com Git: Usando o VS Code, o analista vê que o arquivo model.bim mudou. Ele "commita" essa mudança para um repositório Git (como GitHub ou Azure DevOps) com uma mensagem clara: "Adicionada medida de crescimento de plantio".
- Integração contínua (CI): Ferramentas de automação no Azure DevOps podem detectar esse novo commit e, automaticamente, usar APIs para publicar o .pbip no workspace de desenvolvimento (DEV) no serviço do Power BI.
- Implantação Contínua (CD): A partir daí, os Pipelines de Implantação do Power BI assumem, permitindo que o gerente de BI promova essa nova versão de DEV para TEST e para PROD de forma controlada.
Este ciclo completo de CI/CD (Integração Contínua / Implantação Contínua) é o ápice da governança e da engenharia de BI. Ele torna o processo de atualização de relatórios tão robusto, rastreável e seguro quanto o desenvolvimento dos aplicativos de software mais críticos.
5.4 - Resumo do Pilar V: Da Mesa do Analista para a Mão da Empresa
A implantação não é um "pós-escrito" do desenvolvimento; é uma disciplina em si. Para garantir que nossos insights cheguem de forma segura e eficiente aos usuários, devemos:
- Adotar a mentalidade de ambientes separados (DEV, TEST, PROD).
- Utilizar os Pipelines de Implantação para automatizar e controlar a promoção de conteúdo entre os estágios.
- Aspirar ao nível mais alto de maturidade, integrando o desenvolvimento baseado em arquivos de projeto (.pbip) com sistemas de controle de versão como o Git, habilitando um verdadeiro ciclo de DevOps para BI.
Com nosso cérebro digital não apenas otimizado e seguro, mas também com um processo de "amadurecimento" e "liberação para a sociedade" bem definido, estamos prontos para a etapa final da nossa jornada de especialista: a sala de cirurgia, onde usaremos instrumentos de precisão para os diagnósticos mais complexos.
Pilar VI: A Sala de Cirurgia – Ferramentas Externas e Otimização Extrema
Como Neurocientistas de Dados, nós entendemos que para entender o cérebro (nosso modelo de dados), às vezes precisamos de mais do que uma simples conversa. Precisamos de ferramentas de imagem como uma ressonância magnética, ou instrumentos cirúrgicos de alta precisão. No ecossistema Power BI, essas ferramentas avançadas são aplicações externas que se conectam ao nosso modelo e nos dão superpoderes.
As duas ferramentas mais essenciais no cinto de utilidades de qualquer profissional de Power BI de elite são o DAX Studio e o Tabular Editor. Elas são gratuitas, mantidas pela comunidade e absolutamente transformadoras. Vamos dissecá-las.
6.1 - O Microscópio: Diagnóstico de Precisão com DAX Studio
Se o Analisador de Desempenho é o nosso "estetoscópio", o DAX Studio é a nossa ressonância magnética funcional (fMRI). Ele não nos diz apenas se uma medida DAX é lenta; ele nos mostra exatamente por quê, revelando o que o motor VertiPaq está fazendo por trás dos panos.
Na Prática: Conectando ao Nosso Modelo de Recife
- Com seu arquivo Analise Arborizacao Recife.pbix aberto.
- Abra o DAX Studio. Ele automaticamente detectará e mostrará seu arquivo na lista de fontes de dados "PBI / SSDT".
- Clique em "Conectar".
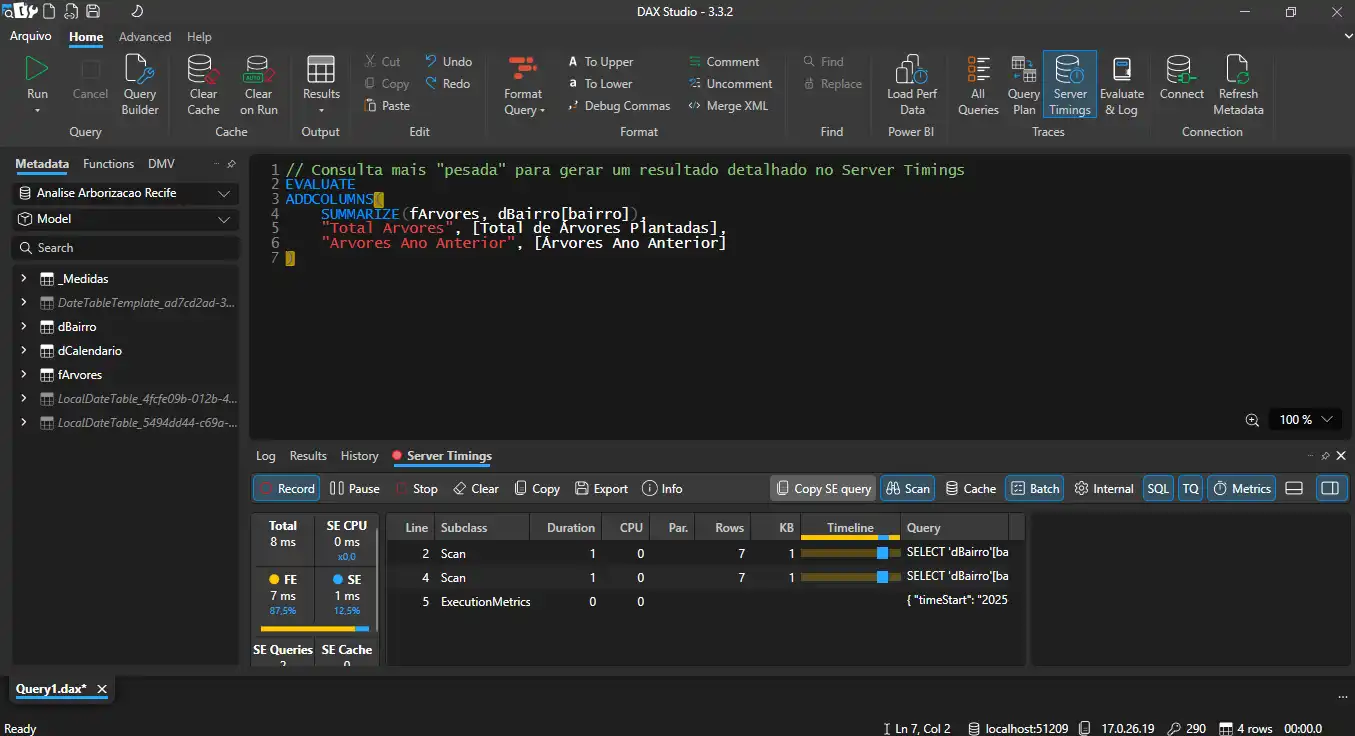
Funcionalidade Chave 1: Análise de Plano de Consulta (Query Plan)
Cada consulta DAX que você escreve é traduzida pelo Power BI em um "plano de execução". O DAX Studio nos permite ver esse plano.
Como usar: Cole uma medida do nosso projeto no DAX Studio (envolvida em um EVALUATE). Por exemplo:
EVALUATE
SUMMARIZECOLUMNS(
dCalendario[Ano],
"Arvores Ano Anterior", [Árvores Ano Anterior]
)
Vá na aba "Plano de Consulta" (Query Plan). Você verá um plano físico e lógico. A chave é procurar pela distinção entre Storage Engine (SE) e Formula Engine (FE). O Storage Engine é o motor de dados super-rápido. O Formula Engine é mais lento e lida com cálculos complexos. Uma consulta otimizada passa o máximo de tempo possível no SE.
Funcionalidade Chave 2: Timings do Servidor (Server Timings)
Esta é a visão mais detalhada da performance da sua consulta.
- Como usar: Na aba "Traços" (Traces), ative "Timings do Servidor". Limpe o cache (Limpar Cache) e execute sua consulta novamente.
- O que revela: Ele mostra exatamente quantos milissegundos foram gastos no Formula Engine vs. no Storage Engine, e quantas vezes o Formula Engine precisou "chamar de volta" (callback) o Storage Engine, um sinal claro de ineficiência (geralmente causado por transições de contexto - a "guerra" que discutimos no Pilar II).
6.2 - O Bisturi de Precisão: Modelagem Avançada com Tabular Editor
Se o DAX Studio é para diagnóstico, o Tabular Editor é para cirurgia. Ele permite editar a estrutura do seu modelo de dados (model.bim) diretamente, de forma muito mais rápida e poderosa que a interface do Power BI Desktop.
Funcionalidade Chave 1: Edição em Massa e Scripting
No Power BI Desktop, criar 10 medidas é um processo repetitivo. No Tabular Editor, você pode automatizá-lo.
- Na Prática: Usando a janela de "Advanced Scripting", você pode executar scripts em C# para criar ou modificar objetos no seu modelo. Por exemplo, você poderia ter um script que automaticamente cria 5 medidas de inteligência de tempo (YTD, QTD, MTD, etc.) para cada medida base que você selecionar. Isso economiza horas de trabalho e reduz erros.
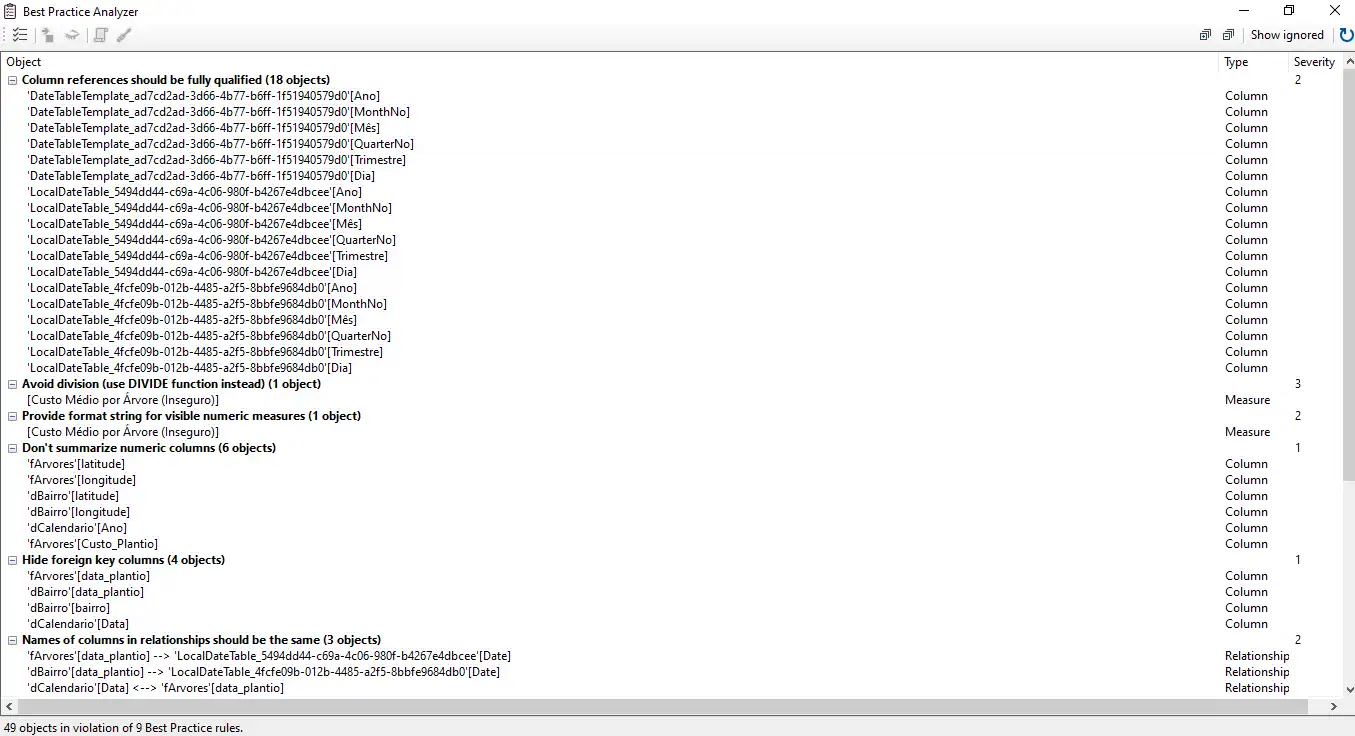
Funcionalidade Chave 2: Analisador de Melhores Práticas (Best Practice Analyzer - BPA)
Esta é, talvez, a funcionalidade mais valiosa para garantir a qualidade do seu modelo.
- Como funciona: O BPA é um conjunto de regras, criado por especialistas da comunidade (incluindo a equipe da SQLBI), que analisa seu modelo e aponta violações de melhores práticas de modelagem e performance.
Exemplos de regras que ele detecta:
- "Não use a função IF para tratar divisões por zero (use DIVIDE)."
- "Oculte colunas de chave estrangeira da sua tabela de fatos."
- "Não use colunas de ponto flutuante para colunas de baixa cardinalidade."
- "Tabelas de dimensão devem ter uma chave única."
Funcionalidade Chave 3: Grupos de Cálculo (Calculation Groups)
Este é um dos conceitos mais avançados e poderosos do DAX, e só pode ser implementado através do Tabular Editor.
- O Conceito: Em vez de criar dezenas de medidas de inteligência de tempo (ex: [Vendas YTD], [Custo YTD], [Lucro YTD]), você cria um único Grupo de Cálculo para a Lógica de Tempo (YTD, QTD, etc.).
- O Resultado: Você aplica esse grupo de cálculo a qualquer medida base que você quiser. Você arrasta sua medida [Total de Árvores Plantadas] para um visual, adiciona um filtro do seu Grupo de Cálculo e seleciona "YTD". A mágica acontece. Isso pode reduzir o número de medidas no seu modelo em até 90%, tornando-o absurdamente mais limpo, leve e fácil de manter.
6.3 - Resumo do Pilar VI: Expandindo os Limites da Mente e da Ferramenta
O desenvolvimento profissional em Power BI vai muito além da interface gráfica. Para atingir o nível de elite, é preciso dominar as ferramentas que nos permitem ver e interagir com o "código-fonte" do nosso cérebro de dados.
- Use o DAX Studio como seu laboratório de diagnóstico para entender profundamente a performance de suas consultas.
- Use o Tabular Editor como sua sala de cirurgia para editar o modelo de forma eficiente, aplicar as melhores práticas automaticamente e implementar lógicas de cálculo escaláveis.
Com nosso dashboard otimizado, seguro, implantado de forma profissional e agora com a capacidade de ser diagnosticado e modificado com precisão cirúrgica, cobrimos o ciclo de vida completo do desenvolvimento de BI.
O Efeito Dominó – O Impacto da Otimização no Mundo Real (Hoje e Amanhã)
Até agora, nossa jornada tem sido uma exploração profunda da mente da máquina. Desmontamos o dashboard, analisamos cada componente, da fonte SQL à segurança, do modelo de dados ao ciclo de vida, e o reconstruímos com a precisão de um cirurgião e a filosofia de um neurocientista. O resultado é uma solução que não é apenas funcional, mas performática, segura e governada.
Mas a história não termina no nosso computador. O verdadeiro valor de todo esse esforço meticuloso não está nos milissegundos que economizamos, mas no impacto que esses milissegundos causam no mundo real. Este pilar final explora o efeito dominó da otimização, mostrando como uma única decisão técnica bem-feita pode transformar a forma como uma empresa opera e como um profissional de dados constrói sua carreira nos dias de hoje.
A Transformação do Negócio: De Relatórios Estáticos a Ecossistemas de Decisão
Nos dias de hoje, Agosto de 2025, a conversa sobre "cultura de dados" já é antiga. A maioria das empresas tem acesso a dados e a ferramentas de BI como o Power BI. A nova fronteira competitiva não é ter dados, mas ser capaz de agir sobre eles na velocidade do negócio. É aqui que a otimização se torna uma vantagem estratégica crucial.
- A Velocidade da Decisão: Pense em uma equipe de marketing analisando o resultado de uma campanha digital. Em uma empresa com um dashboard lento e não otimizado, o relatório pode levar horas (ou dias!) para ser atualizado e analisado. Quando a equipe finalmente percebe que um anúncio específico está performando mal, milhares de reais já foram desperdiçados. Em contrapartida, uma empresa que investiu na otimização de ponta a ponta (do SQL ao visual) permite que essa mesma equipe analise os dados quase em tempo real. Eles identificam o anúncio ineficaz em minutos, pausam a campanha, e realocam o orçamento para os anúncios que estão funcionando. A otimização, aqui, traduz-se diretamente em ROI e eficiência de capital.
- A Democratização da Confiança: Um dos maiores custos ocultos em BI é a falta de adoção. As empresas investem fortunas em tecnologia, mas os gestores continuam usando planilhas. Por quê? Porque não confiam nos dashboards. A lentidão gera desconfiança ("Será que está quebrado?"), e a falta de segurança granular (nosso Pilar IV) os torna irrelevantes ("Estou vendo os dados de todo mundo, não os meus"). Ao construir dashboards rápidos e seguros com RLS, que falam a língua de cada usuário, transformamos desconfiança em confiança. A adoção aumenta, o "Shadow IT" (as planilhas de Excel perigosas e descentralizadas) diminui, e a empresa passa a ter uma única fonte da verdade que é, de fato, utilizada.
- A Eficiência de Custos na Nuvem: No mundo do cloud computing, paga-se por aquilo que se usa: armazenamento, tempo de processamento (CPU), etc. Um modelo de dados de 2GB que demora 30 minutos para atualizar consome recursos de nuvem significativamente mais caros do que um modelo otimizado de 50MB que atualiza em 2 minutos. O profissional que domina a otimização (especialmente no SQL e na modelagem) não entrega apenas velocidade ao usuário; ele entrega uma redução de custos direta e mensurável para a empresa.
A Evolução do Profissional de Dados: Do Construtor de Gráficos ao Arquiteto de Confiança
A era do "fazedor de gráficos" acabou. Nos dias de hoje, saber arrastar um campo para um visual no Power BI é o básico. As ferramentas de IA, como o Copilot, já conseguem fazer isso com um simples comando de voz. O que, então, diferencia um profissional de dados de elite em 2025?
É a profundidade. É o domínio de todos os pilares que discutimos.
- O Profissional "Full-Stack" de BI: O mercado não busca mais especialistas isolados ("o cara do SQL" ou "a moça do DAX"). Ele busca o profissional que entende o ciclo de vida completo do dado. Alguém que consegue discutir a otimização de uma VIEW com o DBA (Pilar Zero), arquitetar um modelo estrela robusto (Pilar I), escrever uma medida DAX performática (Pilar II), projetar uma interface limpa (Pilar III), implementar regras de segurança dinâmicas (Pilar IV), gerenciar o ciclo de vida com pipelines (Pilar V) e diagnosticar problemas complexos com ferramentas externas (Pilar VI). Este é o profissional que se torna indispensável.
- O Valor Estratégico: Ao dominar esses pilares, o profissional deixa de ser um executor de tarefas e se torna um parceiro estratégico do negócio. Ele não responde apenas "qual foi a venda?"; ele questiona "qual a forma mais eficiente e segura de responder a essa pergunta para cada pessoa na empresa?". Essa mudança de mentalidade eleva o analista de uma posição técnica para uma posição de consultor de confiança.
O Horizonte Futuro: IA, Microsoft Fabric e o Neurocientista como Curador
Se olharmos para o horizonte, o papel da otimização se torna ainda mais crítico. Com a ascensão de plataformas de dados unificadas como o Microsoft Fabric e a onipresença de Inteligência Artificial Generativa, o desafio muda.
A IA pode gerar uma consulta SQL ou uma medida DAX complexa em segundos. Isso é um ganho de produtividade imenso. No entanto, a IA, em seu estado atual, é uma péssima otimizadora. Ela frequentemente escreve códigos que são funcionalmente corretos, mas performaticamente terríveis.
É aqui que o papel do Neurocientista de Dados se torna o grande diferencial humano. Nosso trabalho no futuro não será tanto o de escrever o código do zero, mas o de curar, validar e otimizar o código gerado pela IA. Seremos os mestres que sabem olhar para uma consulta DAX criada por um Copilot e dizer: "Isso funciona, mas vai quebrar o motor do VertiPaq. A forma correta de pensar sobre este problema é esta...".
Seremos os arquitetos que garantem que os ecossistemas de dados, cada vez mais complexos e integrados no Fabric, não se transformem em pântanos de lentidão. A habilidade de entender a "mente da máquina" em cada camada, do SQL ao visual, é o que garantirá o nosso valor em uma era de automação inteligente.

A Arte da Narrativa – A Otimização Final é a Clareza
Nós viajamos pelas profundezas da otimização. Da fazenda dos dados com SQL à arquitetura do nosso cérebro de BI no Modelo de Dados; da fluência na conversa com o DAX à eficiência da nossa Apresentação visual; da Fortaleza da Segurança à Linha de Montagem do DevOps, culminando na Sala de Cirurgia com as ferramentas de elite. Construímos um dashboard que é, tecnicamente, uma obra-prima: rápido, seguro, robusto.
Mas um carro de Fórmula 1, com o motor mais potente e a aerodinâmica mais avançada, é inútil se o piloto não souber para onde está indo. A performance técnica é apenas o preço da entrada. A vitória está na clareza do destino.
A otimização final, o verdadeiro objetivo de toda a nossa jornada, não é reduzir os milissegundos de carregamento de um visual. É reduzir os segundos de confusão na mente de quem o consome. O objetivo é acelerar a chegada do "momento Aham!", aquele instante de epifania em que o dado se transforma em insight, e o insight se transforma em uma decisão. Um dashboard tecnicamente perfeito que não gera este momento é, em sua essência, um fracasso.
Essa última sessão é sobre a otimização da comunicação. É sobre usar a neurociência não para acelerar a máquina, mas para clarear a mensagem.
O Cérebro Preguiçoso: Guiando o Olhar com o Design
O psicólogo e economista Daniel Kahneman, em sua obra seminal "Rápido e Devagar", nos ensina que o cérebro humano opera em dois sistemas. O Sistema 1 é rápido, intuitivo e preguiçoso; ele odeia gastar energia. O Sistema 2 é lento, analítico e deliberado. Um dashboard confuso e desorganizado força o usuário a ativar seu Sistema 2 para o simples ato de entender o que ele está vendo, esgotando sua energia mental antes mesmo que a análise comece.
Um design de excelência trabalha a favor do preguiçoso Sistema 1. Ele não apresenta um quebra-cabeça, mas sim uma paisagem clara, guiando o olhar do usuário de forma intuitiva.
- Hierarquia Visual é Tudo: Nem toda informação tem o mesmo peso. A informação mais importante (o KPI principal, a principal tendência) deve ser o elemento de maior destaque visual na tela. Use o tamanho, o contraste e a posição a seu favor. A convenção ocidental de leitura (em formato de Z ou F) nos diz que o canto superior esquerdo de qualquer tela é o "ponto de ouro". Coloque sua conclusão mais importante ali. Não crie uma parede de gráficos do mesmo tamanho. Crie um ponto focal.
- A "Dieta" de Cores: Um dashboard não é uma obra de arte abstrata; é um instrumento de clareza. O uso excessivo de cores (um "saco de confete" visual) gera um ruído que o cérebro precisa filtrar, gastando energia. A melhor prática é usar uma paleta de cores neutras e suaves (cinza, azul claro) para a base do relatório, e reservar uma ou duas cores de destaque (um laranja, um verde vivo) para serem usadas estrategicamente, apenas para sinalizar o que é bom, o que é ruim ou o que exige atenção.
A Voz dos Dados: Títulos e Anotações que Contam uma História
Os dados não falam por si sós. Nós somos os seus tradutores, os seus contadores de histórias. Um gráfico sem um bom título é como uma imagem sem legenda: aberto a interpretações, incompleto. A maior oportunidade perdida na maioria dos dashboards é o uso de títulos descritivos em vez de títulos narrativos.
- Título Descritivo (Fraco): "Vendas por Mês"
- Título Narrativo (Forte): "Vendas Disparam 25% no 2º Trimestre Após Lançamento do Produto X"
O segundo título não apenas descreve o que o gráfico mostra; ele já entrega a principal conclusão. Ele transforma o usuário de um "explorador" em um "leitor informado".
Na Prática: Use a funcionalidade de "Título Dinâmico" do Power BI. Crie uma medida DAX que gere um título narrativo que muda de acordo com os filtros aplicados pelo usuário. Imagine um título que se atualiza para: "No bairro de Boa Viagem, a espécie de árvore mais plantada em 2024 foi o Ipê Amarelo." O dashboard passa a conversar com o usuário.
Construindo a Jornada: O Relatório como um Roteiro
Um relatório de excelência raramente é uma página única e sobrecarregada. Ele é uma história com começo, meio e fim, que leva o usuário pela mão em uma jornada de descoberta.
- Aba 1 (A Capa / O Resumo Executivo): A visão de helicóptero. Deve conter os 3 a 5 KPIs mais importantes e os principais insights. Um executivo deve conseguir abrir esta aba e, em 30 segundos, entender o "quê": o que está acontecendo com o negócio?
- Abas 2, 3... (O Desenvolvimento / As Análises Profundas): Cada aba deve ser dedicada a responder uma pergunta específica. É aqui que o usuário explora o "porquê". Por que as vendas caíram? Qual a performance por região? Qual o perfil do nosso cliente? O uso de Drill-through (Obter Detalhes) é o mecanismo que conecta o "quê" ao "porquê", permitindo que o usuário clique em um número no resumo executivo e seja levado diretamente para a análise detalhada que o explica.
- Última Aba (O Apêndice): Uma página com notas de rodapé, definições de métricas, informações sobre a fonte de dados e a data da última atualização. Isso constrói confiança e transparência.
Resumo: O Veredito do Comunicador
A jornada do Neurocientista de Dados nos mostra que a otimização técnica e a arte da comunicação são duas faces da mesma moeda. Ambas buscam o mesmo objetivo: reduzir a fricção. Uma reduz a fricção entre o clique e a resposta da máquina; a outra, entre a visualização da resposta e o entendimento da mente humana.
Um grande analista não é apenas quem constrói o modelo mais rápido, mas quem constrói a ponte mais curta entre o dado e a decisão.
Com a técnica refinada e a arte da comunicação dominada, nosso Neurocientista de Dados completou sua formação. Estamos, agora sim, prontos para o nosso veredito final.

Conclusão: A Velocidade do Pensamento – O Veredito do Neurocientista de Dados
A jornada que percorremos nestas páginas começou em uma noite de sábado, com a frustração diante de um dashboard quebrado e uma pergunta simples: por que a tecnologia que deveria empoderar estava, na verdade, criando barreiras? A resposta inicial, descoberta na metódica desconstrução daquele projeto, revelou os três pilares fundamentais da otimização dentro do Power BI: a Fundação do modelo de dados, a Conversa em DAX e a Apresentação visual.
Mas a investigação não parou aí. Aquela busca inicial pela velocidade se mostrou apenas a ponta do iceberg. Ela nos forçou a olhar para trás, para a Fonte da Verdade com SQL, e a entender que a otimização começa na "fazenda", muito antes de os ingredientes chegarem à nossa "cozinha". Ela nos forçou a olhar para os lados, para a Fortaleza da Segurança e a Linha de Montagem do DevOps, percebendo que um dashboard profissional não é apenas rápido, mas também confiável e com um ciclo de vida governado. E nos deu a coragem de entrar na Sala de Cirurgia, usando as ferramentas de especialista para realizar diagnósticos e modificações com precisão absoluta.
Descobrimos que o impacto de nosso trabalho reverbera por todo o negócio, num verdadeiro Efeito Dominó que acelera decisões e gera confiança. E, por fim, aprendemos que a otimização mais crucial de todas era a da própria Narrativa, a arte de transformar dados em uma história clara e convincente.
Ao final desta jornada, o que fica não é um checklist de funções DAX ou de configurações de segurança. É uma nova filosofia de trabalho. O verdadeiro ofício do Neurocientista de Dados não é ser um mestre da tecnologia. A tecnologia é o meio. Nosso trabalho é sermos arquitetos de clareza. Nosso inimigo fundamental não é uma consulta lenta ou um modelo complexo; é a fricção cognitiva, a barreira invisível de esforço que se interpõe entre a mente de um tomador de decisão e o insight que ele procura.
Cada linha de código SQL que pré-agrega dados, cada relacionamento criado corretamente, cada medida DAX escrita com elegância, cada visual escolhido com propósito e cada camada de segurança implementada têm um único objetivo em comum: fazer a tecnologia desaparecer. Buscamos criar uma experiência tão fluida, tão intuitiva, que o dashboard deixe de ser uma ferramenta a ser "operada" e se torne uma extensão natural do raciocínio do usuário.
Portanto, da próxima vez que você abrir um arquivo em branco no Power BI, lembre-se que você não está apenas arrastando campos ou escrevendo código. Você está projetando uma experiência. Você está moldando a forma como as decisões serão tomadas.
A jornada para entender a mente da máquina, no fim, nos ensina a projetar para a mente humana. E essa é a otimização mais poderosa de todas.
Referências e Leituras Recomendadas
Livros e Autores de Referência (A Base Filosófica)
- Daniel Kahneman - "Rápido e Devagar: Duas Formas de Pensar" (Original: "Thinking, Fast and Slow")
- Relevância: Leitura essencial para entender a psicologia por trás da tomada de decisão. Seus conceitos de "Sistema 1" (rápido, intuitivo) e "Sistema 2" (lento, analítico) são a base para a nossa filosofia de design de dashboards, que busca reduzir a carga cognitiva e apresentar insights que o Sistema 1 possa absorver instantaneamente.
- Don Norman - "O Design do Dia a Dia" (Original: "The Design of Everyday Things")
- Relevância: Uma obra-prima sobre design centrado no usuário. Embora não fale de dados, seus princípios sobre como criar objetos e sistemas intuitivos são diretamente aplicáveis à construção de dashboards. Ele nos ensina a projetar para a clareza, a evitar a ambiguidade e a criar uma experiência sem frustrações para o usuário final.
- Ralph Kimball - "A Coleção de Ferramentas do Data Warehouse" (Original: "The Data Warehouse Toolkit")
- Relevância: Considerado o "pai" da modelagem de dados dimensional. Sua obra é a referência definitiva para entender os princípios por trás do Esquema Estrela, que é a base do nosso Pilar I (A Fundação).
Ferramentas Essenciais (O Arsenal do Analista)
- Power BI Desktop & Service
- Descrição: A plataforma central da nossa análise, onde os dados são modelados, analisados e visualizados.
- Site Oficial: https://powerbi.microsoft.com
- DAX Studio
- Descrição: O nosso "microscópio" para diagnóstico de performance. Ferramenta gratuita e essencial para analisar a execução de consultas DAX, entender os timings dos motores SE/FE e inspecionar o modelo de dados.
- Site Oficial: https://daxstudio.org/
- Tabular Editor (2 & 3)
- Descrição: O nosso "bisturi de precisão". A ferramenta de elite para modelagem de dados avançada, edição em massa de medidas, aplicação de melhores práticas (BPA) e implementação de Grupos de Cálculo. A versão 2 é gratuita e a 3 é uma suíte comercial poderosa.
- Site Oficial: https://www.tabulareditor.com/
- Visual Studio Code
- Descrição: Editor de código versátil usado para gerenciar os arquivos de projeto do Power BI (
.pbip) e para o controle de versão com Git, permitindo a implementação de um ciclo de DevOps para BI. - Site Oficial: https://code.visualstudio.com/
Comunidades e Fontes de Conhecimento Online
- SQLBI (Marco Russo & Alberto Ferrari)
- Descrição: Considerada a fonte de conhecimento mais respeitada do mundo em DAX e modelagem de dados para o ecossistema Microsoft. Seus artigos, vídeos e cursos são a referência para qualquer tópico avançado. O arquivo de regras do Best Practice Analyzer é mantido por eles.
- Site Oficial: https://www.sqlbi.com/
- Microsoft Power BI Documentation & Blog
- Descrição: A fonte oficial para todas as atualizações, guias técnicos e documentação de funcionalidades da plataforma Power BI e do ecossistema Fabric.
- Documentação: https://docs.microsoft.com/pt-br/power-bi/
- Blog: https://powerbi.microsoft.com/pt-br/blog/
- GitHub
- Descrição: A maior plataforma de hospedagem de código do mundo. Essencial para o controle de versão de projetos de BI (Pilar V) e para baixar ferramentas open-source como o Tabular Editor 2.
- Site Oficial: https://github.com/
Fontes de Dados (Nosso Estudo de Caso)
- Portal de Dados Abertos da Prefeitura do Recife
- Descrição: A fonte de dados utilizada em nosso estudo de caso prático para a análise de arborização urbana. Um exemplo de recurso cívico para a prática de análise de dados.
- Site Oficial: https://dados.recife.pe.gov.br/





Obrigado @Kaiky
Obrigado @Mari
Respondendo sua pergunta @Cauan Ferrer. Sim, a filosofia é totalmente viável e, a longo prazo, é a abordagem mais rápida.
A lógica é que a pressa inicial para atender a um prazo curto gera "dívida técnica". O tempo que você "economiza" ignorando a arquitetura e a qualidade é pago com juros altíssimos mais tarde.
Em resumo:
No fim, a escolha é entre ser um "bombeiro de dashboards", que vive correndo para apagar incêndios, ou um "arquiteto de soluções", que constrói estruturas que não pegam fogo. A segunda abordagem é sempre a mais eficiente.
Obrigado, @Cauan Ferrer
K
Parabéns
K
Que artigo maravilhoso
A
👏👏👏
Mais um artigo nota 10 Tarciso, meus parabéns pelo trabalho 🤗👏👏
Essa filosofia é viável com os prazos apertados do mundo real ou é um idealismo acadêmico?
Artigo super completo 👏
Muito obrigado pelo feedback @DIO, fico imensamente feliz em saber que a mensagem do artigo foi compreendida com tanta sensibilidade.
Sobre sua pergunta, acredito que o maior desafio inicial está em entender a lógica da modelagem de dados, principalmente com SQL e o conceito de esquema estrela. Sem uma base sólida nesse ponto, o Power BI acaba virando um campo minado, porque sem um modelo bem estruturado, até a DAX mais simples pode gerar resultados incorretos ou ineficientes.
Por outro lado, dominar DAX e seus contextos é o que realmente transforma um dashboard funcional em uma ferramenta de análise poderosa. É como aprender a "conversar com os dados". Mas sem um bom modelo, essa conversa vira um telefone sem fio.
Minha dica para quem está começando: foque primeiro em entender bem o modelo relacional, chaves primárias, normalização e depois desnormalização para análise. Depois disso, mergulhar na DAX se torna bem mais intuitivo, e até divertido!
Excelente artigo, Tarciso. Sua narrativa foi além da simples técnica, entregando uma jornada completa sobre o que realmente significa construir um dashboard de alto desempenho com Power BI. Ao dissecar um projeto real, você nos mostrou com clareza que otimização não é um truque de última hora, mas uma filosofia de desenvolvimento que começa na estrutura dos dados, passa pelas fórmulas DAX e se estende até a escolha de cada visual.
Na DIO, valorizamos profundamente esse olhar holístico para a criação de dashboards: acreditamos que a performance, a governança e a clareza de comunicação são tão importantes quanto os próprios dados. Mais do que entregar respostas rápidas, trata-se de projetar experiências que eliminam fricções entre o usuário e o insight.
Na sua visão, para quem está começando a construir dashboards e sente o peso da complexidade, o maior desafio está em dominar a lógica da modelagem de dados com SQL e esquema estrela, ou em aprender a conversar com o Power BI por meio de DAX e seus contextos de filtro e linha?