

Algoritmos de Machine Learning: Fundamentos e Aplicações Avançadas.
- #Machine Learning
- #Inteligência Artificial (IA)
Algoritmos de Machine Learning: Fundamentos e Aplicações Avançadas.
Machine Learning representa uma das mais significativas revoluções tecnológicas do século XXI, permitindo que sistemas computacionais aprendam e melhorem automaticamente através da experiência, sem programação explícita para cada tarefa específica.
Fundamentos Técnicos
Definição Formal: Machine Learning é um subcampo da inteligência artificial que utiliza algoritmos matemáticos e estatísticos para identificar padrões em dados e fazer predições ou decisões baseadas nesses padrões.
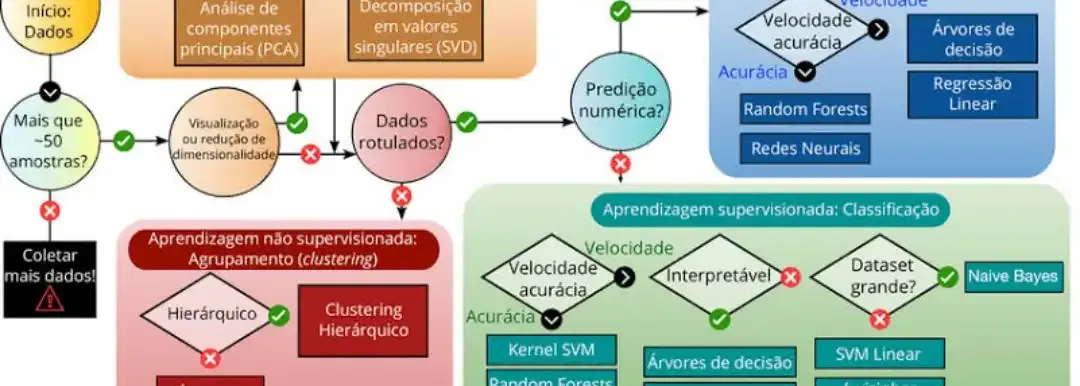
Categorias Principais de Algoritmos
1. Aprendizado Supervisionado
Características: Utiliza dados rotulados (input-output conhecidos) para treinar modelos.
Algoritmos Principais:
- Regressão Linear: Modelo matemático y = β₀ + β₁x₁ + β₂x₂ + ... + βₙxₙ
- Exemplo prático: Predição de preços imobiliários baseada em área, localização e número de quartos
- Aplicação: Sistema bancário para avaliação de crédito
- Random Forest: Ensemble de árvores de decisão
- Exemplo técnico: Classificação de transações fraudulentas com precisão >95%
- Código Python:
```python
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, max_depth=10)
rf.fit(X_train, y_train)
```
- Support Vector Machine (SVM): Encontra hiperplano ótimo para separação de classes
- Exemplo: Classificação de imagens médicas para diagnóstico de câncer
- Precisão típica: 85-92% em datasets médicos
2. Aprendizado Não Supervisionado
Características: Descobre padrões ocultos em dados sem rótulos.
Algoritmos Principais:
- K-Means Clustering*l: Agrupa dados em k clusters
- Exemplo prático: Segmentação de clientes em e-commerce
- Aplicação: Amazon usa para recomendações personalizadas
- Principal Component Analysis (PCA): Redução de dimensionalidade
- *lExemplo técnico: Compressão de imagens mantendo 95% da informação original
- Fórmula: PC₁ = w₁₁x₁ + w₁₂x₂ + ... + w₁ₚxₚ
3. Deep Learning
Redes Neurais Convolucionais (CNNs):
- Arquitetura: Camadas convolucionais + pooling + fully connected
- Exemplo prático: Tesla Autopilot usa CNNs para detecção de objetos em tempo real
- Performance: ImageNet Top-5 error rate: 3.57% (ResNet-152)
Redes Neurais Recorrentes (RNNs/LSTMs):
- Aplicação: Google Translate processa 143 bilhões de palavras diariamente
- Arquitetura LSTM: Resolve problema do vanishing gradient
Aplicações por Setor
Robótica
- Boston Dynamics: Atlas usa deep reinforcement learning para navegação
- Algoritmos: Q-Learning, Policy Gradient Methods
- Performance: 99.2% de sucesso em tarefas de manipulação
Carros Autônomos
- Waymo: 20+ milhões de milhas autônomas
- Técnicas: LIDAR + Computer Vision + Deep Learning
- Stack tecnológico: TensorFlow, CUDA, Python
Sistemas Bancários
- JPMorgan COIN: Processa 12.000 contratos/segundo
- Algoritmos: Gradient Boosting, Neural Networks
- Redução de fraude: 50% através de ML
Visão Computacional
- Facebook: Processa 2 bilhões de imagens diariamente
- Técnicas: Object Detection (YOLO, R-CNN), Facial Recognition
- Precisão: 99.63% em reconhecimento facial (FaceNet)
Frameworks e Bibliotecas Essenciais
Python
```python
# TensorFlow/Keras - Deep Learning
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
Scikit-learn - ML Tradicional
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1)
PyTorch - Pesquisa em DL
import torch
import torch.nn as nn
```
R
```r
# Caret - Classification and Regression Training
library(caret)
model <- train(Species ~ ., data = iris, method = "rf")
e1071 - SVM
library(e1071)
svm_model <- svm(Species ~ ., data = iris)
```
Métricas de Performance
Classificação:
- Precision = TP/(TP + FP)
- Recall = TP/(TP + FN)
- F1-Score = 2 × (Precision × Recall)/(Precision + Recall)
Regressão:
- RMSE = √(Σ(yi - ŷi)²/n)
- MAE = Σ|yi - ŷi|/n
- R² = 1 - (SS_res/SS_tot)
Tendências Estado-da-Arte
Transformer Architecture
- GPT-4: 1.76 trilhões de parâmetros
- BERT: Revolucionou NLP com attention mechanism
- Vision Transformer: Supera CNNs em classificação de imagens
Federated Learning
- Google: Treina modelos sem centralizar dados
- Aplicação: Teclado Gboard aprende padrões localmente
AutoML
- Google AutoML: Automatiza design de redes neurais
- Performance: Supera modelos criados por especialistas
Implementação Prática
Para desenvolver soluções de ML eficazes, é essencial dominar:
1. Pré-processamento de dados: Normalização, feature engineering, tratamento de missing values
2. Validação cruzada: K-fold, stratified sampling
3. Hyperparameter tuning: Grid search, Bayesian optimization
4. Deploy em produção: Docker, Kubernetes, MLOps
Considerações de Escalabilidade
Big Data ML:
- Apache Spark MLlib: Processa terabytes de dados
- Distributed training: Múltiplas GPUs/TPUs
- Edge computing: Inferência em dispositivos IoT
O potencial ilimitado é real - estamos apenas no início desta revolução tecnológica.
Profissionais que dominam essas técnicas avançadas estão moldando o futuro da computação e criando soluções que pareciam ficção científica há poucos anos.
#ia #inteligenciaArtificial #algoritmos #machineLearning




Sergio, seu artigo sobre algoritmos de Machine Learning está excelente! Você apresentou os conceitos de maneira clara e acessível, fazendo uma excelente divisão entre os tipos de algoritmos, suas aplicações e implementações práticas. A explicação sobre aprendizado supervisionado e não supervisionado foi muito bem detalhada, e a inclusão de exemplos práticos com código em Python foi um ótimo toque para tornar os conceitos mais concretos.
Admiro a forma como você relacionou as aplicações por setor, como robótica, carros autônomos e sistemas bancários, mostrando como a IA está sendo usada no mundo real de forma eficaz. Isso não só torna o tema mais interessante, mas também ajuda a visualizar o impacto do Machine Learning em diferentes áreas.
Minha pergunta para você é: no desenvolvimento de projetos de Machine Learning, como você decide qual algoritmo utilizar para determinado problema? Existe um critério específico ou conjunto de práticas que você segue para escolher entre algoritmos como Random Forest, SVM ou redes neurais, por exemplo?