


Big Data e Python
- #Data
🧠 Big Data e Python: como transformar milhões de dados em decisões inteligentes
#Data
Você sabia que as maiores empresas do mundo tomam decisões com base em dados analisados por Python e ferramentas de Big Data?
Neste artigo, você vai entender como essa combinação pode transformar dados brutos em insights estratégicos e como isso pode impulsionar sua carreira em dados.
📊 1. O que é Big Data e por que ele importa tanto
Vivemos na era da informação. A cada segundo, geramos uma quantidade imensa de dados: compras online, cliques em redes sociais, sensores de dispositivos e muito mais. Isso é o que chamamos de Big Data.
O conceito é geralmente explicado pelos 5 Vs:
- Volume: milhões (ou bilhões) de registros
- Velocidade: os dados são gerados constantemente
- Variedade: texto, imagem, vídeo, sensores etc.
- Veracidade: nem todos os dados são confiáveis
- Valor: transformar dados em insights úteis
Python se destaca nesse cenário por ser simples, poderoso e altamente escalável — com bibliotecas específicas para lidar com grandes volumes de dados.
🐍 2. Python na prática: ferramentas para lidar com grandes volumes de dados
Se você já trabalhou com pandas, sabe como é simples explorar e transformar dados. Mas... e quando um arquivo CSV tem 10GB e seu computador trava?
Aí entram ferramentas como:
- Dask: semelhante ao pandas, mas funciona de forma distribuída
- PySpark: integra o Python com o Apache Spark, ideal para clusters
- PyArrow: usado para formatos otimizados como Parquet
Veja um exemplo de como o Dask pode ajudar:
python
CopiarEditar
import dask.dataframe as dd
# Lendo um arquivo grande com Dask
df = dd.read_csv('grande_arquivo.csv')
# Operações como no pandas
media = df['preco'].mean().compute()
print(media)
🧭Entenda o Fluxo: Do Dado à Decisão com Python e Big Data
Este fluxograma representa o caminho que os dados percorrem até se tornarem insights valiosos.
Começa na entrada dos dados (como arquivos, APIs ou bancos), passa pela ingestão e processamento com ferramentas como Dask ou PySpark, segue para o armazenamento otimizado e termina na análise final, onde decisões estratégicas são tomadas com Python ou ferramentas de BI.
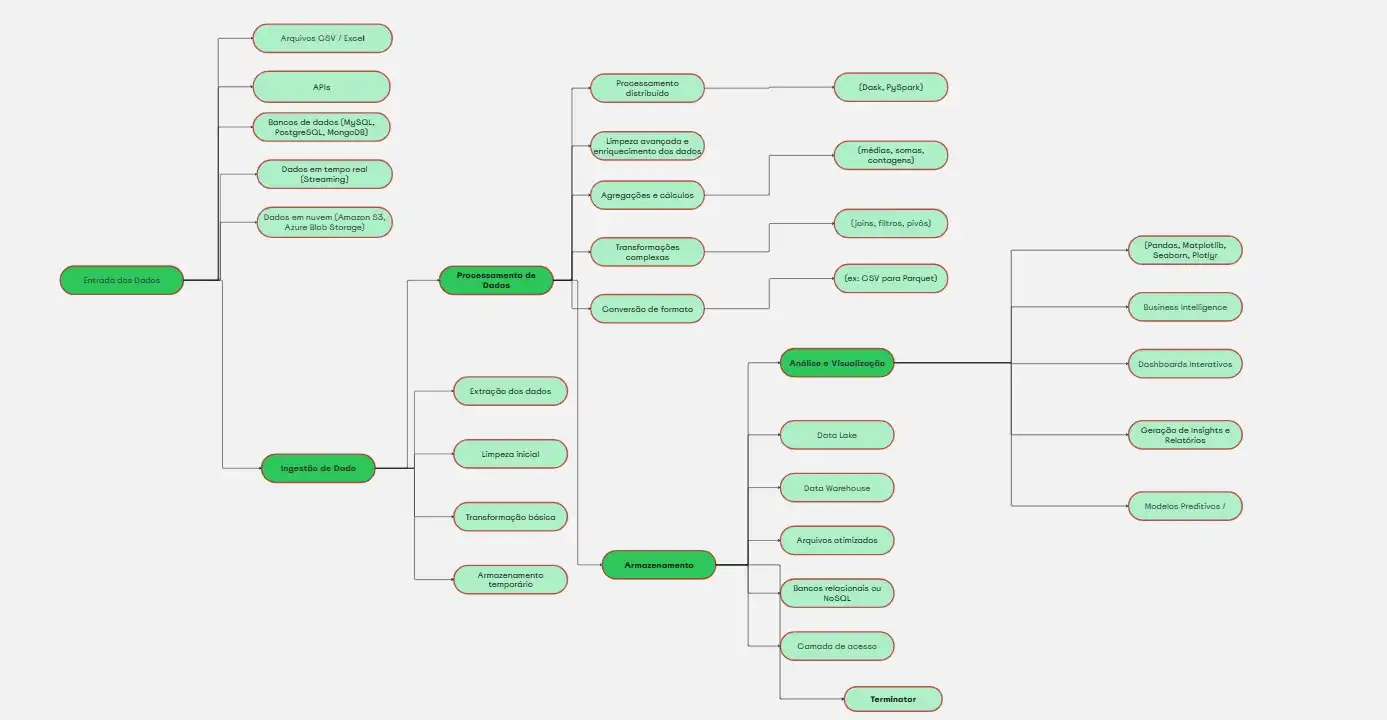
Veja o fluxo completo no Miro: Clique aqui
🚀 3. Aplicações reais e impacto na carreira
Empresas como Netflix, iFood e Nubank usam Big Data + Python para:
- Personalizar recomendações
- Prever fraudes ou inadimplência
- Otimizar campanhas de marketing em tempo real
Esses dados não ficam apenas em gráficos. Eles impulsionam ações, estratégias e decisões que impactam diretamente os resultados das empresas.
👩💻 Carreiras possíveis:
- Analista de Dados
- Engenheiro de Dados
- Cientista de Dados
- Engenheiro de Machine Learning
✅ Conclusão
Big Data, aliado ao poder do Python, deixou de ser o futuro e se tornou o presente da análise de dados.
Com ferramentas acessíveis e uma comunidade ativa, você pode começar hoje mesmo a explorar e construir soluções reais com dados.
🔗 Referências
- Documentação do Dask
- Apache Spark com PySpark
- PyArrow
- Kaggle - datasets e competições
- Miro – ferramenta de diagramas
Caso você queira trocar ideias sobre esse tema, estou totalmente aberta para conversas e feedbacks construtivos. Vamos fortalecer nossa rede!
Deixo abaixo meus contatos para continuarmos conectados:
🐙 GitHub




AR
Excelente artigo. 💜
Muito obrigada pelo feedback, fico feliz que o artigo tenha contribuído para a compreensão do tema!
Se eu fosse continuar essa discussão, acredito que explorar a construção de pipelines com Dask e PySpark seria um caminho muito enriquecedor, especialmente por sua importância na automação e escalabilidade do tratamento de dados em ambientes reais. Entender como distribuir tarefas, aplicar transformações eficientes em grandes volumes e gerenciar dependências entre etapas é essencial para quem busca atuar com dados em produção.
No entanto, também considero fundamental fechar o ciclo da análise com visualizações interativas, pois são elas que traduzem os dados em insights acionáveis para as áreas de negócio. Nesse sentido, mostrar como integrar os dados processados em Dask ou PySpark com bibliotecas como Plotly, Dash, ou até conectá-los a ferramentas de BI como Power BI e Tableau via Python, agregaria muito valor à discussão.
Na prática, acredito que o ideal seria seguir uma abordagem híbrida: demonstrar a construção de um pipeline escalável e, ao final, apresentar os resultados com visualizações dinâmicas que ajudem na tomada de decisão. Assim, conseguimos fechar o ciclo completo da jornada do dado com eficiência e clareza.
Excelente artigo, Patrícia. Você fez uma ótima síntese da complementaridade entre Big Data e Python, destacando de forma clara como essa união se tornou essencial para transformar grandes volumes de dados em decisões estratégicas. A explicação dos 5 Vs e a introdução ao uso de ferramentas como Dask e PySpark ajudam muito quem está começando a entender os desafios e soluções no tratamento de dados em escala.
Gostei particularmente da maneira como você apresentou o fluxo completo da jornada do dado, do recebimento à ação, tornando tangível um processo que muitas vezes parece abstrato para iniciantes. Além disso, a conexão com casos reais de empresas como Netflix e Nubank trouxe muita relevância prática ao conteúdo.
Se você fosse continuar essa discussão, preferiria explorar mais profundamente a construção de pipelines com Dask e PySpark ou mostrar como integrar esses dados a visualizações interativas usando Python e ferramentas de BI?