


Inteligência Artificial Generativa: Os Quatro Pilares da Nova Era Cognitiva
- #IA Generativa
André Codea
Graduando em Ciência da Computação. AI Tech Lead na Magical Reality Network e pesquisador independente em Inteligência Artificial.
Resumo
A Inteligência Artificial Generativa (GenAI) representa um marco na evolução da computação cognitiva, sendo capaz de criar conteúdo original a partir de grandes volumes de dados. Este artigo explora a trajetória da IA desde suas origens baseadas em regras até o surgimento dos Large Language Models (LLMs) e Specialized Small Language Models (SSLMs), destacando também os pilares essenciais da aplicação prática da GenAI: Engenharia de Prompt, Retrieval-Augmented Generation (RAG) e Large Language Model Operations (LLMOps). Por fim, discute-se como a integração desses elementos forma a base para o desenvolvimento de agentes inteligentes e aplicações de IA de alta confiabilidade.
Palavras-chave: Inteligência Artificial Generativa. LLMs. Engenharia de Prompt. RAG. LLMOps.
1. Introdução
A Inteligência Artificial (IA), em sua essência, representa a aspiração humana de replicar e expandir as capacidades cognitivas em máquinas. Longe de ser um conceito recente, a IA tem suas raízes em meados do século XX, nascendo como um campo interdisciplinar da ciência da computação que busca criar sistemas capazes de raciocinar, aprender, resolver problemas, perceber e até mesmo manipular, de maneira análoga ou superior à inteligência humana. Inicialmente dominada por abordagens baseadas em regras explícitas e lógica simbólica, que exigiam a programação manual de cada cenário possível, com laços de repetição, condicionais, entre outros. A IA moderna testemunhou uma transformação radical. Impulsionada pelo aumento exponencial do poder computacional e pela vasta disponibilidade de dados, o paradigma mudou do "como programar a inteligência" para o "como as máquinas podem aprender e gerar dados de maneira autônoma", abrindo caminho para o florescimento do Machine Learning (Aprendizado de Máquina) e, posteriormente, do Deep Learning (Aprendizado Profundo). Ambos têm suas raízes em fundamentos matemáticos como estatística, probabilidade e cálculo multivariado.
A partir desse avanço em métodos de aprendizado de máquina, especialmente o Deep Learning, surgiu um subcampo revolucionário: a Inteligência Artificial Generativa (GenAI). Diferentemente dos sistemas de IA tradicionais que se concentram em tarefas de análise e classificação de dados existentes, a GenAI tem a capacidade de criar conteúdo novo, original e coerente. Seja gerando imagens a partir de descrições textuais, compondo músicas inéditas, escrevendo código funcional ou, mais notavelmente, produzindo textos complexos e contextualmente relevantes, a GenAI inaugurou uma nova era de criatividade digital. Nesse cenário, os modelos de linguagem, como os Large Language Models (LLMs) e os Specialized Small Language Models (SSLM) emergem como protagonistas, representando a vanguarda dessa capacidade generativa no domínio da linguagem, aptos a processar e gerar volumes impressionantes de texto com uma fluidez e compreensão que antes pareciam exclusivas da mente humana e, além disso, servem como base para os Agentes Inteligentes, que são motores de raciocínio e tomada de decisões autônomos, capazes de tomar decisões com base em sua percepção do ambiente em que estão.
2. A Revolução da Criação Digital e Governança
A ascensão da Inteligência Artificial Generativa (GenAI), impulsionada por modelos de linguagem como os LLMs e agora, os SSLMs, não é apenas um avanço tecnológico; é uma força transformadora que está redefinindo as indústrias, desde a criação de conteúdo e marketing até a engenharia de software e pesquisa científica. De assistentes virtuais sofisticados capazes de conversar fluentemente a ferramentas que tomam conta de fluxos industriais completos, a GenAI inaugurou uma era sem precedentes de criatividade digital e automação inteligente.
No entanto, o entusiasmo inicial com as capacidades desses modelos logo deu lugar a uma compreensão mais profunda de seus desafios inerentes. Questões como a tendência à "alucinação" (geração de informações falsas ou sem suporte factual), a dependência de conhecimento estático (limitado aos dados de treinamento) e a necessidade de controle e otimização de suas saídas tornaram-se centrais. Para transcender essas limitações e construir aplicações de IA verdadeiramente confiáveis, escaláveis e de alto impacto no mundo real, é essencial dominar um ecossistema de técnicas e metodologias que se complementam, por isso, da mesma forma que o DevOps garante um ciclo de vida saudável para softwares, o LLMOps garante um ciclo de vida saudável para aplicações LLM, incluindo as aplicações GenAI.
Este artigo propõe uma exploração profunda dos quatro pilares que sustentam a IA Generativa de sucesso em ambientes de produção:
- Large Language Models (LLMs) e Specialized Small Language Models (SSLM): O motor de geração de conteúdo e suas variações.
- Engenharia de Prompt: A arte de extrair a máxima performance e direção do modelo, ou "saber o que pedir " e "de que maneira pedir".
- Retrieval-Augmented Generation (RAG): O mecanismo de precisão que permite que o modelo acesse dados factuais sob demanda.
- LLM Operations (LLMOps): O framework de engenharia que garante a escalabilidade, monitoramento e governança de todo o ciclo de vida da aplicação em produção.
3. Large Language Models (LLMs) e Specialized Small Language Models (SSLMs)
3.1. Origem dos Modelos de Linguagem e a Arquitetura Transformer
No epicentro da revolução da IA Generativa textual encontram-se os Large Language Models (LLMs) e seus análogos mais enxutos, os Specialized Small Language Models (SSLM). Ambos são manifestações poderosas do Deep Learning, especificamente da arquitetura Transformer, que se tornou o padrão para o processamento de linguagem natural (PLN) desde sua introdução em 2017, pela Google, justamente por sua capacidade de atenção. Em sua essência, um LLM é uma rede neural (modelo matemático estatístico) composta por bilhões de parâmetros e treinada em quantidades inimagináveis de dados textuais extraídos da internet – livros, artigos, websites e conversas. Esse treinamento massivo permite que o modelo aprenda padrões complexos de linguagem, gramática, semântica e até mesmo conhecimento factual.
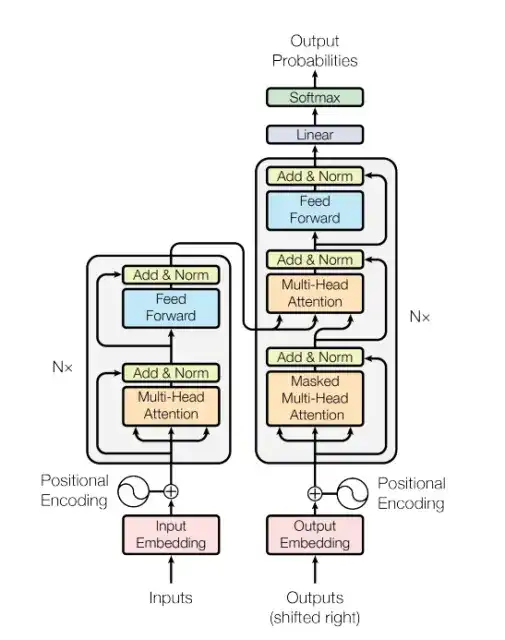
Figura 1. A arquitetura Transformer
3.2. Arquiteturas Contemporâneas
Recentemente, arquiteturas avançadas como Mixture of Experts (MoE) têm permitido a criação de modelos com um número ainda maior de parâmetros totais, mas que ativam apenas um subconjunto desses parâmetros para processar cada input, resultando em maior eficiência computacional e capacidade de escalonamento. A principal diferença entre LLMs e SSLMs reside na escala: enquanto LLMs como GPT-4 ou Bard visam a generalização em uma vasta gama de tarefas com centenas de bilhões ou até trilhões de parâmetros, os SSLMs, embora menores (geralmente com milhões ou poucos bilhões de parâmetros), são otimizados ou finetunados para domínios ou tarefas específicas, oferecendo eficiência e desempenho superiores para casos de uso especializados com recursos computacionais reduzidos.
3.3. Habilidades dos Modelos de Linguagem
As habilidades que esses modelos adquirem a partir desse treinamento colossal são notáveis e multifacetadas, representando um salto enorme na interação humano-máquina. A capacidade mais evidente é a geração de texto coerente e fluida, permitindo que criem textos com uma qualidade que se assemelha a da escrita humana. Além disso, exibem uma profunda compreensão de linguagem natural, sendo capazes de responder a perguntas, resumir documentos extensos, extrair informações específicas e traduzir entre diferentes idiomas. Essa compreensão é a base para o que se assemelha a um "raciocínio" básico, permitindo a tomada de decisões, embora esse "raciocínio" seja apenas uma função estatística de predição da sequência de tokens mais provável dada uma janela de contexto, e não uma cognição no sentido humano, o que significa que toda saída é uma predição que depende diretamente de contexto. A adaptabilidade desses modelos também os permite ajustar o tom, estilo e formato da saída para atender a requisitos específicos, tornando-os ferramentas incrivelmente versáteis em diversas aplicações.
3.4. Limitações dos Modelos de Linguagem
Apesar de suas capacidades impressionantes, modelos de linguagem não estão isentos de desafios e limitações. Uma das preocupações mais prementes é a propensão à "alucinação", em que o modelo gera informações que soam convincentes, mas são factualmente incorretas ou totalmente inventadas, uma consequência direta de sua natureza preditiva estatística e também de seu treinamento, que tende à recompensar o modelo por adivinhar em vez de assumir desconhecimento. Outra limitação é a de seu conhecimento estático: o dataset em que foram treinados determina seu conhecimento, o que significa que eles não têm acesso a eventos em tempo real, dados proprietários de uma organização ou informações publicadas após a data de seu corte de treinamento (cutoff). Além disso, a capacidade de gerar texto é acompanhada pelo risco de viés e toxicidade, pois os modelos podem inadvertidamente replicar ou até amplificar tendências presentes nos conjuntos de dados da internet. Finalmente, apesar de seu "raciocínio" aparente, esses modelos carecem de um bom senso real ou compreensão do mundo como os humanos, operando com base em correlações estatísticas, e não em uma representação semântica profunda da realidade, o que pode levar a erros lógicos ou a falhas em situações que exigem inferência causal complexa.
4. A Chave de Controle: Engenharia de Prompts
4.1. A Engenharia de Prompts
A Engenharia de Prompt pode ser definida como a ciência de formular inputs (os "prompts") de forma estratégica e otimizada para guiar o modelo a produzir a output desejada. Longe de ser uma tarefa trivial, a Engenharia de Prompt é a ponte fundamental entre a vasta capacidade de um modelo de linguagem e a intenção específica do usuário, transformando um modelo passivo em uma ferramenta precisa e direcionada. Em um mundo onde a interação com a IA se torna cada vez mais baseada em linguagem natural, dominar a arte de "saber o que pedir e de que maneira pedir" é a chave para desbloquear o verdadeiro potencial desses sistemas, mitigando suas falhas e maximizando sua utilidade em uma miríade de aplicações. Inclusive, a Engenharia de Prompt é a base para o módulo de "raciocínio" do framework CoALA (Cognitive Architectures for Language Agents) e frameworks de Agentes Inteligentes, como o ReAct (Reason, Act, Observe) e o ReWoo (Plan, Execute, Solve).
4.2. O Prompt Eficaz
Para construir um prompt eficaz, que maximize a probabilidade de obter a resposta desejada e minimize as chances de alucinação ou desvio, é fundamental considerar a inclusão de vários componentes estratégicos. Primeiramente, a Instrução Clara e Precisa é a espinha dorsal: o prompt deve comunicar explicitamente a tarefa que o modelo deve executar, evitando ambiguidades. Em segundo lugar, fornecer Contexto Relevante é vital; isso inclui quaisquer informações de fundo, dados específicos ou cenários que o modelo precisa considerar para gerar uma resposta informada. A Definição de Persona instrui o modelo a assumir um papel ou estilo específico (ex: "Aja como um historiador experiente" ou "Escreva em um tom formal"), moldando o formato e o conteúdo da saída. Além disso, especificar o Formato de Saída Desejado (seja uma lista, um parágrafo, código JSON, uma tabela ou um resumo conciso) ajuda o modelo a estruturar a resposta de maneira utilizável. Finalmente, a inclusão de Restrições ou Condições (ex: "Não use mais de 100 palavras", "Inclua apenas fatos verificáveis") impõe limites e regras que guiam o modelo para uma resposta mais controlada e alinhada às expectativas. A combinação inteligente desses elementos transforma um comando simples em uma diretriz rica e eficaz para o modelo.
4.3. Técnicas de Engenharia de Prompts
Indo além dos componentes básicos, a Engenharia de Prompt também engloba técnicas avançadas que aprimoram significativamente a capacidade do modelo de performar tarefas complexas, simular raciocínio e corrigir suas próprias falhas. O Zero-Shot Learning e o Few-Shot Learning, por exemplo, referem-se à capacidade de um modelo de executar tarefas sem exemplos (zero-shot) ou com apenas alguns exemplos (few-shot) fornecidos no prompt, demonstrando sua generalização. A técnica de Chain-of-Thought (CoT), ou "Cadeia de Pensamento", instrui o modelo a decompor um problema complexo em etapas menores e a "pensar em voz alta", o que geralmente leva a respostas mais precisas e logicamente estruturadas. Em seguida, a Self-Consistency leva o CoT um passo adiante, ao gerar múltiplas cadeias de pensamento para a mesma pergunta e selecionar a resposta que emerge como a mais consistente entre elas, aumentando a robustez da solução. Outra técnica poderosa é a Self-Correction, que envolve pedir ao próprio modelo para revisar, avaliar e corrigir suas saídas com base em critérios fornecidos, refinando a qualidade final.
5. A Solução para a Precisão: Retrieval-Augmented Generation (RAG)
5.1. A Geração Aumentada por Recuperação de Contexto
Retrieval-Augmented Generation (RAG), que significa geração aumentada por recuperação, é a solução mais adequada para acabar com a limitação dos modelos de linguagem: o conhecimento estático e a propensão à alucinação. Como discutido na Seção III, a base informacional desses modelos é restrita aos dados em que foram treinados até um determinado cutoff temporal, o que os impede de acessar informações em tempo real, dados privados ou corporativos, ou até mesmo os desenvolvimentos mais recentes de qualquer área. Consequentemente, ao se depararem com perguntas que transcendem seu conjunto de treinamento ou exigem fatos muito específicos e atualizados, os modelos podem gerar respostas que, embora soem convincentes, são factualmente incorretas ou simplesmente inventadas, minando a confiança e a aplicabilidade em cenários críticos. É para resolver precisamente essas lacunas de conhecimento e confiabilidade que surge o Retrieval-Augmented Generation (RAG), uma arquitetura que busca trazer precisão e verificabilidade à potência generativa dos modelos de linguagem. Diferentemente do Fine-tuning, que pode ser análogo a "mandar o modelo para a faculdade" para se especializar em um domínio, o RAG é como "dar um livro de presente" para o modelo, fornecendo informações factuais que podem ser acessadas sob demanda.
5.2. Funcionamento do RAG
O funcionamento do RAG baseia-se em um processo de quatro etapas interligadas que enriquecem o prompt do usuário antes que ele seja processado pelo modelo de linguagem. Primeiramente, quando o usuário faz uma Consulta (Prompt), o sistema RAG não a envia diretamente ao LLM. Em vez disso, essa consulta é usada para iniciar uma Busca de Documentos (Retrieval). Nesta etapa, a consulta é convertida em uma representação numérica (um embedding) e utilizada para pesquisar em uma base de dados externa (vector store) contendo uma vasta coleção de documentos, artigos, FAQs, etc., também representados por embeddings, que servirão como um banco semântico, em que por meio do cálculo das distâncias cosseno entre os embeddings, é possível calcular a similaridade semântica entre os textos. O objetivo é encontrar os trechos de informação mais relevantes e semanticamente similares à consulta original. Uma vez que esses trechos são recuperados, o sistema realiza o Aumento do Prompt, onde as informações recuperadas são concatenadas ou inseridas de forma estratégica no prompt original do usuário. Esse novo prompt, agora enriquecido com contexto factual, é então enviado ao LLM para a etapa final de Geração da Resposta (Generation). Com essa base de conhecimento contextualizada e específica, o LLM é capaz de formular uma resposta muito mais precisa, informada e menos propensa a alucinações, pois tem acesso a fatos concretos para apoiar sua saída.
5.3. Benefícios do RAG
Os benefícios do RAG são transformadores para o desenvolvimento de aplicações de IA Generativa robustas. Em primeiro lugar, há uma redução drástica na alucinação, pois as respostas do modelo são ancoradas em trechos de texto recuperados de fontes verificáveis, em vez de serem extrapolações dos dados de treinamento. Isso aumenta a confiabilidade e a acurácia das saídas. Em segundo lugar, o RAG permite o acesso a conhecimento atualizado e proprietário; empresas podem integrar seus próprios documentos internos, bancos de dados ou informações recém-publicadas, superando o cutoff de treinamento dos modelos base. Em terceiro lugar, o sistema oferece transparência e auditabilidade, permitindo que o modelo não só forneça uma resposta, mas também cite as fontes ou documentos de onde a informação foi extraída, algo crucial para setores regulados. Por fim, o RAG apresenta uma abordagem custo-benefício atraente para a atualização de conhecimento, sendo frequentemente mais eficiente e flexível do que o fine-tuning completo do modelo para incorporar novas informações. O RAG é o que permite com que modelos tenham "consciência" do ambiente em que estão.
6. O Pilar da Produção: Large Language Model Operations (LLMOps)
6.1. Aplicações LLM em Produção
A transição de um experimento promissor de IA Generativa para uma solução robusta e escalável em produção apresenta um conjunto único de desafios operacionais e de governança. É nesse cenário que surge o Large Language Model Operations (LLMOps), um processo trifásico e bidirecional, que representa as boas práticas, infraestruturas e processos para garantir um ciclo de vida saudável para aplicações LLM — desde o desenvolvimento, teste e implantação até o monitoramento contínuo, manutenção e evolução em ambientes de produção. A necessidade de LLMOps é amplificada pela natureza dinâmica e frequentemente imprevisível dos LLMs, onde a qualidade da saída pode ser sensível a pequenas mudanças no prompt, na versão do modelo, ou nos dados externos.Sem um framework LLMOps bem estabelecido, a promessa da IA Generativa permanece confinada a provas de conceito, incapaz de entregar valor contínuo e confiável em escala corporativa.
6.2. Ciclo de Vida de Aplicações LLM
Para garantir a eficácia e a longevidade das aplicações de IA Generativa, o LLMOps organiza e estrutura todo o processo em fases distintas, garantindo que cada etapa seja tratada com a devida diligência. A primeira é a fase de Ideação, em que as necessidades de negócio são traduzidas em casos de uso viáveis para LLMs, incluindo a definição de objetivos claros e critérios de sucesso. Segue-se a fase de Desenvolvimento, que engloba a experimentação com diferentes modelos, Chains e Agents, a Engenharia de Prompt, a construção e otimização da infraestrutura RAG (incluindo a gestão dos vector stores e pipelines de dados), e os testes rigorosos para assegurar a qualidade e a segurança das soluções. Por fim, a fase Operacional foca na implantação em produção, no monitoramento e observabilidade contínuos de performance, custos, latência e qualidade das saídas, na gestão de versões dos modelos e prompts, e na capacidade de realizar atualizações e adaptações rápidas para manter a relevância e a segurança da aplicação. Cada fase é interconectada, e a orquestração entre elas é fundamental para o sucesso de longo prazo de qualquer iniciativa de IA Generativa.
7. Conclusão
Ao longo deste artigo, percorremos a fascinante jornada da Inteligência Artificial, desde suas raízes históricas e a evolução para o Machine Learning e Deep Learning, culminando na era transformadora da IA Generativa. Detalhamos os Large Language Models (LLMs) e Small Specialized Language Models (SSLM) como o coração pulsante dessa nova capacidade criativa, compreendendo suas proezas em gerar e entender linguagem, mas também suas inerentes limitações, como a alucinação e o conhecimento estático. Para superar esses desafios, apresentamos a Engenharia de Prompt como a arte de direcionar esses modelos com precisão e a Retrieval-Augmented Generation (RAG) como a solução engenhosa para ancorar suas respostas em fatos atualizados e verificáveis, concedendo aos modelos uma "consciência" do ambiente. Finalmente, exploramos o LLMOps, o pilar fundamental que garante que a promessa da IA Generativa possa ser entregue de forma confiável, segura e escalável em ambientes de produção, gerenciando todo o ciclo de vida da aplicação através de suas fases de Ideação, Desenvolvimento e Operacional.
A sinergia entre esses quatro pilares — Modelos de Linguagem robustos, Engenharia de Prompt habilidosa, RAG para precisão contextual e um framework LLMOps resiliente — é o que capacita as organizações a transcenderem os experimentos iniciais e a construir soluções de IA Generativa de alto impacto. Essa integração determina o caminho para a emergência de Agentes Inteligentes verdadeiramente autônomos, capazes de raciocinar, agir e tomar decisões complexas no mundo real. À medida que a IA Generativa continua sua rápida evolução, o domínio desses pilares será não apenas um diferencial competitivo, mas uma necessidade estratégica para qualquer empresa ou indivíduo que aspire a inovar e a prosperar na vanguarda da revolução da inteligência artificial.
Referências
LEWIS, Patrick et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In: Advances in Neural Information Processing Systems, v. 33, p. 9459-9474, 2020.
VASWANI, Ashish et al. Attention Is All You Need. In: Advances in Neural Information Processing Systems, p. 5998-6008, 2017.
JI, Ziwei et al. Why Language Models Hallucinate. Nature Machine Intelligence, v. 5, n. 10, p. 1007-1018, 2023.
WEN, Haozhuo et al. Cognitive Architectures for Language Agents. arXiv:2401.07111, 2024.
WANG, Ziqi et al. Small Language Models are the Future of Agentic AI. arXiv:2402.16259, 2024.
PIMENTA, Matheus. ReAct VS ReWoo: What Does It Means? Medium, 27 mar. 2024. Disponível em: https://medium.com/@thepimentaorougecompany/react-vs-rewoo-what-does-it-means-9b07f6a3e1da. Acesso em: 03/11/2025.
RUSSEL, Stuart; NORVIG, Peter. Inteligência Artificial, Uma Abordagem Moderna. 4. ed. Rio de Janeiro: Elsevier, 2021.






Olá, DIO Community!
Creio que o maior desafio para desenvolvedores, principalmente iniciantes, tem a ver diretamente com o foco excessivo no desenvolvimento, em vez da distribuição de foco entre a ideação, desenvolvimento e manutenção. Em aplicações de IA, a observabilidade e monitoramento são essenciais para garantir que a saúde da aplicação seja boa, inclusive a segurança.
Para isso, é possível utilizar ferramentas como LangSmith ou LangFlow, que tem diversas funcionalidades para o acompanhamento de custos, logging, versionamento de prompts, entre outros. Isso facilita MUITO a vida do desenvolvedor, por exemplo, por meio da observabilidade, podemos versionar o prompt para evitar abusos como o prompt injection.
Assim como o monitoramento é essencial, a ideação também é. Escolher entre modelos proprietários ou open-source, tamanho do modelo, se vai ser finetunado ou não, são questões imperativas para a projeção de custos, projeção de governança e de segurança também. Ou seja, fazer apenas um agente inteligente (que muita das vezes é apenas um chatbot), não é criar um sistema de IA, existem muitas variáveis que podem impactar custos, segurança, governança e manutenibilidade.
Excelente, André! Que artigo épico, detalhado e de altíssimo valor estratégico! Você tocou no ponto crucial da IA Generativa: o LLMOps é a próxima fronteira da engenharia de software, garantindo que as soluções de IA não sejam apenas experimentos, mas sistemas confiáveis e escaláveis em produção.
É fascinante ver como você aborda o tema, mostrando que a sinergia entre os Quatro Pilares é o que transforma a promessa da GenAI em realidade corporativa.
Qual você diria que é o maior desafio para um desenvolvedor ao implementar os princípios de IA responsável em um projeto, em termos de balancear a inovação e a eficiência com a ética e a privacidade, em vez de apenas focar em funcionalidades?