

Otimização de Consultas em SQL: Quando Performance Pode Salvar Vidas
- #SQL
Uma história (hipotética) sobre como uma query lenta pode custar vidas
Vivemos na era da velocidade. Esperamos que sistemas respondam em milissegundos, que dados estejam disponíveis em tempo real e que decisões sejam tomadas com base em informações sempre atualizadas.
Mas o que acontece quando uma simples consulta SQL é lenta?
Pior: e se essa lentidão ocorrer em um sistema de saúde?
Imagine os sistemas brasileiros de vigilância epidemiológica, como o e-SUS Notifica ou o SINAN. Eles coletam dados em tempo real de hospitais espalhados por todo o país para identificar surtos de doenças graves — como COVID-19, dengue ou meningite.
Agora visualize o seguinte cenário:
Vários hospitais estão notificando casos críticos de uma nova doença a cada hora.
O sistema, sobrecarregado, demora minutos (ou horas) para processar cada requisição, e a consulta que deveria retornar os dados mais recentes da doença trava por segundos preciosos.
Enquanto isso, centenas de profissionais da saúde aguardam uma resposta do sistema para iniciar medidas de contenção.
A pergunta é: quantas vidas poderiam ter sido poupadas com um simples EXPLAIN ANALYZE?
O objetivo deste artigo
Este artigo não é apenas técnico — ele é um convite à responsabilidade.
Trago aqui boas práticas e técnicas essenciais para otimizar consultas SQL em bancos relacionais, com foco em performance, clareza e eficiência.
Você vai aprender como pensar como um engenheiro de dados pragmático, arquitetando queries com precisão e propósito.
Entendendo o poder da otimização
O que é SQL?
SQL (Structured Query Language) é a linguagem padrão para manipulação de dados em sistemas gerenciadores de bancos relacionais (como PostgreSQL, MySQL, SQL Server, entre outros). Com ela, fazemos inserções, atualizações, deleções e consultas de dados.
Mas há uma verdade frequentemente ignorada:
SQL mal escrito escala mal.
E um código que escala mal, em um sistema crítico, vira um gargalo real — técnico, financeiro e humano.
5 Dicas Práticas para Otimizar as Consultas
Agora que você compreende a gravidade de uma consulta mal estruturada — e o impacto que isso pode ter em sistemas críticos —, vamos direto ao ponto: como você pode escrever consultas SQL que realmente entregam performance, escalabilidade e confiança?
A seguir, você verá boas práticas que não só reduzem o tempo de resposta, mas também diminuem o consumo de recursos do servidor, melhoram a manutenibilidade do código e preparam o sistema para crescer com segurança.
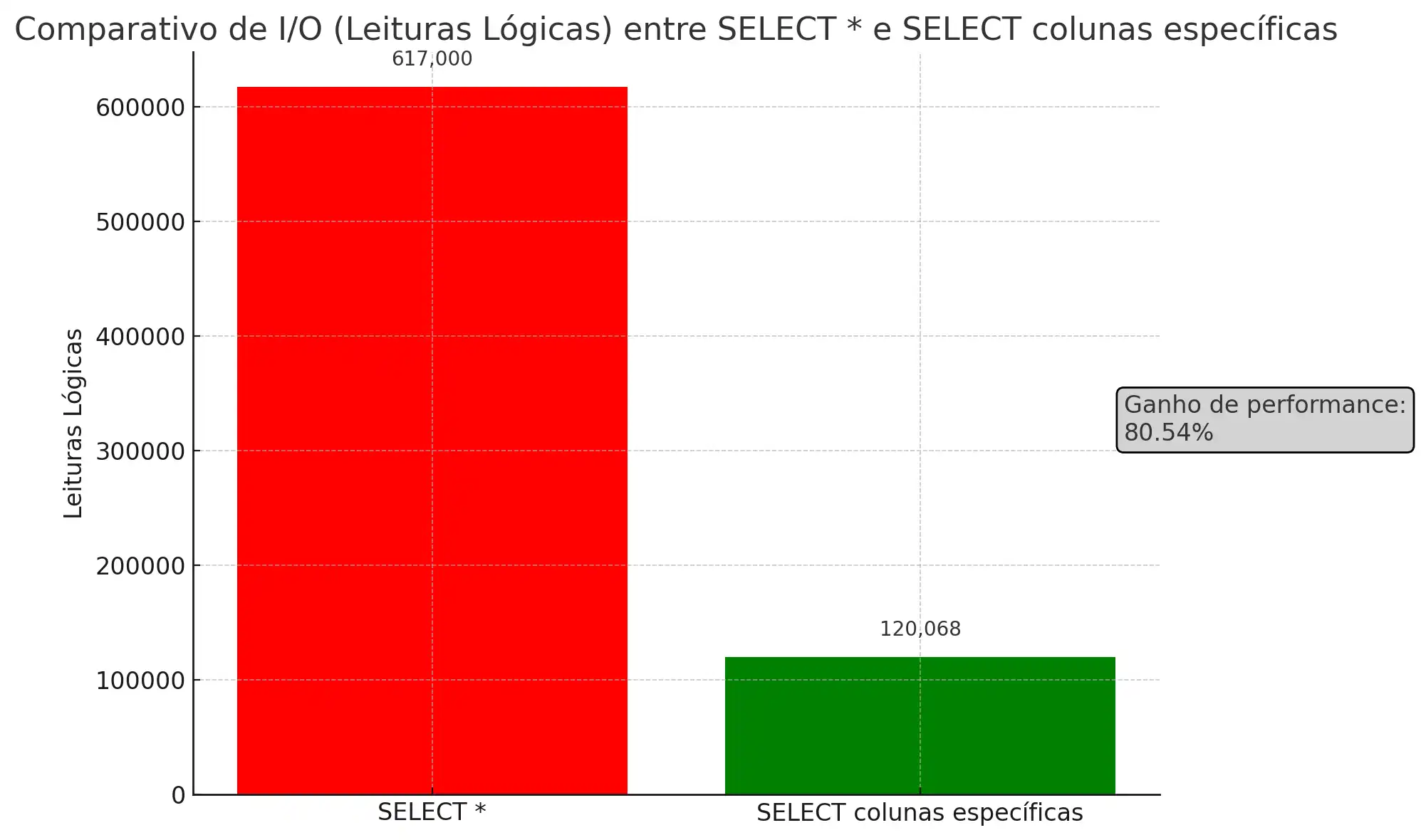
1. Evite o uso de SELECT * — sempre que possível
Um dos erros mais comuns — e perigosos — é utilizar SELECT * para retornar todas as colunas de uma tabela.
Por que isso é um problema? Ao solicitar todas as colunas, você está forçando o banco a percorrer cada linha e retornar uma quantidade gigantesca de dados, mesmo que precise de apenas dois ou três campos. Em tabelas com milhões de registros, isso pode gerar um gargalo severo de I/O e memória, especialmente em sistemas de alta concorrência.
Além disso: caso novas colunas sejam adicionadas no futuro, elas também serão retornadas — mesmo que não sejam utilizadas. Isso quebra o princípio da previsibilidade e pode causar falhas inesperadas em integrações e relatórios. ****
prática: retorne apenas o necessário!
-- Exemplo otimizado
SELECT nm_cliente, cpf_cliente
FROM tb_cliente;
Esse pequeno ajuste pode representar um ganho de mais de 80% de performance em consultas em bancos de dados volumosos.
2. Use LIMIT para restringir o número de registros retornados
Ao consultar bancos de dados, é comum precisar apenas de um recorte dos dados disponíveis — por exemplo, os 10 usuários mais recentes, os 20 produtos mais vendidos, ou apenas os primeiros resultados de uma busca. Mesmo assim, muitos desenvolvedores deixam suas consultas abertas, retornando milhares (ou milhões) de linhas sem necessidade.
Qual o problema?
Consultas sem limitação de resultados consomem muito mais memória do que o necessário, sobrecarregam a rede com dados inúteis e afetam diretamente o tempo de resposta da aplicação — especialmente em endpoints públicos ou APIs que alimentam frontends com paginação.
Boa prática: defina um limite claro para seus resultados
-- Exemplo com limite de registros
SELECT nm_produto, preco
FROM tb_produto
LIMIT 10;
Nesse exemplo, apenas os 10 produtos mais recentes serão retornados, otimizando o tráfego e o desempenho geral da aplicação.
3. Crie índices nos campos mais utilizados em consultas
Imagine que você está numa biblioteca com milhares de livros empilhados aleatoriamente. Se alguém te pede um livro específico, sem um índice ou sistema de organização, você teria que procurar livro por livro até encontrar — e isso pode demorar muito. Agora, pense na diferença que faz um catálogo organizado por nome do autor, título ou assunto. Com ele, você vai direto ao ponto.
É exatamente assim que os índices funcionam em um banco de dados.
Um índice cria uma estrutura auxiliar otimizada (como uma árvore B+ ou hash) que permite ao banco localizar dados muito mais rapidamente, sem precisar varrer a tabela inteira (o que chamamos de full table scan.
Sem índice:
SELECT * FROM tb_cliente WHERE cpf_cliente = '12345678900';
-- o banco examina TODAS as linhas da tabela para encontrar o CPF.
Com índice:
-- Criação do índice
CREATE INDEX idx_cpf_cliente ON tb_cliente (cpf_cliente);
Com esse índice, a consulta anterior será muito mais eficiente. O banco consultará o índice (como se fosse o catálogo da biblioteca) e acessará diretamente o registro correspondente, economizando tempo e recursos.
4. Use JOINs com inteligência: entenda qual tipo aplicar
Os JOINs são essenciais para combinar dados de múltiplas tabelas relacionais — afinal, normalizamos nossos bancos justamente para evitar redundâncias. No entanto, o uso incorreto dos JOINs pode causar consultas lentas, confusas e até incorretas.
O que é um JOIN?
JOIN é uma cláusula que permite relacionar duas ou mais tabelas, com base em uma chave comum. Funciona como montar um quebra-cabeça: cada tabela tem uma peça que se encaixa na outra.
Tipos de JOINs e como funcionam
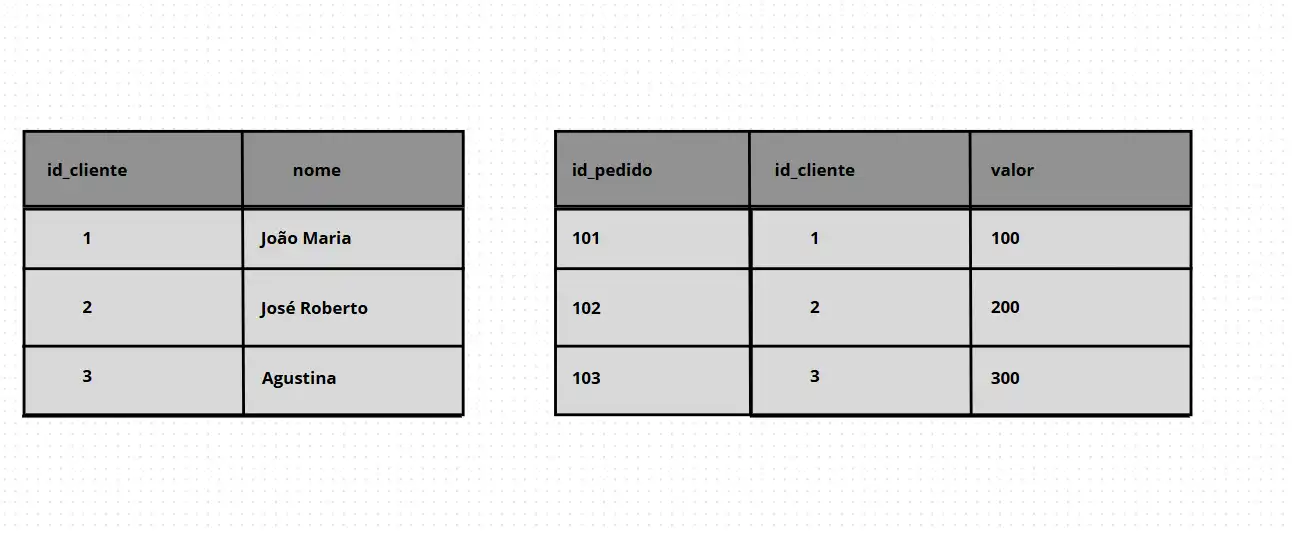
Vamos imaginar duas tabelas:
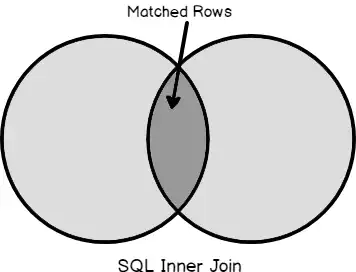
INNER JOIN — O mais comum e o mais performático
Retorna apenas os registros que possuem correspondência nas duas tabelas.
SELECT c.nome, p.valor
FROM clientes c
INNER JOIN pedidos p ON c.id_cliente = p.id_cliente;
- Resultado: Apenas João e Maria aparecem, pois são os únicos com pedidos.
- Quando usar: Você só precisa dos dados que existem em ambas as tabelas.
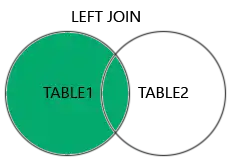
LEFT JOIN (ou LEFT OUTER JOIN) — Todos da esquerda, mesmo sem correspondência
Retorna todos os registros da tabela da esquerda, mesmo que não tenham correspondência na tabela da direita. Onde não houver correspondência, retorna NULL.
SELECT c.nome, p.valor
FROM clientes c
LEFT JOIN pedidos p ON c.id_cliente = p.id_cliente;
- Resultado: João, Maria e Carla aparecem. Carla aparece com
valor = NULL, pois não fez nenhum pedido. - Use quando: Precisa de todos os registros da tabela principal (clientes) mesmo que não tenham relação (pedidos).
RIGHT JOIN (ou RIGHT OUTER JOIN) — Todos da direita, mesmo sem correspondência
O oposto do LEFT JOIN. Retorna todos os registros da tabela da direita, com NULL para os que não têm correspondência na esquerda.
SELECT c.nome, p.valor
FROM clientes c
RIGHT JOIN pedidos p ON c.id_cliente = p.id_cliente;
- Resultado: João, Maria e um pedido “fantasma” de
id_cliente = 4, que aparece comnome = NULL. - Use quando: Você quer garantir que todos os registros da segunda tabela apareçam (geralmente menos comum que o LEFT).
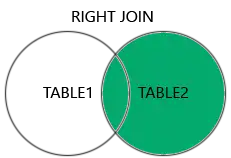
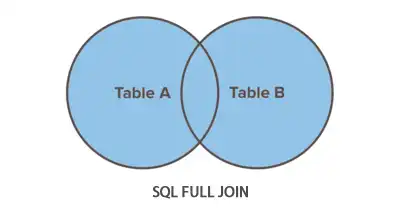
FULL JOIN (ou FULL OUTER JOIN) — Todos os registros de ambas as tabelas
Combina LEFT e RIGHT. Traz todos os registros de ambas as tabelas, e onde não houver correspondência, retorna NULL.
SELECT c.nome, p.valor
FROM clientes c
FULL JOIN pedidos p ON c.id_cliente = p.id_cliente;
- Resultado: Todos os clientes e todos os pedidos aparecem — inclusive os que não têm relação entre si.
- Use quando: Precisa de uma visão completa de todas as informações, relacionadas ou não.
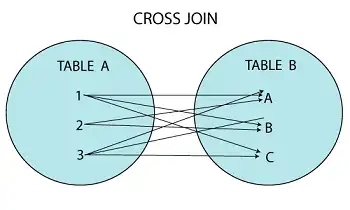
CROSS JOIN — Produto cartesiano
Une tudo com tudo. Cada linha da primeira tabela se junta com todas da segunda. Isso gera um número de linhas igual a:
nº de linhas da Tabela A × nº de linhas da Tabela B
SELECT c.nome, p.valor
FROM clientes c
CROSS JOIN pedidos p;
Resultado: Se houver 3 clientes e 3 pedidos, serão 9 registros.
Use com MUITO cuidado, pois pode explodir a memória se não houver filtros.
Dica de Performance
- Sempre use
ONcom colunas indexadas nas cláusulasJOIN. - Evite
JOINsdesnecessários: analise se as tabelas envolvidas realmente precisam estar na consulta. - Use
EXPLAIN(ouEXPLAIN ANALYZE) para identificar gargalos causados porJOINsmal planejados.
5. Use EXPLAIN para entender o plano de execução da consulta
Você já se perguntou como o banco de dados executa uma query por trás dos panos? Saber disso pode ser o divisor de águas entre um sistema performático e um sistema que trava com 10 usuários simultâneos.
É exatamente isso que o comando EXPLAIN oferece: visibilidade total sobre o plano de execução de uma consulta.
O que é o EXPLAIN?
O EXPLAIN é um comando que mostra como o otimizador de consultas do banco de dados vai executar uma query: quais índices serão usados, quais tabelas serão acessadas primeiro, quantas linhas serão lidas, se haverá operações de varredura completa (full scan), junções, ordenações, entre outros detalhes.
Como usar?
Basta colocar o comando EXPLAIN antes da sua query:
EXPLAIN SELECT nome FROM clientes WHERE cidade = 'São Paulo';
Em PostgreSQL e MySQL, ele retorna uma tabela com colunas como:
- id – identificação da etapa da execução.
- select_type – tipo da consulta (simples, subquery, etc.).
- table – qual tabela será consultada.
- type – tipo de acesso (ALL, index, range, ref, eq_ref…).
- possible_keys – quais índices podem ser usados.
- key – qual índice foi de fato usado.
- rows – número estimado de linhas que serão examinadas.
- Extra – observações sobre a execução.
EXPLAIN ANALYZE: performance real em tempo de execução
Enquanto o EXPLAIN simula o plano de execução, o EXPLAIN ANALYZE executa a query de fato e mede o tempo gasto em cada etapa.
EXPLAIN ANALYZE SELECT nome FROM clientes WHERE cidade = 'São Paulo';
Use isso para análises mais profundas em ambiente de teste, jamais em produção com queries pesadas, pois a consulta será executada.
O que observar no plano?
- Uso de índice
- Se a coluna consultada não estiver usando um índice (coluna
keyvazia), pode ser um sinal de ineficiência. - Tipo de acesso (
type)
ALL= varredura completa da tabela (ruim em geral).ref,eq_refouindex= acesso mais eficiente.
- Número de linhas (
rows) - Se a estimativa de linhas for muito alta, pode indicar necessidade de filtrar melhor ou indexar.
- Joins aninhados ou mal otimizados
- Joins que não usam índices, ou em ordem ineficiente, vão aparecer.
Boas práticas ao usar o EXPLAIN
- Sempre rode
EXPLAINantes de aplicar filtros e joins complexos. - Teste diferentes versões da query e compare os planos.
- Adicione índices e verifique se o plano muda (e melhora).
- Combine
EXPLAINcom métricas de tempo real (ANALYZE) para decisões mais seguras.
Conclusão
O uso consciente e estratégico de recursos como LIMIT, índices, JOINs e a análise com EXPLAIN é essencial para o desenvolvimento de consultas SQL de alto desempenho. Mais do que simplesmente escrever uma query funcional, é papel do desenvolvedor compreender como o banco de dados processa cada operação, identificando gargalos e oportunidades de otimização.
Assim como um bibliotecário eficiente sabe exatamente onde encontrar um livro em meio a milhares, o desenvolvedor que domina boas práticas de otimização SQL é capaz de entregar resultados precisos e rápidos, mesmo em bases de dados massivas.
Em ambientes corporativos, onde milissegundos podem impactar diretamente a experiência do usuário e a escalabilidade do sistema, investir tempo no entendimento desses recursos não é opcional — é uma necessidade.
Portanto, o aprendizado contínuo, aliado a testes e medições frequentes, é o caminho para queries cada vez mais performáticas e sistemas mais confiáveis.
Referências
- MySQL Documentation – Optimization Overview:
- https://dev.mysql.com/doc/refman/8.0/en/optimization.html
- PostgreSQL Documentation – Performance Tips:
- https://www.postgresql.org/docs/current/performance-tips.html
- SQLite Documentation – Query Planning:
- https://www.sqlite.org/queryplanner.html
- Livro: SQL Performance Explained – Markus Winand.
- Artigo: 10 SQL Performance Tuning Tips – Percona Blog.





JS
Obrigado, @Dio e todos os outros comentários pelo feedback! Muito feliz por poder apresentar um conteúdo realmente relevante para o dia a dia de todos nós que trabalhamos com software. Acredito que a análise anda junto com todas as outras práticas, mas mais ainda a consciência do profissional ao desenvolver uma solução.
MC
Conteúdo extraordinário e cheio de propósito! É fundamental reforçar que as querys não devem ser construídas de qualquer maneira — é preciso sempre pensar estrategicamente, projetando soluções que atendam não apenas ao agora, mas também ao que vem pela frente.
Parabéns, José!
José, que contribuição extraordinária! Seu artigo é uma verdadeira aula de consciência técnica com propósito, com uma abordagem direta, clara e incrivelmente relevante. Trazer a perspectiva de que uma simples query mal otimizada pode afetar decisões críticas é um lembrete poderoso do papel que nós, profissionais de dados, desempenhamos na sociedade.
Na DIO, acreditamos que a performance não é apenas sobre rapidez, mas sobre responsabilidade e impacto real. E o seu conteúdo traduz isso de forma brilhante. A forma como você articulou boas práticas, explicou o funcionamento interno de comandos como EXPLAIN ANALYZE e contextualizou tudo com um storytelling impactante mostra que SQL vai muito além da técnica.
Na sua visão, qual dessas práticas você acredita que mais falta hoje nos sistemas em produção: uso consciente de índices e LIMIT, ou análise real com ferramentas como o EXPLAIN antes do deploy?
JR
Que conteúdo massa de ler!
JR
Muito bom!
PH
Muito bom José, consegui aplicar na prática tudo que você abordou nesse artigo, parabéns!!
Muito bom zé
SB
Muito bom zé, congratulations
VJ
Muito Bom José, graças a este artigo tive a oportunidade de relembrar de forma clara os conceitos de otimização de consulta, parabéns!!!
GB
Muito bom!