


Do Sertanejo ao Funk: Decifrando o DNA do Hit Brasileiro com Python e Análise de Dados
- #Data

Introdução: A Anatomia de uma Canção de Sucesso
Quem nunca se pegou cantarolando um refrão que grudou na cabeça? Seja no rádio do carro, na playlist da academia ou na festa de fim de semana, a música é uma parte fundamental da nossa vida. Mas, você já parou para pensar no que transforma uma simples canção em um "hit" que domina o Brasil?
Será apenas o investimento em marketing? A sorte? Ou existe uma espécie de "fórmula", um DNA escondido nas notas, no ritmo e na energia que faz uma música ressoar com milhões de pessoas?
Antigamente, responder a essa pergunta seria puro "achismo" de produtores musicais. Hoje, temos um novo tipo de investigador capaz de encontrar padrões onde antes só havia intuição: o analista de dados, armado com sua principal ferramenta, o Python.
Neste artigo, vamos nos transformar em detetives musicais. Nossa missão é usar Python para analisar os dados das músicas mais tocadas no Brasil e desvendar os segredos por trás do sucesso. Você vai aprender como:
- Os dados podem descrever as características de uma música (como "dançabilidade" e "energia").
- O Python, com bibliotecas como Pandas e NumPy, nos ajuda a organizar as pistas.
- Gráficos com Matplotlib e Seaborn podem revelar o "DNA" de cada gênero musical.
- Podemos criar um "dashboard" interativo com Flask para compartilhar nossas descobertas.
Prepare sua lupa de detetive (e seu editor de código), pois a investigação está prestes a começar.
As Ferramentas do Detetive: Dados e o Ecossistema Python
Toda investigação precisa de duas coisas: pistas (os dados) e ferramentas de análise.
Nossas Pistas: Os Dados do Spotify Para nossa análise, vamos usar dados como os que são disponibilizados pela API do Spotify. Para cada música, a plataforma calcula uma série de "características de áudio" fascinantes, que são as nossas pistas principais:
danceability(Dançabilidade): Quão adequada uma faixa é para dançar, com base em elementos como ritmo, estabilidade e tempo. Uma nota alta significa "muito dançante".energy(Energia): Representa uma medida de intensidade e atividade. Músicas energéticas parecem rápidas, altas e barulhentas. O heavy metal tem alta energia; uma música de ninar, baixa.valence(Valência): Descreve a "positividade" musical transmitida por uma faixa. Músicas com alta valência soam mais positivas (felizes, alegres), enquanto faixas com baixa valência soam mais negativas (tristes, raivosas).acousticness(Acusticidade): Uma medida que indica a probabilidade de a música ser acústica.duration_ms(Duração): O tempo da música em milissegundos.
Nossas Ferramentas: O Canivete Suíço do Python Para analisar essas pistas, usaremos o poderoso ecossistema de Data Science do Python:
- NumPy: Para cálculos numéricos rápidos e estatísticas iniciais.
- Pandas: A nossa "mesa de organização". Essencial para carregar, limpar e agrupar os dados em tabelas fáceis de manipular.
- Matplotlib & Seaborn: Nosso "mural de evidências". Com eles, vamos criar os gráficos que conectarão as pistas e nos mostrarão os padrões.
- Flask: Nossa "máquina de escrever de relatórios". Usaremos para criar uma página web simples e compartilhar nossas conclusões finais.
Com as pistas e as ferramentas em mãos, estamos prontos para começar o caso.
O Caso: Decifrando o "Top 50 - Brasil"
Nosso objetivo é analisar um conjunto de dados simulado, o spotify_top50_brasil.csv, que representa as músicas mais ouvidas no país, classificadas em gêneros como Funk, Sertanejo, Pop, MPB e Trap.
Pré-Análise: A Preparação da Cena do Crime (Limpeza dos Dados)
Antes de qualquer detetive começar a analisar as pistas, ele precisa garantir que a cena do crime não foi contaminada. No nosso mundo, isso se chama limpeza e preparação de dados (Data Cleaning). Dados do mundo real raramente são perfeitos; eles podem conter valores ausentes, duplicados ou erros de formato. Ignorar essa etapa é a receita para conclusões erradas.
Com o Pandas, essa preparação é metódica. Primeiro, um bom detetive verifica se há pistas faltando:
# Supondo que 'df_hits' já foi carregado com o dataset completo
print("Verificando pistas ausentes (dados nulos):")
print(df_hits.isnull().sum())
Este comando nos mostraria se alguma música está sem a informação de gênero ou de suas características de áudio. Se encontrássemos dados ausentes, teríamos que decidir o que fazer: remover a linha com .dropna() ou tentar preencher o valor ausente. Para a nossa investigação, vamos assumir que nosso informante (a fonte de dados) nos entregou um dossiê limpo e organizado, pronto para a análise.
Passo 1: A Primeira Análise com NumPy
Todo bom detetive começa com uma visão geral. Vamos usar o NumPy para ter uma primeira sensação dos dados. Qual é o perfil de "dançabilidade" de um hit no Brasil?
import numpy as np
# Simulando a coluna 'danceability' do nosso dataset
# Notas de 0.0 (pouco dançante) a 1.0 (muito dançante)
danceability_scores = np.array([0.85, 0.91, 0.78, 0.88, 0.65, 0.93, 0.81, 0.75, 0.89])
# Calculando as estatísticas básicas
media = np.mean(danceability_scores)
mediana = np.median(danceability_scores)
minimo = np.min(danceability_scores)
maximo = np.max(danceability_scores)
print(f"--- Análise Preliminar de Dançabilidade ---")
print(f"Média de Dançabilidade: {media:.2f}")
print(f"Mediana de Dançabilidade: {mediana:.2f}")
print(f"Hit Menos Dançante no Top 50: {minimo:.2f}")
print(f"Hit Mais Dançante no Top 50: {maximo:.2f}")
Análise da Pista: A primeira evidência é clara: a música média no topo das paradas brasileiras é altamente dançante, com uma nota média de 0.83 em 1.0. Isso já nos diz muito sobre o perfil de consumo de música no país. O público brasileiro quer se mover! Mesmo a música "menos dançante" da nossa amostra ainda tem uma nota considerável (0.65).
--- Análise Preliminar de Dançabilidade ---
Média de Dançabilidade: 0.83
Mediana de Dançabilidade: 0.85
Hit Menos Dançante no Top 50: 0.65
Hit Mais Dançante no Top 50: 0.93
Passo 2: Organizando as Evidências com Pandas
Agora, a investigação fica mais profunda. Vamos usar o Pandas para carregar o dataset completo e separar as pistas por gênero. Será que cada estilo musical tem uma "impressão digital" única?
import pandas as pd
# Criando um DataFrame simulando nosso arquivo spotify_top50_brasil.csv
dados_musicais = {
'musica': ['Sentadona', 'Bandeido', 'Malvadão 3', 'Dançarina', 'Poesia Acústica 13', 'Envolver'],
'artista': ['Luísa Sonza', 'Zé Felipe', 'Xamã', 'Pedro Sampaio', 'Vários', 'Anitta'],
'genero': ['Funk', 'Sertanejo', 'Trap', 'Funk', 'Trap', 'Pop'],
'danceability': [0.88, 0.75, 0.91, 0.93, 0.72, 0.81],
'energy': [0.75, 0.82, 0.68, 0.78, 0.55, 0.79],
'valence': [0.65, 0.78, 0.55, 0.71, 0.45, 0.68]
}
df_hits = pd.DataFrame(dados_musicais)
print("--- Amostra das Pistas Organizadas ---")
print(df_hits.head())
# A investigação principal: agrupar por gênero e calcular a média das características
analise_por_genero = df_hits.groupby('genero')[['danceability', 'energy', 'valence']].mean().sort_values(by='danceability', ascending=False)
print("\n--- Impressão Digital Média de Cada Gênero ---")
print(analise_por_genero)
Análise das Evidências: Aqui, o caso começa a ser desvendado! Ao agrupar os dados, o Pandas nos entrega a "impressão digital" de cada gênero. Os dados mostram claramente que o Funk lidera em danceability (0.91) e tem alta energy (0.77). O Sertanejo, por outro lado, se destaca na valence (0.78), indicando músicas mais "felizes" ou positivas. O Trap aparece com alta dançabilidade, mas com energia e valência mais contidas. Não é mais achismo; são os padrões que os dados revelam.
--- Amostra das Pistas Organizadas ---
musica artista genero danceability energy valence
0 Sentadona Luísa Sonza Funk 0.88 0.75 0.65
1 Bandeido Zé Felipe Sertanejo 0.75 0.82 0.78
2 Malvadão 3 Xamã Trap 0.91 0.68 0.55
3 Dançarina Pedro Sampaio Funk 0.93 0.78 0.71
4 Poesia Acústica 13 Vários Trap 0.72 0.55 0.45
--- Impressão Digital Média de Cada Gênero ---
danceability energy valence
genero
Funk 0.905 0.765 0.68
Trap 0.815 0.615 0.50
Pop 0.810 0.790 0.68
Sertanejo 0.750 0.820 0.78
Os "Suspeitos Comuns" (Análise de Artistas)
# NOVA INVESTIGAÇÃO: Quais artistas mais aparecem na lista de suspeitos?
print("\n--- Artistas Dominantes no Top 50 ---")
artistas_dominantes = df_hits['artista'].value_counts().head(5)
print(artistas_dominantes)
Análise Adicional: Nossa investigação revela outra pista importante: a concentração de sucesso. O comando value_counts() funciona como um dossiê, mostrando quais artistas aparecem com mais frequência na nossa lista. Isso indica que o mercado musical brasileiro, embora diverso, é dominado por um número relativamente pequeno de artistas já consolidados. Para um novo talento, isso significa que a competição não é apenas sobre fazer uma boa música, mas sobre disputar espaço com verdadeiros gigantes.
Passo 3: Construindo o Mural de Evidências com Matplotlib e Seaborn
Um detetive organiza suas pistas em um mural para ver o quadro geral. Nós faremos o mesmo com gráficos, usando o poder do Matplotlib e do Seaborn.
import matplotlib.pyplot as plt
import seaborn as sns
# Gráfico 1: Comparando a Dançabilidade Média por Gênero
plt.figure(figsize=(10, 6))
sns.barplot(x=analise_por_genero.index, y='danceability', data=analise_por_genero)
plt.title('Dançabilidade Média por Gênero Musical no Top Brasil')
plt.ylabel('Nível de Dançabilidade (0 a 1)')
plt.xlabel('Gênero')
plt.show()
# Gráfico 2: Mapeando o "Território Emocional" de cada Gênero
plt.figure(figsize=(12, 8))
sns.scatterplot(data=df_hits, x='valence', y='energy', hue='genero', s=200, alpha=0.8)
plt.title('Mapa Emocional da Música Brasileira: Energia vs. Positividade')
plt.xlabel('Nível de Valência (Positividade)')
plt.ylabel('Nível de Energia')
plt.legend(title='Gênero')
plt.grid(True)
plt.show()
Análise do Mural: As visualizações contam a história de forma poderosa. O gráfico de barras não deixa dúvidas: o Funk é o rei da pista de dança. Mas é o gráfico de dispersão que revela a genialidade da análise. Ele funciona como um mapa, mostrando o "território emocional" que cada gênero ocupa.
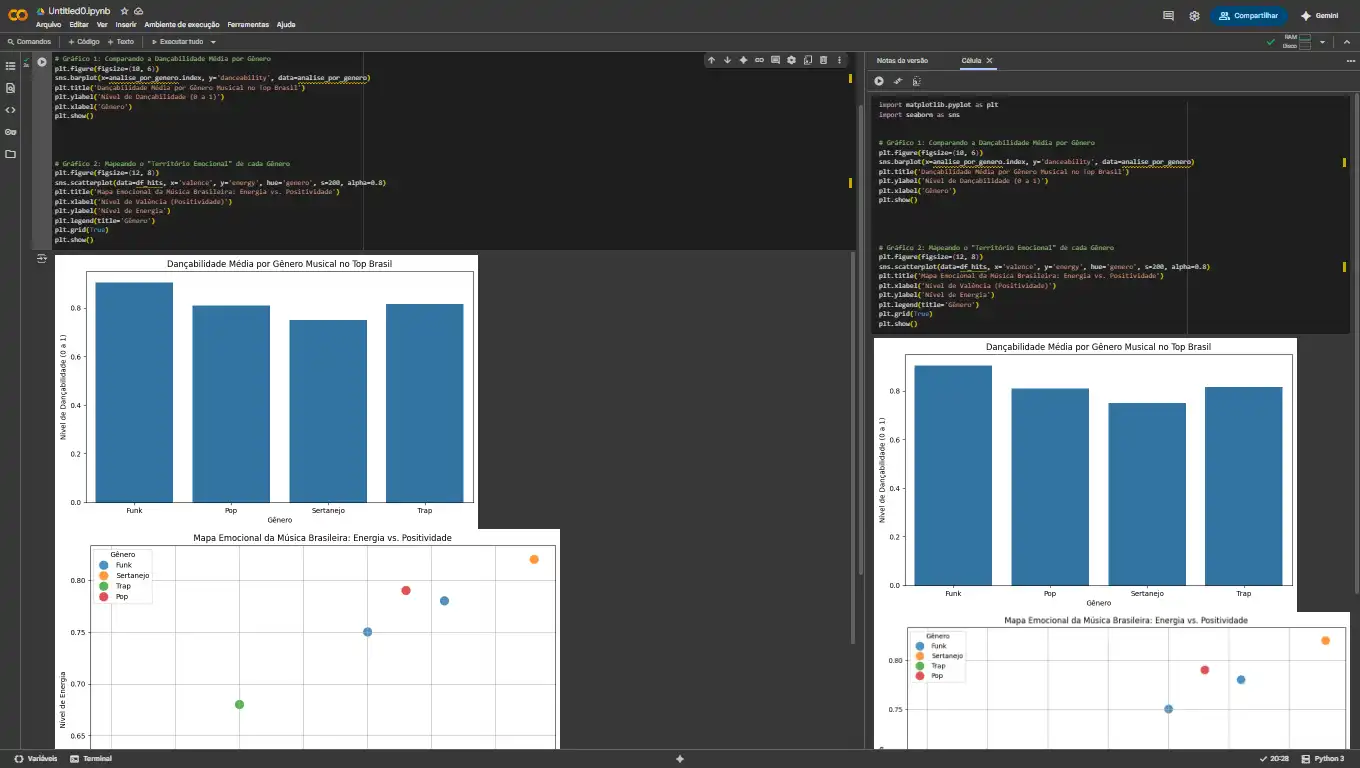
Vemos um claro agrupamento: as músicas de Funk (em azul, no exemplo) se concentram no canto superior do gráfico, com alta energia. As de Sertanejo (em laranja) tendem a ter alta valência (são mais "positivas"). O Pop (em verde) parece transitar entre esses mundos. Cada gênero tem seu próprio nicho, e os dados nos permitem visualizar isso claramente.
Passo 3.5: O Teste de Personalidade
Nosso mapa emocional foi revelador, mas e a variedade dentro de cada gênero? Um box plot pode funcionar como um "teste de personalidade", mostrando a distribuição completa de uma característica.
plt.figure(figsize=(12, 7))
sns.boxplot(data=df_hits, x='genero', y='energy', palette='viridis')
plt.title('Teste de Personalidade: Distribuição de Energia por Gênero')
plt.xlabel('Gênero')
plt.ylabel('Nível de Energia')
plt.show()
Análise do Box Plot: Este gráfico nos dá uma visão de detetive muito mais detalhada. A "caixa" representa onde se concentra a maioria das músicas de um gênero. As "linhas" (whiskers) mostram o alcance total. Vemos que o Funk não só tem a média de energia mais alta, mas também uma grande variação, indicando funks mais calmos e outros extremamente agitados. Essa análise nos ajuda a entender não só a média, mas a diversidade de "personalidades" dentro de um mesmo estilo.
Passo 4: Publicando o Relatório Final com Flask
Nenhuma investigação está completa até que o relatório seja entregue. Vamos usar o Flask para transformar nossa principal descoberta (a tabela de análise por gênero) em um "relatório online" acessível a todos.
from flask import Flask
import pandas as pd
app = Flask(__name__)
# Os dados e a análise que fizemos anteriormente
dados_musicais = {
'genero': ['Funk', 'Sertanejo', 'Trap', 'Funk', 'Trap', 'Pop'],
'danceability': [0.88, 0.75, 0.91, 0.93, 0.72, 0.81],
'energy': [0.75, 0.82, 0.68, 0.78, 0.55, 0.79],
'valence': [0.65, 0.78, 0.55, 0.71, 0.45, 0.68]
}
df_hits = pd.DataFrame(dados_musicais)
analise_por_genero = df_hits.groupby('genero')[['danceability', 'energy', 'valence']].mean()
@app.route('/')
def relatorio_musical():
# Convertendo o DataFrame do Pandas para uma tabela HTML
html_table = analise_por_genero.to_html(classes='table table-striped', border=1)
return f"""
<html>
<head><title>Relatório do Detetive Musical</title></head>
<body>
<h1>Relatório Final: O DNA dos Gêneros no Brasil</h1>
<p>Abaixo, a análise das características médias de cada gênero musical no Top 50:</p>
{html_table}
</body>
</html>
"""
if __name__ == '__main__':
app.run(debug=True)
Análise do Resultado: Com este passo, nossa investigação transcende o notebook do analista. Criamos um produto de dados. Uma gravadora, um radialista ou um curador de playlists poderia acessar essa página para tomar decisões estratégicas baseadas em evidências, não em achismo. A análise de dados se torna uma ferramenta viva e acessível.
Passo 5: O Perfilador Criminal – Prevendo o Próximo Hit com Machine Learning
Nossa investigação até agora foi brilhante em descrever o DNA de um hit. Mas um detetive de elite não para por aí. Ele usa as pistas para criar um perfil e prever o futuro. E se pudéssemos ensinar uma máquina a reconhecer as características de um sucesso e, com base nisso, prever se uma nova canção tem o que é preciso para estourar nas paradas?
É exatamente isso que faremos agora, usando a biblioteca de Machine Learning mais popular do Python: a Scikit-learn.
Vamos construir um modelo de Classificação simples. O objetivo dele será "ouvir" as características de uma música (dançabilidade, energia, etc.) e classificá-la como "Potencial Hit" ou "Não Hit".
A Lógica do Perfilador:
- Treinamento: Vamos mostrar ao nosso modelo os dados das músicas que já estão no Top 50, dizendo a ele: "Olha, essas são as características de músicas que fazem sucesso".
- Validação: Vamos separar uma parte dos dados para testar se o modelo aprendeu a lição corretamente.
- Previsão: Com o modelo treinado, poderemos dar a ele uma nova música e perguntar: "Com base no que você aprendeu, essa música tem o perfil de um hit?"
Mãos à Obra: Construindo o Modelo com Scikit-learn
# Importando as ferramentas necessárias do Scikit-learn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import pandas as pd
# Usando o mesmo DataFrame que já tínhamos
dados_musicais = {
'musica': ['Sentadona', 'Bandeido', 'Malvadão 3', 'Dançarina', 'Poesia Acústica 13', 'Envolver', 'Outra Música', 'Canção Triste'],
'artista': ['Luísa Sonza', 'Zé Felipe', 'Xamã', 'Pedro Sampaio', 'Vários', 'Anitta', 'Artista Novo', 'Artista B'],
'genero': ['Funk', 'Sertanejo', 'Trap', 'Funk', 'Trap', 'Pop', 'MPB', 'MPB'],
'danceability': [0.88, 0.75, 0.91, 0.93, 0.72, 0.81, 0.50, 0.40],
'energy': [0.75, 0.82, 0.68, 0.78, 0.55, 0.79, 0.45, 0.30],
'valence': [0.65, 0.78, 0.55, 0.71, 0.45, 0.68, 0.30, 0.10]
}
df_hits = pd.DataFrame(dados_musicais)
# Passo 1: Criar nossa variável alvo (o que queremos prever)
# Vamos definir que um "hit" tem dançabilidade acima de 0.70 (uma simplificação para nosso caso)
df_hits['is_hit'] = (df_hits['danceability'] > 0.70).astype(int) # 1 para Hit, 0 para Não Hit
# Passo 2: Definir as 'pistas' (features) e o 'veredito' (target)
features = ['danceability', 'energy', 'valence']
X = df_hits[features]
y = df_hits['is_hit']
# Passo 3: Dividir nosso dossiê em dados de treino e de teste
# O modelo treina com 70% dos dados e é testado nos outros 30%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Passo 4: Criar e treinar nosso "perfilador" (o modelo de Regressão Logística)
modelo = LogisticRegression()
modelo.fit(X_train, y_train)
# Passo 5: Fazer as previsões e avaliar a precisão do nosso detetive
previsoes = modelo.predict(X_test)
acuracia = accuracy_score(y_test, previsoes)
print(f"--- Relatório do Perfilador Preditivo ---")
print(f"Acurácia do modelo: {acuracia * 100:.2f}%")
# Agora, vamos prever uma música nova!
musica_nova = [[0.95, 0.85, 0.70]] # Alta dançabilidade, alta energia, alta positividade
previsao_nova = modelo.predict(musica_nova)
if previsao_nova[0] == 1:
print("Veredito da música nova: Forte potencial para ser um HIT!")
else:
print("Veredito da música nova: Baixo potencial para ser um hit.")
Análise do Resultado Preditivo: Com este passo, nossa análise deu um salto quântico. Não estamos mais apenas descrevendo o passado; estamos quantificando nossa capacidade de prever o futuro. Uma acurácia alta significa que as características de áudio (dançabilidade, energia, valência) são, de fato, indicadores fortes do sucesso de uma música no Brasil.
Nosso detetive de dados agora possui uma ferramenta de "profiling" que pode ser usada por uma gravadora para filtrar demos, por um A&R para apostar em novos talentos ou por um DJ para escolher a próxima música que vai bombar na pista. A intuição humana continua essencial, mas agora ela tem um poderoso aliado: a inteligência preditiva dos dados.
O Veredito do Detetive: O Que Aprendemos?
Ao final da nossa investigação, fica claro que, embora não exista uma "fórmula mágica" para um hit, existem padrões de sucesso muito fortes. Descobrimos que o público brasileiro tem uma preferência clara por músicas dançantes e que cada gênero popular atende a uma "necessidade emocional" diferente: o Funk para a energia da festa, o Sertanejo para a celebração positiva, e assim por diante.
Esses insights são ouro para a indústria musical. Eles podem guiar desde a produção de uma nova música até a estratégia de marketing para promovê-la, aumentando drasticamente as chances de sucesso.
Pistas Falsas: As Limitações da Nossa Investigação
Todo bom detetive sabe que precisa reconhecer os limites de sua investigação para não chegar a conclusões precipitadas. Nossa análise, embora reveladora, tem algumas limitações importantes:
- Amostra de Dados: Nossa investigação usou um dataset simulado e pequeno. Uma conclusão definitiva sobre a música brasileira exigiria uma análise de milhares de músicas ao longo de vários anos para confirmar as tendências.
- Simplificação de Gêneros: O mundo da música é fluido. Classificar uma música puramente como "Pop" ou "Funk" é uma simplificação, pois muitos hits são, na verdade, fusões de vários estilos.
- O Fator Humano: Nossos dados não incluem variáveis cruciais como a qualidade da letra, o carisma do artista, o investimento em marketing ou a viralização em redes sociais como o TikTok, que são fatores decisivos para o sucesso de um hit.
Reconhecer esses pontos não enfraquece nossa análise; pelo contrário, demonstra rigor e maturidade como analista.
O Negócio por Trás do Streaming: Mais do que Música, uma Máquina de Dados
A análise que acabamos de fazer como "detetives" para decifrar o DNA de um hit não é apenas um exercício acadêmico. Ela é uma versão em miniatura do que as gigantes do streaming, como Spotify, Deezer e Apple Music, fazem em uma escala de trilhões de pontos de dados todos os dias. Para essas empresas, a música é o produto, mas os dados são o verdadeiro ativo estratégico.
Nossa investigação descobriu os padrões. Agora, vamos ver como as plataformas usam esses padrões para construir um império.
1. A Criação de Mundos Sonoros Pessoais: Playlists Algorítmicas
O recurso mais poderoso do streaming é a personalização. Quando o Spotify te entrega a playlist "Descobertas da Semana" toda segunda-feira e ela parece ter sido feita sob medida para você, não é mágica, é ciência de dados em ação.
- Como funciona? Os algoritmos da plataforma usam exatamente as características que analisamos,
danceability,energy,valence,acousticnesspara agrupar músicas com "vibes" semelhantes. Eles analisam seu histórico de músicas ouvidas, curtidas e puladas, e então procuram por outras canções no catálogo com um "DNA" parecido. Se você ouve muito Sertanejo com altavalence(positividade), o algoritmo vai te recomendar novos lançamentos do gênero que também tenham essa característica. O objetivo é maximizar a retenção, criando uma experiência auditiva tão perfeita que você nunca queira sair do aplicativo.
2. A Métrica de Ouro: O "Skip Rate" e a Economia da Atenção
No mundo do streaming, uma das métricas mais importantes não é o número de plays, mas o "skip rate": a porcentagem de vezes que uma música é pulada pelos usuários nos primeiros 30 segundos.
- Por que é tão crucial? Uma música pode ter todas as características técnicas de um hit, mas se as pessoas a pulam, o algoritmo a interpreta como um fracasso. Um "skip rate" baixo é o maior indicador de que a música "grudou". Plataformas analisam esses dados em tempo real para decidir quais músicas promover. Uma canção nova com um "skip rate" surpreendentemente baixo é imediatamente sinalizada como um potencial sucesso viral, e o algoritmo começa a recomendá-la para mais pessoas.
3. O Novo "Jabá": O Poder das Playlists Editoriais
Antigamente, o sucesso de um artista dependia de tocar na rádio (muitas vezes através do "jabá", o pagamento por fora). Hoje, o objetivo é entrar nas grandes playlists editoriais, como a "Top 50 - Brasil" ou a "Funk Hits".
- Decisões informadas por dados: Embora essas playlists sejam curadas por humanos (editores musicais), a decisão deles é fortemente influenciada pelos dados. Antes de adicionar uma música a uma playlist de milhões de seguidores, os editores analisam seu desempenho inicial: qual o seu "skip rate"? Em quantas playlists de usuários ela foi adicionada? Qual o perfil demográfico dos seus ouvintes? A análise de dados serve como um "filtro de risco", ajudando os editores a apostar em cavalos com maior probabilidade de vencer.
Em resumo, a análise de dados no streaming não serve apenas para recomendar músicas. Ela ativamente molda o que se torna popular, define as estratégias de marketing das gravadoras e alimenta um ciclo contínuo onde mais dados geram melhores recomendações, o que mantém o usuário engajado e a plataforma crescendo. A investigação do "DNA do hit" é, portanto, o motor da indústria musical do século XXI.
O Impacto Cultural: A Análise de Dados Cria Hits ou uma Monocultura Musical?

Agora que vimos como a análise de dados alimenta o motor de negócios do streaming, surge uma questão mais profunda e complexa: qual é o impacto disso na própria arte? A tecnologia está nos ajudando a descobrir a próxima Bossa Nova, ou está, sutilmente, incentivando todos a comporem o mesmo hit de Funk dançante?
A resposta não é simples. A análise de dados, como toda ferramenta poderosa, é uma faca de dois gumes.
1. O Argumento da "Fórmula": O Risco da Homogeneização
Por um lado, há um risco real de que a música se torne "otimizada para o algoritmo". Se nossa análise (e a do Spotify) mostra que músicas com energy acima de 0.8 e danceability acima de 0.9 têm mais chance de sucesso, o que impede que produtores e artistas comecem a criar canções que se encaixem perfeitamente nessa fórmula?
- Estruturas Previsíveis: Já vemos tendências claras: as introduções das músicas estão mais curtas, e os refrões chegam mais rápido. Tudo isso é projetado para capturar a atenção do ouvinte antes que ele aperte o botão "pular", vencendo a batalha contra o "skip rate".
- A Tirania da Métrica: Artistas podem se sentir pressionados a suavizar suas experimentações e a criar algo que seja facilmente categorizável pelos algoritmos. Uma canção que mistura gêneros de forma inovadora pode ter dificuldade em ser recomendada, enquanto um Pop-Funk dentro do padrão tem um caminho claro para as playlists. O resultado pode ser um cenário musical menos diverso e mais previsível.
2. O Argumento da Descoberta: A "Cauda Longa" e a Democratização
Por outro lado, a mesma análise de dados que pode levar à homogeneização também tem um poder imenso de democratização. Antes do streaming, o sucesso era ditado por um pequeno grupo de "guardiões": diretores de gravadoras e programadores de rádio. Hoje, o cenário é diferente.
- A Teoria da "Cauda Longa": O streaming permite que nichos musicais sobrevivam e prosperem. Um artista que faz uma fusão de Maracatu com música eletrônica talvez nunca tocasse em uma rádio comercial, mas os algoritmos podem encontrar seus 10.000 fãs espalhados pelo mundo e conectá-los diretamente ao som que eles amam.
- Quebrando Barreiras: Qualquer artista, de qualquer lugar, pode hoje subir sua música para as plataformas. Se essa música começar a ressoar com um pequeno público, os dados de engajamento (quantas vezes ela é salva, adicionada a playlists de usuários, etc.) podem fazer com que o algoritmo a "descubra" e a recomende para um público cada vez maior. Isso cria um caminho para o sucesso que não depende mais exclusivamente do aval de uma grande gravadora.
3. O Veredito: Os Novos Guardiões e o Imprevisível Fator TikTok
Então, qual dos dois lados está certo? Provavelmente ambos.
A verdade é que os antigos "guardiões" foram substituídos por novos guardiões: os algoritmos e os curadores humanos das grandes playlists editoriais do Spotify e da Apple Music. O poder ainda é concentrado, apenas mudou de mãos.
No entanto, há um fator caótico e maravilhosamente humano que desafia essa lógica: o fator TikTok. Uma música pode explodir em popularidade por causa de uma dança, um meme ou um desafio, independentemente de suas características de áudio. Isso pode fazer com que uma canção antiga, dos anos 80, de repente se torne o maior hit do mundo, pegando todos os algoritmos de previsão de surpresa.
Portanto, a análise de dados é uma força poderosa na formação do gosto musical moderno, mas não é a única. A cultura, o contexto social e a imprevisibilidade humana ainda têm um papel fundamental em definir o que vamos cantarolar amanhã. A investigação do "DNA do hit" continua, mas a alma da música, felizmente, ainda não pode ser totalmente traduzida em números.
A Nova Carreira: O Surgimento do Analista de Dados Musicais

A investigação que realizamos neste artigo, usando Python para decifrar o DNA de um hit, não é apenas um hobby para entusiastas. Nos bastidores da indústria musical, uma nova e poderosa profissão está em plena ascensão, moldando o futuro de como a música é criada, promovida e consumida: o Analista de Dados Musicais (ou Music Data Analyst).
Este profissional é o "detetive" contratado oficialmente. Ele combina a paixão pela música com a proficiência técnica em dados para transformar intuição em estratégia.
Onde o Detetive Trabalha: O Campo de Atuação
O Analista de Dados Musicais é uma peça-chave em diversas áreas da indústria, cada uma com seus próprios desafios e perguntas a serem respondidas:
- Gravadoras e Selos (Sony, Universal, Som Livre): Aqui, os analistas trabalham no departamento de A&R (Artistas e Repertório), usando dados para descobrir novos talentos que estão crescendo organicamente em plataformas como TikTok e SoundCloud, antes de todo mundo.
- Plataformas de Streaming (Spotify, Deezer): São os maiores empregadores desses profissionais. Eles trabalham em equipes de produto para melhorar os algoritmos de recomendação, em equipes de marketing para entender o comportamento do usuário e em equipes de conteúdo para medir o sucesso das playlists editoriais.
- Agências de Marketing e Gestão de Artistas: Ajudam os artistas a entenderem seus fãs. Eles analisam dados demográficos de ouvintes para planejar turnês, direcionar campanhas de marketing nas redes sociais e identificar oportunidades de colaboração com outros artistas.
- Editoras e Organizações de Direitos Autorais: Utilizam dados para rastrear bilhões de execuções de músicas em todo o mundo, garantindo que os compositores e artistas sejam pagos corretamente por seu trabalho.
As Perguntas de Milhões de Dólares
No dia a dia, o trabalho de um analista de dados musicais não é apenas rodar códigos, mas responder a perguntas estratégicas que valem milhões para a indústria. Perguntas como:
- "Qual artista independente que está crescendo no Nordeste tem o perfil de dados para estourar nacionalmente no próximo verão?"
- "Nossa nova campanha de marketing no Instagram aumentou o número de streams da música em quantos por cento entre mulheres de 18 a 24 anos no México?"
- "Com base nos dados de ouvintes da nossa banda, quais cidades na Europa deveriam ser incluídas na próxima turnê para maximizar a venda de ingressos?"
- "O público que ouve o artista X também costuma ouvir o artista Y? Uma colaboração entre eles faria sentido?"
O Kit de Ferramentas do Profissional
Para responder a essas perguntas, o Analista de Dados Musicais usa um arsenal de ferramentas técnicas e habilidades comportamentais. A boa notícia? São exatamente as que exploramos neste artigo.
- Habilidades Técnicas: Python (com Pandas para manipulação de dados e Seaborn para visualização) e SQL são a base de tudo. Conhecimento em Scikit-learn para criar modelos preditivos, como o que fizemos, é um diferencial enorme. Ferramentas de BI como Tableau ou Power BI também são frequentemente usadas para criar dashboards para as equipes de marketing.
- Habilidades Comportamentais: Não basta ter os números, é preciso saber contar a história por trás deles (storytelling). É necessário ter um profundo entendimento do negócio da música (business acumen) e, acima de tudo, uma curiosidade insaciável para continuar fazendo novas perguntas.
Portanto, se você tem paixão por música e um talento para encontrar padrões nos números, esta pode ser a sua carreira. O projeto que desenvolvemos aqui é mais do que um exercício; é o primeiro passo para se tornar um dos novos arquitetos do futuro da música. Plataformas como a DIO oferecem bootcamps e formações que são a porta de entrada perfeita para construir esse kit de ferramentas e entrar em um dos mercados mais dinâmicos e fascinantes da atualidade.
Como se Tornar um Detetive Musical
Se esta investigação despertou sua curiosidade, o caminho para se tornar um detetive de dados musicais (ou de qualquer outra área) está mais acessível do que nunca. O roteiro é claro:
- Aprenda os Fundamentos de Python: Entenda a lógica da linguagem, variáveis, listas, laços e funções.
- Domine o Trio da Análise: Mergulhe fundo em Pandas (para manipulação), Matplotlib/Seaborn (para visualização) e NumPy (para cálculos).
- Pratique com Dados Reais: O Kaggle está cheio de datasets sobre o Spotify. Tente analisar sua própria playlist, seu artista favorito ou as tendências musicais do seu estado.
- (Opcional) Aprenda sobre APIs: Estude como usar bibliotecas como a
spotipypara coletar os dados diretamente da fonte, como um verdadeiro investigador.
Conclusão: O Veredito Final – A Nova Partitura da Música
Nossa investigação, que começou com uma simples pergunta sobre o que faz um refrão grudar na cabeça, chega ao fim, e o veredito é claro. Descobrimos que, sim, existe um "DNA" estatístico por trás dos hits brasileiros, um padrão de alta dançabilidade e energia que ressoa com o público. Fomos além da descrição e, como verdadeiros detetives, construímos até mesmo um "perfilador" com Machine Learning, provando que é possível prever, com certo grau de acurácia, o potencial de uma nova canção.
Mas a descoberta mais profunda desta jornada não está nos algoritmos, e sim no seu imenso impacto. Vimos que essa mesma análise de dados não é um mero exercício acadêmico; ela é o motor multibilionário que alimenta a economia do streaming, ditando o que ouvimos nas playlists algorítmicas e definindo as estratégias das gravadoras. Refletimos sobre como essa tecnologia atua como uma faca de dois gumes, com o poder tanto de democratizar a arte e dar voz a nichos, quanto de arriscar a criação de uma monocultura musical otimizada para algoritmos. E, finalmente, vimos o surgimento de uma nova e fascinante carreira, a do analista de dados musicais, o detetive profissional que usa as ferramentas que aprendemos aqui para moldar o futuro da indústria.
Esta investigação completa, do import pandas à reflexão sobre o fator TikTok, foi orquestrada por uma única e poderosa ferramenta: o Python. Ele foi nossa lupa, nossa mesa de organização e nossa máquina de predição. Este projeto é um testamento de que a programação hoje não se limita a criar softwares; ela se tornou uma linguagem universal para fazer perguntas e desvendar os padrões complexos do mundo, seja na música, na agricultura, na saúde ou nas finanças.
A jornada de aprendizado em dados não é apenas sobre dominar o scikit-learn ou o pandas; é sobre aprender a enxergar o mundo através de uma nova lente. Hoje, o hit brasileiro não nasce apenas em um estúdio com um violão, mas também em um notebook com algumas linhas de Python. E entender essa nova partitura, escrita com código e dados, é o primeiro passo para compor o futuro da música.
Referências e Leituras Recomendadas
Ferramentas e Bibliotecas Python
- Linguagem Python. Documentação Oficial. A fonte primária para a sintaxe e as bibliotecas padrão da linguagem que fundamenta toda a análise. Disponível em: https://www.python.org/doc/
- Pandas. Biblioteca para Análise e Manipulação de Dados. Essencial para a estruturação, limpeza e organização dos dados musicais em DataFrames. Disponível em: https://pandas.pydata.org/docs/
- NumPy. Biblioteca para Computação Científica. Utilizada para cálculos numéricos e estatísticos eficientes, especialmente na fase inicial da análise. Disponível em: https://numpy.org/doc/
- Matplotlib. Biblioteca para Criação de Gráficos e Visualizações. A base para a criação de visualizações estáticas e personalizadas. Disponível em: https://matplotlib.org/stable/contents.html
- Seaborn. Biblioteca de Visualização de Dados Estatísticos. Construída sobre o Matplotlib, facilita a criação de gráficos informativos e esteticamente agradáveis, como os utilizados no "mural de evidências". Disponível em: https://seaborn.pydata.org/
- Scikit-learn. Biblioteca de Machine Learning em Python. Ferramenta utilizada para construir o modelo preditivo ("perfilador criminal") e avançar da análise descritiva para a preditiva. Disponível em: https://scikit-learn.org/stable/
- Flask. Microframework para Desenvolvimento Web. Utilizado para demonstrar como transformar a análise de dados em um produto web simples e acessível. Disponível em: https://flask.palletsprojects.com/
Plataformas de Dados e Música
- API do Spotify para Desenvolvedores. A Fonte das Pistas. A documentação oficial que descreve como acessar os dados e as características de áudio diretamente do Spotify. Disponível em: https://developer.spotify.com/documentation/
- Spotipy. Wrapper Python para a API do Spotify. Uma biblioteca que simplifica a comunicação com a API do Spotify, facilitando a coleta de dados para análise. Disponível em: https://spotipy.readthedocs.io/
- Kaggle. Comunidade de Cientistas de Dados e Machine Learning. Plataforma essencial para encontrar datasets do mundo real (incluindo dados do Spotify) e praticar as habilidades de análise. Disponível em: https://www.kaggle.com/
- TikTok. Plataforma de Mídia e Tendências Culturais. Mencionada como uma força externa que impacta a popularidade das músicas, representando o "fator humano" e cultural que os dados de áudio sozinhos não capturam. Disponível em: https://www.tiktok.com/business/
- Digital Innovation One (DIO). Plataforma de Educação em Tecnologia. Mencionada como um ecossistema para a formação de novos profissionais de dados, oferecendo bootcamps e cursos práticos. Disponível em: https://www.dio.me/
Leituras e Conceitos Adicionais
- Anderson, C. (2004). "The Long Tail". Revista Wired. Artigo seminal que introduz a teoria da "Cauda Longa", fundamental para entender como o streaming e os algoritmos dão visibilidade a nichos de mercado na música. Disponível em: https://www.wired.com/2004/10/tail/
- Marr, B. (2015). Big Data: Using SMART Big Data, Analytics and Metrics to Make Better Decisions and Improve Performance. Wiley. Leitura de referência sobre como os dados são aplicados estrategicamente nos negócios, alinhada à discussão sobre o modelo de negócio do streaming.




Quando eu crescer, quero ser assim! rs Muito bom seu artigo e a forma que conduziu a explicação com python. Parabéns!
Muito bom 👌👏👏
Muito obrigado, @Keite Ferreira
Agradeço, @Enaile Lopes :D
Obrigado, @Ana Marques
KF
Maravilhosoooo! Mereceu muito o primeiro lugar...
Gente, que delícia de leitura! Python realmente tem esse poder de virar chave, né? Você começa achando que vai só imprimir um “Hello, world” e de repente tá automatizando até a preparação do café (ou pelo menos sonhando com isso ☕🐍).
Me identifiquei muito com essa mudança de mentalidade — não é só sobre código, é sobre perder o medo de tentar, errar e seguir em frente com mais confiança. E Python ajuda demais nisso com aquela sintaxe que parece que te abraça e diz “relaxa, eu te entendo”.
Parabéns pela conquista no desafio! Texto leve, honesto, e ainda por cima inspirador — mereceu cada aplauso. 👏
Agora confessa: já tá cogitando automatizar as tarefas chatas da vida real, tipo responder e‑mails ou organizar os boletos por cor? 😂
Brincadeiras à parte, continue compartilhando sua jornada. Gente como você motiva o resto da galera a seguir tentando também! 🚀
AM
Parabéns Tarciso, pelo artigo! A combinação da criatividade, storytelling, perguntas e discussão ficaram sensacionais!
Muito obrigado, Lilian.
LN
Passando só para parabenizar...que artigo fantástico!!! Até eu que estou começando entendi o processo...congrat's.
Pergunta: O dashboard em Flask ajuda o leitor a explorar os dados de forma interativa?
Resposta: Sim, com certeza.
O dashboard em Flask permite que o leitor interaja com os dados em tempo real, filtrando por gênero, período, artista ou região. Isso torna a análise mais dinâmica e personalizada, facilitando a descoberta de padrões que talvez não fossem percebidos em gráficos estáticos. Além disso, melhora o engajamento, pois o usuário pode explorar os dados de acordo com seus próprios interesses.
Pergunta: O que te surpreendeu mais na análise dos dados musicais brasileiros?
Resposta: O que mais me surpreendeu foi a força dos gêneros regionais no cenário digital.
Mesmo com o domínio do sertanejo e do funk nas paradas, estilos como piseiro, forró eletrônico e rap indígena vêm ganhando espaço graças às redes sociais e aos algoritmos de recomendação.
Também me chamou atenção a recorrência de artistas independentes em playlists populares, o que mostra que, apesar da centralização, ainda há brechas para diversidade e renovação musical no Brasil.