
Set e Map em Java: como gerenciar duplicados corretamente
- #Java
Introdução
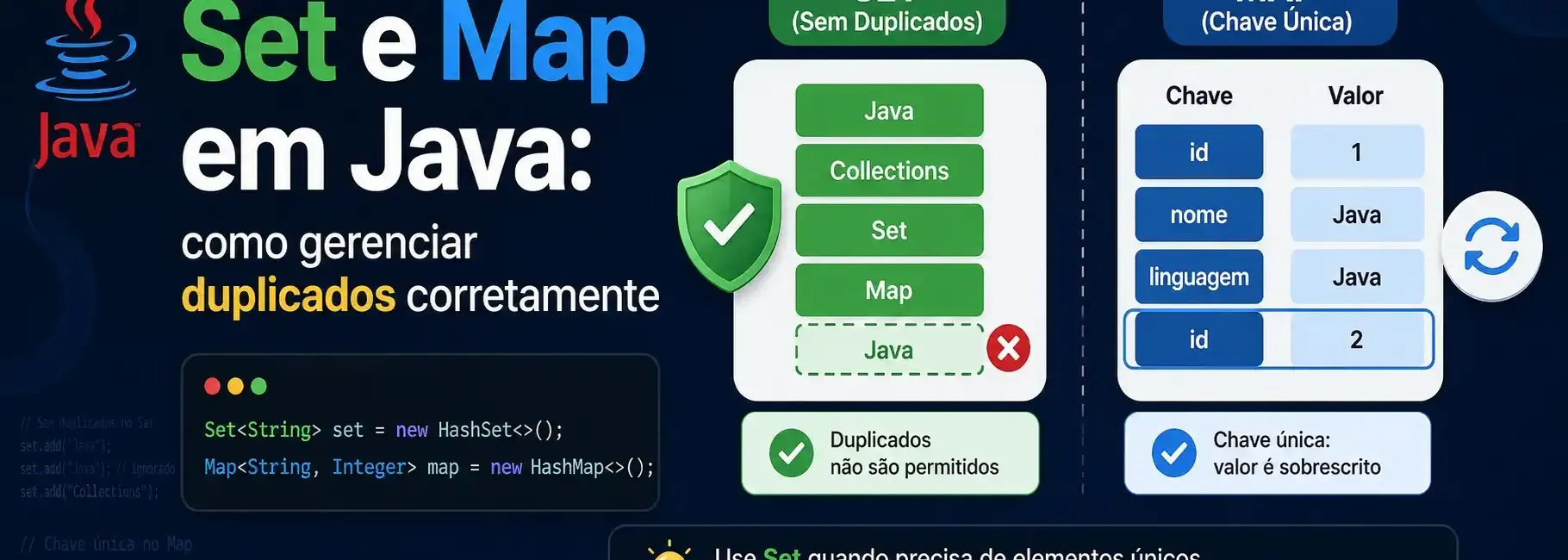
- Set<> é uma interface de coleção que representa um conjunto de elementos sem duplicatas. A unicidade é determinada por equals() (e hashCode() em implementações como HashSet()). Não possui índice nem estrutura chave/valor, ex:
Set<Integer> setDatos = new HashSet<>();
setDatos.add(10);
setDatos.add(20);
setDatos.add(10);
System.out.println(setUser);
Isso retorna como resultado uma coleção de elementos sem duplicatas, vemos que o valor duplicado não é exibido no conjunto:
[20, 10]
- Map<> é uma interface de coleção que representa uma estrutura de par chave/valor (key/value), ex:
Map<Integer, String> mapDatos = new HashMap<>();
mapDatos.put(1, "dato1");
mapDatos.put(2, "dato2");
mapDatos.put(2, "dato3");
System.out.println(mapDatos);
Retorna uma estrutura chave/valor onde não são permitidas chaves duplicadas. Se uma chave existente for inserida, o valor anterior é substituído pelo novo.
Como se vê no exemplo, estamos duplicando a chave “dato3”, portanto o valor anterior (com a mesma chave) é sobrescrito.
{1=dato1, 2=dato3}
Resumo:
- Utilize Set<> quando precisar de elementos únicos
- Use Map<> quando precisar de chaves únicas e valores associados
Mas.....
O que acontece quando estamos considerando uma classe "User" para criar um Map<>?
public class User {
private int code;
private String name;
public User(int code, String name) {
this.code = code;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return code == user.code && Objects.equals(name, user.name);
}
@Override
public int hashCode() {
return Objects.hash(code, name);
}
@Override
public String toString() {
return "User{" +
"code=" + code +
", name='" + name + '\'' +
'}';
}
}
Provavelmente faríamos isto:
Map<Integer, User> newMapUser = new HashMap<>();
newMapUser.put(1, new User(1, "John"));
newMapUser.put(2, new User(2, "Jane"));
newMapUser.put(3, new User(2, "Jane"));
O console.log nos mostraria a seguinte estrutura chave/valor
{
1=User{code=1, name='John'},
2=User{code=2, name='Jane'},
3=User{code=2, name='Jane'}
}
Mas....
Vemos que existe um value que está se repetindo
User{code=2, name='Jane'}
- Isso ocorre porque um Map<> apenas evita a duplicidade de chaves (keys), não de valores (values).
- Portanto, pode haver várias chaves diferentes apontando para objetos iguais ou até mesmo para o mesmo objeto em memória.
- Mesmo que a classe User sobrescreva os métodos equals() e hashCode(), isso não afeta o comportamento dos valores dentro de um Map, já que essas regras de unicidade se aplicam apenas às chaves.
Uma possível solução seria complementar um Map<> com um Set<>
Set<User> userSet = new HashSet<>();
userSet.add(new User(1, "claudio"));
userSet.add(new User(2, "maria"));
userSet.add(new User(2, "maria"));
Map<Integer, Set<User>> mapUserSet = new HashMap<>();
mapUserSet.put(1, userSet);
System.out.println(mapUserSet);
- Criamos um set para não permitir elementos duplicados
- O terceiro add tenta inserir um objeto igual ao segundo
- como User sobrescreve equals() e hashCode() o duplicado não é adicionado
- Criamos o Map<> para não permitir chaves duplicadas
- key = Integer
- value = Set<User>
Estamos associando a chave Integer ao Set de User
- Mostramos no console.log
{
1=[
User{code=2, name='maria'},
User{code=1, name='claudio'}
]
}
Podemos ver que não temos duplicidade de chaves nem de valores com esta implementação.
Ideia final
- Set -> elimina duplicatas de User
- Map -> organiza esses sets por chaves
- As duas estruturas são combinadas para ter "uma chave" -> "um conjunto" SEM DUPLICATAS





