
A Jornada dos Dados: Como Integrar Azure SQL, ADLS, Databricks e Fabric para Gerar Valor aos Negócio
A Jornada dos Dados: Como Integrar Azure SQL, ADLS, Databricks e Fabric para Gerar Valor Real aos Negócios
No cenário atual, dados são o ativo mais valioso de qualquer organização. Mas, ao contrário do que muitos imaginam, o valor não está nos dados em si — e sim na capacidade de transformá-los em informação útil, confiável e acessível. Essa transformação exige muito mais do que ferramentas isoladas: requer a integração harmoniosa de múltiplos sistemas, cada um com suas particularidades, limitações e pontos fortes.
Este artigo apresenta uma visão prática dessa jornada, baseada no desenvolvimento de um pipeline completo que conecta Azure SQL Database, Azure Data Lake Storage (ADLS), Azure Databricks, Microsoft Fabric e Power BI, demonstrando como tecnologias distintas podem trabalhar juntas para entregar insights de alto impacto.
1. O Desafio: Unir Sistemas Diferentes em um Propósito Comum
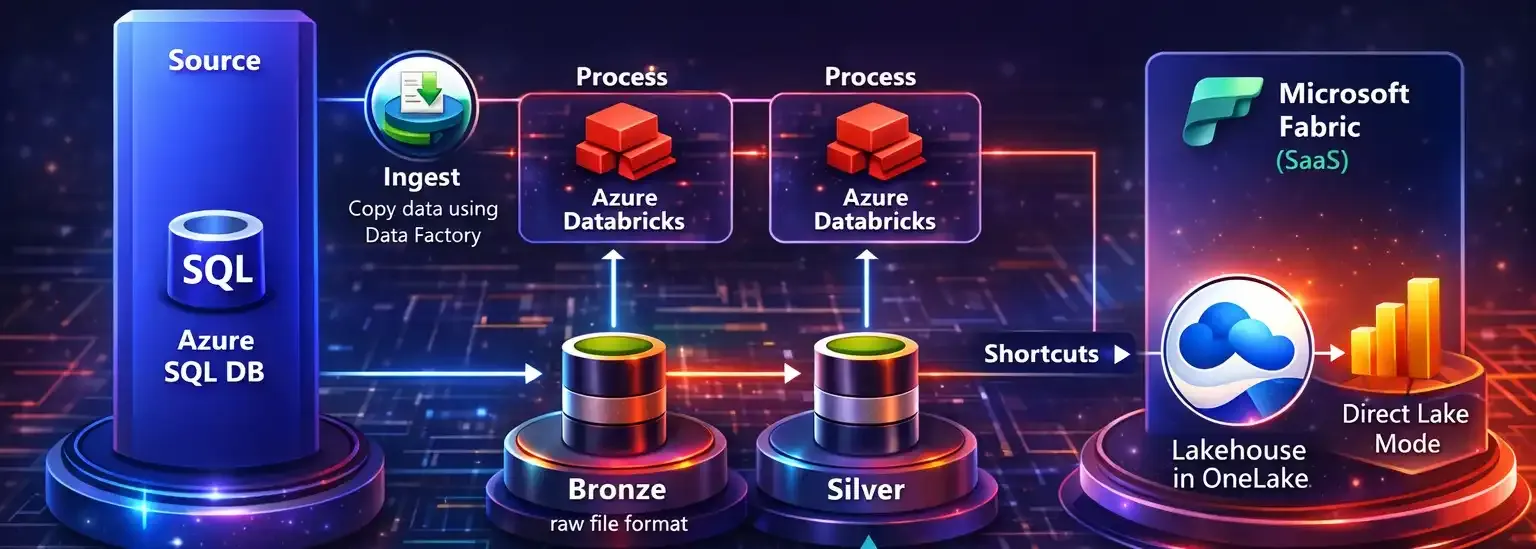
Cada tecnologia envolvida no pipeline cumpre um papel específico:
- Azure SQL Database é a fonte transacional, onde os dados nascem.
- ADLS é o repositório escalável que organiza os dados em camadas.
- Azure Databricks é o motor de processamento e transformação.
- Fabric Data Factory é o orquestrador que garante fluidez e automação.
- Fabric Lakehouse é a camada de consumo analítico.
- Power BI é a porta de entrada para o usuário final.
Esses sistemas não foram criados para competir entre si, mas para se complementar. Cada um traz uma especialidade que, quando bem combinada, resulta em um ecossistema poderoso e eficiente.
2. A Origem: Dados Transacionais no Azure SQL Database
O pipeline começa com o Azure SQL Database, onde reside o banco AdventureWorks, uma base rica em tabelas de vendas, produtos, clientes e operações.
Essa camada é essencialmente operacional:
- alta disponibilidade
- consistência transacional
- consultas rápidas para aplicações
Mas não é adequada para análises pesadas ou transformações complexas.
Por isso, os dados precisam ser extraídos e enviados para um ambiente mais flexível.
3. O Lago de Dados: ADLS e a Organização em Camadas
O Azure Data Lake Storage é o coração do pipeline. Ele organiza os dados em três camadas:
- Bronze → dados brutos, exatamente como vieram da origem
- Silver → dados limpos, padronizados e enriquecidos
- Gold → dados analíticos, prontos para consumo
Essa estrutura permite:
- rastreabilidade
- governança
- versionamento
- reprocessamento eficiente
E prepara o terreno para o próximo passo: a transformação.
4. O Motor de Transformação: Azure Databricks
O Databricks entra como o componente responsável por transformar dados em informação.
Por que Databricks?
- Processamento distribuído
- Suporte nativo ao Delta Lake
- Integração com Unity Catalog
- Notebooks colaborativos
- Escalabilidade sob demanda
Duas abordagens de autenticação
Durante o projeto, foram demonstradas duas formas de conectar o Databricks ao ADLS:
- OAuth com Client Secret (uso pedagógico)
- Configurado via Secret Scope
- Demonstração prática de autenticação manual
- Útil para entender o fluxo de credenciais
- Access Connector + Storage Credential + External Location (abordagem moderna)
- Baseada em Managed Identity
- Sem segredos expostos
- Ideal para produção
- Governança centralizada via Unity Catalog
Essa combinação mostra como o domínio de diferentes métodos de autenticação é essencial para arquiteturas robustas.
5. A Orquestração: Fabric Data Factory
Nenhum pipeline moderno funciona sem automação.
O Fabric Data Factory assume esse papel:
- extrai dados do Azure SQL
- carrega no ADLS (Bronze)
- aciona notebooks do Databricks
- valida e publica a camada Gold
O Data Factory garante que tudo aconteça:
- na ordem correta
- com monitoramento
- com logs
- com repetibilidade
É a cola que une todas as etapas.
6. A Entrega: Fabric Lakehouse e Power BI
Após o processamento, a camada Gold é disponibilizada no Fabric Lakehouse via Shortcuts, que apontam diretamente para o ADLS.
Isso permite:
- consumo imediato
- sem duplicação de dados
- sem ETL adicional
- com desempenho otimizado via DirectLake
O Power BI, integrado ao Fabric, acessa essas tabelas com latência mínima, oferecendo dashboards e relatórios que refletem o estado mais atualizado dos dados.
7. O Resultado: Dados Brutos Transformados em Valor
Ao final, o pipeline entrega:
- dados confiáveis
- modelos analíticos consistentes
- governança centralizada
- automação ponta a ponta
- insights acessíveis a qualquer área de negócio
E tudo isso só é possível porque cada sistema faz o que sabe fazer melhor, e todos trabalham juntos em harmonia.
8. A Conclusão: O Profissional de Dados Precisa Ser um Integrador
Este projeto evidencia uma verdade fundamental:
Não basta dominar uma ferramenta.
O profissional de dados moderno precisa entender como sistemas diferentes se conectam, se autenticam, se complementam e se potencializam.
A integração entre SQL Database, ADLS, Databricks, Fabric e Power BI demonstra que:
- cada tecnologia tem seu papel
- cada camada agrega valor
- cada decisão de arquitetura impacta o resultado final
E quando tudo funciona em conjunto, os dados deixam de ser apenas registros e se tornam informação estratégica, capaz de impulsionar decisões, otimizar processos e gerar vantagem competitiva.
visite: https://github.com/EliasPira/PipelineFimAFim-Com-AzureDatabricks-Fabric.git





