

Amazon DynamoDB na Prática: Escalabilidade NoSQL para Aplicações Modernas Introdução
Amazon DynamoDB na Prática: Escalabilidade NoSQL para Aplicações Modernas
Introdução
No cenário atual de desenvolvimento, onde a latência de milissegundos e a alta disponibilidade são cruciais, o Amazon DynamoDB surge como uma das soluções mais robustas da AWS. Diferente dos bancos relacionais (RDS) que exploramos anteriormente, o DynamoDB é um banco de dados NoSQL de chave-valor e documentos, totalmente gerenciado e projetado para rodar em qualquer escala.
Por que escolher o DynamoDB?
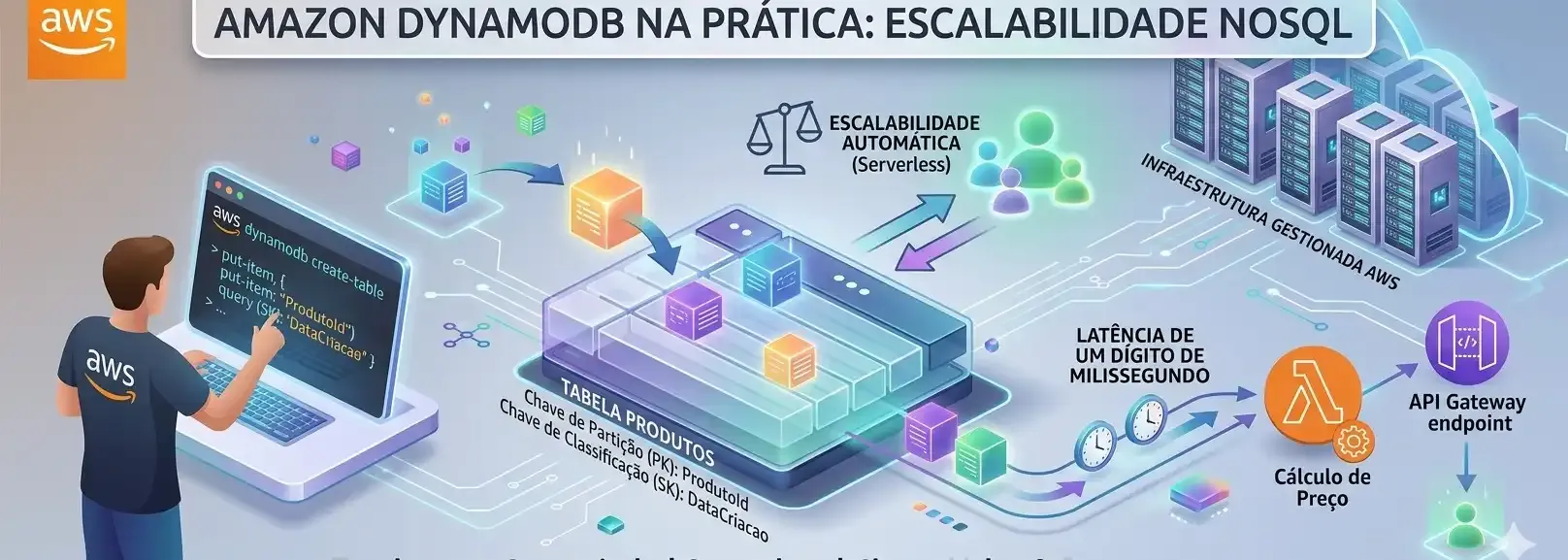
O grande trunfo do DynamoDB é ser Serverless. Isso significa que você não precisa se preocupar com provisionamento de servidores, patches de sistema operacional ou gerenciamento de clusters.
Principais Diferenciais:
- Performance Consistente: Latência de um dígito de milissegundo, independentemente do volume de dados.
- Escalabilidade Automática: O serviço ajusta a capacidade de leitura e escrita conforme a demanda da aplicação.
- Integração Nativa: Conecta-se perfeitamente com AWS Lambda, facilitando arquiteturas orientadas a eventos.
Estrutura de Dados: Chaves que Importam
Diferente das tabelas SQL fixas, no DynamoDB o esquema é flexível, mas a definição das chaves de acesso é vital:
- Partition Key (PK): Determina em qual partição física os dados serão armazenados. Essencial para buscas diretas.
- Sort Key (SK): Permite organizar itens dentro da mesma partição, facilitando buscas por intervalos (Ex: datas, IDs sequenciais).
Juntas, elas formam a Composite Primary Key, permitindo modelagens complexas e eficientes.
Na Prática: Criando sua Primeira Tabela
Para colocar a mão na massa via AWS CLI, o comando básico para criar uma tabela de alta performance seria:
Bash
aws dynamodb create-table \
--table-name TabelaProdutos \
--attribute-definitions \
AttributeName=ProdutoId,AttributeType=S \
--key-schema \
AttributeName=ProdutoId,KeyType=HASH \
--provisioned-throughput \
ReadCapacityUnits=5,WriteCapacityUnits=5
Operações de Leitura: Query vs. Scan
Um erro comum de iniciantes é usar o Scan. Entenda a diferença:
- Query: Busca eficiente baseada na Partition Key. Consome menos recursos e é mais rápida.
- Scan: Varre a tabela inteira. Deve ser evitado em tabelas grandes, pois é caro e lento.
Dica de "Elite" para o Arquiteto
Ao desenhar suas tabelas, pense sempre no padrão de acesso primeiro. No DynamoDB, não modelamos os dados baseados na realidade (como no modelo relacional), mas sim baseados nas perguntas que a sua aplicação precisa responder rapidamente.
Casos de Uso Comuns:
- Carrinhos de compras em e-commerce.
- Histórico de transações financeiras em tempo real.
- Armazenamento de estados para jogos online.
Conclusão
O Amazon DynamoDB é uma ferramenta indispensável para quem busca criar aplicações globais e resilientes. Dominar suas chaves e entender o comportamento das partições é o que separa um desenvolvedor comum de um especialista em Cloud Architecture.





