


Desvendando o Big Data: Ferramentas e Estratégias para Lidar com a Era dos Dados
- #Data
Vivemos em uma era onde dados são gerados a todo instante. Seja por meio de redes sociais, sensores inteligentes, transações online ou dispositivos móveis, a quantidade de informações produzidas diariamente é imensurável. É nesse cenário que o fenômeno do Big Data se torna cada vez mais relevante — e desafiador.
Meu nome é Raphael, sou formado em Gestão de Empresas e também em Análise e Desenvolvimento de Sistemas. No último ano da graduação, tive contato com a disciplina eletiva de Análise de Dados, o que despertou meu interesse por essa área estratégica e em constante expansão. Por isso, iniciei uma pós-graduação em Ciência de Dados e Big Data Analytics, curso no qual venho explorando diversas ferramentas e metodologias essenciais para lidar com o universo dos dados em larga escala, como Hadoop, Spark e streaming de dados.
Neste artigo, trago uma abordagem completa sobre o que é o Big Data, como lidar com grandes volumes de dados e as principais tecnologias utilizadas para extração de valor nesse contexto.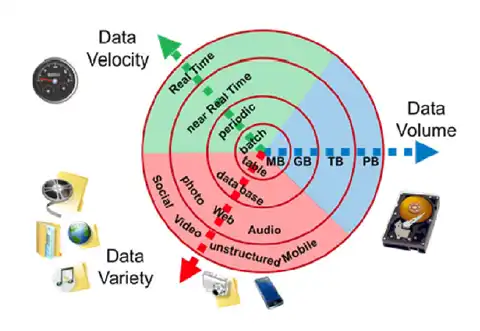
Figura 1 - Visão geral dos principais aspectos do Big Data: Velocidade, Volume e Variedade.
O que é Big Data?
O termo Big Data refere-se a conjuntos de dados extremamente grandes e complexos, que não podem ser processados por métodos tradicionais de gerenciamento e análise. O conceito é comumente associado aos 5 V’s:
- Volume: Refere-se à enorme quantidade de dados gerados a cada segundo.
- Velocidade: A rapidez com que os dados são gerados e processados.
- Variedade: Diferentes formatos de dados (estruturados, semiestruturados e não estruturados).
- Veracidade: A confiabilidade e qualidade dos dados.
- Valor: A utilidade dos dados para tomada de decisão e geração de insights.
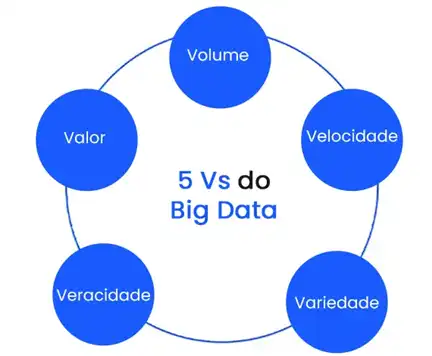
Figura 2 - Os 5 Vs do Big Data: Volume, Velocidade, Variedade, Veracidade e Valor.
Como destaca Marr (2016), “Big Data é muito mais do que um grande volume de dados. Ele trata da capacidade de transformar esses dados em valor para as organizações”.
O fenômeno da explosão de dados
Segundo a IDC (2021), o volume global de dados criados, capturados e replicados será superior a 180 zettabytes até 2025. Essa explosão vem sendo impulsionada por tecnologias como IoT (Internet das Coisas), cloud computing, redes sociais e dispositivos móveis.
O desafio atual não é apenas armazenar esses dados, mas transformá-los em informações úteis, interpretáveis e acionáveis. E para isso, entra o papel crucial das ferramentas e arquiteturas voltadas para Big Data.
Ferramentas para Big Data: Hadoop e Spark
Durante minha pós-graduação, tive a oportunidade de explorar profundamente duas das principais tecnologias usadas em projetos de Big Data: Hadoop e Apache Spark.
Hadoop
O Hadoop é um framework de código aberto que permite o armazenamento distribuído e o processamento paralelo de grandes conjuntos de dados em clusters de computadores. Ele se baseia em dois componentes principais:
- HDFS (Hadoop Distributed File System): sistema de arquivos distribuído que armazena dados de forma redundante em diferentes máquinas.
- MapReduce: modelo de programação que processa grandes volumes de dados em paralelo.
Segundo White (2012), “o Hadoop democratizou o acesso ao processamento de dados em larga escala, ao permitir que empresas utilizassem hardware comum para executar tarefas computacionalmente intensivas”.
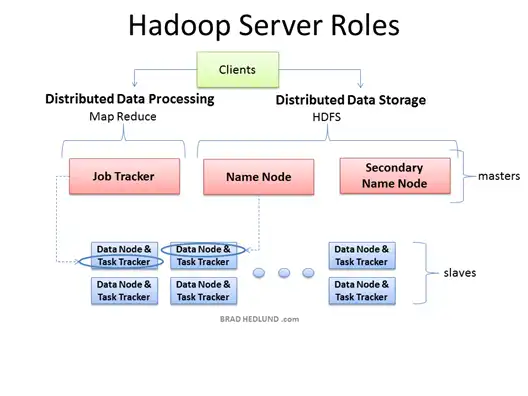
Figura 3 - Arquitetura do Hadoop: divisão entre armazenamento (HDFS) e processamento (MapReduce).
Apache Spark
Já o Apache Spark é uma plataforma de processamento mais moderna, conhecida pela sua velocidade e flexibilidade. Ele trabalha com processamento em memória, o que o torna até 100 vezes mais rápido do que o Hadoop MapReduce em determinadas situações (Zaharia et al., 2016).
Principais vantagens do Spark:
- Suporte a várias linguagens (Python, Java, Scala).
- APIs otimizadas para machine learning e análises em tempo real.
- Melhor desempenho em cargas de trabalho iterativas.
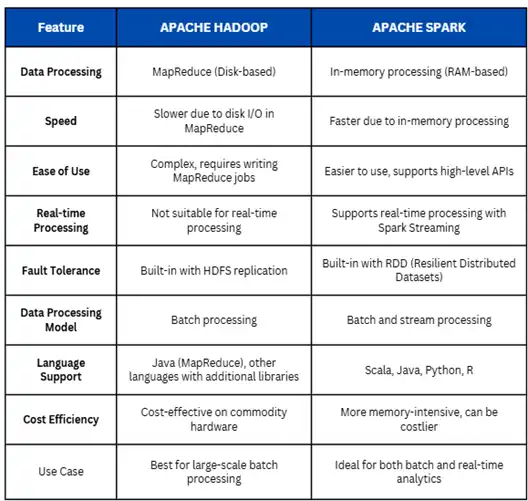
Figura 4 - Comparação entre Hadoop e Spark em diferentes dimensões.
Streaming de dados: análise em tempo real
Com o aumento da geração de dados em tempo real — como sensores de dispositivos IoT, logs de aplicações e cliques em sites — surgiu a necessidade de análise instantânea. Essa abordagem é conhecida como streaming de dados.
Diferente do modelo tradicional batch (lote), o streaming processa os dados assim que eles são gerados. Isso é essencial para:
- Monitoramento de fraudes em tempo real.
- Análise de sentimento nas redes sociais.
- Detecção de anomalias em sistemas críticos.
O Apache Spark, com o módulo Spark Streaming, oferece suporte completo para esse tipo de análise. Outro destaque é o Apache Kafka, usado para transmissão confiável de mensagens em pipelines de dados.
Desafios no tratamento de grandes volumes de dados
Apesar do avanço das ferramentas, lidar com Big Data exige enfrentar diversos desafios técnicos e estratégicos:
- Escalabilidade: adaptar a infraestrutura conforme o volume de dados cresce.
- Governança: garantir a segurança, privacidade e conformidade legal dos dados.
- Qualidade: tratar dados incompletos, duplicados ou inconsistentes.
- Integração: unir dados de fontes heterogêneas em uma visão unificada.
- Custo: manter clusters, ferramentas e armazenamento em nuvem pode ser caro.
Boas práticas para projetos com Big Data
Para conduzir projetos bem-sucedidos com grandes volumes de dados, algumas práticas são recomendadas:
- Definir objetivos claros de negócio antes de coletar dados.
- Implementar pipelines automatizados de ingestão, transformação e análise.
- Utilizar dashboards e ferramentas de visualização para facilitar insights.
- Investir na capacitação da equipe em ferramentas como Hadoop, Spark e SQL.
- Garantir que os dados sejam limpos, consistentes e atualizados.
Aplicações práticas do Big Data
O uso do Big Data está presente em praticamente todos os setores:
Setor - Aplicação Principal
Saúde - Diagnóstico preditivo, gestão hospitalar
Varejo - Personalização de ofertas, previsão de demanda
Finanças - Detecção de fraudes, análise de risco
Logística - Roteirização e otimização de entregas
Educação - Análise de desempenho estudantil
Marketing Digital - Segmentação de público e campanhas personalizadas
Conclusão
Lidar com grandes volumes de dados é um desafio crescente — e uma oportunidade valiosa para empresas e profissionais. Ao compreender o fenômeno do Big Data, dominar ferramentas como Hadoop e Spark, e aplicar estratégias de análise em tempo real com streaming de dados, é possível transformar o caos informacional em decisões inteligentes.
A formação contínua nessa área é fundamental. No meu caso, a pós-graduação tem sido um divisor de águas, permitindo compreender melhor o impacto da ciência de dados na transformação digital das organizações.
Como reforça Thomas Davenport (2014):
“As empresas que investem em Big Data e análises são cinco vezes mais propensas a tomar decisões mais rápidas do que seus concorrentes”.
Referências
- Marr, B. (2016). Big Data in Practice. Wiley.
- White, T. (2012). Hadoop: The Definitive Guide. O'Reilly.
- Zaharia, M. et al. (2016). Apache Spark: The Definitive Guide. O'Reilly.
- IDC (2021). DataSphere Forecast. International Data Corporation.
- Davenport, T. (2014). Big Data at Work. Harvard Business Review Press.





Muito obrigado pelas palavras! Ainda sou estudante na pós em Ciência de Dados e Big Data Analytics, mas tenho buscado aprofundar meus conhecimentos.
Se fosse montar um roteiro para quem está começando, eu seguiria algo assim, baseado no que venho estudando:
Introdução ao Big Data
– Conceitos fundamentais, os 5Vs e tipos de dados
– Relação com a ciência de dados
Ecossistema e Ferramentas
– Linguagens como Python, R e SQL
– Tecnologias como Hadoop e Spark
Processamento de Dados
– Processamento em lote e em tempo real
– Streaming (Kafka, Spark Streaming)
Análise e Aplicações
– Text Mining e BI
– Aplicações em saúde, logística e marketing
– Descoberta de conhecimento com Big Data
Excelente artigo, Raphael. Você construiu uma visão ampla e técnica sobre Big Data, articulando conceitos fundamentais com experiências acadêmicas e aplicações práticas. A forma como você apresenta os 5 Vs e os relaciona com os desafios do mundo real demonstra domínio do assunto e uma preocupação genuína em transmitir clareza, mesmo ao abordar temas complexos como arquitetura distribuída, processamento em lote e em tempo real.
Gostei especialmente do destaque para o papel das ferramentas Hadoop e Spark, explicando suas diferenças e casos de uso com muita propriedade. A menção ao streaming e à aplicação em áreas como saúde, logística e marketing reforça o quanto o Big Data transcende o universo técnico e impacta diretamente o mundo dos negócios.
Se você fosse montar um roteiro de aprendizado para quem quer começar a atuar com Big Data, que ordem de ferramentas, linguagens e conceitos você recomendaria para os primeiros meses de estudo?