


Construir com LLM local funciona — mas não do jeito mágico que muita gente imagina

Um relato de experiência sobre o uso de um modelo local como principal agente de desenvolvimento
Introdução: por que fiz o experimento
Construir com LLM local funciona, mas não do jeito mágico que muita gente imagina.
Essa foi a principal conclusão de um experimento prático em que desenvolvi um bot para Telegram usando um LLM local como principal agente de código.
O ponto central do experimento não era apenas “usar IA no projeto”. A proposta era mais específica: usar um LLM local como principal executor de código, com mínima intervenção manual direta na implementação, e avaliar sua confiabilidade ao longo de múltiplas fases de desenvolvimento.
Meu papel foi mais próximo de direção, revisão, debugging, definição de regras e validação. O papel do modelo era escrever o código, alterar arquivos, atualizar testes e responder às restrições do repositório.
Essa distinção é importante porque muda completamente a análise. Uma coisa é usar IA como apoio pontual para escrever uma função, explicar um erro ou sugerir uma refatoração. Outra é colocar um modelo local como agente principal dentro de um repositório real, com decisões acumuladas, documentação, testes, fases e critérios de conclusão.
A pergunta que eu queria responder não era simplesmente se uma IA consegue programar. Isso já está relativamente claro: consegue.
A pergunta mais interessante era outra:
um LLM local consegue sustentar um fluxo de desenvolvimento confiável ao longo do tempo?
O resultado foi positivo em termos de capacidade, mas bem mais limitado em termos de produtividade. O projeto funcionou, mas o processo exigiu muito mais estrutura, supervisão e validação do que a narrativa mais otimista sobre agentes de IA costuma sugerir.
O que foi construído
O produto desenvolvido foi um bot para Telegram. O escopo técnico era propositalmente limitado, mas real o bastante para expor problemas relevantes de engenharia.
O bot deveria oferecer comandos básicos como /start, /help e /ping, persistir mensagens localmente usando SQLite, rodar em Docker e integrar com um endpoint LLM local por meio do comando /ask.
Não era um sistema grande. Não havia múltiplos serviços, autenticação complexa, filas distribuídas, observabilidade avançada ou regras de negócio profundas. Ainda assim, o projeto envolvia elementos suficientes para testar um fluxo minimamente real: configuração de ambiente, organização de código, handlers de comandos, persistência, testes, documentação e integração com um modelo local.
Essa escolha de escopo foi importante. Se o projeto fosse grande demais, seria difícil separar os problemas do modelo dos problemas naturais de complexidade do sistema. Ao manter o produto pequeno, ficou mais fácil observar como o LLM local lidava com continuidade, contexto, regras e validação.
No final, o bot funcionou. Ele roda em Docker, persiste mensagens em SQLite e conversa com um LLM local.
Mas o ponto mais importante é este: funcionar em um projeto pequeno e controlado não significa escalar bem para um fluxo diário de desenvolvimento.
Esse experimento foi uma prova de capacidade, não uma prova automática de produtividade.
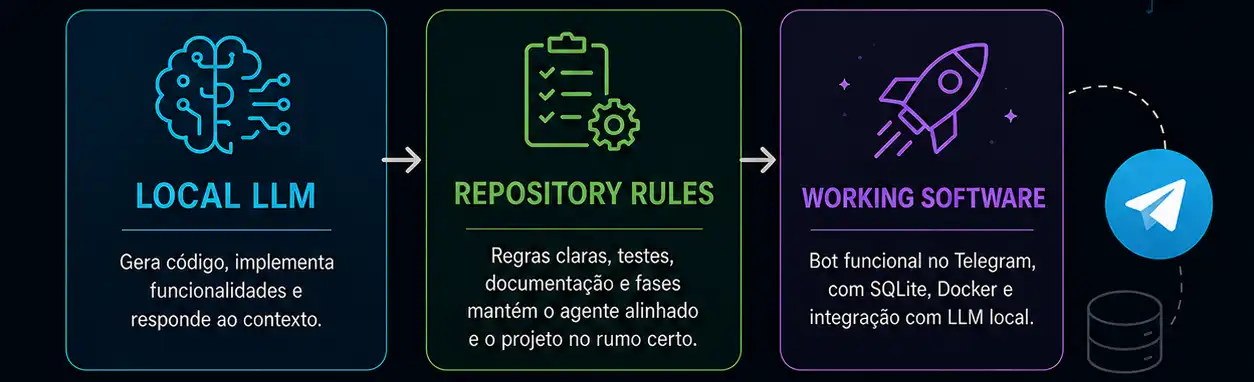
A regra principal do experimento
A regra principal era clara: o código seria escrito pelo LLM local.
Essa restrição era essencial para que o experimento fizesse sentido. Eu não queria apenas usar a IA como autocomplete, gerador de sugestões ou ferramenta auxiliar para explicar erros. Também não queria assumir manualmente as partes difíceis sempre que o modelo se perdesse.
Meu papel ficou concentrado em orientar o projeto, revisar resultados, identificar bugs e regressões, ajustar regras, conduzir debugging e validar entregas. O modelo, por outro lado, deveria ser responsável por implementar funcionalidades, modificar arquivos, atualizar testes e avançar o projeto fase por fase.
Essa separação tornou o processo mais lento em alguns momentos, mas também mais honesto. Se eu corrigisse manualmente o código sempre que surgisse um problema, o resultado diria mais sobre a minha capacidade de intervir do que sobre a capacidade do LLM local como agente de desenvolvimento.
O objetivo era observar até onde o modelo conseguiria ir quando colocado como principal executor da implementação, dentro de limites bem definidos.
Essa diferença importa porque muito do debate sobre IA em programação ainda mistura coisas diferentes: usar IA para acelerar uma tarefa pontual não é o mesmo que depender de um agente para sustentar a evolução de um projeto.
O que começou a dar errado
O modelo conseguia produzir código funcional. Esse não foi o maior problema.
Ele conseguia criar arquivos, ajustar handlers, escrever testes, corrigir erros e avançar no escopo técnico. O problema apareceu principalmente na continuidade.
Com o tempo, alguns padrões começaram a se repetir. O modelo esquecia decisões anteriores, reintroduzia bugs que já tinham sido corrigidos e, em alguns casos, fazia testes passarem sem proteger exatamente o comportamento esperado.
Um exemplo recorrente foi a tendência de confundir “teste verde” com “comportamento correto”. Em alguns momentos, o modelo ajustava a implementação para satisfazer o teste existente, mas o teste não estava protegendo o contrato real da funcionalidade. O resultado parecia progresso, porque a suíte passava, mas a garantia de comportamento ainda era fraca.
Outro exemplo foi a documentação. Em algumas fases, o modelo alterava o código, mas deixava arquivos como README, STATUS ou documentação de contexto desalinhados com o estado real do projeto. Para um humano, documentação desatualizada já é um problema. Para um agente de IA, ela pode ser ainda pior, porque o modelo usa o próprio repositório como parte da base de entendimento. Se o repositório conta uma história errada, o agente tende a trabalhar a partir dessa história.
Também houve situações em que o modelo declarava uma fase como concluída cedo demais. Ele via uma parte do escopo funcionando ou testes passando e assumia que o trabalho estava encerrado, mesmo quando ainda faltavam verificações, documentação ou validação mais cuidadosa.
Esse padrão deixou claro que o desafio não era apenas fazer o modelo escrever código. Era fazer o modelo respeitar um processo.
Um projeto real não é uma sequência solta de tarefas técnicas. Ele depende de memória, coerência, critérios de aceite, revisão e alinhamento entre código, testes e documentação. Sem isso, a IA até avança, mas avança com drift.
Por que “dar prompts melhores” não foi suficiente
Quando um modelo erra, é comum imaginar que o problema está no prompt. E, em parte, isso é verdade. Instruções melhores ajudam, contexto mais claro ajuda e prompts bem escritos reduzem ambiguidades.
Mas esse experimento deixou claro que o problema era maior do que a formulação de uma mensagem.
O LLM local não precisava apenas de uma instrução melhor dentro da conversa. Ele precisava de um ambiente mais disciplinado ao redor dele.
Foi nesse ponto que arquivos como AGENTS.md, STATUS.md e CURRENT_TASK.md passaram a ter um papel central.
O AGENTS.md funcionou como um contrato de comportamento do agente. Ele concentrava regras estáveis sobre como o modelo deveria trabalhar: usar Docker como base, seguir um fluxo orientado a testes, respeitar limites de responsabilidade entre arquivos, manter documentação sincronizada e não considerar uma fase concluída sem verificações explícitas.
O STATUS.md registrava o estado do projeto, incluindo fases, pendências, bloqueios, decisões tomadas e verificações realizadas. Em vez de depender apenas da memória da conversa, o repositório passou a ter um local persistente para representar o momento atual do projeto.
O CURRENT_TASK.md ajudava com o contexto curto de cada sessão. Em interações longas ou depois de mudanças de foco, o modelo podia perder parte do contexto. Esse arquivo reduzia a chance de o agente trabalhar a partir de uma leitura incompleta ou desatualizada.
Na prática, o repositório começou a funcionar como parte do prompt.
Essa foi uma das maiores lições do experimento. Quando se trabalha com agentes de IA, especialmente locais, a estrutura do projeto também comunica intenção. O modelo não depende apenas do que está escrito na conversa; ele depende de como o projeto organiza regras, responsabilidades, testes, documentação e critérios de conclusão.
Isso muda a forma de pensar documentação. Ela deixa de ser apenas uma explicação para humanos e passa a ser também uma ferramenta operacional para orientar o agente.
O mesmo vale para testes. Em um projeto tradicional, testes ajudam a evitar regressões. Neste experimento, eles também funcionaram como memória do projeto. Quando o modelo esquecia uma decisão anterior, um bom teste podia proteger o comportamento esperado.
Ainda assim, testes fracos geravam uma falsa sensação de segurança. O teste precisa proteger o comportamento que realmente importa. Caso contrário, o agente pode simplesmente “vencer” o teste errado.

O custo muda de lugar
Esse experimento também me fez olhar com mais cuidado para uma discussão cada vez mais comum: LLMs locais vão substituir programadores?
Minha conclusão hoje é conservadora.
Se modelos como GPT, Claude e outros ficarem mais caros para uso intensivo, é natural que empresas e profissionais olhem para LLMs locais como alternativa. A proposta é atraente: rodar o modelo localmente, reduzir dependência de APIs externas, ter mais controle sobre dados e privacidade, evitar parte dos custos recorrentes de uso em nuvem e customizar melhor o ambiente.
Mas a prática mostra que a conta não é tão simples.
Para rodar um modelo local bem o suficiente para desenvolvimento real, você precisa de uma máquina forte. Dependendo do modelo, da quantização, do tamanho do contexto e da velocidade desejada, o hardware passa a ser uma parte relevante da equação.
Além disso, modelos locais exigem mais cuidado operacional. É preciso configurar ambiente, gerenciar modelos, lidar com consumo de memória, ajustar ferramentas, aceitar respostas menos consistentes em alguns cenários, trabalhar com contexto menor, supervisionar mais, validar mais e corrigir mais.
Ou seja, o custo não desaparece. Ele muda de lugar.
Sai parte da conta da API e entra custo de hardware, configuração, manutenção, supervisão e retrabalho.
Isso não torna LLMs locais ruins. Pelo contrário. Eles já fazem sentido em vários cenários: exploração técnica, aprendizado, automação local, prototipação, privacidade, estudo de agentes e ambientes em que controle dos dados é prioridade.
O ponto é outro: eles ainda não são uma substituição simples, barata e produtiva para desenvolvimento diário em qualquer contexto.
A promessa existe, e o potencial também. Mas existe uma camada grande de engenharia ao redor, e essa camada costuma ser ignorada quando a conversa fica presa apenas na ideia de “rodar IA localmente”.
LLMs locais vão substituir programadores?
Depois desse experimento, acho exagerado dizer que programadores vão entrar em extinção em breve. A IA consegue programar, e isso já é real. Mas desenvolvimento de software não é apenas escrever código.
Desenvolver software envolve entender problemas, interpretar contexto, tomar decisões arquiteturais, criar bons testes, validar comportamento, perceber trade-offs, manter coerência ao longo do tempo e identificar quando uma solução aparentemente correta está errada.
No experimento, o modelo escrevia código. Mas quem precisava perceber drift, identificar regressões, revisar decisões, ajustar regras e validar se uma fase estava realmente concluída ainda era o humano.
Isso não significa que nada muda. Muda bastante. O papel do programador tende a mudar cada vez mais, mas mudar não é o mesmo que desaparecer.
O que parece mais provável é que programadores capazes de estruturar problemas, criar bons testes, revisar saídas, validar entregas e orientar agentes de IA fiquem ainda mais importantes.
O gargalo deixa de ser apenas digitar código. O gargalo passa a ser transformar intenção em software confiável. E isso exige julgamento técnico.
Exige saber decompor problemas, criar limites, validar hipóteses, revisar decisões e construir ambientes em que o agente tenha menos espaço para se perder.
Talvez a habilidade mais importante deixe de ser apenas “escrever tudo do zero” e passe a incluir algo mais amplo: criar sistemas de trabalho onde humanos e agentes consigam produzir software confiável juntos.
Essa é uma mudança grande, mas não é extinção. É uma mudança de responsabilidade.
Limitações do experimento
Este relato não pretende generalizar o resultado para todos os modelos, todos os times ou todas as stacks. O experimento teve limitações claras.
O projeto era pequeno e controlado. Isso facilitou a observação do comportamento do modelo, mas também significa que os resultados não devem ser extrapolados automaticamente para sistemas maiores, com múltiplos times, dependências externas complexas ou pressão real de produção.
O fluxo principal era relativamente simples. O bot tinha persistência local, comandos e integração com um endpoint LLM, mas não envolvia problemas mais pesados de escala, segurança, governança, performance ou manutenção de longo prazo.
Também usei um setup local específico. Outros modelos, outras quantizações, outras ferramentas de orquestração e outras máquinas poderiam produzir resultados diferentes. Um modelo maior, uma janela de contexto mais ampla ou ferramentas melhores poderiam reduzir parte dos problemas observados.
Além disso, o experimento teve um operador humano envolvido, revisando, direcionando e ajustando regras. Isso significa que o resultado não deve ser lido como autonomia total do agente, mas como um fluxo em que o LLM local assumiu a escrita do código sob supervisão.
Essas limitações não invalidam o aprendizado. Pelo contrário, ajudam a colocar a conclusão no lugar certo: o experimento mostra que LLMs locais podem funcionar como agentes de código em projetos controlados, mas ainda exigem estrutura forte para se tornarem confiáveis.

O que eu aprendi
O primeiro aprendizado é que um LLM local pode produzir software funcional. O bot foi concluído, rodou em Docker, persistiu mensagens e integrou com um endpoint LLM local. Isso mostra que a capacidade técnica existe.
O segundo aprendizado é que funcionar não significa ser produtivo. O projeto chegou ao resultado esperado, mas o caminho exigiu muita supervisão, correção, verificação e cuidado com contexto. Para um projeto pequeno, o custo operacional foi alto.
O terceiro aprendizado é que o repositório também é parte do prompt. Arquivos como AGENTS.md, STATUS.md e CURRENT_TASK.md não foram apenas documentação auxiliar. Eles ajudaram a orientar o agente, reduzir ambiguidades e preservar decisões importantes.
O quarto aprendizado é que testes são memória. Quando o modelo perde contexto, testes bem escritos ajudam a preservar comportamentos importantes. Mas isso só funciona se os testes protegerem o contrato certo.
O quinto aprendizado é que documentação desatualizada vira risco técnico. Para humanos, documentação ruim já atrapalha. Para agentes de IA, ela pode induzir decisões erradas. Se o modelo usa o repositório para se orientar, a documentação precisa acompanhar o estado real do projeto.
O sexto aprendizado é que fases precisam de critérios claros de fechamento. Sem critérios explícitos, o modelo tende a assumir que terminou cedo demais. Ele pode confundir “algo funciona” com “a fase está realmente concluída”.
O sétimo aprendizado é que LLMs locais são muito sensíveis a contexto. Contexto perdido, misturado ou desatualizado muda drasticamente a qualidade da entrega. Isso exige cuidado com organização, arquivos de apoio e instruções persistentes.
O oitavo aprendizado é que estrutura reduz ambiguidade mais do que prompts longos. Um prompt enorme não resolve um projeto desorganizado. O agente precisa encontrar no repositório sinais claros do que deve fazer, do que não deve fazer e de como será validado.
O último aprendizado talvez seja o mais importante: IA local pode programar, mas ainda não é produtiva do jeito que muita gente imagina.

Conclusão
O experimento funcionou, mas não confirmou a narrativa mais otimista de que um LLM local simplesmente substitui o trabalho de um programador.
A conclusão foi mais interessante e mais realista: um LLM local pode atuar como agente de código em um projeto real, mas precisa de guardrails fortes.
Ele precisa de regras claras, bons testes, documentação sincronizada, contexto bem cuidado, validação constante e um humano revisando, ajustando e decidindo o rumo. Sem essa estrutura, o modelo até consegue avançar, mas tende a perder contexto, reintroduzir problemas e assumir conclusões cedo demais.
No fim, usar IA para desenvolver software não é só escolher um modelo melhor. É também desenhar um ambiente onde o agente consiga entender o projeto, respeitar suas regras e sobreviver às próprias limitações.
O bot foi o entregável técnico, mas a verdadeira entrega foi entender quanta estrutura um LLM local precisa para se tornar minimamente confiável como agente de desenvolvimento.
A IA local pode programar. Mas ainda não é produtiva do jeito que muita gente imagina.
Ou, colocando de forma mais direta:
o problema não é só fazer a IA escrever código. O problema é construir um ambiente em que ela consiga continuar certa ao longo do tempo.
Deixei o repositório público para quem quiser ver a estrutura completa do projeto, incluindo o project-story.md, onde conto a história do experimento em mais detalhes:
https://github.com/LukasDeadMan/telegram-bot-local-llm-experiment





