


Explorando o Poder do NLP em Python: Como as IAs Entendem Texto
- #Python
- #Processamento de Linguagem Natural (PLN)
- #Inteligência Artificial (IA)
O que você vai encontrar nesse artigo:
- 🚀 Introdução: Como as IAs estão aprendendo a entender a linguagem
- 🧠 O que é NLP e por que ele importa?
- 🔧 Como preparar os textos para uma IA: O Pré-processamento
- 🧩 Tarefas que uma IA faz com NLP
- 🧬 Como representar texto para a IA?
- 🔍 Como treinar modelos de NLP: dados, exemplos e atalhos
- 📊 Fontes de dados para treinar modelos
- 🧠 Modelos pré-treinados para não começar do zero
- 💡 Boas práticas para trabalhar com NLP em português
- 🧪Avaliação de modelos de NLP
- 🧱 Desafios comuns em NLP
- 🔮 O futuro do NLP: para onde vamos?
- 🏁 Conclusão: O primeiro passo é entender
1.🚀 Introdução: Como as IAs estão aprendendo a entender a linguagem
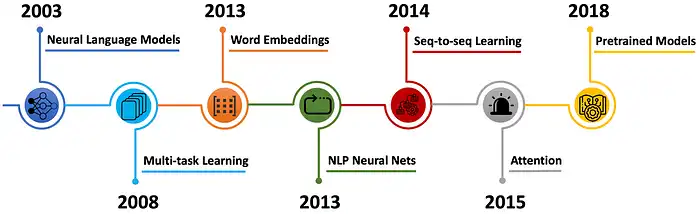
Hoje em dia, é difícil encontrar alguém que nunca tenha conversado com uma inteligência artificial, seja num chatbot, assistente virtual ou até mesmo ao usar ferramentas como ChatGPT. Mas já parou para pensar como essas IAs entendem o que escrevemos?
Neste artigo, vamos explorar o NLP (Natural Language Processing) e como você pode trabalhar com isso usando Python, mesmo que esteja começando agora.
Entender os fundamentos do NLP é essencial porque boa parte do que uma IA “compreende” começa na forma como tratamos e representamos a linguagem. Saber como a máquina interpreta palavras, frases e contextos te dá muito mais controle sobre os resultados.
Seja para criar, ajustar ou apenas usar ferramentas com NLP, dominar essas bases te ajuda a resolver problemas de forma mais eficaz. Então vamos desmistificar o assunto com exemplos simples, explicações e dicas práticas. Vem comigo?
2. 🧠 O que é NLP e por que ele importa?

NLP é uma área da inteligência artificial que ensina máquinas a entender, interpretar e gerar linguagem humana. Ele é usado em:
- Assistentes virtuais (Siri, Alexa, Google Assistant)
- Chatbots de atendimento
- Análise de sentimentos em redes sociais
- Traduções automáticas
- Recomendação de conteúdo
3. 🔧 Como preparar os textos para uma IA: O Pré-processamento
Lembrando que, assim como em outras aplicações de IA, o pré-processamento de texto também exige atenção com balanceamento de dados e remoção de campos nulos. A qualidade dos dados afeta diretamente o desempenho do modelo.
Antes de uma IA conseguir entender um texto, é necessário “organizar a bagunça”. A linguagem humana é cheia de ambiguidade, erros, gírias, variações e ruídos que podem confundir a máquina.
🧨 Principais tarefas de pré-processamento:
- Tokenização: quebra o texto em palavras ou frases menores (tokens).
- Stop words: remove palavras muito comuns (como “de”, “o”, “é”) que não agregam significado.
- Stemming e Lemmatization: reduzem palavras à sua forma base (“correndo” → “correr”).
- Lowercasing: tudo em letras minúsculas.
- Remoção de pontuação e números: remover pontuações e números, que muitas vezes não contribuem para o entendimento do texto, exceto quando esses elementos são relevantes para a tarefa.
Em redes sociais, o texto pode vir com hashtags, emojis e abreviações (“vc”, “blz”, “sdds”). Já no campo jurídico, estruturas longas e termos em latim são comuns. Por isso, entender o domínio do seu dado pode ajudar a definir as melhores etapas de limpeza e tratamento do texto.
Com isso, deixamos o texto mais limpo, uniforme e objetivo. Isso facilita (e muito) o trabalho da IA na hora de identificar padrões, entender o conteúdo e gerar respostas ou classificações.
E para entender um pouco na prática, seguimos para um exemplo prático. Lembrando que se for tentar executar requer:
pip install nltk
📝Exemplo em Python com NLTK:
import nltk
from nltk.corpus import stopwords
from nltk import tokenize
from nltk.stem import PorterStemmer
import string
nltk.download('punkt_tab')
nltk.download('stopwords')
texto = "NLP é uma área incrível da inteligência artificial que está mudando o mundo."
# Tokenização
tokens = tokenize.word_tokenize(texto.lower())
# token: ['nlp', 'é', 'uma', 'área', 'incrível', 'da', 'inteligência', 'artificial', 'que', 'está', 'mudando', 'o', 'mundo', '.']
# Remover pontuação
tokens = [t for t in tokens if t not in string.punctuation]
# tokens: ['nlp', 'é', 'uma', 'área', 'incrível', 'da', 'inteligência', 'artificial', 'que', 'está', 'mudando', 'o', 'mundo']
# Remover stopwords
stop_words = set(stopwords.words('portuguese'))
filtered = [t for t in tokens if t not in stop_words]
print(filtered)
# filtered: ['nlp', 'área', 'incrível', 'inteligência', 'artificial', 'mudando', 'mundo']
# Stemming
stemmer = PorterStemmer()
stemmed = [stemmer.stem(t) for t in filtered]
print(stemmed)
# output: ['nlp', 'área', 'incrível', 'inteligência', 'artifici', 'mudando', 'mundo']
4. 🧩 Tarefas que uma IA faz com NLP

Depois que o texto está limpo, a IA pode realizar diversas tarefas para entender melhor o conteúdo. A imagem mostra um exemplo de cada tarefa que trago aqui no texto, além disso vamos imaginar um contexto para entender cada tarefa. Vamos imaginar que estamos em um escritório de advocacia, recebemos inumeros processos por dia para analisar e gostariamos de tornar esse processo mais agil então estamos vendo como um IA de NLP pode nos ajudar.
📄 Algumas tarefas em NLP:
🧠 Part-of-Speech Tagging:
- Para que serve? Entende a função gramatical das palavras (verbo, substantivo, etc).
- Quando usar? Pode ser usado em tradutores, geradores de texto ou sistemas que precisam manter a coerência linguística.
- Exemplo? Considerando nosso escritório de advocacia, poderiamos uma IA que recebe um processo e gere um resumo. Essa IA precisa entender se "caso" é substantivo ("o caso em questão") ou verbo ("eu caso com ela") para manter o sentido correto na hora de reescrever trechos ou produzir novos.
🏷️ Named Entity Recognition (NER):
- Para que serve? Identificar nomes de pessoas, lugares, empresas, entre outros.
- Quando usar? Quando precisamos identificar determinados campos.
- Exemplo: nossa IA que lê contratos extrai “Empresa contratante”, “Prazo”, “Valor total” para conseguirmos organizar melhor nossas demandas.
🌳Parsing Sintático:
- Para que serve? Analisar a estrutura das frases.
- Quando usar? Quando a estrutura da frase influencia o sentido, como em perguntas, comandos ou textos jurídicos.
- Exemplo? Identificar quem fez o quê em “João foi atacado por Maria” vs “Maria atacou João”. Apesar de semelhantes, a responsabilidade muda completamente — algo essencial em contextos legais.
😊 Sentiment Analysis:
- Para que serve? Detecta a polaridade emocional de um texto (positivo, negativo, neutro).
- Quando usar? Comentários de clientes, redes sociais ou avaliações de produtos.
- Exemplo? A IA pode avaliar o tom de e-mails recebidos, comentários públicos nas redes sociais ou até manifestações de clientes nos autos de um processo, para entender se há reclamações recorrentes ou elogios ao atendimento jurídico.
📚 Classificação de Texto
- Para que serve? Atribui categorias a um texto com base em seu conteúdo.
- Quando usar? Para organizar automaticamente documentos por tipo: contratos, petições, decisões, etc.
- Exemplo? A IA pode ler automaticamente novos arquivos e classificá-los como “ação trabalhista”, “recurso”, “contestação”, agilizando a triagem por tipo de documento.
5. 🧬 Como representar texto para a IA?
Máquinas não entendem palavras como nós. Elas entendem números. Por isso, o texto precisa ser transformado em algo que a IA consiga processar.
Formas de representação:

- Bag of Words (BoW): Como o nome diz é um saco de palavras que guarda a informação da frequência de cada palavra, ignorando a ordem e o contexto das palavras.
- TF-IDF (Term Frequency - Inverse Document Frequency): Baseia-se na ideia de que palavras raras contêm mais informações sobre o conteúdo de um documento do que palavras que são usadas muitas vezes em todos os documentos.
Por exemplo: “gostei muito do produto” e “não gostei do produto”. Ambas têm as mesmas palavras, exceto pelo “não”. O BoW pode considerar ambas parecidas, porque ignora a ordem e contexto. Já o TF-IDF pode destacar que “não” é uma palavra importante por não ser comum em todos os documentos.
- Word Embeddings (Word2Vec, GloVe): Transforma as palavras em vetores que permite a extração da relação entre palavras como antônimos, sinônimos e palavras do mesmo grupo.
- Modelos de linguagem baseados em Transformers (BERT, GPT): é uma rede neural que aprende o contexto, são mais variados e mais complexos. Vale se aprofundar dando uma explorada no Hugging Face https://huggingface.co/docs/transformers/en/index
6. 🔍 Como treinar modelos de NLP: dados, exemplos e atalhos

Depois de entender como limpar e preparar os textos, surge uma pergunta comum: “de onde vêm os dados para treinar um modelo de NLP?” e “é sempre necessário treinar do zero?” A boa notícia é que existem várias opções – desde usar bases públicas até aproveitar modelos prontos que já sabem muito. E caso nenhum dataset pronto se encaixe para o seu objetivo pode ser valido coletar os dados, principalmente se for para atender uma demanda particular.
6.a.📊 Fontes de dados para treinar modelos
Você pode começar com dados gratuitos e abertos. Aqui vão alguns exemplos:
- Kaggle (https://kaggle.com/datasets): uma das maiores plataformas de datasets. Lá você encontra conjuntos prontos para tarefas como análise de sentimentos, classificação de notícias, detecção de fake news, entre outros.
- Dados públicos do governo: portais como o dados.gov.br oferecem bases que vão desde boletins de ocorrência até dados de saúde e educação – tudo em linguagem natural.
- Repositórios acadêmicos: como a Open Data Hub ou o portal da UCI Machine Learning Repository.
Além do Kaggle e de portais governamentais, também vale explorar APIs públicas como a do Twitter (para análise de sentimentos), Reddit (discussões), ou repositórios como Common Crawl, que trazem dados da web. Sempre verifique se o uso dos dados está de acordo com os termos de uso e privacidade.
6.b.🧠 Modelos pré-treinados para não começar do zero
Nem sempre é necessário (ou viável) treinar um modelo do zero. Plataformas como a Hugging Face oferecem modelos prontos (como BERT, RoBERTa, GPT-2, etc.) que você pode:
- Usar diretamente para tarefas como classificação, NER ou geração de texto.
- Fazer fine-tuning (ajuste fino) com seus próprios dados para um domínio específico (jurídico, médico, educacional...).
Esses modelos já entendem boa parte da linguagem e, com poucos exemplos, conseguem se adaptar a contextos mais específicos.
Um exemplo de como usar os modelos disponibilizados de transformers no hugging face, lembrando que será necessário usar pip install <module>:
from transformers import pipeline
analisador = pipeline("sentiment-analysis", model="nlptown/bert-base-multilingual-uncased-sentiment")
resultado = analisador("O escritório fez um acompanhamento bem detalhado do caso, boa orientação!")
print(resultado)
# [{'label': '4 stars', 'score': 0.5836421847343445}]
6.c💡 Boas práticas para trabalhar com NLP em português:
- Usar bibliotecas com suporte ao idioma:
spaCycom modelopt_core_news_sm, oustanzada Stanford NLP. - Usar modelos pré-treinados em português:
BERTimbau,neuralmind/bert-base-portuguese-cased, ouxlm-roberta-base. - Fazer seu próprio fine-tuning com textos reais, caso trabalhe em um domínio específico (ex: jurídico).
- Fazer pré-processamento cuidadoso, respeitando acentos, stopwords específicas do português e morfologia.
📦 Dica: No Hugging Face, basta pesquisar por modelos com a tag portuguese para encontrar vários que já foram treinados com dados em português — alguns, inclusive, com dados jurídicos e médicos.
🧪 7. Avaliação de modelos de NLP

Depois de treinar (ou ajustar) um modelo de NLP, como saber se ele está realmente funcionando bem? Avaliar um modelo é tão importante quanto desenvolvê-lo, porque é isso que garante que ele esteja entregando resultados confiáveis.
📊 Principais métricas de avaliação:
- Acurácia: Proporção de acertos sobre o total de previsões.
- Precisão (Precision): Entre os resultados positivos previstos, quantos realmente são positivos.
- Revocação (Recall): Entre todos os positivos reais, quantos foram corretamente identificados.
- F1-score: Média harmônica entre precisão e recall (equilibra os dois).
- Métricas específicas por tarefa:
- BLEU (para tradução automática)
- ROUGE (para resumo automático)
- Exact Match e F1 (para perguntas e respostas)
📝 Exemplo prático:
Imagine que seu modelo classifica se um processo jurídico é trabalhista, penal ou civil. Se ele errar esse tipo de classificação, pode impactar a priorização de casos. Por isso, é essencial rodar testes com dados reais e analisar essas métricas para validar a eficácia antes de implantar.
8. 🧱 Desafios comuns em NLP

Mesmo com modelos avançados, ainda existem obstáculos importantes:
- Ambiguidade: A mesma palavra pode ter sentidos diferentes dependendo do contexto (“banco” pode ser de sentar ou financeiro).
- Ironia e sarcasmo: “Nossa, que ótimo atendimento!” pode ser positivo ou sarcástico, e a IA pode se confundir.
- Idiomas e sotaques regionais: Modelos treinados em português de Portugal podem errar interpretações no português brasileiro — ou mesmo entre regiões do Brasil.
Grande parte dos recursos de NLP foi desenvolvida originalmente para o inglês. Isso gera um desafio para quem trabalha com português, uma língua morfologicamente mais complexa e com menos datasets disponíveis.
9. 🔮 O futuro do NLP: para onde vamos?

A cada ano, os modelos de NLP ficam mais avançados. Hoje, já conseguimos gerar textos coerentes, traduzir em tempo real e até resumir livros com IA. Mas o futuro promete ainda mais:
- IA com senso de contexto mais profundo
- Traduções culturais e não literais
- Interação multimodal (texto + imagem + som)
- Menos viés e mais ética no processamento de linguagem
- O que mais você consegue imaginar?
10. 🏁 Conclusão: O primeiro passo é entender

Você não precisa ser um cientista de dados para começar a explorar o NLP. Entender o básico, como vimos aqui, já é um ótimo primeiro passo. Se você programa em Python, está a um comando de distância de começar a aplicar NLP em seus próprios projetos.
Existe um mar de conhecimento aqui na DIO e em diversos sites para aprendermos mais sobre IA, Python e NLP. Entender como funciona uma tecnologia além da chamada da API é um grande diferencial no mercado e até no uso das ferramentas.
Comente se esse conteúdo ajudou você ou te inspirou a buscar saber mais sobre NLP ❤️
🆙 O seu feedback contribui com a minha melhora continua
📚 Referências e Recursos
- NLP: o que é, usos práticos e como aplicar em seu dia a dia, FlowUp - 2024
- Multilingual Denoising Pre-training for Neural Machine Translation, Yinhan Liu et al - 2020
- A Brief History of Natural Language Processing — Part 2, Antoine Louis - 2020
- Introduction to Natural Language Processing — TF-IDF, Kinder Chen - 2021
- Understanding Natural Language Processing Pipeline, Hassan Amin - 2022
- NLTK Documentation
- spaCy.io






Obrigada Fernando! 💕✨️
Ótimo artigo! Prêmio merecido!!!
João muito obrigado pelo seu comentário, que bom que gostou do artigo 💕
Sim, com certeza o NLP pode ser muito útil para quem atua no mercado financeiro. Você pode treinar modelos para:
E para ter maior precisão pode extrair dados relevantes de notícias usando web scrapping, documentos regulatórios ou balanços como já tem disponivel na biblioteca do yahoo finance
Hoje já existem ferramentas e modelos que ajudam a automatizar esses processos. Com os dados certos e um bom direcionamento, é totalmente possível adaptar uma IA para apoiar (ou até acelerar) sua análise financeira 🪙
JG
Daniela, gostei muito do artigo
E fiquei curioso, acredita que eu posso usar isso pra minha profissão? Trabalho no mercado financeiro e tu acha que poderia treinar a ia para ler artigos conseguindo, criar relatórios e conseguindo informações precisas do que necessito?
Muito obrigada Gabriehl ❤️❤️❤️
DIO Community, muito obrigada pelo feedback! Fico bem feliz em ler isso ❤️
Acredito que a parte mais desafiadora para quem está começando é o pre-processamento porque essa parte impacta todo o resto do processo, então se não tiver um bom pré-processamento o modelo pode não conseguir aprender como esperado mesmo com o modelo mais adequado.
Daniela, seu artigo apresenta uma explicação clara e didática sobre o processamento de linguagem natural (NLP) com Python, abordando desde conceitos fundamentais até exemplos práticos que ajudam a desmistificar o tema. A estrutura do texto, com etapas bem definidas e o uso de código comentado, facilita o entendimento para quem está começando e reforça a importância do pré-processamento e das tarefas típicas de NLP.
Na sua experiência, qual etapa do processamento de linguagem natural costuma ser a mais desafiadora para iniciantes?
GC
Muito bom e interessante!!