


IA Sem Fronteiras, Mas Com Dono
- #Inteligência Artificial (IA)
IA Sem Fronteiras, Mas Com Dono
Por que a Soberania de Dados é o Verdadeiro Desafio da IA em 2026
1. Problema de Negócio
Existe uma contradição silenciosa no uso corporativo de IA em 2026:
• Se você usa IA no trabalho hoje, seus dados já saíram da sua empresa — você só ainda não percebeu.
• Quanto mais você usa, mais você expõe.
Na prática, isso significa que toda vez que um desenvolvedor cola um trecho de código em uma IA, toda vez que um analista de dados envia uma planilha para ser interpretada, toda vez que um time de produto usa um assistente para rascunhar uma estratégia — dados sensíveis saem do seu ambiente e vão para servidores de terceiros.
Esse não é apenas um problema técnico. É um risco com três dimensões:
- Jurídico: a LGPD prevê multas de até 2% do faturamento anual, limitadas a R$ 50 milhões por infração. Vazar dados de clientes por negligência no uso de ferramentas externas se enquadra diretamente nessa categoria.
- Estratégico: código proprietário, arquiteturas internas e estratégias de produto enviados para APIs externas podem, dependendo dos termos de serviço, ser usados para treinar modelos concorrentes.
- Financeiro: o custo recorrente de múltiplas ferramentas SaaS de IA cresce de forma silenciosa e difícil de rastrear.
A pergunta que motivou este projeto foi simples:
É possível usar IA com a mesma capacidade das grandes plataformas, mas mantendo os dados dentro do meu próprio ambiente?
2. Contexto
Trabalho como Data Engineer e Cloud Architect, com experiência em sistemas críticos bancários onde controle de dado não é preferência — é requisito regulatório.
Nesse contexto, observei um padrão se repetindo nas empresas com que tenho contato:
- Times técnicos adotam ferramentas de IA individualmente, sem política centralizada
- Cada adoção cria um novo ponto de vazamento potencial
- O custo se fragmenta em múltiplos cartões de crédito corporativos
- E quando alguém pergunta "onde estão nossos dados?", ninguém sabe responder com certeza
Foi a partir dessa observação que comecei a estudar arquiteturas self-hosted de orquestração de IA — e o OpenClaw surgiu como o componente central de uma solução que construí e opero em produção.
3. Premissas
Para garantir a transparência da análise, é importante deixar claro o que foi assumido como verdade neste projeto:
- Os valores de custo por usuário (R$ 200–R$ 1.000/mês) são estimativas baseadas em planos pagos de ferramentas como ChatGPT Plus, Copilot Enterprise e Notion AI, somados, para perfis de uso intenso em times técnicos.
- O MTTR (Mean Time to Recovery) de ~40 minutos representa o tempo médio que eu levava antes para executar um ciclo de troubleshooting manual: identificar o problema, acessar o servidor via terminal, executar comandos e confirmar restauração. Esse valor foi reduzido após a automação via Telegram, com média de execução medida ao longo de 3 semanas de operação.
- A economia de 70–90% compara o custo de um VPS (~R$ 30/mês) com o custo hipotético de 3 SaaS de IA em uso simultâneo, sem considerar o custo de engenharia para configurar e manter o ambiente self-hosted.
- O ambiente testado é de uso individual/pequeno time — escalar para dezenas de usuários simultâneos requer revisão de infraestrutura.
- O OpenClaw é uma ferramenta open source de terceiros. A solução arquitetural descrita aqui — incluindo as escolhas de infraestrutura, integração de modelos e automações — é de minha autoria.
4. Estratégia da Solução
A implementação seguiu uma abordagem incremental em quatro fases:
Fase 1 — Infraestrutura base
Provisionamento de uma VPS com uptime 24/7, configuração de Docker para isolamento de serviços e exposição segura via HTTPS com certificado SSL.
Fase 2 — Instalação e configuração do OpenClaw
O OpenClaw atua como um *gateway inteligente*: ele recebe requisições de canais como WhatsApp e Telegram, roteia para o modelo de IA configurado, executa as respostas e devolve ao canal de origem — tudo dentro do meu servidor.
Usuário (Telegram / WhatsApp)
↓
OpenClaw (gateway — VPS)
↓
Modelo de IA (API externa ou Ollama local)
↓
Execução segura (dentro do servidor)
↓
Resposta automatizada ao canal
Fase 3 — Integração híbrida de modelos
Configurei dois modos de operação:
- API externa (GPT / Claude): para tarefas que exigem maior capacidade de raciocínio
- Ollama local (LLaMA / Mistral): para tarefas onde a privacidade é prioritária e a latência é tolerável
Fase 4 — Automações operacionais via Telegram
Configurei comandos que executam operações no servidor diretamente pelo Telegram: deploy de containers, restart de serviços, verificação de logs e monitoramento de uptime. Isso eliminou a necessidade de acesso SSH manual para operações rotineiras.
5. Decisões Técnicas
Essas escolhas não foram aleatórias. Cada uma tem uma justificativa e um trade-off aceito conscientemente.
Por que VPS e não máquina local?
Uma máquina local depende de energia elétrica, conexão residencial e disponibilidade física. A VPS garante automação contínua (jobs agendados, alertas, deploys noturnos) sem intervenção humana. O trade-off é o custo mensal fixo (~R$ 30), que considero justificado pela disponibilidade.
Por que Docker?
Isolamento de serviços, portabilidade entre ambientes e atualização sem impacto no sistema operacional host. O OpenClaw, o Ollama e os serviços auxiliares rodam em containers separados, com volumes persistentes para dados críticos.
Por que a estratégia híbrida de modelos (API + local)?
Nenhuma abordagem isolada atende todos os cenários:
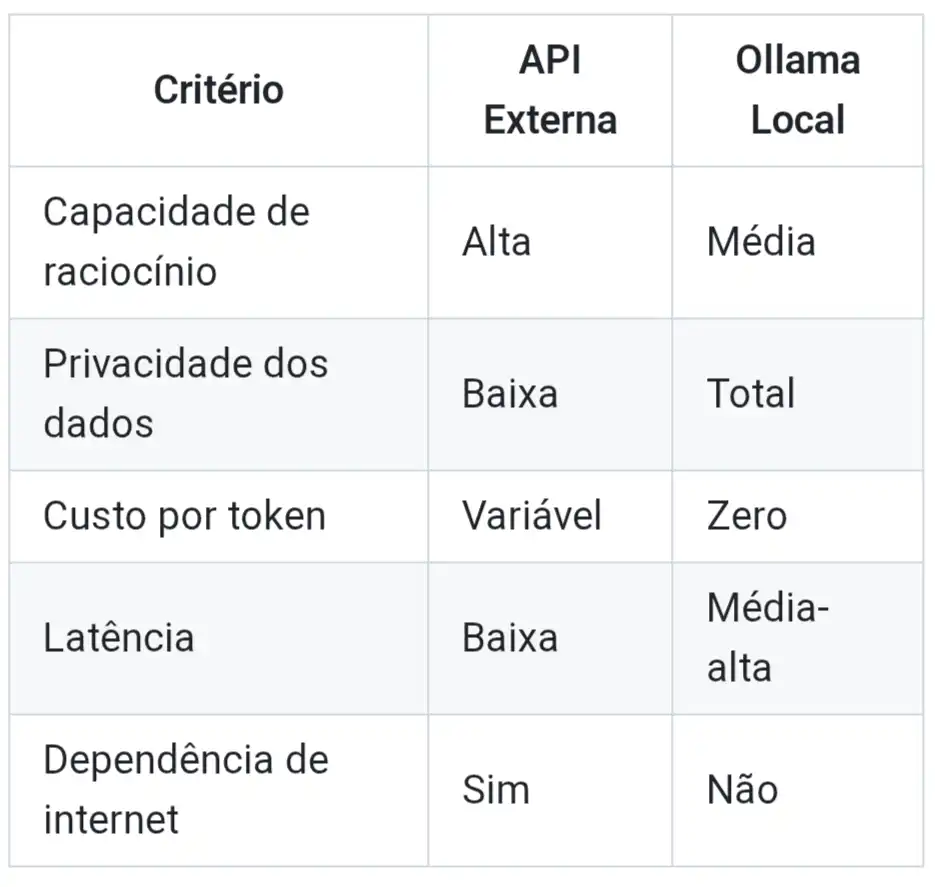
A combinação das duas abordagens permite escolher o modelo certo para cada tipo de tarefa, equilibrando custo, performance e privacidade.
Por que não usar soluções SaaS prontas?
Precisamente porque o problema que estou resolvendo é a dependência de SaaS. Usar uma ferramenta de orquestração de IA hospedada por terceiros para resolver o problema de dados em terceiros seria contraditório.
6. Business Performance
Esse é o ponto que a maioria dos projetos técnicos ignora: **qual é o impacto em números reais?**
Redução de custo direto
- Antes: estimativa de R$ 400–600/mês em ferramentas SaaS de IA (3 ferramentas, uso intenso)
- Depois: R$ 30/mês de VPS + custo variável de API (controlável por orçamento configurado)
- Economia estimada: 70–85% no custo de ferramentas de IA
Redução de risco regulatório
- Dados sensíveis processados localmente não trafegam por APIs externas
- Logs de auditoria centralizados e controláveis
- Mitigação de exposição direta a multas LGPD para dados que, antes, saíam do ambiente sem rastreabilidade
Eficiência operacional (MTTR)
Antes da automação via Telegram:
- Identificar alerta → abrir terminal → acessar VPS via SSH → executar comandos → confirmar → ~40 min
Depois, com comando automatizado:
- Receber alerta → enviar comando pelo Telegram → confirmar execução → *
menos de 5 min
Redução de ~87,5% no tempo de resposta operacional para incidentes rotineiros.
7. Insights
Três aprendizados que só ficaram claros depois de colocar o sistema em produção:
Insight 1 — O custo real de SaaS de IA é invisível
Antes de centralizar, eu não sabia exatamente quanto gastava em ferramentas de IA por mês. Elas estavam distribuídas em diferentes métodos de pagamento e planos. A consolidação em um único ambiente self-hosted tornou o custo visível e controlável pela primeira vez.
Insight 2 — Self-hosted não elimina dependência, redistribui responsabilidade
Ao sair de um SaaS, você para de depender do fornecedor para disponibilidade e segurança. Mas você passa a ser responsável por isso. Em 2026, já foram documentadas vulnerabilidades em skills (extensões) de terceiros para plataformas como o OpenClaw. Isso significa que o modelo self-hosted é mais seguro por design, mas exige maturidade operacional para ser seguro na prática.
Insight 3 — A automação via Telegram é subestimada como interface operacional
Inicialmente, encarei o Telegram como um canal de conveniência. Depois de algumas semanas, percebi que ele é a interface mais eficiente que já usei para operações de servidor em mobilidade. Mais de 80% das interações operacionais com minha infraestrutura passaram a acontecer pelo Telegram, não pelo terminal.
8. Aprendizados Honestos
O que foi mais difícil:
A configuração inicial do OpenClaw com Ollama local foi significativamente mais trabalhosa do que a documentação sugeria. A integração entre os dois requer ajuste fino de variáveis de ambiente e, em algumas versões, há incompatibilidades que não estão documentadas. Gastei aproximadamente 6 horas depurando uma falha de conexão que tinha origem em uma variável de configuração com nome inconsistente entre versões.
O que faria diferente:
Começaria pelo Ollama isolado — sem o OpenClaw — para validar os modelos locais antes de adicionar a camada de gateway. A complexidade de debugar dois sistemas novos simultaneamente atrasou o projeto em pelo menos dois dias.
O que não estava no plano:
Descobri durante a implementação que o gerenciamento de contexto de conversas longas no modo local tem limitações práticas de memória que não aparecem nos benchmarks. Para casos de uso com histórico extenso, a API externa ainda é superior.
Reconhecimento:
A comunidade do projeto OpenClaw no GitHub foi essencial para resolver os problemas de integração. Duas issues abertas por outros usuários continham exatamente as soluções que eu precisava.
9. Riscos e Premissas de Operação
Self-hosted não é mágica — é responsabilidade redistribuída.
Os principais riscos operacionais que identifiquei e as mitigações aplicadas:
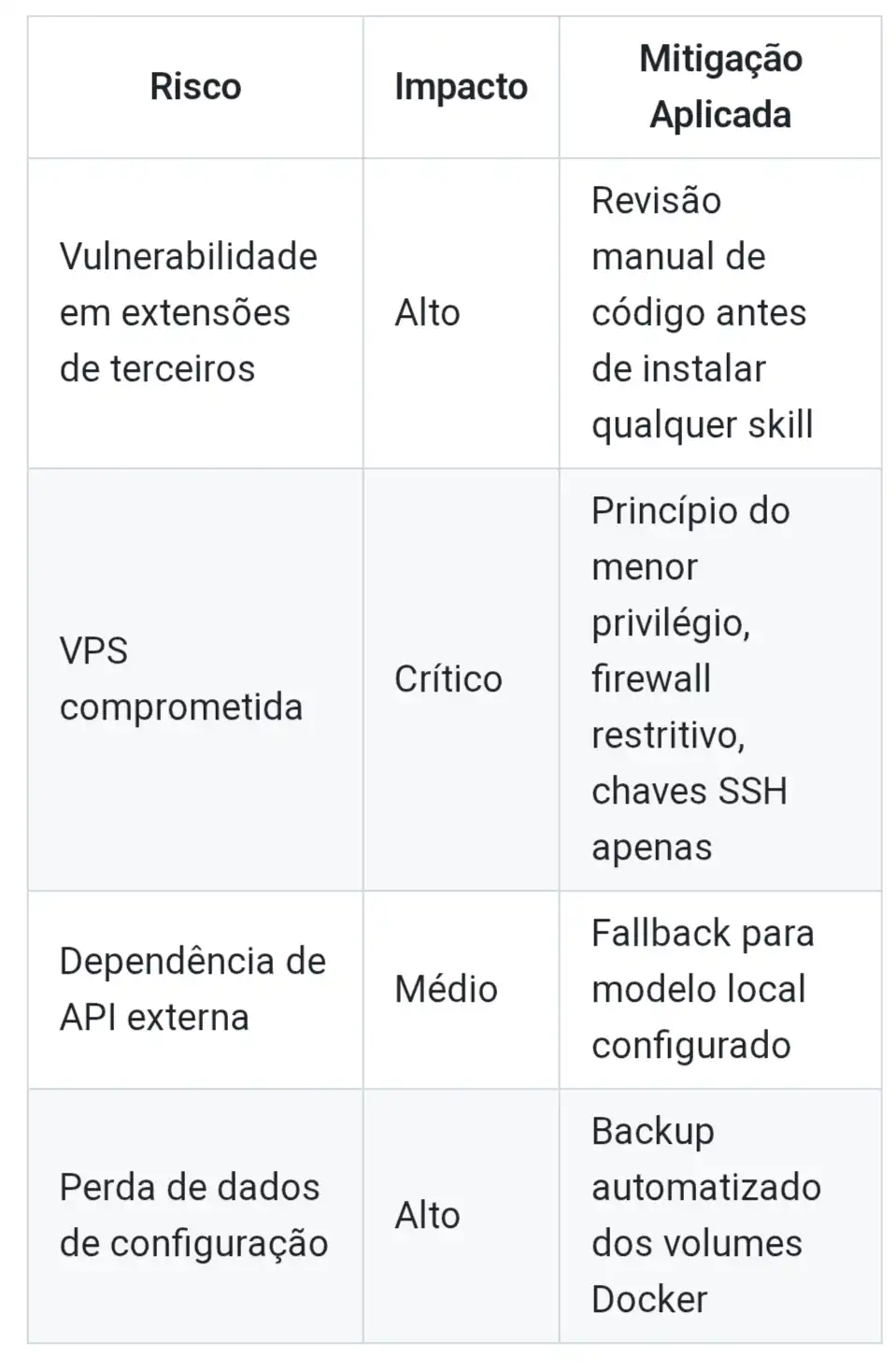
10. Próximos Passos
Com base no que aprendi na primeira fase de operação, os próximos desenvolvimentos planejados são:
- Monitoramento contínuo com alertas inteligentes: integrar stack de observabilidade (logs + métricas) com notificações proativas, não apenas reativas
- Múltiplos agentes especializados: separar o agente de operações de infraestrutura do agente de análise de dados, reduzindo o escopo de permissões de cada um
- Análises preditivas de falha: usar histórico de logs para treinar um modelo simples de detecção de anomalias antes que virem incidentes
- Documentação de runbooks automatizados: transformar os comandos Telegram mais usados em fluxos guiados, facilitando eventual delegação para outros membros do time
Conclusão
O problema que esse projeto resolve não é técnico na sua essência.
É uma questão de controle sobre o que é seu.
O OpenClaw foi a ferramenta. A solução foi a arquitetura: um ambiente self-hosted, híbrido, auditável, com custo controlado e dados que não saem do seu servidor sem sua autorização explícita.
Para empresas que lidam com dados regulados — saúde, finanças, dados de clientes — esse modelo não é uma opção avançada. É o caminho inevitável.
O mercado não vai contratar quem usa IA.
Vai contratar quem entende onde os dados estão, quem tem acesso a eles
e como garantir que isso não vire um passivo jurídico e estratégico.
IA sem soberania de dados não é inovação — é risco operacional escalável.
Hoje, essa arquitetura substitui múltiplas ferramentas no meu fluxo e se tornou a base operacional das minhas automações.
Provocação Final
Você sabe para onde vão os dados que você digita na sua IA hoje?
Se a resposta for "não tenho certeza" — esse projeto foi escrito para você.
#OpenClaw #IA
#DataEngineering #Cloud #LGPD #SelfHosted #TechLeadership #DataPrivacy






Uau.
Que artigo incrível.
Eu entendo a questão de segurança, mas, como jornalista, sou a prova de que segurança informacional é efêmera e sutil; não importa quantos muros coloque ao redor da rosa.
Escrevo isso pois o jornalismo nasceu com o Imperador Júlio César criando o primeiro jornal da humanidade: Acta Diurna.
Eran grandes placas de madeira ou argila que anunciavam no outro dia as decisões tomadas na cidade, ficavam nas praças em lugares altos.
Os jornalistas tinham a tarefa de difundir a informação somente para os romanos, mas nunca deu certo.
Antes do Acta Diurna, os mensageiros tinham que correr de casa em casa proclamando as notícias, acabavam morrendo.
Com isso, criou-se o Acta Diurna e a cifra de César para proteger as informações seguras, pois só quem soubesse ler latim da elite leria corretamente o jornal e só quem soubesse a combinação de César decodificava a informação.
Ao passar do tempo, esses muros romanos foram caindo. E hoje, usamos o Acta Diurna como outdoors nas esquinas e a Cifra de César para criar dialetos entre amigos.
Então, acredito que o efeito manada nos irá fazer a banalizar parte da informação, e construir fluxos seguros para informações relevantes minoritarias para a empresa.