
Jupyter Notebook + Linux Bash
Jupyter Notebook
O Jupyter Notebook (Jupyter Lab, Colab, etc.) já é uma ferramenta consolidada para executar código Python, principalmente no tratamento de dados.
Porém, além de executar scripts Python, é possível executar códigos e scripts de várias outras linguagens. O nome Jupyter vem de JUlia PYThon E (and ou &) R.
Conceitualmente, é possível executar qualquer código desde que existe um interpretador de executar o código fornecido.
Para isso, “basta” instalar ou criar um kernel para o Jupyter que se comunique com o interpretador.
Por exemplo, o Java possui um REPL que funciona como interpretador, chamado JShell. Com o kernel do JShell, é possível executar Java dentro de um notebook.
Jupyter + Bash
É aí que entra a dupla Jupyter + Bash. Isso mesmo: é possível executar código Bash do Linux dentro de um notebook. O melhor é que já existe um kernel pronto para o Jupyter executar comandos Bash.
E qual a necessidade de executar bash dentro de um notebook?
Se você vai aprender ou ensinar Bash, essa dupla pode facilitar muito as coisas. Similar ao que acontece em Python, o uso de um Notebook com Bash permite manter em um só lugar a documentação e histórico de execução do seu código.
É mais fácil planejar, organizar, compartilhar e executar o conteúdo a ser estudado. Em seguida, basta exportar o histórico da execução como arquivo “.html”.
Pronto, você já tem um documento com código e resultado de tudo que foi feito.
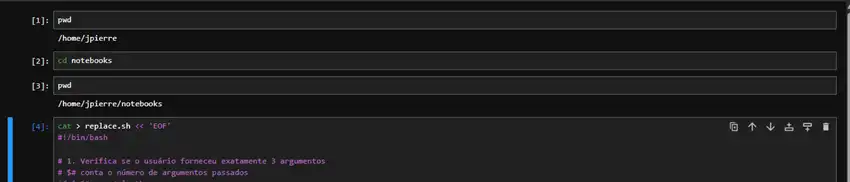
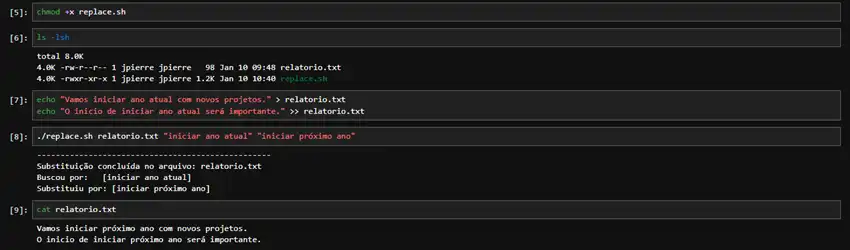
Estude além do Bash
Além de organizar estudos sobre Bash, é possível organizar qualquer (ou quase) estudo executado pela linha de comando do Linux.
Por exemplo, esses dias estou me aventurando a executar Spark em cluster Kubernetes. Porém, estou usando Kubernetes localmente em containers Docker. Ou seja, nem sempre as coisas dão certo.
Mesmo com ajuda da IA, em determinado momento ficou confuso quais “passos” deram certo ou errado, e manter todo o histórico de saída de comandos não é nada fácil.
Fazer isso em um Notebook facilita manter um histórico de tudo que foi feito, inclusive o que deu errado (o que é muito importante no processo de aprendizagem).
Depois, é só criar uma cópia com as execuções que deram certo como documento final.
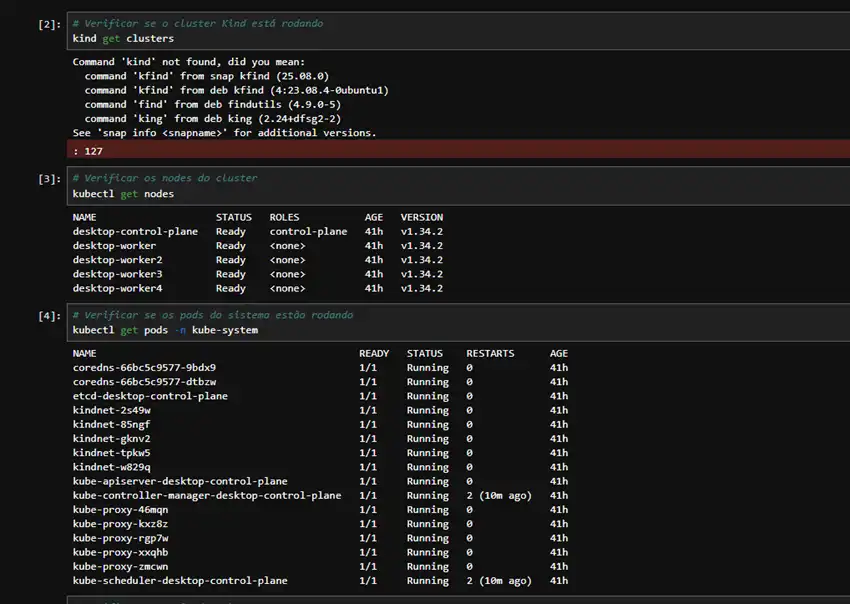
Como testar
Você precisa ter uma distribuição Linux para testar.
Para usuário Windows, você vai precisar do WSL. Tentei criar, junto com Claude.ai, um kernel para executar o Bash do Git instalado no Windows, mas não obtive muito sucesso. Então, fica com o WSL mesmo.
No meu teste, usei WSL2/Ubuntu.
Uma boa prática é criar uma venv para instalar o Jupyter. Considerando que já tenha o Python instalado, basta seguir os procedimentos abaixo.
# Criação e ativação do ambiente virtual
user@host:~$ python3 -m venv jupyter_env
user@host:~$ source jupyter_env/bin/activate
# Instalar Jupyter e Bash Kernel
(jupyter_env) user@host:~$ pip install jupyter
(jupyter_env) user@host:~$ pip install bash_kernel
Collecting bash_kernel
Baixando bash_kernel-0.10.0-py2.py3-none-any.whl.metadata (5,2.2 kB)
Requirement already satisfied: pexpect>=4.0 in ./jupyter_env/lib/python3.12/site-packages (from bash_kernel) (4.9.0)
Requirement already satisfied: ipykernel in ./jupyter_env/lib/python3.12/site-packages (from bash_kernel) (7.1.0)
Coletando tipo de arquivo (do bash_kernel)
Downloading filetype-1.2.0-py2.py3-none-any.whl.metadata (6.5 kB)
# Configurar e listar o kernel
(jupyter_env) user@host:~$ python -m bash_kernel.install
Instalando a especificação do kernel IPython
(jupyter_env) user@host:~$ jupyter kernelspec list
Kernels disponíveis:
python3 /home/jpierre/jupyter_env/share/jupyter/kernels/python3
bash /home/jpierre/.local/share/jupyter/kernels/bash
# Iniciar o Jupyter Lab
(jupyter_env) user@host:~$ jupyter lab
[I 2026-01-10 08:44:17.727 ServerApp] jupyter_lsp | extensão vinculada com sucesso.
[I 2026-01-10 08:44:17.729 ServerApp] jupyter_server_terminals | extension foi vinculada com sucesso.
...
[I 2026-01-10 08:44:17.933 ServerApp] Jupyter Server 2.17.0 está em execução em:
[I 2026-01-10 08:44:17.933 ServerApp] http://localhost:8888/lab?token=a952aa75128a49953e51704af476093c3e0597c605101b76
[I 2026-01-10 08:44:17.933 ServerApp] http://127.0.0.1:8888/lab?token=a952aa75128a49953e51704af476093c3e0597c605101b76
[I 2026-01-10 08:44:17.933 ServerApp] Use Control-C para interromper este servidor e desligar todos os kernels (duas vezes para pular a confirmação).
Cuidado com conflitos
Aqui, precisamos fazer algumas considerações. Quando o Jupyter é iniciado, é criado um servidor local acessível no endereço localhost, porta 8888.
Se você executar mais de uma instância do Jupyter simultaneamente, o próximo servidor estará disponível automaticamente na porta 8889 e assim sucessivamente.
Se você executar uma instância do Jupyter no Windows e outra no WSL/Ubuntu (ou vice-versa), a segunda instância não “saberá” da primeira, pois cada sistema operacional usa uma instalação distinta do Jupyter.
Nesses casos, será necessário indicar explicitamente em qual porta o Jupyter deve ser iniciado.
# Iniciar o Jupyter Lab em uma porta específica
(jupyter_env) user@host:~$ jupyter lab —ip=0.0.0.0 —port=18888 —no-browser
Também é possível configurar o Jupyter para sempre executar em uma porta específica, como a 18888, por exemplo.
# Configura porta padrão do Jupyter
(jupyter_env) user@host:~$ jupyter notebook —generate-config
# Editar arquivo, pressiona CTRL + X ao terminar
(jupyter_env) user@host:~$ nano ~/.jupyter/jupyter_notebook_config.py
# Adicionar o trecho abaixo no final do arquivo
## Configuração para acesso de qualquer lugar (IP)
c.NotebookApp.ip = '0.0.0.0'
## Configuração da porta desejada
c.NotebookApp.port = 18888
## Impedir que o Jupyter abra o navegador automaticamente
c.NotebookApp.open_browser = False
c.ServerApp.open_browser = False
Limitações
Algumas limitações que encontrei na solução
- Não consegui executar programas que precisam de interação dentro do programa, como o nano, por exemplo. Para sair do nano, é necessário passar o comando CTRL+x;
- A função autocompletar com a tecla “Tab” não funciona para nomes de diretórios e arquivos;
- Não consegui executar dois notebooks simultaneamente usando o kernel do Bash
Bônus
Se você estiver executando o Jupyter em um navegador com IA, como o Comet, por exemplo, pode fazer perguntas sobre a página como fonte de informação.
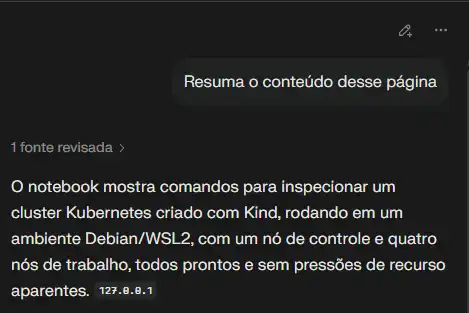
Resuma o conteúdo dessa página
O notebook mostra comandos para inspecionar um cluster Kubernetes criado com Kind, rodando em um ambiente Debian/WSL2, com um nó de controle e quatro nós de trabalho, todos prontos e sem pressões de recurso aparentes.
Comandos executados
- Tentativa de usar o comando kind para listar clusters, mas o binário não está instalado ou não está no PATH, gerando mensagem “Command 'kind' not found”.
- Uso de kubectl get nodes para listar os nós do cluster, exibindo um nó desktop-control-plane e quatro nós desktop-worker em status Ready com versão v1.34.2.
- Uso de kubectl get pods -n kube-system para verificar pods de sistema, como coredns, kube-apiserver, kube-scheduler, kube-controller-manager, kube-proxy, kindnet e etcd, todos em estado Running.
Versão do cluster
- Comando kubectl version mostrando cliente na versão v1.34.1 com Kustomize v5.7.1.
- Servidor Kubernetes reportado na versão v1.34.2.
Detalhes dos nodes
- kubectl describe nodes exibe, para cada nó, informações de capacidade (16 CPUs, ~16 GiB de memória, 110 pods por nó), sistema operacional Debian GNU/Linux 12, runtime containerd://2.2.0 e kernel 6.6.87.2-microsoft-standard-WSL2.
- As condições de todos os nós indicam MemoryPressure=False, DiskPressure=False, PIDPressure=False e Ready=True, sem eventos de erro relevantes, apenas eventos normais de registro de nó.
Pods e recursos alocados
- Para o nó de controle, os pods principais são coredns, etcd, kube-apiserver, kube-controller-manager, kube-scheduler, kube-proxy, kindnet e local-path-provisioner, com solicitações de recurso baixas (menos de 5% de CPU e cerca de 1–2% de memória).
- Nos nós de trabalho aparecem pods de rede (kindnet), kube-proxy e alguns workloads adicionais como spark-operator e portainer-agent, todos sem limites nem requests agressivos, mantendo uso de recursos muito baixo.



