
Python para Análise de Dados: Domínio Completo de Estruturas e Técnicas.
- #Data
Guia Definitivo de Python para Análise de Dados: Dicionários, Conjuntos, List Comprehensions e Funções Avançadas.
Python para Análise de Dados: Domínio Completo de Estruturas e Técnicas.
💡 Você sabia que mais de 70% do tempo de um analista é gasto em limpeza e manipulação de dados?
Python, quando bem utilizado, reduz drasticamente esse tempo — e neste guia você vai aprender exatamente como.
Em um cenário onde o tempo é o recurso mais escasso, analistas de dados que dominam Python com profundidade ganham uma vantagem competitiva real. Ferramentas como Excel ou BI atendem bem à análise descritiva, mas quando o desafio envolve grandes volumes, automação ou personalização, é o código limpo e eficiente que dita o ritmo.
É aqui que entra Python — uma linguagem que vai muito além do básico quando se conhece suas estruturas de dados poderosas: dicionários, conjuntos, list comprehensions e funções de alta ordem. Esses recursos, quando bem aplicados, reduzem a complexidade do código, aumentam a performance e permitem maior clareza na extração de insights.
📊 Estudos revelam que profissionais que dominam essas técnicas economizam até 40% do tempo em tarefas rotineiras de manipulação de dados, podendo focar no que realmente importa: análise e tomada de decisão.
Neste artigo, você vai aprender — com código real, aplicações práticas e um projeto final — como utilizar essas ferramentas com maestria. Prepare-se para transformar sua rotina analítica com um arsenal Pythonico que representa 80% das operações mais comuns em análise de dados profissional.
⚡ Dominar as estruturas certas em Python é como ter superpoderes na análise de dados.
Este artigo combina todos os conceitos essenciais para:
- Manipulação profissional de dados estruturados.
- Processamento otimizado de grandes volumes.
- Código limpo e eficiente com técnicas Pythonicas.
- Casos reais aplicados a análise de dados.
E o melhor: você não precisa ser especialista para começar — este guia vai te levar do domínio básico ao avançado, com exemplos claros e diretos ao ponto.
🧠 "O Python se tornou essencial para análise de dados porque combina legibilidade com poder técnico."
— Wes McKinney, autor de Python para Análise de Dados.

“Dicionários – Sua Estrutura de Dados Mais Versátil”
Os dicionários em Python são estruturas de dados poderosas formadas por pares de chave-valor. Eles permitem armazenar, acessar e manipular informações de forma organizada, rápida e altamente legível — ideais para representar dados estruturados como cadastros de clientes, inventários, configurações ou registros transacionais.
Ao contrário das listas, onde os elementos são acessados por índice numérico, nos dicionários o acesso é feito por chaves únicas, o que proporciona uma leitura mais intuitiva e otimizada. Essa estrutura é amplamente utilizada em análises de dados, especialmente em casos que exigem agrupamentos, buscas eficientes e associações diretas entre categorias e valores.
Além disso, recursos como defaultdict, get() com valor padrão e dictionary comprehensions elevam os dicionários a um nível avançado de performance e expressividade, permitindo escrever códigos mais curtos, robustos e preparados para lidar com dados reais, muitas vezes incompletos ou inconsistentes.
💡 “Se os dados fossem peças de LEGO, os dicionários seriam os conectores que estruturam tudo com lógica e agilidade.”
1.1 Operações Essenciais:
# Criação de dicionário com dados iniciais
cliente = {
'nome': 'Carlos',
'compras': [150, 220, 340]
}
# Atualização segura do dicionário com novos campos
cliente.update({
'idade': 35,
'status': 'premium'
})
# Acesso com valor padrão (evita erro se a chave não existir)
telefone = cliente.get('telefone', 'Não cadastrado')
# Exibição do resultado
print(f"Telefone do cliente: {telefone}")
1.2 Técnicas Avançadas:
Agrupamento com defaultdict
from collections import defaultdict
# Lista de vendas com tuplas (estado, valor)
vendas = [('SP', 1500), ('RJ', 800), ('SP', 2300)]
# Criação de dicionário com listas como valor padrão
por_estado = defaultdict(list)
# Agrupamento das vendas por estado
for estado, valor in vendas:
por_estado[estado].append(valor)
# Exibição do resultado
print(dict(por_estado)) # Saída: {'SP': [1500, 2300], 'RJ': [800]}
Dictionary Comprehension
# Listas de produtos e seus respectivos preços
produtos = ['Notebook', 'Tablet', 'Smartphone']
precos = [4500, 1500, 2800]
# Criação do dicionário com compreensão de dicionário (dict comprehension)
catalogo = {produto: preco for produto, preco in zip(produtos, precos)}
# Exibição do resultado
print(catalogo)
# Saída: {'Notebook': 4500, 'Tablet': 1500, 'Smartphone': 2800}
“Conjuntos – Enxugando Dados Repetidos com Classe”
2.1 Operações Fundamentais
# Conjuntos de usuários ativos em janeiro e fevereiro
usuarios_jan = {'user1', 'user2', 'user3'}
usuarios_fev = {'user3', 'user4', 'user5'}
# Identificar usuários novos em fevereiro (presentes apenas em fevereiro)
novos = usuarios_fev - usuarios_jan
print("Novos usuários em fevereiro:", novos)
# Saída: {'user4', 'user5'}
# Identificar usuários ativos em ambos os meses
ativos = usuarios_jan & usuarios_fev
print("Usuários ativos em ambos os meses:", ativos)
# Saída: {'user3'}
2.2 Aplicações Práticas
# Lista com dados duplicados
dados = [10, 20, 20, 30, 40, 40]
# Remoção de duplicatas preservando a ordem original
unicos = list(dict.fromkeys(dados))
print("Valores únicos:", unicos)
# Saída: [10, 20, 30, 40]
“List Comprehensions – Transformações em Uma Linha”
3.1 Transformações Complexas
# Lista original de números
numeros = [1, 2, 3, 4, 5, 6]
# Filtrar os números pares e calcular o quadrado de cada um
pares_quadrado = [x**2 for x in numeros if x % 2 == 0]
print("Quadrado dos números pares:", pares_quadrado)
# Saída: [4, 16, 36]
3.2 Fatiamento Avançado
# Lista de dados históricos
dados_historicos = [10, 15, 20, 25, 30, 35, 40]
# Cálculo da média móvel com janela de tamanho 2
medias = [(dados_historicos[i] + dados_historicos[i + 1]) / 2
for i in range(len(dados_historicos) - 1)]
print("Médias móveis:", medias)
# Saída: [12.5, 17.5, 22.5, 27.5, 32.5, 37.5]
“Funções Profissionais – Modularize e Analise com Clareza”
4.1 Padrões de Retorno:
def analise_estatistica(dados):
if not dados:
return {
'media': None,
'max': None,
'min': None,
'unique': 0
}
return {
'media': sum(dados) / len(dados),
'max': max(dados),
'min': min(dados),
'unique': len(set(dados))
}
# Exemplo de uso
amostra = [10, 20, 20, 30, 40]
resultado = analise_estatistica(amostra)
print(resultado)
# Saída: {'media': 24.0, 'max': 40, 'min': 10, 'unique': 4}
4.2 Funções como Objetos:
from functools import reduce
def aplicar_pipeline(dados, funcoes):
return [reduce(lambda v, f: f(v), funcoes, item) for item in dados]
# Uso:
resultado = aplicar_pipeline(
dados=[' info ', ' data '],
funcoes=[str.strip, str.upper, lambda x: x + '!']
)
print(resultado) # ['INFO!', 'DATA!']
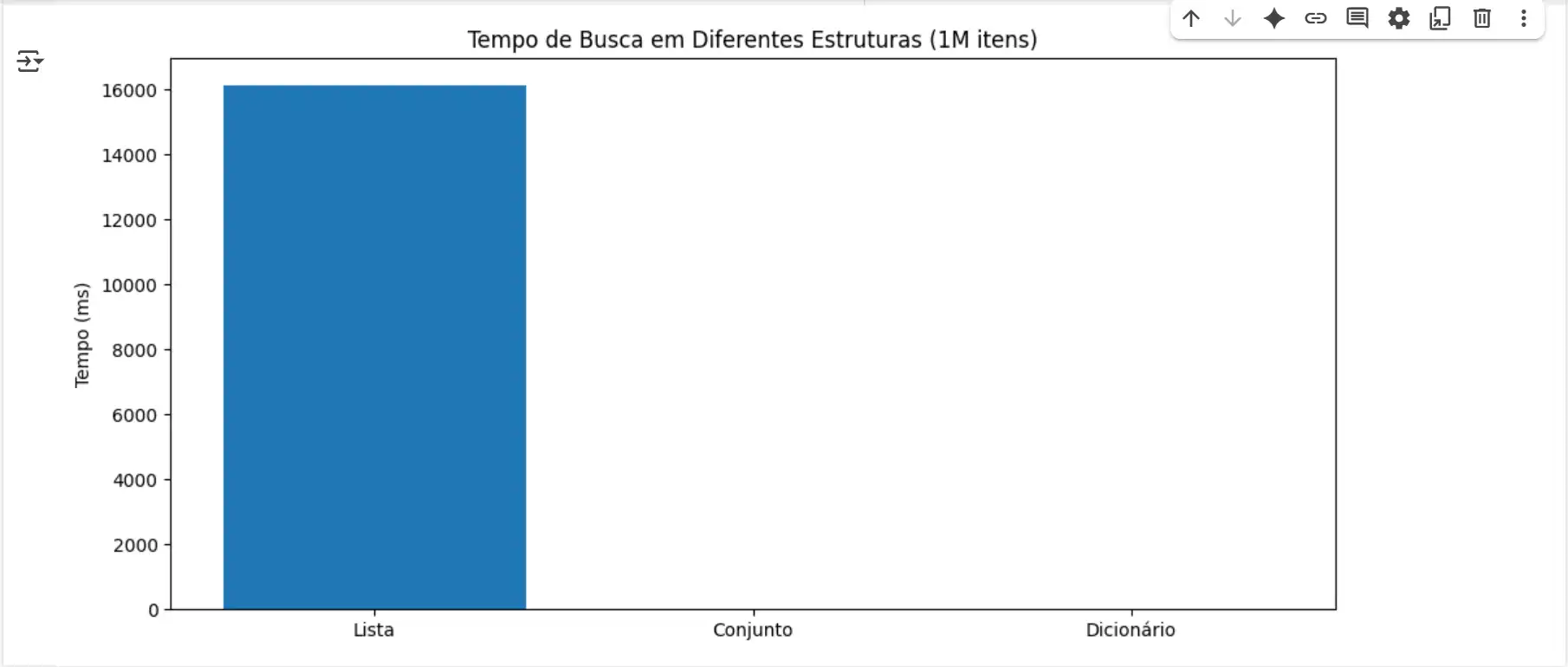
Comparativo de Performance:
import matplotlib.pyplot as plt
import timeit
tecnicas = {
'Lista': timeit.timeit(
"999999 in lista",
setup="lista = list(range(1000000))",
number=1000
),
'Conjunto': timeit.timeit(
"999999 in conjunto",
setup="conjunto = set(range(1000000))",
number=1000
),
'Dicionário': timeit.timeit(
"'chave' in dicio",
setup="dicio = {str(x): x for x in range(1000000)}",
number=1000
)
}
# Converter para milissegundos
tempos_ms = {k: v * 1000 for k, v in tecnicas.items()}
plt.figure(figsize=(10, 5))
plt.bar(tempos_ms.keys(), tempos_ms.values(), color=['#1f77b4', '#ff7f0e', '#2ca02c'])
plt.title('Tempo de Busca em Diferentes Estruturas (1M itens)')
plt.ylabel('Tempo (ms)')
plt.tight_layout()
plt.savefig('performance_estruturas.png', dpi=120)
plt.show()
Projeto Prático: Análise de Vendas:
from collections import defaultdict
# 1. Agrupar vendas por região
vendas = [('Norte', 150), ('Sul', 200), ('Norte', 180)]
totais = defaultdict(int)
for regiao, valor in vendas:
totais[regiao] += valor
# 2. Filtrar regiões com meta batida
meta = 300
atingiram = {k for k, v in totais.items() if v >= meta}
# 3. Gerar relatório
relatorio = {
'total_vendas': sum(totais.values()),
'top_regiao': max(totais.items(), key=lambda x: x[1])[0],
'atingiram_meta': len(atingiram)
}
print(relatorio)
Erros comuns:
# Exemplo de sobrescrita indesejada
dados = {}
dados['item'] = 100
dados['item'] = 200 # ⚠️ O valor anterior (100) foi perdido!
print(dados) # Saída: {'item': 200}
Solução: usar defaultdict para armazenar múltiplos valores
from collections import defaultdict
# Cria um dicionário onde cada valor é uma lista
dados = defaultdict(list)
dados['item'].append(100)
dados['item'].append(200)
print(dados) # Saída: defaultdict(<class 'list'>, {'item': [100, 200]})
Expandir o projeto final
import pandas as pd
# Lista de vendas por região
vendas = [('Norte', 150), ('Sul', 200), ('Norte', 180)]
# Transformar os dados em um DataFrame
df = pd.DataFrame(vendas, columns=['Região', 'Valor'])
# Exportar para arquivo CSV (sem índice)
df.to_csv('relatorio_vendas.csv', index=False)
print("✅ Relatório exportado com sucesso!")
Conclusão:
Dominar estruturas como dicionários, conjuntos, list comprehensions e funções avançadas em Python não é apenas uma vantagem técnica — é uma exigência estratégica para quem atua com dados. Segundo Raymond Hettinger, desenvolvedor do Python, “There should be one-- and preferably only one --obvious way to do it”. Ao adotar abordagens Pythonicas, você não só simplifica seu código como também otimiza seu desempenho.
🚀 Agora que você domina as estruturas fundamentais e avançadas do Python para dados, desafie-se: automatize um processo real, compartilhe seu código, e inspire outros analistas!
"A diferença entre um analista comum e um analista de elite está nas ferramentas que ele domina — e como ele as aplica."
📢 Continue aprendendo. Continue praticando. Continue Pythonizando. 🐍
Este guia mostrou como usar essas estruturas para:
- Organizar e agrupar informações com
defaultdict. - Eliminar redundâncias com
set. - Realizar transformações complexas com compreensões de listas.
- Construir funções reutilizáveis e pipelines analíticos.
📢 Próximos passos?
- 🔍 Baixe e explore nosso dataset prático: https://github.com/dados-para-treinamento/dataset-vendas
Agora que você domina as estruturas-chave do Python, está pronto para analisar dados de forma eficiente, legível e escalável.
Call to Action:
🎯 Desafio final: Pegue um dataset público, aplique tudo que aprendeu aqui e publique seu notebook no Kaggle com a hashtag #DataChallengePython. Marque a comunidade! 🚀
- Aprofunde-se com cursos completos: https://www.kaggle.com/
- Pesquisar dados: https://opendatasus.saude.gov.br/
- Experimente: Recrie o projeto prático com suas adaptações.
- Compartilhe: Poste no fórum com #DIODataStructures.
"Estas técnicas representam 80% das operações diárias em análise de dados profissional"
Referências:
- López, César Pérez. Técnicas Avançadas para Análise de Dados Multivariados Utilizando Python. Amazon Kindle Edition, 2021.
- McKinney, Wes. Python para Análise de Dados: Tratamento de dados com pandas, NumPy e Jupyter. 2ª Edição. Novatec, 2018.
- Python Software Foundation. Documentação Oficial do Python.
- Repositórios com exemplos no GitHub: https://github.com/





DIO Community Muito obrigada pelo feedback e pelas palavras generosas!
Na prática, o maior benefício está na capacidade de transformar código complexo em soluções simples, legíveis e altamente performáticas, permitindo que o analista gaste menos tempo com tarefas repetitivas e mais tempo com a geração de insights estratégicos.
Técnicas como list/dict comprehensions, uso de
defaultdicte estruturas comosetreduzem blocos extensos de código para poucas linhas claras e eficientes. Isso não só diminui a complexidade algorítmica, como aumenta a velocidade de execução em grandes volumes de dados, o que é essencial para análises em tempo real ou pipelines robustos de ETL.Quando o código se torna uma extensão direta do raciocínio analítico, o profissional ganha agilidade, clareza e assertividade na descoberta de padrões e oportunidades — o que se traduz em decisões mais rápidas, precisas e impactantes.
Excelente, Mirtes! Seu artigo sobre Python para Análise de Dados: Domínio Completo de Estruturas e Técnicas é um guia definitivo e super prático. É fascinante ver como você aborda o Python como uma linguagem que, quando bem utilizada, reduz drasticamente o tempo gasto em limpeza e manipulação de dados.
Você demonstrou que dominar dicionários, conjuntos, list comprehensions e funções avançadas é como ter superpoderes na análise de dados, permitindo manipulação profissional e processamento otimizado de grandes volumes. Sua análise de operações essenciais, técnicas avançadas e o comparativo de performance, inspira a transformar a rotina analítica.
Considerando que "analistas de dados que dominam Python com profundidade ganham uma vantagem competitiva real", qual você diria que é o maior benefício para um profissional ao dominar essas estruturas e técnicas Pythonicas, em termos de redução da complexidade do código e aumento da performance na extração de insights?