


Quando usar listas, tuplas, conjuntos e dicionários em Python (sem decorar, entendendo a ideia)
1. Introdução
Em praticamente todo projeto em Python, mais cedo ou mais tarde você acaba lidando com coleções de dados: uma lista de pedidos, um dicionário de configurações, um conjunto de permissões ou uma tupla com coordenadas que não deveriam mudar. Essas quatro estruturas – listas, tuplas, conjuntos e dicionários – formam a base da forma como Python organiza informação na memória, e entender bem quando usar cada uma delas faz diferença direta em legibilidade, performance e quantidade de bugs que você cria no dia a dia.
O problema é que, nos bootcamps e cursos introdutórios, a gente quase sempre aprende a sintaxe (“como criar” e “como adicionar elementos”), mas raramente discute escolha de projeto: qual coleção faz mais sentido para o meu caso de uso? Resultado: muita gente usa lista para tudo, ignora tuplas, esquece que conjuntos existem e só lembra de dicionários quando precisa “guardar coisa com chave”. Este artigo tem como objetivo justamente preencher essa lacuna, mostrando, com exemplos práticos e comparações diretas, quando faz mais sentido optar por listas, tuplas, conjuntos ou dicionários em Python, para que essa decisão deixe de ser chute e passe a ser uma escolha consciente de design.
2. Visão geral rápida
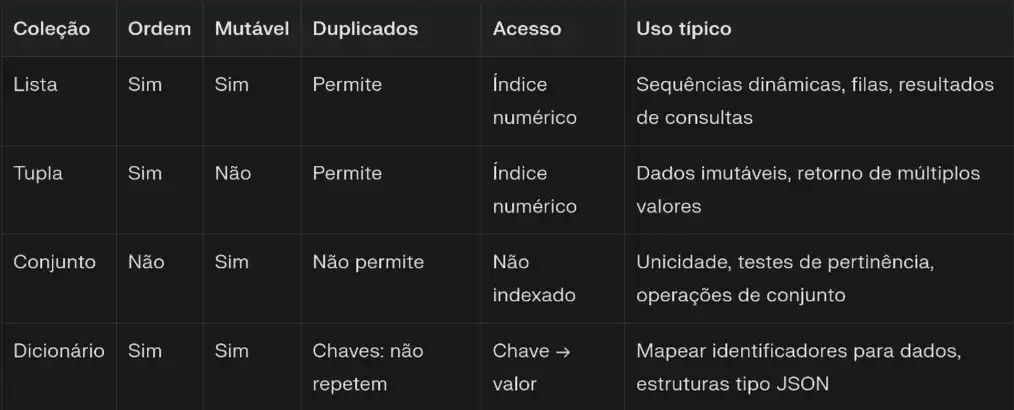
Antes de mergulhar em cada tipo separadamente, vale ter uma visão geral das principais características de listas, tuplas, conjuntos e dicionários em Python. Essa comparação rápida ajuda a enxergar o “perfil” de cada coleção e já dá uma pista forte de qual delas faz mais sentido em diferentes cenários de projeto.
A tabela a seguir resume propriedades importantes como ordem, mutabilidade, suporte a duplicados, forma de acesso aos elementos e usos típicos no dia a dia. A partir dela, o restante do artigo aprofunda cada tipo com exemplos práticos, boas práticas e armadilhas comuns, para que a escolha deixe de ser automática (“sempre lista”) e passe a ser uma decisão consciente.
3. Listas: o canivete suíço do dia a dia
Listas são, provavelmente, a estrutura de dados mais usada em Python, justamente por serem extremamente flexíveis: mantêm a ordem de inserção, permitem elementos duplicados e podem ser modificadas a qualquer momento (adicionando, removendo ou alterando itens). Isso faz com que sejam a escolha natural para representar sequências dinâmicas, como resultados de consultas, filas simples de processamento ou coleções de objetos que vão mudar ao longo da execução do programa.
Na prática, listas aparecem em praticamente todo tipo de projeto: da lista de registros retornados do banco de dados em um backend, passando por listas de eventos em sistemas de monitoramento, até coleções de amostras em scripts de ciência de dados. Esse poder vem com algumas responsabilidades: como são mutáveis e passadas por referência, modificações “sem querer” dentro de funções podem causar bugs difíceis de rastrear; além disso, usar listas para tudo (inclusive quando só se precisa de unicidade ou de acesso por chave) pode tornar o código menos expressivo e mais custoso do que o necessário. Por isso, entender onde listas brilham – e onde outra coleção seria uma escolha mais adequada – é fundamental para escrever código mais claro, eficiente e fácil de manter.
Quando usar listas
Listas são uma ótima escolha quando se precisa de uma sequência ordenada de elementos que pode crescer, encolher ou ter itens alterados durante a execução do programa. Exemplos típicos incluem: resultados de uma query no banco de dados, uma fila simples de tarefas a serem processadas ou uma coleção de objetos que será percorrida em loops e filtrada com list comprehensions.
Exemplo – resultados de consulta no backend:
# resultado de uma busca de usuários no banco
usuarios = [
{"id": 1, "nome": "Ana"},
{"id": 2, "nome": "Bruno"},
{"id": 3, "nome": "Carla"},
]
# filtrar apenas usuários com id > 1
usuarios_filtrados = [u for u in usuarios if u["id"] > 1]
print(usuarios_filtrados)
# [{'id': 2, 'nome': 'Bruno'}, {'id': 3, 'nome': 'Carla'}]
Exemplo – fila simples de tarefas em memória:
pytarefas = ["enviar_email", "gerar_relatorio", "atualizar_cache"]
# adiciona nova tarefa
tarefas.append("sincronizar_backup")
# processa tarefas na ordem
while tarefas:
tarefa_atual = tarefas.pop(0)
print("Processando:", tarefa_atual)
Exemplo – acumulando leituras de sensores:
leituras = []
def registrar_leitura(valor):
leituras.append(valor)
for valor in [10.2, 10.5, 10.3, 10.9]:
registrar_leitura(valor)
media = sum(leituras) / len(leituras)
print("Média das leituras:", media)
Quando não usar listas
Listas não são a melhor escolha quando a unicidade dos elementos é o requisito principal ou quando o acesso mais comum não é por posição, mas por algum identificador mais expressivo. Se a pergunta natural do código é “esse item já existe aqui dentro?”, um conjunto tende a ser mais apropriado; se a pergunta é “qual o valor associado a esta chave?”, um dicionário comunica melhor a intenção do que uma lista de pares.
Exemplo ruim – usando lista onde um conjunto seria melhor:
# RUIM: usando lista para checar duplicade
emails_processados = []
def processar_email(email):
if email in emails_processados:
return # já foi processado
emails_processados.append(email)
print("Processando:", email)
Versão melhor com conjunto:
# MELHOR: Utilizando conjunto para garantir unicidade
emails_processados = set()
def processar_email(email):
if email in emails_processados:
return
emails_processados.add(email)
print("Processando:", email)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Exemplo ruim – usando lista para dados imutáveis:
# RUIM: ponto como lista
ponto = [10, 20]
# em outro lugar do código alguém altera
ponto[0] = 999 # muda "sem querer" a coordenada
Versão melhor com tupla:
# MELHOR: ponto como tupla imutável
ponto = (10, 20)
# qualquer tentativa de alterar gera erro
# ponto[0] = 999 # TypeError
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Exemplo ruim – lista de pares:
# RUIM: Utilizar listas para chave:valor
status = [
(200, "OK"),
(404, "Não encontrado"),
(500, "Erro interno"),
]
def mensagem_status(codigo):
for c, msg in status:
if c == codigo:
return msg
return "Desconhecido"
Versão melhor com dicionário:
# MELHOR: Utlizando dicionários para arquitetura chave:valor
status = {
200: "OK",
404: "Não encontrado",
500: "Erro interno",
}
def mensagem_status(codigo):
return status.get(codigo, "Desconhecido")
4. Tuplas: quando “não mudar” é uma vantagem
Tuplas são sequências ordenadas como listas, mas com uma diferença crucial: são imutáveis, ou seja, depois de criadas, não é possível adicionar, remover ou alterar elementos. Isso faz delas uma ótima escolha quando se quer deixar explícito no código que determinados dados formam um “pacote” que não deve ser modificado, como coordenadas, parâmetros fixos ou constantes agrupadas.
Outra consequência interessante da imutabilidade é que tuplas podem ser usadas como chaves em dicionários (ao contrário de listas), o que abre espaço para modelar combinações de valores como identificadores, por exemplo (método, rota) ou (linha, coluna) em um tabuleiro. Isso torna o código mais expressivo e reduz o risco de alterações acidentais em estruturas que deveriam permanecer estáveis durante toda a execução.
Quando usar tuplas
Use tuplas quando os dados formam uma unidade lógica que não deve mudar após ser criada: coordenadas, ranges fixos, parâmetros de configuração, retornos de função que agrupam múltiplos valores, etc. Essa escolha também comunica de forma clara, para quem lê o código, que aquela sequência é conceitualmente imutável.
Exemplo – coordenadas e tamanhos fixos:
resolucao_tela = (1920, 1080)
posicao_inicial = (10, 20)
largura, altura = resolucao_tela
x, y = posicao_inicial
print(largura, altura) # 1920 1080
print(x, y) # 10 20
Exemplo – retorno de múltiplos valores:
def dividir(dividendo, divisor):
if divisor == 0:
return (False, None)
return (True, dividendo / divisor)
sucesso, resultado = dividir(10, 2)
if sucesso:
print("Resultado:", resultado)
else:
print("Divisão inválida")
Exemplo – usando tupla como chave de dicionário:
# chave = (método HTTP, rota)
estatisticas = {
("GET", "/users"): 120,
("POST", "/users"): 15,
("GET", "/status"): 50,
}
print(estatisticas[("GET", "/users")]) # 120
Quando não usar tuplas
Tuplas não são uma boa escolha quando você sabe que a coleção vai mudar com o tempo – por exemplo, uma lista de tarefas em fila, um conjunto de registros sendo atualizado ou qualquer sequência em que serão feitas inserções e remoções. Nesses casos, usar tupla só vai atrapalhar, porque toda alteração exigirá criar uma nova tupla, enquanto uma lista resolve o problema de forma direta e mais legível.
Exemplo ruim – tentando usar tupla em uma sequência dinâmica:
# RUIM: sequência que muda o tempo todo como tupla
tarefas = ("enviar_email", "gerar_relatorio")
# para "adicionar" algo, você precisa criar outra tupla
tarefas = tarefas + ("atualizar_cache",)
Versão melhor com lista:
tarefas = ["enviar_email", "gerar_relatorio"]
tarefas.append("atualizar_cache")
5. Conjuntos: garantindo unicidade de forma eficiente
Conjuntos (set) representam coleções não ordenadas de elementos únicos, ou seja, não aceitam valores duplicados e não oferecem acesso por índice, apenas por pertinência (“este elemento está aqui dentro?”). Isso faz deles uma estrutura excelente para problemas em que a unicidade é o requisito central, como remover duplicados de uma lista, rastrear itens já processados ou trabalhar com operações de teoria dos conjuntos (união, interseção, diferença).
Além disso, a verificação de pertencimento (x in meu_set) costuma ser bem mais eficiente em conjuntos do que em listas, o que é relevante em cenários como filtragem de grande volume de dados, controle de acesso ou detecção de itens repetidos em fluxos de eventos. Por outro lado, como não preservam ordem e não permitem acesso posicional, conjuntos não são adequados quando a sequência ou a posição de cada elemento importam para a lógica do programa.
Quando usar conjuntos
Conjuntos são ideais quando a pergunta principal é “esse elemento já apareceu?” ou quando se deseja modelar relações de pertencimento entre grupos, como usuários de dois sistemas, permissões de perfis diferentes ou categorias associadas a um item.
Exemplo – removendo duplicados de uma lista de emails:
emails = [
"ana@example.com",
"bruno@example.com",
"ana@example.com",
"carla@example.com",
]
emails_unicos = set(emails)
print(emails_unicos)
# {'bruno@example.com', 'carla@example.com', 'ana@example.com'}
Exemplo – checando se um usuário já foi processado:
usuarios_processados = set()
def processar_usuario(user_id):
if user_id in usuarios_processados:
return # já foi processado
usuarios_processados.add(user_id)
print("Processando usuário:", user_id)
for uid in [1, 2, 1, 3, 2]:
processar_usuario(uid)
Exemplo – operações de conjunto em permissões:
permissoes_admin = {"criar", "ler", "atualizar", "deletar"}
permissoes_editor = {"ler", "atualizar"}
permissoes_comuns = permissoes_admin & permissoes_editor # interseção
print(permissoes_comuns) # {'ler', 'atualizar'}
Quando não usar conjuntos
Conjuntos não são adequados quando a ordem dos elementos é importante, como em filas, listas ordenadas por data ou sequências em que a posição carrega significado (primeiro, segundo, último). Nesse tipo de situação, usar set pode gerar resultados inesperados e confusos, já que a estrutura não garante nenhuma ordem específica ao iterar.
Exemplo ruim – tentando manter uma fila com set:
# RUIM: tentando usar conjunto como fila
fila = {"ana", "bruno", "carla"}
for pessoa in fila:
print("Atendendo:", pessoa) # a ordem é imprevisível
Versão melhor com lista:
fila = ["ana", "bruno", "carla"]
while fila:
pessoa = fila.pop(0)
print("Atendendo:", pessoa)
6. Dicionários: mapeando chaves para valores
Dicionários são estruturas que armazenam pares chave → valor, permitindo acessar rapidamente um dado a partir de um identificador significativo, como id, email, cpf ou uma rota de API. Essa ideia de “mapa” torna dicionários extremamente úteis para representar entidades do mundo real (usuários, pedidos, produtos), configurações, caches em memória e qualquer situação em que se queira ir direto ao valor certo sem percorrer toda a coleção.
Outra característica importante é que chaves precisam ser únicas e, em geral, imutáveis (strings, números, tuplas imutáveis), enquanto os valores podem ser de qualquer tipo: listas, outros dicionários, objetos, etc. Isso permite construir estruturas aninhadas parecidas com JSON, comuns em APIs REST e aplicações web, além de tabelas de roteamento (“comando → função”) e índices rápidos em dados que, de outra forma, exigiriam buscas lineares em listas.
Quando usar dicionários
Use dicionários sempre que a pergunta natural do código for “qual é o valor associado a esta chave?” ou quando se quer acessar diretamente um elemento sem depender de posição.
Exemplo – representando um usuário:
usuario = {
"id": 1,
"nome": "Ana",
"email": "ana@example.com",
"ativo": True,
}
print(usuario["nome"]) # Ana
print(usuario["email"]) # ana@example.com
Exemplo – índice rápido de usuários por id:
usuarios = {
1: {"nome": "Ana", "email": "ana@example.com"},
2: {"nome": "Bruno", "email": "bruno@example.com"},
3: {"nome": "Carla", "email": "carla@example.com"},
}
user_id = 2
if user_id in usuarios:
print("Encontrado:", usuarios[user_id]["nome"])
Exemplo – tabela de roteamento simples (comando → função):
def criar():
print("Criando recurso...")
def listar():
print("Listando recursos...")
acoes = {
"criar": criar,
"listar": listar,
}
comando = "listar"
acao = acoes.get(comando)
if acao:
acao()
else:
print("Comando inválido")
Quando não usar dicionários
Dicionários não são a melhor escolha quando a ordem dos elementos e sua posição relativa são mais importantes do que a associação chave → valor, como em listas ordenadas, filas ou sequências em que “primeiro” e “último” têm significado central.
Exemplo ruim – usando dicionário para algo que é claramente uma lista ordenada:
# RUIM: tentando representar uma fila com dicionário
fila = {
0: "ana",
1: "bruno",
2: "carla",
}
# para remover o primeiro, precisa gerenciar índices manualmente
primeiro = fila.pop(0)
Versão melhor com lista:
fila = ["ana", "bruno", "carla"]
primeiro = fila.pop(0)
7. Como escolher: listas, tuplas, conjuntos ou dicionários?
Depois de entender cada coleção isoladamente, o passo mais importante é transformar esse conhecimento em critério prático: dado um problema concreto, como decidir rapidamente qual estrutura usar? A ideia desta seção é funcionar como um “guia mental” para ajudar a responder essa pergunta de forma consistente no dia a dia.
Perguntas rápidas para decidir
Um jeito eficiente de escolher é responder, em ordem, a algumas perguntas simples:
- Precisa de ordem e vai modificar a coleção (adicionar/remover/alterar elementos)?
- Use uma lista.
- Os dados formam um “pacote” que não deveria mudar depois de criado (coordenadas, parâmetros fixos, retorno de função)?
- Use uma tupla.
- A preocupação principal é unicidade (sem duplicados) e verificações do tipo “X já apareceu?” ou operações de união/interseção?
- Use um conjunto (
set). - A pergunta natural do código é “qual valor está associado a esta chave?” (id → usuário, código → descrição, rota → handler)?
- Use um dicionário.
Essas perguntas cobrem a maior parte dos cenários de uso em aplicações reais, evitando o reflexo automático de “usar lista para tudo” e forçando a pensar na intenção semântica de cada coleção.
Mini-cenários práticos
Abaixo, alguns cenários típicos mostrando como combinar essas coleções em problemas do mundo real.
Exemplo – sistema simples de requisições HTTP:
- Lista para guardar o histórico de requisições na ordem em que chegaram.
- Dicionário para mapear
idde requisição → dados detalhados (headers, body). - Conjunto para rastrear IPs que já foram vistos ou bloqueados.
- Tupla para representar pares imutáveis como
(método, rota)em uma tabela de estatísticas.
Exemplo – fluxo de dados em pequeno ETL:
- Lista de registros lidos de um CSV ou API.
- Conjunto de chaves já processadas, para evitar duplicidade.
- Dicionário para agrupar resultados por categoria (
categoria -> métricas). - Tupla para representar chaves compostas imutáveis, como
(ano, mês)em uma agregação.
Quando esses padrões começam a ficar naturais, a escolha da coleção deixa de ser detalhe de implementação e passa a ser parte da modelagem do problema, o que leva a códigos mais claros, eficientes e alinhados com a intenção de quem está escrevendo.
8. Conclusão e próximos passos
Escolher entre listas, tuplas, conjuntos e dicionários não é apenas uma questão de sintaxe, mas uma decisão de modelagem: cada coleção comunica uma intenção sobre como os dados serão usados, modificados e acessados. Quando essa intenção fica clara no código, ele se torna mais legível, menos propenso a bugs sutis e, em muitos casos, mais eficiente em termos de tempo de execução e uso de memória.
9. Referências
Documentação oficial do Python – seção sobre tipos de dados embutidos, incluindo listas, tuplas, conjuntos e dicionários, que detalha comportamento, métodos e exemplos de uso.
Materiais introdutórios sobre coleções em Python (listas, tuplas, conjuntos e dicionários) utilizados em cursos e trilhas de formação focadas em estruturas de dados e boas práticas na linguagem.






