
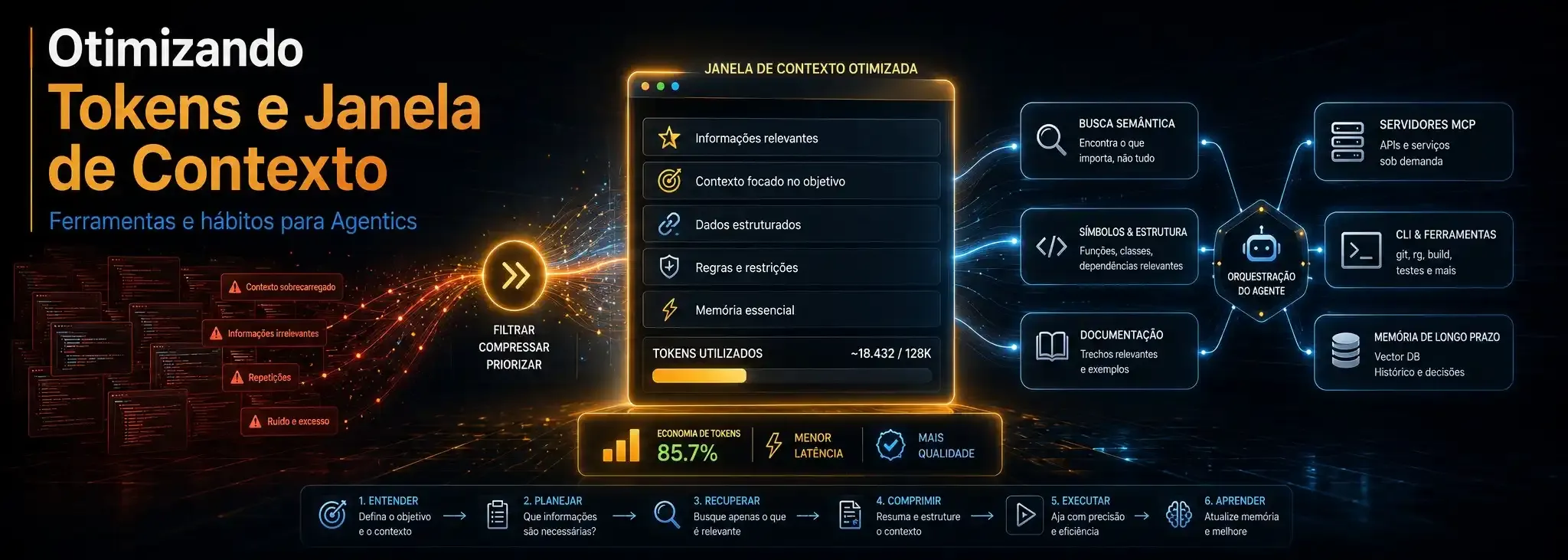

Você está desperdiçando sua janela de contexto: 11 ferramentas e 12 hábitos para usar agentes de IA
À medida que ferramentas como Claude Code, Codex, Gemini CLI, Cursor, Windsurf, Cline, OpenCode e outros agentes de programação se tornam parte do cotidiano dos desenvolvedores, surge um problema que nem sempre é percebido imediatamente: o desperdício da janela de contexto.
Não basta utilizar um modelo com centenas de milhares — ou até milhões — de tokens disponíveis. Quando um agente lê arquivos inteiros desnecessariamente, recebe enormes saídas de terminal, carrega documentação repetida ou mantém instruções obsoletas durante toda a sessão, grande parte dessa capacidade é consumida antes mesmo de o trabalho realmente começar.
O problema não é apenas financeiro. Uma janela de contexto mal utilizada pode provocar:
- aumento da latência;
- perda de informações relevantes;
- respostas mais genéricas;
- repetição de análises;
- compactações frequentes da conversa;
- dificuldade para o agente distinguir o essencial do ruído;
- maior consumo de tokens de entrada e saída;
- sessões que degradam rapidamente em projetos extensos.
Portanto, economizar tokens não significa simplesmente pedir respostas menores. Significa construir uma arquitetura de contexto na qual o agente receba a informação certa, no momento certo e na quantidade necessária.
As ferramentas apresentadas a seguir atuam em diferentes pontos desse problema: recuperação de código, documentação, memória, compactação de resultados, conversão de documentos, empacotamento de repositórios, observabilidade de custos e análise estrutural.
A janela de contexto não é uma memória infinita
A janela de contexto pode ser entendida como a área de trabalho temporária do modelo. Nela são colocados:
- o prompt de sistema;
- as instruções do projeto;
- o histórico da conversa;
- as definições das ferramentas;
- os resultados retornados por ferramentas;
- trechos de código;
- documentação;
- mensagens de erro;
- logs;
- planos e respostas anteriores.
Mesmo quando o limite nominal parece muito grande, cada item compete pela atenção do modelo.
Um arquivo com três mil linhas pode ser tecnicamente aceito pelo contexto, mas isso não significa que deveria ser carregado. Se o problema está em uma única função, o ideal é recuperar aquela função, seus chamadores, suas dependências e os testes relacionados — não o arquivo completo, muito menos todo o repositório.
Essa diferença separa dois modelos de trabalho:
Contexto por acumulação
Tudo é carregado antecipadamente, na esperança de que alguma parte seja útil.
Contexto por recuperação
O agente começa com uma visão mínima e consulta informações adicionais conforme a tarefa exige.
Para sistemas agênticos, o segundo modelo tende a ser mais eficiente. É justamente nele que servidores MCP, índices semânticos, grafos de código e ferramentas de compactação se tornam importantes.
1. Serena: navegação e edição no nível dos símbolos
O Serena funciona como uma camada de inteligência de código para agentes. Em vez de limitar o modelo à leitura bruta de arquivos e buscas textuais, ele fornece operações semelhantes às encontradas em uma IDE.
O agente pode trabalhar com elementos estruturais como:
- classes;
- funções;
- métodos;
- interfaces;
- referências;
- símbolos;
- relações entre componentes.
Isso permite solicitar algo como “localize o método responsável pela validação do token” sem obrigar o modelo a ler todos os arquivos do módulo.
Em projetos extensos, essa abordagem reduz a necessidade de despejar grandes blocos de código no contexto. Além da recuperação, o Serena oferece recursos para edição, refatoração e depuração orientados pela estrutura do programa.
Apesar de ser frequentemente associado ao Claude Code, ele utiliza o Model Context Protocol e pode ser integrado a diferentes clientes e modelos compatíveis com MCP.
Projeto oficial:
https://github.com/oraios/serena
Documentação:
https://oraios.github.io/serena/
Quando utilizar
O Serena é especialmente interessante para:
- monorepositórios;
- código legado;
- projetos com muitas classes e módulos;
- refatorações;
- localização de referências;
- alterações que envolvem vários arquivos;
- agentes que precisam editar código com precisão estrutural.
2. Context7: documentação atualizada sob demanda
Uma causa comum de erros em código gerado por IA é a utilização de documentação desatualizada. O modelo pode conhecer uma versão anterior de uma biblioteca e sugerir métodos removidos, parâmetros modificados ou APIs que já não existem.
O Context7 recupera documentação e exemplos atualizados, incluindo informações específicas da versão da biblioteca. Em vez de inserir manualmente páginas inteiras de documentação no prompt, o agente consulta apenas o conteúdo necessário para resolver a tarefa.
Isso ajuda a combater dois problemas simultaneamente:
- alucinação de APIs;
- desperdício de contexto com documentação excessiva.
O projeto oferece integração por MCP e também modos baseados em CLI e skills, podendo ser usado em Claude Code, Cursor, Windsurf e outros ambientes de desenvolvimento assistido por IA.
Projeto oficial:
https://github.com/upstash/context7
Site oficial:
Quando utilizar
O Context7 é indicado quando o trabalho envolve:
- bibliotecas que mudam rapidamente;
- frameworks front-end;
- SDKs de serviços em nuvem;
- APIs com várias versões;
- migração entre versões;
- geração de exemplos técnicos;
- resolução de incompatibilidades.
3. Claude Context: busca semântica sobre o repositório
O nome pode sugerir exclusividade com o Claude, mas o Claude Context foi projetado como um plugin MCP que também pode servir a outros agentes compatíveis.
Sua principal função é indexar o código e permitir buscas semânticas. Em uma busca textual convencional, o desenvolvedor precisa conhecer aproximadamente o nome da classe, função ou variável. Na busca semântica, é possível procurar pelo significado.
Por exemplo:
Onde ocorre a renovação da sessão do usuário quando o token expira?
Mesmo que o código não contenha exatamente essas palavras, o sistema pode localizar funções semanticamente relacionadas.
A vantagem para a janela de contexto é clara: o agente recebe os trechos mais relevantes em vez de explorar repetidamente pastas, arquivos e resultados de pesquisa.
Projeto oficial:
https://github.com/zilliztech/claude-context
Quando utilizar
O Claude Context pode ser útil em:
- grandes bases de código;
- projetos pouco documentados;
- exploração de código desconhecido;
- localização de regras de negócio;
- análise de implementações distribuídas;
- repositórios com milhões de linhas;
- perguntas conceituais sobre a arquitetura.
4. Token Savior: navegação estrutural, memória e compactação
O Token Savior combina diferentes estratégias de economia de contexto em um servidor MCP.
Entre seus objetivos estão:
- navegação estrutural pelo código;
- consultas por símbolos;
- memória persistente entre sessões;
- compactação de saídas de comandos;
- análise de dependências;
- acompanhamento de alterações;
- redução da necessidade de reler arquivos completos.
A memória persistente é particularmente interessante. Sem ela, o agente pode precisar reconstruir decisões arquiteturais, convenções e descobertas sempre que uma nova sessão é iniciada.
Entretanto, memória não significa armazenar tudo. Uma memória eficiente deve preservar decisões, restrições e fatos duráveis, evitando guardar conversas inteiras sem critério.
Projeto oficial:
https://github.com/mibayy/token-savior
Quando utilizar
O Token Savior é adequado para:
- projetos acompanhados durante várias sessões;
- agentes que executam muitos comandos no terminal;
- investigação de dependências;
- tarefas incrementais;
- projetos em que o histórico das decisões precisa ser preservado.
5. Caveman: menos verbosidade na saída do modelo
Nem todo desperdício ocorre na entrada. Respostas excessivamente longas também consomem tokens, aumentam custos e ocupam a janela de contexto nas interações seguintes.
O Caveman é uma skill ou plugin que orienta o agente a responder de maneira extremamente concisa. Sua proposta é eliminar:
- introduções desnecessárias;
- repetições;
- explicações óbvias;
- frases cerimoniais;
- resumos que apenas repetem o que já foi dito;
- longas justificativas quando uma resposta direta seria suficiente.
Apesar do nome bem-humorado, a ideia técnica é válida: controlar a verbosidade é uma forma importante de gestão de contexto.
O projeto informa compatibilidade com Claude Code e diversos outros agentes, como Codex, Gemini, Cursor, Windsurf, Cline e Copilot.
Projeto oficial:
https://github.com/JuliusBrussee/caveman
Quando utilizar
O Caveman é útil para:
- sessões operacionais;
- correções rápidas;
- execução de tarefas bem especificadas;
- pipelines automáticos;
- agentes que retornam resultados para outros agentes;
- ambientes em que a saída será processada por software.
Ele deve ser utilizado com cautela em situações didáticas, revisões arquiteturais ou análises de segurança, nas quais uma explicação detalhada continua sendo importante.
6. Context Mode: grandes resultados fora da conversa
Ferramentas conectadas a agentes podem retornar volumes enormes de informação:
- logs;
- páginas HTML;
- snapshots do DOM;
- resultados de testes;
- respostas de APIs;
- listas de issues;
- diffs;
- relatórios;
- resultados de busca.
O Context Mode atua como uma camada intermediária. Em vez de enviar toda a saída diretamente para a janela do modelo, ele processa e armazena os dados externamente, utilizando recursos como SQLite, busca textual e ambientes de execução isolados.
O agente recebe resumos, referências ou os resultados de consultas específicas.
Essa arquitetura é semelhante a colocar documentos em um banco de dados e permitir que o agente faça perguntas sobre eles, em vez de colar todo o banco dentro da conversa.
Projeto oficial:
https://github.com/mksglu/context-mode
Página do projeto:
https://mksg.lu/blog/context-mode
Quando utilizar
O Context Mode pode trazer grande benefício para:
- automação de navegador;
- análise de logs;
- integração com GitHub;
- testes extensos;
- consultas a APIs;
- scraping;
- sistemas com muitos servidores MCP;
- agentes que produzem grandes saídas intermediárias.
7. Token Optimizer: encontrando os tokens invisíveis
Uma sessão pode consumir uma quantidade significativa de tokens antes mesmo da primeira solicitação do desenvolvedor.
Esse consumo inicial pode incluir:
- prompt de sistema;
- arquivos de instrução;
- definições de ferramentas MCP;
- skills;
- plugins;
- arquivos de memória;
- regras globais;
- configurações específicas do projeto.
O Token Optimizer procura tornar esse consumo visível. Sua finalidade é identificar componentes carregados automaticamente e ajudar o desenvolvedor a remover configurações redundantes, plugins desnecessários e instruções excessivas.
O termo “tokens fantasmas” representa justamente aquilo que ocupa contexto sem aparecer claramente na conversa.
Projeto oficial:
https://github.com/alexgreensh/token-optimizer
Quando utilizar
É recomendado principalmente quando:
- a sessão já começa com parte considerável do contexto ocupada;
- existem muitos servidores MCP instalados;
- diferentes plugins oferecem funções repetidas;
- o arquivo de instruções cresceu sem controle;
- há skills globais carregadas em todos os projetos;
- o agente perde desempenho rapidamente.
8. MarkItDown: documentos transformados em Markdown limpo
PDFs, documentos do Word, planilhas, apresentações e páginas HTML podem conter uma quantidade significativa de estruturas irrelevantes para um modelo de linguagem.
O MarkItDown, desenvolvido pela Microsoft, converte diferentes formatos para Markdown. O objetivo é produzir uma representação textual mais simples e apropriada para:
- indexação;
- análise;
- recuperação;
- processamento por LLMs;
- construção de bases RAG;
- entrada para agentes.
Markdown não elimina automaticamente todo o desperdício, mas normalmente é uma representação mais previsível do que formatos binários ou documentos carregados por ferramentas que retornam metadados e estruturas internas extensas.
Projeto oficial:
https://github.com/microsoft/markitdown
Pacote Python:
https://pypi.org/project/markitdown/
Quando utilizar
O MarkItDown é indicado para:
- manuais em PDF;
- especificações DOCX;
- apresentações PPTX;
- planilhas XLSX;
- páginas HTML;
- documentação corporativa;
- construção de índices semânticos;
- preparação de documentos para RAG.
9. Repomix: empacotamento controlado de repositórios
O Repomix transforma um repositório em um arquivo preparado para consumo por modelos de linguagem. Ele pode gerar formatos como:
- XML;
- Markdown;
- JSON;
- texto simples.
A ferramenta também apresenta recursos para:
- contar ou estimar tokens;
- selecionar arquivos com padrões;
- ignorar diretórios;
- remover conteúdo desnecessário;
- comprimir representações de código;
- incluir a estrutura de diretórios;
- processar repositórios remotos.
Seu uso exige critério. Empacotar todo o repositório em um único arquivo não significa que todo esse conteúdo deva ser colocado diretamente no prompt.
O maior benefício surge quando o Repomix é utilizado com filtros, exclusões e compressão, produzindo uma visão controlada do projeto para tarefas específicas.
Projeto oficial:
https://github.com/yamadashy/repomix
Site oficial:
Quando utilizar
O Repomix é especialmente útil para:
- fornecer uma visão inicial da arquitetura;
- compartilhar código com um modelo sem integração direta ao repositório;
- preparar material para revisão;
- gerar documentação;
- construir um artefato para RAG;
- analisar um repositório remoto;
- estimar o custo de contexto antes do envio.
Diretórios como node_modules, builds, dependências vendorizadas, arquivos gerados e grandes dados de teste devem normalmente ser excluídos.
10. ccusage: observabilidade de tokens e custos
Não é possível otimizar adequadamente aquilo que não é medido.
O ccusage analisa dados locais de diferentes ferramentas de programação assistida por IA e apresenta informações como:
- tokens de entrada;
- tokens de saída;
- criação de cache;
- leitura de cache;
- uso por sessão;
- uso diário ou mensal;
- custos estimados;
- consumo por modelo;
- ritmo de utilização.
Embora tenha surgido muito associado ao Claude Code, o projeto passou a abranger outras ferramentas, incluindo Codex, OpenCode, Gemini CLI, GitHub Copilot CLI e diferentes agentes de programação.
Ele não reduz tokens diretamente. Sua função é tornar o consumo observável, permitindo comparar fluxos de trabalho e identificar sessões anormalmente caras.
Projeto oficial:
https://github.com/ryoppippi/ccusage
Documentação e site:
Quando utilizar
O ccusage deve ser considerado quando:
- há cobrança por API;
- diferentes modelos são utilizados;
- o desenvolvedor deseja avaliar cache;
- uma equipe precisa acompanhar custos;
- várias ferramentas agênticas são utilizadas;
- é necessário comparar estratégias de contexto.
11. Code Review Graph: um grafo estrutural do código
O Code Review Graph constrói um mapa persistente do repositório utilizando análise estrutural. Em vez de tratar cada arquivo como um bloco isolado, ele identifica relações entre componentes.
Esse grafo pode representar:
- símbolos;
- chamadas;
- importações;
- dependências;
- arquivos afetados;
- relações entre módulos;
- impacto potencial de uma alteração.
Diante de uma modificação, o agente pode consultar o grafo para descobrir quais partes do sistema são relevantes. Isso evita a leitura indiscriminada do repositório durante revisões e análises de impacto.
O projeto oferece interfaces MCP e CLI e adota uma abordagem local, mantendo o índice do código no ambiente do desenvolvedor.
Projeto oficial:
https://github.com/tirth8205/code-review-graph
Site oficial:
https://code-review-graph.com/
Quando utilizar
A ferramenta é adequada para:
- revisão de pull requests;
- análise de impacto;
- projetos com dependências complexas;
- arquiteturas em camadas;
- localização de chamadores;
- investigação de efeitos colaterais;
- grandes repositórios;
- agentes responsáveis por revisão contínua.
Essas ferramentas não são exclusivas do Claude
Muitos desses projetos nasceram no ecossistema do Claude Code ou utilizam seu nome na descrição. No entanto, há três categorias de integração que ampliam sua utilização:
Model Context Protocol
Servidores MCP expõem ferramentas padronizadas que podem ser chamadas por diferentes clientes compatíveis.
Ferramentas de linha de comando
Uma CLI pode ser executada diretamente pelo desenvolvedor ou por qualquer agente que tenha acesso controlado ao terminal.
Skills e arquivos de instrução
Skills podem ser adaptadas para agentes capazes de carregar instruções ou executar fluxos de trabalho locais.
Por isso, os conceitos apresentados são aplicáveis a diferentes ecossistemas:
- Claude Code;
- OpenAI Codex;
- Gemini CLI;
- Cursor;
- Windsurf;
- Cline;
- OpenCode;
- GitHub Copilot;
- agentes desenvolvidos com LangChain;
- LangGraph;
- CrewAI;
- AutoGen;
- Agno;
- sistemas agênticos personalizados.
O ponto mais importante não é instalar todas as ferramentas. É compreender qual problema de contexto cada uma resolve.
Uma arquitetura prática para uso conjunto
As ferramentas podem ser organizadas em camadas.
Camada 1 — Preparação das fontes
Utilize:
- MarkItDown para converter documentos;
- Repomix para preparar visões controladas do repositório.
Camada 2 — Recuperação contextual
Utilize:
- Serena para navegação por símbolos;
- Claude Context para busca semântica;
- Context7 para documentação;
- Code Review Graph para relações estruturais;
- Token Savior para navegação e memória.
Camada 3 — Controle das saídas
Utilize:
- Context Mode para manter grandes resultados fora da conversa;
- Caveman ou regras de concisão para reduzir a verbosidade.
Camada 4 — Diagnóstico e governança
Utilize:
- Token Optimizer para descobrir sobrecarga inicial;
- ccusage para medir tokens e custos.
Não é necessário instalar todas as soluções simultaneamente. Na realidade, isso poderia aumentar a quantidade de definições MCP carregadas e produzir o efeito contrário.
Uma configuração inicial equilibrada poderia conter:
- uma ferramenta de navegação estrutural;
- uma fonte de documentação atualizada;
- uma ferramenta de observabilidade;
- uma estratégia para resultados extensos.
12 hábitos gratuitos para preservar a janela de contexto
Ferramentas ajudam, mas boa parte da economia vem da disciplina do desenvolvedor.
1. Comece cada sessão com um objetivo definido
Evite iniciar com pedidos amplos como:
Analise todo o projeto e diga o que pode ser melhorado.
Prefira:
Analise o fluxo de autenticação, começando pelo endpoint /login. Identifique apenas vulnerabilidades e problemas de tratamento de erro.2. Peça um mapa antes de pedir a leitura
Antes de carregar arquivos completos, solicite:
- árvore resumida de diretórios;
- principais módulos;
- símbolos públicos;
- dependências;
- pontos de entrada.
Depois selecione o que realmente precisa ser lido.
3. Leia símbolos antes de ler arquivos
Uma função, classe ou interface geralmente custa muito menos contexto que o arquivo inteiro.
A sequência ideal costuma ser:
- localizar o símbolo;
- ler sua assinatura;
- identificar referências;
- carregar a implementação;
- consultar dependências somente quando necessário.
4. Separe descoberta de implementação
Não misture exploração arquitetural, implementação, testes e documentação em um único prompt.
Uma sequência mais eficiente seria:
- localizar o problema;
- propor uma correção;
- implementar;
- testar;
- documentar.
5. Limite saídas de terminal
Evite enviar milhares de linhas de logs.
Utilize comandos como:
tail -n 100 application.log
grep -n "ERROR" application.log | tail -n 50
journalctl -u minha-aplicacao --since "10 minutes ago" --no-pager
Solicite primeiro as linhas relevantes e amplie a busca apenas quando necessário.
6. Mantenha arquivos de instrução pequenos
Arquivos como CLAUDE.md, AGENTS.md e equivalentes não devem virar manuais completos do projeto.
Mantenha neles apenas:
- comandos essenciais;
- convenções obrigatórias;
- restrições arquiteturais;
- caminhos importantes;
- critérios de validação.
Documentação extensa deve permanecer em arquivos consultados sob demanda.
7. Não carregue todas as ferramentas em todas as sessões
Cada servidor MCP pode adicionar definições de ferramentas ao contexto.
Crie perfis por atividade:
- desenvolvimento;
- revisão;
- documentação;
- banco de dados;
- automação de navegador;
- infraestrutura.
Ative apenas o necessário para a tarefa atual.
8. Defina um orçamento de saída
É possível estabelecer limites como:
Responda em até cinco tópicos.
Não repita o código completo; apresente somente o diff.
Mostre apenas arquivos alterados.
Explique somente decisões que não sejam evidentes pelo código.
Isso reduz a verbosidade sem impedir análises profundas.
9. Salve decisões, não conversas completas
Uma memória útil deve registrar fatos como:
- PostgreSQL foi escolhido como banco principal;
- o sistema utiliza autenticação JWT;
- alterações públicas precisam preservar compatibilidade;
- testes são executados com determinado comando.
Não é necessário preservar todos os diálogos que levaram a essas decisões.
10. Reinicie sessões quando o objetivo mudar
Uma sessão usada para investigar um problema de banco de dados pode carregar informações inúteis quando o trabalho passa para a interface gráfica.
Ao mudar significativamente de domínio, considere iniciar uma nova sessão com um resumo mínimo das decisões relevantes.
11. Solicite diffs em vez de arquivos completos
Depois que o agente altera um arquivo, peça:
Mostre somente as linhas modificadas e o contexto mínimo necessário.
Isso reduz tokens de saída e facilita a revisão humana.
12. Meça antes e depois
Registre:
- tokens utilizados;
- duração da sessão;
- número de chamadas;
- frequência de compactação;
- custo estimado;
- quantidade de arquivos lidos;
- taxa de correções aceitas.
A otimização deve ser avaliada com dados, não apenas pela sensação de que o agente está respondendo mais rápido.
O risco de instalar tudo sem critério
Existe uma contradição importante: ferramentas criadas para economizar contexto também podem consumir contexto.
Cada plugin pode adicionar:
- instruções;
- hooks;
- ferramentas;
- descrições;
- memórias;
- resultados;
- processos auxiliares.
Portanto, instalar onze ferramentas simultaneamente não representa necessariamente a melhor configuração.
Antes de adicionar uma ferramenta, pergunte:
- Qual problema específico ela resolve?
- Já existe outra ferramenta realizando a mesma função?
- Quanto contexto sua própria definição consome?
- Ela funciona no meu agente?
- Os dados permanecem locais ou são enviados para serviços externos?
- O projeto está ativo e possui documentação?
- Posso desativá-la quando não estiver em uso?
Em ambientes profissionais, também é necessário avaliar:
- licença;
- telemetria;
- segurança da cadeia de dependências;
- acesso ao código-fonte;
- execução de comandos;
- permissões;
- armazenamento de dados;
- possibilidade de prompt injection;
- política da empresa.
Economizar tokens é praticar engenharia de contexto
Durante algum tempo, a discussão sobre modelos generativos ficou concentrada na engenharia de prompts. Entretanto, sistemas agênticos exigem uma preocupação mais ampla: a engenharia de contexto.
Isso envolve decidir:
- quais informações entram;
- quando entram;
- em que formato entram;
- por quanto tempo permanecem;
- onde os resultados intermediários são armazenados;
- como o agente recupera conhecimento;
- como o consumo é medido;
- quais informações devem ser esquecidas.
O melhor agente não é aquele que recebe todo o repositório, toda a documentação e todo o histórico. É aquele que consegue recuperar, no momento correto, o menor conjunto de informações suficiente para tomar uma boa decisão.
Serena, Context7, Claude Context, Token Savior, Caveman, Context Mode, Token Optimizer, MarkItDown, Repomix, ccusage e Code Review Graph representam diferentes respostas para esse mesmo desafio.
Algumas reduzem a leitura de código. Outras diminuem a verbosidade. Algumas mantêm grandes resultados fora da conversa. Outras oferecem documentação atualizada, memória persistente ou observabilidade financeira.
O desenvolvedor não precisa utilizar todas. Precisa compreender o fluxo de contexto de seu agente e escolher as ferramentas que removem seus verdadeiros gargalos.
No fim, economizar tokens não significa limitar a inteligência do modelo. Significa reduzir o ruído para que essa inteligência possa ser aplicada exatamente onde ela é necessária.



