


[Se voce usa IA, LEIA!] Domando o fantasma criativo: Como reduzir alucinações em GenAI
- #IA Generativa
O Paradoxo da criatividade e o desafio de reduzir alucinações
Assumindo as seguintes premissas:
- A Inteligência Artificial Generativa (GenAI) está moldando uma nova era de interação entre humanos e máquinas.
- Modelos de linguagem extensos (LLMs) já são capazes de escrever textos, responder perguntas, gerar código e criar arte com uma fluência sem precedentes.
- No entanto, esta revolução tecnológica é assombrada por um desafio técnico e ético fundamental: a alucinação.
- Alucinações em IA generativa ocorrem quando o modelo "inventa" informações. Ele apresenta dados incorretos, inexistentes ou enganosos com a mesma confiança e autoridade com que afirma verdades verificadas.
- O verdadeiro perigo das alucinações não reside apenas no erro, mas na sua plausibilidade.
- Os LLMs são elaborados para serem convincentes, o que significa que podem não estar necessariamente corretos. Eles são otimizados para a fluência, não para a verdade.
- Esta dinâmica cria um "desalinhamento entre o grau de confiança das organizações na IA e o grau de confiabilidade real da tecnologia".
- Consequentemente, a alucinação é indiscutivelmente "a maior barreira para a implantação segura" de LLMs em sistemas de produção do mundo real.
- Em domínios críticos como saúde, direito, educação e finanças, um erro plausível pode comprometer a confiabilidade, a segurança e a confiança do usuário.
- A raiz deste problema é que a GenAI otimiza para a fluência estatística — prevendo a próxima palavra mais provável — o que não garante a factualidade do mundo real.
- A principal tarefa para a adoção generalizada da GenAI é, portanto, reconciliar a fluência estatística do modelo com a factualidade verificável.

Créditos: Freepik/ Aarud/ Pobytov
Este artigo fornece uma dissecação exaustiva das causas técnicas das alucinações. Mais importante, ele apresenta um roteiro estratégico e multifacetado, abrangendo desde a curadoria de dados até arquiteturas de inferência avançadas, para reduzir sistematicamente as alucinações.
O objetivo é transformar este desafio em uma oportunidade de construir soluções de IA mais seguras, precisas e, finalmente, confiáveis.
Anatomia da alucinação: Por que os modelos de GenAI erram?
Decodificando as Causas das Alucinações em GenAI
Para reduzir eficazmente as alucinações, devemos primeiro compreender suas diferentes formas. As alucinações não são um fenômeno monolítico; elas se manifestam de várias maneiras distintas.
Uma taxonomia prática de erros inclui:
- Alucinação Intrínseca: O modelo gera informações que contradizem diretamente o contexto ou a fonte fornecida no prompt.
- Alucinação Extrínseca: O modelo introduz informações que não podem ser verificadas ou apoiadas pela fonte, parecendo factuais, mas sendo, na verdade, fabricadas.
- Alucinação Factual: A geração de dados concretamente errados, como afirmar que a Torre Eiffel foi construída em 1950 ou citar estatísticas incorretas.
- Alucinação Lógica: A geração de conclusões absurdas ou que violam a lógica básica, como afirmar que "todos os pássaros são mamíferos porque voam".
- Alucinação Contextual: O modelo perde o "fio da meada" da conversa e começa a falar sobre algo completamente fora do tópico.
- Alucinação de Entidade: A invenção de pessoas, publicações ou instituições, como citar uma fictícia "Universidade de Atlantis" como referência.
- Alucinação Temporal: Confusão sobre cronologia ou datas históricas, como afirmar que "a internet foi inventada no século 18".
- Alucinação de Atribuição: Creditar erroneamente uma citação ou descoberta a alguém, como dizer que "Einstein descobriu a penicilina".
As raízes técnicas que geram alucinações
As alucinações não são falhas aleatórias ou "bugs" no sentido tradicional. Elas são subprodutos diretos e esperados de como os LLMs são construídos, treinados e operados. As causas podem ser rastreadas até três fases principais do ciclo de vida do modelo.
Causa 1: Dados de treinamento
A causa fundamental é o princípio de "Garbage In, Garbage Out" (Lixo Entra, Lixo Sai).
Os LLMs são treinados em vastos conjuntos de dados da Internet. Esses dados estão inerentemente repletos de "dados ruidosos", incluindo informações falsas, desatualizadas, contraditórias, vieses e desinformação. Quando os dados de treinamento carecem de informações abrangentes ou precisas sobre um tópico específico, especialmente em domínios de nicho, o modelo tem dificuldade para produzir resultados confiáveis.
Nesses casos, ele é forçado a "preencher as lacunas" com o conteúdo estatisticamente mais provável, que muitas vezes é fabricado.
Causa 2: Arquitetura do modelo
O conhecimento de um LLM padrão é "paramétrico". Isso significa que todo o seu "conhecimento" está armazenado estaticamente nos pesos (parâmetros) do modelo, definidos durante o treinamento.
Isso leva a dois problemas principais: o conhecimento do modelo não pode ser atualizado após o treinamento, resultando em fatos desatualizados; e o modelo não tem um mecanismo para saber o que não sabe.
Além disso, o sobreajuste (Overfitting) durante o treinamento pode fazer com que o modelo memorize padrões específicos dos dados de treinamento, em vez de generalizar o raciocínio, levando a respostas inflexíveis ou incorretas.
Causa 3: Decodificação
O processo de geração de texto em um LLM é inerentemente probabilístico.
O modelo não "escolhe" a melhor palavra; ele amostra de uma distribuição de palavras prováveis. Técnicas como nucleus sampling (amostragem de núcleo) são usadas para aumentar a criatividade e a diversidade das respostas. No entanto, essa mesma criatividade aumenta a probabilidade de o modelo selecionar um token (palavra) que seja estatisticamente plausível, mas factualmente incorreto. As alucinações, portanto, representam uma falha em cascata.
Dados ruidosos (Causa 1) criam o potencial para o erro, que é armazenado nos parâmetros do Modelo (Causa 2). A Decodificação probabilística (Causa 3) é o mecanismo que atualiza esse potencial em uma alucinação tangível. Isso demonstra que uma única solução — como apenas limpar os dados — é insuficiente.
A mitigação eficaz de alucinações exige uma estratégia de "defesa em profundidade", com intervenções em todas as três etapas: dados melhores, treinamento mais robusto e inferência mais segura.
A Fundação da verdade: Reduzindo alucinações através de estratégias de dados
A Curadoria de dados como ferramenta para reduzir alucinações
A estratégia mais fundamental para reduzir alucinações começa antes mesmo do treinamento do modelo: melhorar a qualidade dos dados de treinamento. Esta abordagem é conhecida como "Curadoria de Dados". É um processo meticuloso que envolve a seleção, limpeza e processamento cuidadoso dos dados de treinamento.
O objetivo é priorizar informações que sejam revisadas, verificáveis e de alta qualidade.Isso significa filtrar ativamente dados "ruidosos", falsos, contraditórios ou desatualizados antes que o modelo tenha a chance de aprendê-los. O Aumento de Dados (Data Augmentation) também pode ser empregado. Isso envolve aumentar o conjunto de treinamento adicionando variações de fatos conhecidos, tornando o conhecimento do modelo sobre esses fatos mais robusto e menos suscetível a desvios.
Reduzindo alucinações com dados sintéticos
A curadoria manual de dados é cara, demorada e difícil de escalar. Em resposta, os dados sintéticos surgiram como uma solução poderosa e escalável. Dados sintéticos são informações geradas artificialmente por algoritmos — muitas vezes, outros LLMs — para replicar as estatísticas e os padrões de dados do mundo real. Esta abordagem oferece vantagens e desvantagens claras na luta contra as alucinações.
- Prós:
- Privacidade: Permite o treinamento em padrões de dados sensíveis (como transações financeiras ou registros médicos) sem expor informações reais de indivíduos.
- Escala: Oferece a capacidade de produzir "volumes ilimitados de dados" para preencher lacunas nos dados de treinamento ou para testes de software rigorosos.
- Factualidade Direcionada: Permite a geração de exemplos de "cauda longa" ou casos de teste factuais que são raros nos dados do mundo real, mas cruciais para a robustez.
- Contras:
- Amplificação de Viés: Se o modelo generativo usado para criar os dados sintéticos tiver vieses, esses vieses serão herdados e potencialmente amplificados nos dados gerados.
- Colapso do Modelo: Treinar repetidamente um modelo com dados gerados por ele mesmo (ou por modelos semelhantes) pode levar a uma degradação da qualidade e diversidade, um fenômeno conhecido como "colapso do modelo".
Esta seção revela um dilema central na preparação de dados: o trade-off entre qualidade e escalabilidade:
- A Curadoria Manual oferece a maior garantia de qualidade e veracidade, mas sofre com baixa escalabilidade e alto custo.
- Os Dados Sintéticos oferecem alta escalabilidade e privacidade, mas correm o risco de qualidade degradada e colapso.
A estratégia ideal, portanto, não é uma escolha binária, mas uma combinação: usar a Curadoria Manual para criar um "conjunto de sementes" (seed set) de alta veracidade e, em seguida, usar Dados Sintéticos para expandir esse conjunto de forma controlada.

Crédito: Osama Madlom/ Unsplash
Codificando a factualidade: Técnicas de treinamento para reduzir alucinações
O Papel do ajuste fino (Fine-Tuning) na redução de alucinações
O ajuste fino (fine-tuning) é um processo que pega um modelo pré-treinado de propósito geral e o adapta para tarefas ou domínios específicos.
- Ajuste Fino de Domínio: Esta técnica especializa o modelo em contextos técnicos específicos, como medicina, direito ou finanças. Ao treinar o modelo em um corpus de dados profundo e específico do domínio, ele desenvolve um conhecimento mais preciso e reduz alucinações contextuais.
- Ajuste Fino de Instrução (Instruction Tuning): Esta é uma técnica crucial para o comportamento do modelo. Em vez de apenas alimentá-lo com dados brutos, o modelo é treinado em um conjunto de dados de instruções e respostas desejadas.
Isso ajuda a reduzir alucinações ao ensinar ao modelo como ele deve se comportar.
Por exemplo, o modelo aprende que para uma instrução "resuma este texto", ele deve resumir e não inventar fatos novos. Ele aprende a seguir regras e alinhar-se à intenção do usuário, em vez de apenas completar padrões estatísticos.
O feedback humano como pilar para reduzir alucinações (RLHF)
O Aprendizado por Reforço com Feedback Humano (RLHF) é uma técnica proeminente, usada por organizações como OpenAI e Google, para alinhar melhor os modelos com as preferências e valores humanos.
O processo de RLHF geralmente envolve três fases principais :
- Fase 1: Pré-treinamento: Um LLM de fundação é treinado em um vasto conjunto de dados.
- Fase 2: Ajuste Fino Supervisionado (SFT): O modelo é ajustado em um conjunto menor de dados de demonstração de alta qualidade, mostrando exemplos de comportamento desejado.
- Fase 3: Modelo de Recompensa (RM) e RL:
- (a) Várias saídas do modelo SFT são geradas para um conjunto de prompts.
- (b) Avaliadores humanos classificam essas saídas da melhor para a pior.
- (c) Um "Modelo de Recompensa" (RM) separado é treinado para prever a pontuação que um humano daria a qualquer resposta.
- (d) O LLM da Fase 2 é então treinado (usando Aprendizado por Reforço) para otimizar suas respostas a fim de maximizar a pontuação dada pelo RM.
Uma suposição comum é que o RLHF "ensina" o modelo a não alucinar. No entanto, pesquisas sugerem uma realidade mais complexa.
O estudo do InstructGPT, por exemplo, indicou que o RLHF, na verdade, piorou as alucinações em algumas métricas, embora tenha melhorado a utilidade geral. Isso expõe um perigo oculto: o RLHF otimiza para o que os avaliadores humanos preferem. Os humanos são notoriamente ruins em detectar alucinações factuais sutis; nós tendemos a preferir respostas que sejam confiantes, fluentes e pareçam úteis, mesmo que estejam erradas. Portanto, o RLHF otimiza o modelo para parecer correto, não necessariamente para ser correto.
Isso implica que, embora o RLHF seja vital para segurança, tom e utilidade, ele não é uma solução completa para a factualidade. Para garantir a veracidade, o RLHF deve ser combinado com técnicas de grounding (aterramento) factual.
Reduzindo alucinações com treinamento contraditório (Adversarial Training)
O treinamento contraditório (adversarial training) é uma técnica de robustez que expõe intencionalmente o modelo a "entradas contraditórias". Esses são prompts cuidadosamente elaborados, muitas vezes por outros modelos de IA, projetados especificamente para enganar o modelo, explorar fraquezas ou contornar suas barreiras de segurança. O modelo é então treinado para reconhecer e resistir a esses ataques, melhorando sua robustez geral e segurança. No entanto, essa técnica apresenta um trade-off delicado. Conforme observado por pesquisadores, existe um "trade-off entre utilidade e recusa".
Se um modelo é treinado de forma muito agressiva para recusar solicitações (para evitar gerar conteúdo prejudicial ou alucinado), ele pode "esquecer como dizer algo útil" e se tornar excessivamente restritivo ou inútil.
A arquitetura da resposta correta: Usando RAG para reduzir drasticamente as alucinações
O que é RAG (Retrieval-Augmented Generation) e por que ele reduz alucinações?
A Geração Aumentada por Recuperação (RAG) representa uma mudança de paradigma na forma como os LLMs lidam com fatos. Em vez de esperar que o LLM saiba a resposta (dependendo de seu conhecimento paramétrico estático), o RAG permite que o modelo consulte fontes de conhecimento externas e atualizadas em tempo real. O RAG "aterra" (grounds) o LLM em fatos. O modelo é instruído a basear sua resposta apenas nas informações recuperadas de uma base de conhecimento confiável.
Esta arquitetura aborda diretamente as causas-raiz das alucinações:
- Resolve o Conhecimento Desatualizado: A base de dados RAG pode ser atualizada continuamente, garantindo que o modelo tenha acesso às informações mais recentes, algo impossível para um modelo paramétrico estático.
- Resolve o Conhecimento de Nicho: A base de dados pode ser preenchida com conhecimento de domínio específico (ex: documentos internos da empresa, artigos de ciências da vida), permitindo que o modelo responda com precisão sobre tópicos que não viu no treinamento.
- Reduz a Fabricação: Ao ter uma fonte factual explícita para consultar e citar, o modelo não precisa "inventar" ou "preencher as lacunas".
Créditos: Jose R F Junior, AI Engineer
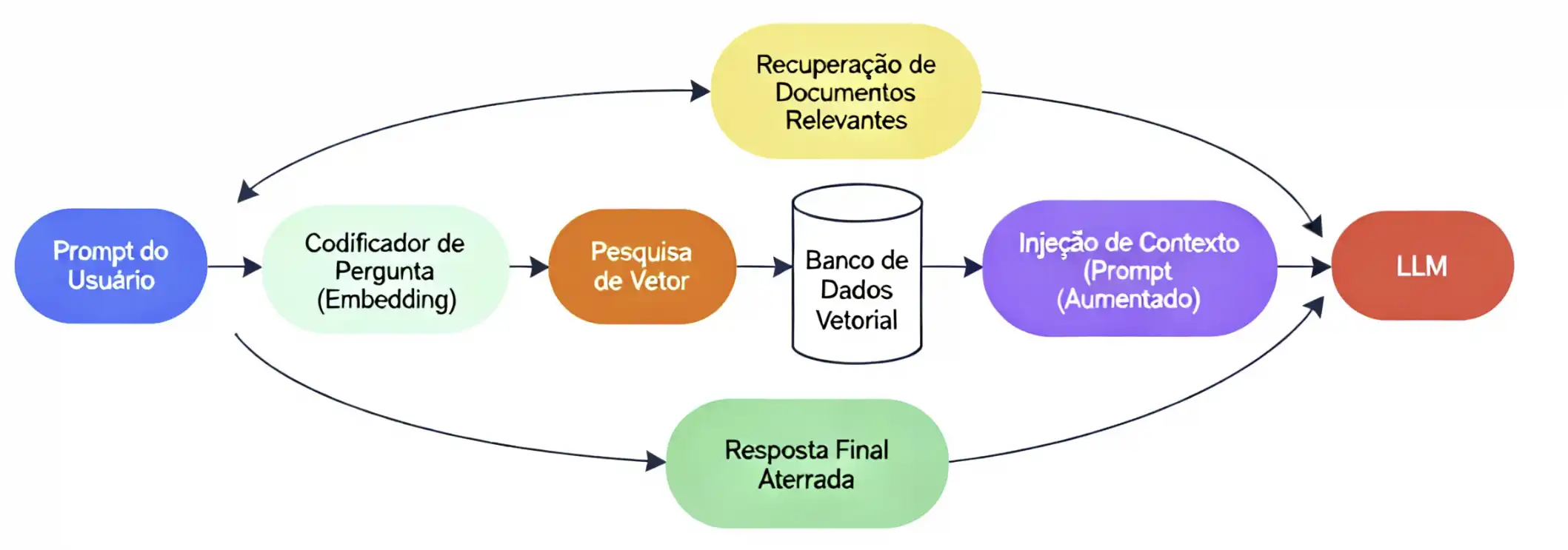
O Fluxo de Dados do RAG para garantir respostas sem alucinações
Em um nível técnico, o fluxo de RAG em tempo de execução (disponibilização) segue um processo claro e de várias etapas para garantir que a resposta final seja aterrada em fatos.
Descrição da Imagem: Um diagrama de fluxo de dados ilustrando a arquitetura RAG. O fluxo começa com (1) "Prompt do Usuário", que segue para (2) "Codificador de Pergunta (Embedding)". Uma seta aponta de (2) para (3) "Pesquisa de Vetor" (realizada contra um "Banco de Dados Vetorial"). A pesquisa resulta em (4) "Recuperação de Documentos Relevantes". Os documentos (4) e o prompt original (1) são combinados em (5) "Injeção de Contexto (Prompt Aumentado)". Este prompt aumentado é então enviado para (6) "LLM", que produz (7) "Resposta Final Aterrada".
O processo pode ser dividido da seguinte forma:
- 1. Ingestão (Processo Offline): Antes que qualquer pergunta seja feita, os documentos externos confiáveis (PDFs, páginas da web, etc.) são limpos, divididos em "chunks" (pedaços) gerenciáveis, convertidos em embeddings (vetores numéricos) e armazenados em um Banco de Dados Vetorial.
- 2. Pergunta (Processo Online): O usuário envia uma solicitação (prompt) ao aplicativo.
- 3. Vetorização: A pergunta do usuário é convertida no mesmo formato de embedding (vetor) que foi usado para os documentos.
- 4. Recuperação (Retrieval): O sistema realiza uma "pesquisa de similaridade semântica" no banco de dados vetorial. Ele compara o vetor da pergunta com os vetores dos "chunks" de documentos para encontrar os pedaços de texto mais relevantes para a pergunta do usuário.
- 5. Aumento (Augmentation): O sistema pega o prompt original do usuário e o "aumenta" injetando os "chunks" de texto recuperados diretamente no contexto do prompt.
- 6. Geração (Generation): O LLM recebe este "prompt aumentado" com uma instrução explícita, como: "Usando apenas o contexto fornecido, responda à pergunta do usuário". O LLM então sintetiza uma resposta baseada apenas nessa fonte factual.

Componentes de arquitetura RAG Chain. Créditos: Jose R F Junior, AI Engineer
As Limitações do RAG e como ele ainda pode gerar alucinações
Apesar de sua eficácia, o RAG não é uma bala de prata infalível. Ele introduz novos pontos potenciais de falha que podem levar a alucinações.
- Falha na Recuperação (Retrieval Failure): Este é o ponto de falha mais comum. Se a pesquisa vetorial falhar em encontrar os documentos corretos (talvez devido a uma pergunta ambígua) e recuperar "blocos desalinhados ou irrelevantes" , o LLM receberá um contexto ruim. Ele então gerará uma resposta irrelevante ou alucinará (uma Alucinação Contextual).
- Falha nos Dados (Data Failure): O RAG assume que a base de conhecimento é a "fonte da verdade". No entanto, se os documentos na base de conhecimento contiverem "vieses ou erros" , o RAG simplesmente forçará o LLM a repetir e amplificar essa informação incorreta com autoridade.
- Falha na Geração (Generation Failure): O LLM ainda é um modelo probabilístico. Ele pode, ocasionalmente, ignorar o contexto fornecido, sintetizá-lo incorretamente ou "produzir conteúdo não suportado pelo contexto recuperado" , embora isso seja menos comum com um bom design de prompt.
O maior benefício do RAG não é a eliminação completa das alucinações, mas sim a transformação da natureza do problema.
Uma alucinação em um LLM padrão é opaca. O erro emana de bilhões de parâmetros dentro de uma "caixa-preta" e é impossível de depurar.
Uma alucinação em um sistema RAG, por outro lado, é quase sempre transparente. O erro pode ser rastreado até um ponto de falha claro: os dados de origem ou a etapa de recuperação.
O RAG transforma um problema intratável de "caixa-preta" do modelo em um problema tratável de "caixa-branca" de engenharia de dados. É possível depurar um banco de dados ou um algoritmo de recuperação; não é possível depurar os parâmetros internos de um LLM de 100 bilhões de parâmetros.
O RAG torna a factualidade um problema de engenharia, não um problema de IA mística.
A ARTE DO COMANDO: Engenharia de prompt para reduzir alucinações
Créditos: Paulo Pinheiro (via Seedream 4.0 Image Generator + Prompt para reduzir alucinações em textos)
A Engenharia de Prompt é a habilidade de criar prompts (comandos) que guiam o LLM para a resposta correta no momento da inferência. Fornecer contexto claro, ser específico e reduzir a ambiguidade são práticas fundamentais para reduzir interpretações errôneas que levam a alucinações. Além disso, podem-se usar instruções de "Barreira de Proteção" (Guardrail), que dão ao modelo regras explícitas sobre como se comportar.
- Exemplo Prático de Prompt de Barreira: Um prompt eficaz, testado em vários modelos, instrui: "Você é um motor de raciocínio neutro. Se a informação for incerta, diga 'desconhecido'. Nunca invente detalhes. Sempre preserve a coerência antes da conclusão. Preservação do significado = prioridade um.".
Reduzindo alucinações com raciocínio (Chain-of-Thought)
A "Cadeia de Pensamento" (Chain-of-Thought ou CoT) é uma técnica de prompt que incentiva o modelo a "dividir o problema em várias etapas" lógicas e gerenciáveis. Em vez de saltar imediatamente para uma conclusão, o modelo é instruído a primeiro "racionalizar" o problema passo a passo. Isso reduz alucinações porque, ao decompor tarefas complexas, o modelo diminui a chance de cometer erros lógicos ou factuais. Ele força o modelo a verificar seu próprio trabalho e lógica em cada etapa.
- Exemplo (Zero-shot CoT): A técnica pode ser tão simples quanto adicionar a frase "Pense passo a passo" ou "Vamos pensar passo a passo" ao final de uma pergunta complexa.
- Prós: Leva a uma "maior precisão" em tarefas de raciocínio e oferece "transparência e compreensão", pois o usuário pode ver como o modelo chegou à sua conclusão.
- Contras: Exige "alto poder computacional" (é mais lento e mais caro por consulta) e carrega o risco de gerar "caminhos de raciocínio plausíveis, mas incorretos".
Reduzindo alucinações com auto-correção e crítica
Esta é uma técnica de inferência avançada onde o LLM é usado para refinar e corrigir suas próprias respostas. O processo funciona como um loop de feedback :
- 1. Geração: O modelo fornece uma resposta inicial (Rascunho 1).
- 2. Crítica: O modelo (ou um segundo LLM atuando como um "Critique-Bot" ) é solicitado a avaliar a resposta inicial. O prompt de crítica pede para verificar a resposta em busca de erros factuais, inconsistências lógicas ou alucinações.
- 3. Refinamento: O modelo gera uma resposta final, incorporando o feedback da etapa de crítica.
As técnicas nesta seção destacam um trade-off econômico fundamental: o custo da inferência versus a precisão. Uma resposta rápida e de uma única passagem tem o menor custo de latência e computação, mas a maior taxa de alucinação.
- Uma resposta CoT é mais lenta e cara, mas reduz a taxa de alucinação.
- Uma resposta de Auto-Correção é pelo menos duas vezes mais cara (exigindo múltiplas chamadas de modelo), mas reduz ainda mais a taxa de alucinação.
A escolha da técnica de prompt depende diretamente do caso de uso. Um chatbot de atendimento ao cliente de alto volume pode exigir baixa latência, enquanto um assistente de pesquisa jurídica exigirá alta factualidade, justificando o custo computacional da auto-correção.
A Rede de segurança: Pós-processamento e verificação para mitigar alucinações: Implementando verificação de fatos externa para bloquear alucinações
Esta é a "rede de segurança" final, ocorrendo depois que o LLM gera uma resposta, mas antes que o usuário a veja.
A "Verificação Factual Automática" envolve o uso de módulos de software externos, ou outros agentes de IA, para verificar de forma independente a precisão das informações geradas.
Na prática, um agente de LLM pode ser equipado com ferramentas, como uma API de pesquisa do Google. O agente pega a afirmação principal gerada pelo LLM, formula consultas de pesquisa, recupera informações contextuais da web e, em seguida, toma uma decisão de verificação (Verdadeiro, Falso, Incerto).
- Prós: Esta abordagem fornece uma verificação independente, livre do conhecimento (potencialmente desatualizado ou tendencioso) do LLM original.
- Contras: Pode ser lento (devido a chamadas de API externas) e os sistemas atuais ainda lutam com "precisão inconsistente" e dificuldade em lidar com veredictos ambíguos.
Construindo confiança através da atribuição e citação
A mitigação de alucinações não é apenas sobre a prevenção do erro, mas sobre o gerenciamento da confiança do usuário. A "transparência da fonte" é um componente essencial para construir essa confiança. Quando um LLM pode citar de onde sua informação veio, o usuário ganha dois benefícios críticos: (1) confiança imediata na resposta e (2) a capacidade de verificar a fonte por si mesmo. Esta abordagem preenche a lacuna crítica entre a "geração opaca" (uma resposta de caixa-preta) e o "raciocínio verificável". Na prática, isso vai além de uma simples lista de fontes.
Os sistemas de ponta agora destacam o texto de origem específico (por exemplo, em um documento PDF) que o LLM usou para formular sua resposta. Isso transforma o LLM de um oráculo "caixa-preta" (que alucina) em um assistente de pesquisa "caixa-branca" (que resume e cita). A combinação da arquitetura RAG com a Citação forma o pilar de um ecossistema de IA confiável.
O RAG força o modelo a usar uma fonte externa , e a Citação mostra ao usuário qual fonte foi usada. Isso resolve o problema da "geração opaca" e torna a verificação um esforço colaborativo entre o usuário e a IA.
Medindo a miragem: Benchmarks e estratégias de avaliação para reduzir alucinações
Um Quadro Comparativo das Estratégias de Mitigação de Alucinações
Para selecionar a estratégia correta, é essencial entender os trade-offs. A tabela a seguir resume as técnicas de mitigação discutidas, seu local no ciclo de vida do modelo, seu custo e suas limitações.
Tabela 1: Quadro Comparativo das Principais Estratégias de Mitigação de Alucinações:

Como os pesquisadores quantificam e testam alucinações
Não podemos reduzir o que não podemos medir. Benchmarks (parâmetros de referência) são cruciais para avaliar objetivamente o progresso dos modelos na redução de alucinações.
Dois benchmarks principais se destacam:
Benchmark 1: TruthfulQA
O TruthfulQA foi projetado especificamente para medir se um modelo de linguagem é veraz (truthful) ao gerar respostas para perguntas.
Seu foco principal são as "falsidades imitativas" — concepções errôneas comuns, mitos e falsidades que os humanos frequentemente acreditam e que estão presentes nos dados de treinamento da web. Os resultados iniciais do TruthfulQA revelaram um chocante fenômeno de "escala inversa" (inverse scaling). Estudos mostraram que os modelos maiores (como o GPT-3 175B) eram, na verdade, menos verazes que os modelos menores. Isso ocorre porque modelos maiores são mais eficazes em imitar os dados de treinamento da web, o que inclui a imitação de falsidades populares com maior confiança.
Benchmark 2: HaluEval
O HaluEval é um benchmark focado em avaliar o desempenho dos LLMs em reconhecer alucinações. Seu principal caso de teste é a alucinação baseada em contexto: ele avalia se o conteúdo gerado pelo modelo entra em conflito com a fonte fornecida.
A existência desses dois benchmarks (TruthfulQA e HaluEval) define perfeitamente a divisão do problema e a direção estratégica da indústria. O TruthfulQA testa o conhecimento paramétrico (o que o modelo "sabe" de memória). O fenômeno do "inverse scaling" prova que esta é uma estratégia fundamentalmente falha — os modelos apenas melhoram em imitar mentiras. O HaluEval testa a fidelidade ao contexto (o quão bem o modelo "usa" uma fonte fornecida).
A indústria está se movendo para longe do problema do TruthfulQA (tentar fazer o modelo saber tudo) e em direção ao problema do HaluEval (fazer o modelo usar fatos fornecidos corretamente).
Isso valida que o RAG não é apenas uma técnica, mas a arquitetura estratégica correta para o futuro da IA factual.
O futuro da GenAI factual e os desafios abertos:
O desafio aberto: As Alucinações São Matematicamente Inevitáveis?
Uma pesquisa recente da OpenAI propôs um "framework matemático abrangente" que oferece uma conclusão sóbria: as alucinações podem ser "matematicamente inevitáveis". O argumento central é que as alucinações não são apenas falhas de engenharia que podem ser corrigidas. Elas "decorrem das propriedades estatísticas do treinamento" em si. Fatores como a "incerteza epistêmica" (quando a informação é rara nos dados de treinamento) e a "intratabilidade computacional" estabelecem limites matemáticos para a precisão de qualquer sistema treinado por imitação.
O Caminho adiante para reduzir alucinações e construir confiança
É um futuro que combina de forma inteligente todas as camadas de defesa:
- Melhores Dados: Uma fundação construída sobre curadoria rigorosa e dados sintéticos direcionados (Seção 2).
- Melhor Alinhamento: Modelos alinhados por RLHF para segurança e utilidade (Seção 3).
- Arquiteturas Aterradas: RAG como o padrão industrial para acesso a fatos em tempo real (Seção 4).
- Inferência Robusta: Raciocínio CoT e Auto-Correção para problemas complexos (Seção 5).
- Transparência Total: Verificação externa e atribuição de citações como uma rede de segurança não negociável (Seção 6).
O objetivo inspirador não é eliminar o "fantasma" criativo da máquina, mas sim domá-lo!
Estamos testemunhando a transição da era dos LLMs "oniscientes" (e perigosamente propensos a alucinações) para a era dos "assistentes de pesquisa" focados, verificáveis e, finalmente, fundamentalmente confiáveis.
Referências
- CI&T (2024) – “Alucinações dos LLMs podem ser gerenciadas, bem como serendipidade”. Disponível em: ciandt.com.
- arXiv (2023) – “Retrieval-Augmented Generation for Large Language Models”. Disponível em: arxiv.org.
- Huyen Chip (2023) – “RLHF: Reinforcement Learning from Human Feedback”. Disponível em: huyenchip.com.
- IBM (2023) – “O que é a técnica Chain-of-Thought (CoT)?”. Disponível em: ibm.com.
- OpenAI (2022) – “TruthfulQA: Measuring How Models Mimic Human Falsehoods”. Disponível em: openai.com.
- ACL Anthology (2023) – “HaluEval: A Large Collection of Hallucinated Samples for Evaluating Large Language Models”. Disponível em: aclanthology.org.
- ComputerWorld (2024) – “OpenAI admits AI hallucinations are mathematically inevitable”. Disponível via Reddit e computerworld.com.






Parabéns!!!
Obrigado @Aníbal Júnior
Exato, temos que ter cuidado, não deixar solto mas não freiar demais, afinal viraria um autocomplete.....
AJ
Parabéns!!
Achei bacana a ideia que devemos domar e não eliminar as alucinações.
Makes us think... Vlw!
Muito obrigado, @DIO COMMUNITY! 🙏 Fico feliz que tenha gostado da reflexão — esse equilíbrio realmente é o coração da discussão sobre GenAI.
Na minha visão, o maior desafio para um desenvolvedor está em conciliar a pressão por resultados rápidos e inovadores com a necessidade de aplicar controles éticos e de privacidade desde o início do ciclo de desenvolvimento.
Muitas vezes, os times são impulsionados por métricas de performance, tempo de entrega e diferenciação de produto — e isso tende a empurrar a ética e a governança para fases posteriores, quando os riscos já estão embutidos no sistema.
O caminho mais sustentável é adotar uma mentalidade de “Responsible by Design”, onde aspectos como transparência, explicabilidade, mitigação de vieses e proteção de dados são tratados como requisitos de arquitetura, e não como etapas opcionais. Isso muda completamente a forma de projetar soluções e força o desenvolvedor a pensar não apenas no que o modelo pode fazer, mas no que ele deveria fazer.
Em suma: o verdadeiro desafio não é técnico — é cultural e estrutural. É fazer com que inovação e responsabilidade caminhem juntas, e não em direções opostas. Eu uso IA diariamente no meu trabalho e lido sempre com esse peso da responsabilidades..... Faz parte de toda inovação né?
Excelente, Paulo! Que artigo magistral, profundo e absolutamente essencial sobre Alucinações em GenAI! Você desvendou o ponto nevrálgico da IA Generativa Corporativa: o LLM (Modelo de Linguagem de Grande Escala) é um Oráculo brilhante, mas sem bom senso, e a alucinação é o preço que pagamos por sua criatividade.
Você transformou o paradoxo da criatividade em um roteiro de engenharia que exige defesa em profundidade e intervenção humana.
Qual você diria que é o maior desafio para um desenvolvedor ao implementar os princípios de IA responsável em um projeto, em termos de balancear a inovação e a eficiência com a ética e a privacidade, em vez de apenas focar em funcionalidades?
JS
👏👏👏