


RAG e NotebookLM – Isso é música para meus ouvidos!
- #IA Generativa
Sumário
1. Introdução
2. Os modelos LLM
3. RAG e suas aplicações
4. NotebookLM e suas aplicações
5. Considerações finais
6. Referências
1 – Introdução
Desde os anos 80, quando eu cursava Engenharia Elétrica, já se estudava Inteligência (IA) Artificial na minha universidade (UFPB, Campus II, em Campina Grande-PB, atual UFCG). Lá, havia grupos de estudo dedicados a PROLOG, LISP e Sistemas Especialistas, formados por professores do curso e de Computação, além de alunos de graduação e de Pós-graduação.
O tema era bem teórico e acadêmico, sem exposição pública nem aplicação fora daquele ambiente.
Em novembro de 2022, a OpenAI lançou a primeira versão do ChatGPT. O lançamento público, de uso gratuito e livre para todos logo virou um hype! Era a ficção científica virando realidade.
Após o ChatGPT, logo várias ferramentas de IA de empresas concorrentes foram lançadas, como (Claude, Gemini, Copilot etc.). No início, elas (IAs Generativas) pareciam um Google turbinado, que dava a resposta correta em texto ao invés de listar links onde ela poderia estar.
Elas se tornaram mais poderosas, chegando às IAs Generativas Multimodais, que geram imagens, vídeos, voz, sons, músicas etc.
Embora tenham sido um avanço formidável, elas apresentam problemas recorrentes como respostas erradas, falta de contexto atualizado e até alucinações.
Foram criadas técnicas que melhoram muito a resposta de ferramentas de IA, como um prompt detalhado e dedicado ao contexto de cada pergunta, a adição de conteúdos extras etc.
Este artigo trata de uma destas soluções, conhecida como RAG (“Retrieval Augmented Generation”), que adiciona novo conteúdo aos dos treinamentos de uma IA, permitindo uma pesquisa mais abrangente. Apresentamos também o NotebookLM, do Google, exemplo de RAG, uma ferramenta de estudo fantástica que eu passei a usar.
2 – Os modelos LLM (“Large Language Model”)
O lançamento do ChatGPT tirou o foco da IA das pesquisas acadêmicas avançadas e a trouxe para o nosso cotidiano e público em geral.
Segundo CHATGPT [1], na década de 90, já existiam modelos de linguagem, mas eles eram pequenos, lentos, com pouca memória e só conseguiam lidar com pequenas quantidades de texto.
Estes modelos processavam uma sequência palavra a palavra, aprendiam a prever a próxima palavra, mas não tinham uma visão global do contexto, além de não serem escaláveis.
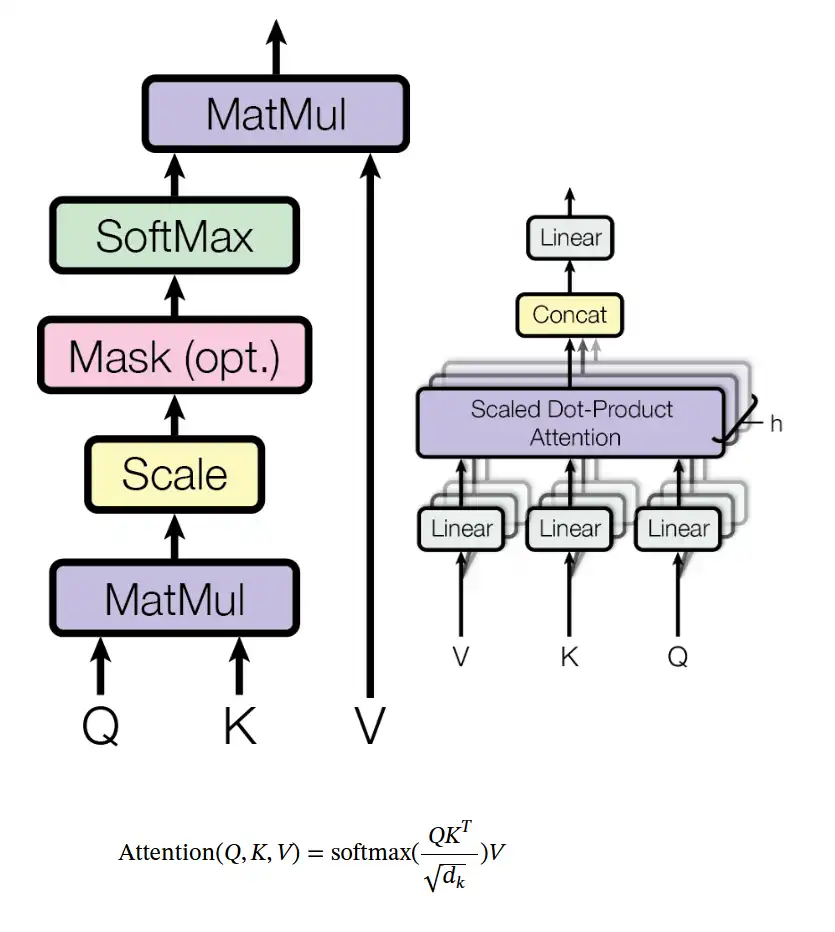
O salto que permitiu a criação dos LLMs foi um artigo publicado em 2017 (VASWANI [2]), por uma equipe do Google, intitulado “atention is all you need”.
Segundo VASWANI [1], foi proposta uma arquitetura de rede neural simples, sem estruturas complexas, chamada Transformer.
Ele afirma que os modelos de melhor desempenho da época se baseavam em redes neurais recorrentes (RNNs) ou convolucionais (CNNs) complexas, que tinham um codificador e um decodificador, conectados por meio de um modelo de atenção.
VASWANI [1] mostrou que o para entender linguagem natural deveria ser usado o contexto inteiro, não palavras isoladas. O Transformer se baseia apenas em mecanismos de atenção.
Uma função de atenção é um mapeamento de uma consulta para uma saída, permitindo ponderar a relevância de cada palavra no contexto geral, tornando o processamento paralelo, mais rápido e escalável.
OBS. - Para quem acha que um artigo técnico acadêmico é só um algoritmo e entidades prontos para implementação direta, aqui está uma ilustração do rigor técnico mostrado neste artigo.
Para tradução automática, VASWANI [1] afirma que o Transformer apresenta qualidade superior aos modelos tradicionais, são mais paralelizáveis e demandam bem menos tempo de treinamento.
Assim, o Transformer se tornou a base dos LLMs (“Large Language Models”) modernos (GPT, Claude, Gemini, Llama, Mistral etc.), com aprendizado paralelo e escalabilidade quase infinita.
Segundo CHATGPT [1], LLMs são sistemas de IA desenvolvidos para processar e analisar enormes quantidades de dados de linguagem natural para gerar respostas às solicitações dos usuários (prompts), com base nos dados de treinamento.
Eles são treinados em grandes conjuntos de dados usando algoritmos avançados de “machine learning” para aprender os padrões e as estruturas da linguagem humana. Com base em relações estatísticas entre palavras e frases, eles podem gerar novos textos usando o contexto destes dados.
Após o lançamento do primeiro modelo, avanços recentes (principalmente a oferta de GPUs e TPUs mais potentes) trouxeram grande destaque à IA generativa e aos LLMs.
Algumas aplicações comuns dos LLMs são:
· Assistentes virtuais e chatbots;
· Geração de código e depuração;
· Análise de sentimento;
· Classificação e agrupamento de texto;
· Resumo de textos;
· Tradução de idiomas;
· Geração de conteúdo.
Hoje, IAs Generativas atuais são largamente aplicadas nas áreas de criação, automação de tarefas repetitivas e análises.
Mesmo assim, até os grandes modelos (como o GPT, Claude, LLaMA) apresentam limitações estruturais, pois foram treinados com dados estáticos e cometem erros fora do contexto aprendido. As principais limitações são:
· Alucinações - O modelo “inventa” fatos plausíveis, mas incorretos;
· Desatualização – Ele só sabe o que estava nos dados de treinamento;
· Falta de acesso a dados privados ou em tempo real – Não acessam bancos de dados internos ou online;
· Dependência do prompt - Pequenas variações na pergunta alteram muito o resultado;
· Ausência de raciocínio verificável – Ele apenas gera texto plausível, não sabendo justificar a resposta;
· Custo e latência - Modelos com bilhões de parâmetros demandam alto custo computacional.
Os LLMs fornecem respostas convincentes e coerentes às perguntas, dando a impressão de raciocínio ao responder. No entanto, os LLMs não são fontes de conhecimento confiáveis. É importante verificar os fatos e entender as respostas antes de usá-las como referência.
Eles são limitados pelos seus dados de treinamento, não sabendo nada que aconteceu depois do seu treinamento nem têm acesso a informações proprietárias, como documentos internos de uma empresa. Quando eles não encontram a resposta correta, inventam respostas estatisticamente melhores, em vez de informar que não sabem a resposta correta.
Esses problemas mostram que os LLMs precisam de camadas de controle, memória e conexão externa. Por isso, foram criadas técnicas de otimização e de controle. As principais são:
· Engenharia de Prompt (“Prompt Engineering”) - Estratégias para estruturar melhor as instruções dadas a um modelo, para reduzir ambiguidades, melhorar a coerência e guiar o raciocínio;
· Ajuste Fino (“Fine-tuning”) - Ajuste do modelo com novos dados específicos (ex: dados jurídicos, médicos etc.);
· Agentes Autônomos - Sistemas que usam LLMs para executar sequências de tarefas, acessando APIs e bancos de dados. (ex: AutoGPT, CrewAI, LangGraph);
· RAG (“Retrieval-Augmented Generation”) – Adição de uma base de dados externa pesquisável.
4 – RAG e suas aplicações
Segundo DATABRICKS [3], os LLMs oferecem recursos poderosos de compreensão e geração de linguagem, mas apresentam limitações. A figura abaixo mostra uma consulta comum a um LLM.
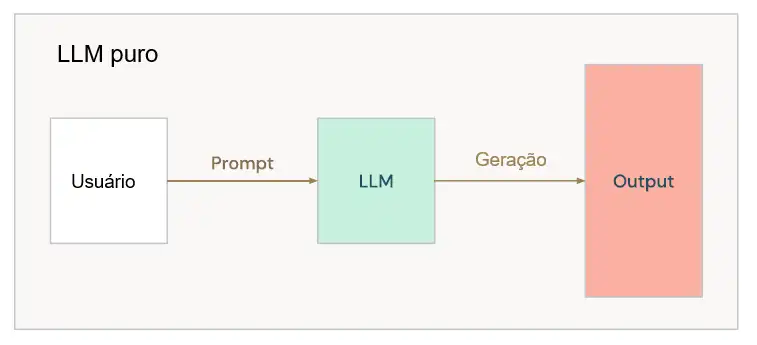
O uso do RAG com um LLM ajuda a resolver algumas das limitações vistas.
O RAG – “Retrieval Augmented Generation” - (ou Geração Aumentada por Recuperação) é um processo que combina o pedido do usuário com informações externas relevantes para formar uma nova solicitação expandida para um LLM.
Assim, o LLM pode dar respostas sobre assuntos em que ele não foi treinado, mais relevantes e precisas, reduzindo a probabilidade de alucinações. Além disso, ele evita que o usuário precise procure as informações adicionais para adicioná-las manualmente à pergunta.
Um aplicativo RAG pode fornecer diversos documentos ao LLM, como textos, arquivos PDF, páginas da web, códigos, além de podcasts, vídeos etc.
A base de um RAG é formada por um LLM e os prompts (ver figura abaixo).
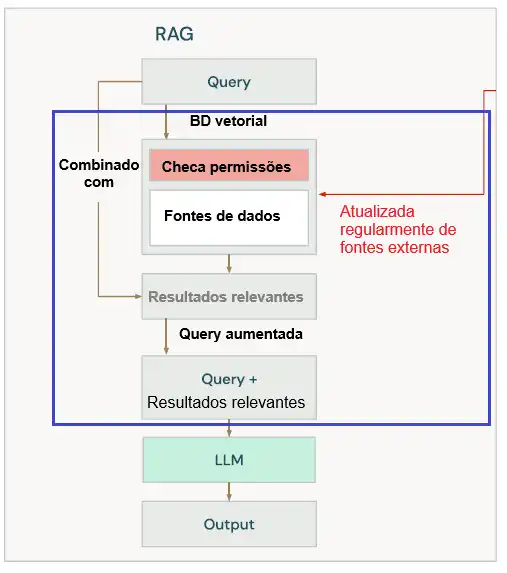
Um aplicativo RAG eficaz deve ser capaz de encontrar informações relevantes para a solicitação do usuário e fornecê-las ao LLM. Para selecionar estes textos, pode ser usada uma técnica chamada Busca Vetorial.
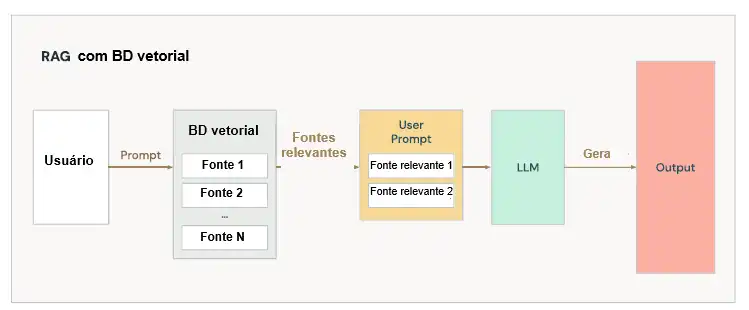
Nela, um tipo especial de modelo de linguagem (modelo de incorporação) traduz cada texto que queremos pesquisar em um vetor numérico (embbeding), bem como o texto da consulta do usuário. Estes dois vetores numéricos são comparados matematicamente para identificar aqueles que são mais semelhantes e mais relevantes.
Os embeddings codificam os significados dos textos, baseados nos significados e relações que os humanos consideram importantes, mas o modelo pode capturar um significado diferente. Por isso, é essencial testar e avaliar cada componente de um aplicativo RAG.
Os vetores gerados por modelos de incorporação são frequentemente armazenados em um banco de dados vetorial especializado, otimizado para armazenamento e recuperação eficientes (ver figura).
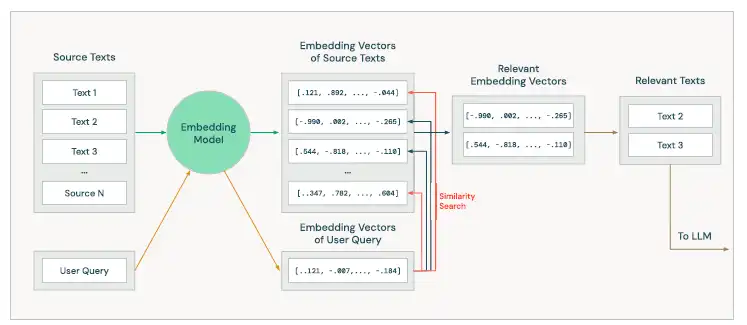
Estes bancos de dados podem gerenciar permissões, metadados e integridade de dados, garantindo acesso seguro e organizado às informações. Além disso, eles garantem que textos recém-adicionados sejam indexados e possam ser usados rapidamente.
A Busca Vetorial segue os seguintes passos:
· Preparação de dados: Adição de uma fonte de informação externa em um banco de dados vetorial;
· Recuperação: Obtenção de contexto relevante;
· Aumento de dados: Adição de contexto à solicitação do usuário;
· Geração: Produção de resultados úteis com um LLM;
· Avaliação: Medição do desempenho do RAG.
As limitações dos LLMs podemos ser mitigadas fornecendo explicitamente ao LLM as informações necessárias para responder à pergunta do usuário. A etapa adicional de construir um sistema de recuperação nos permite automatizar esse processo.
O RAG também apresenta vantagens em comparação com os sistemas apenas de recuperação, pois o LLM pode processar textos de múltiplas fontes em uma saída legível e adaptada à pergunta do usuário.
Comparando abordagens exclusivamente baseadas em LLM com o uso do RAG, o RAG apresenta vantagens, pois pode:
· incorporar dados proprietários;
· acessar informações atualizadas;
· aprimorar a precisão das respostas do LLM;
· incluir citações das fontes originais, permitindo a verificação humana;
· permitir um controle de acesso, recuperando apenas os documentos aos quais um usuário tem permissão de acesso.
Os casos de uso típicos do RAG são:
· Sistemas de perguntas e respostas - O RAG é indispensável para coletar dados de documentos em tempo real;
· Atendimento ao cliente – Melhor a experiência do cliente, reduzindo os tempos de resposta e aumentando a eficiência;
· Geração de conteúdo – Redige comunicações (e-mails), integrando dados recentes e o contexto relevante;
· Assistência de código - Aprimora o preenchimento automático e as perguntas e respostas de código, pesquisando e recuperando informações em bases de código, documentação e bibliotecas externas.
Além do RAG, existem outras abordagens para personalizar LLMs ou adicionar novas informações. Elas envolvem compromissos entre custo (financeiro), complexidade (técnica) e expressividade (respostas significativas):
· Engenharia de prompt – Orientam as saídas de um modelo em direção a um resultado desejado;
· Ajuste fino – Adaptação de modelo pré-treinado a um novo domínio ou tarefa, treinando alguns de seus pesos com novos dados;
· Pré-treinamento – Treinamento de um LLM do zero. Oferece o maior potencial de controle sobre a expressividade do modelo;
· RAG - Requer a configuração de um sistema de recuperação e a integração do contexto recuperado;
Esses métodos podem ser usados em conjunto. A escolha vai depender dos interesses em custos, complexidade e expressividade desejados.
Para acessar informações externas, o RAG oferece alguns benefícios:
· Permite adicionar e remover fontes de dados sem alterar o modelo;
· Controle sobre permissão de acesso sobre as fontes de dados;
· Flexibilidade para comparar LLMs sem precisar treiná-los com novos dados.
ASIMOV [4] apresenta um exemplo prático de uso da técnica de RAG, codificado em Python e utilizando a API da OpenAI e a biblioteca LangChain:
from langchain import OpenAI, DocumentLoader, TextSplitter, VectorStore
# Carregar documentos
document_loader = DocumentLoader("caminho/para/seus/documentos")
documents = document_loader.load()
# Dividir os documentos em trechos (chunks) menores
text_splitter = TextSplitter(chunk_size=500)
chunks = text_splitter.split(documents)
# Criar uma Vector Store com embeddings da OpenAI
vector_store = VectorStore.from_documents(chunks, embedding_model="openai-embedding")
# FUNÇÃO de recuperação de trechos relevantes
def retrieve_relevant_chunks(query):
return vector_store.similarity_search(query, top_k=5)
# FUNÇÃO de geração de texto utilizando os trechos recuperados
def generate_response(query):
relevant_chunks = retrieve_relevant_chunks(query)
context = " ".join([chunk.text for chunk in relevant_chunks])
prompt = f"Contexto: {context}\n\nPergunta: {query}\n\nResposta:"
response = OpenAI().generate(prompt)
return response
# EXEMPLO DE USO
query = "Qual é a capital do Brasil?"
response = generate_response(query)
print(response)
5 – NotebookLM e aplicações
Segundo MCKEE [5], o NotebookLM é uma ferramenta de anotações online desenvolvida pelo Google, que usa IA (o Google Gemini), para ajudar os usuários a interagir com seus documentos.
Ele foi lançado inicialmente em 2023 como "Projeto Tailwind", como um "assistente de pesquisa virtual".
Ele permite que o usuário carregue seus próprios conteúdos e, com base neles, pode gerar resumos, explicações e respostas. Os conteúdos podem ser arquivos de texto, arquivos PDF, do Google Docs, Google Slides, e de sites.
Ele também pode gerar resposta em áudio, em formato de conversação, com dois apresentadores criados por IA falantes, como um podcast.
O NotebookLM, da Google é um bom exemplo de aplicação de RAG, pois:
- Permite ao usuário fazer upload de documentos e gera respostas baseadas nesses conteúdos;
- Gera insights a partir destes conteúdos e submete a um LLM;
- O fluxo envolve chunking de textos + embeddings + recuperação de trechos relevantes antes da geração;
A implementação do fluxo de RAG no NotebookLM segue os passos:
· O usuário carrega documentos/arquivos que serão usados como fonte de conhecimento;
· O sistema processa esses documentos (gera embeddings ou vetores semânticos) e divide em “chunks” (unidades de texto) relevantes;
· Quando o usuário faz uma pergunta ou interage com a ferramenta, ela recupera partes relevantes dos documentos carregados;
· Essas partes + a pergunta são alimentadas no LLM, que gera a resposta;
· O resultado é uma resposta que está baseada nas fontes que você carregou, ajudando a reduzir alucinações e aumentar a precisão.
Segundo AMORIM [6], no mês passado (outubro de 2025), o NotebookLM recebeu atualizações importantes, já disponíveis para todos os usuários:
· aumento de 8 vezes na janela de contexto (agora tem 1 milhão de tokens);
· memória de conversas 6 vezes maior;
· configuração do modelo para assumir papéis específicos;
· salvamento automático do histórico de conversas.
5.1 - Aplicação 1 – Autor de um livro o submete ao NotebookLM

ORLAND [7] afirma que o Google apresenta o NotebookLM como “um assistente de pesquisa virtual capaz de resumir fatos, explicar ideias complexas e sugerir novas conexões — tudo com base nas fontes que você selecionar”
Aí, ele decidiu testar a ferramenta e carregou o livro que ele havia acabado de publicar (“Minesweeper”) sobre o antigo jogo Campo Minado do Windows, com mais de 30 mil palavras. A ferramenta criou um podcast de quase 13 minutos, com duas pessoas que não existem conversando sobre o conteúdo do livro.
Ele disse que não estava preparado e se surpreendeu positivamente ao ouvir a conversa criada. Ele falou que o resumo do NotebookLM abordou todas as principais seções do livro.
Para ele, foi como uma simulação de sua participação em um podcast real, cheio de bate-papo descontraído. Ele acrescenta que o formato de podcast é uma maneira incrivelmente envolvente e cativante de absorver informações complexas.
Ele disse que sentiu como se estivesse ouvindo a conversa de duas pessoas que por acaso estavam discutindo meu livro em um café. Comenta que se divertiu e destaca 3 pontos principais:
· um dos apresentadores do podcast descreveu o livro como “uma história da terra dos disquetes e modems discados", uma expressão que ele não usou no livro;
· A mesma voz fala "um pouco de Bill Gates rondando o escritório da Microsoft", insinuando a anedota favorita dele no livro;
· Uma voz de IA afirma que "descobriram que o Campo Minado original tinha uma falha na forma como gerava tabuleiros aleatórios", e a outra voz intervém e exclama "Uma falha!" com uma sincronia perfeita e um senso de surpresa.
O formato de “duas pessoas conversando” ajuda a criar um ritmo suave e fácil na apresentação de informações densas, com pausas e repetições naturais que ajudam a enfatizar os pontos principais.
Como exemplo, o autor avalia que a ferramenta pode dar uma visão geral rápida de um livro volumoso que ele não tivesse tempo ou vontade de ler na íntegra. E que seria ótimo para ouvir durante uma caminhada ou fazendo compras.
Ele considera que esse caminho é muito mais pessoal para a IA generativa do que uma conversa com um chatbot baseado em texto.
Essa apresentação natural e descontraída faz com que o NotebookLM se destaque de outros produtos de IA que geram resumos de texto competentes.
Finalmente, ele diz que esse formato deu uma aparência muito mais amigável ao que pode parecer a IA uma tecnologia desumanizadora.
5.2 - Aplicação 2 – Spotify usa o NotebookLM para gerar a retrospectiva anual
Eu sou muito fã de música e ouço o Spotify todo dia. Anualmente, o Spotify lança um resumo personalizado para cada usuário com os artistas, músicas, gêneros e podcasts que ele mais ouviu na plataforma durante o ano (“Spotify Wrapped”).
Segundo PEREZ [8], no ano passado (2024), essa retrospectiva acrescentou um podcast feito por IA, criado com o NotebookLM. O resultado é uma experiência semelhante à de ouvir um podcast sobre o seu Wrapped.
O Spotify afirma que se inspirou para trabalhar com o Google no novo recurso Wrapped depois de observar a reação dos consumidores à tecnologia de IA.
O clipe de áudio criado pode ser salvo no seu dispositivo ou publicado nas redes sociais. Assinantes Premium podem inserir sugestões para gerar playlists de IA com base na experiência que tiveram com o Spotify Wrapped. O recurso também inclui uma playlist personalizada que ficará disponível na aba Retrospectiva (Wrapped) na página inicial.
O podcast também apresenta o recurso “Top Listeners” (ou Top Ouvintes), que mostra em qual percentil você se encontra em relação ao seu artista favorito.
Resumindo, o RAG levou ao NotebookLM, que foi usado pelo Spotify para criar a sua Retrospectiva Anual, trazendo música para meus ouvidos!
OBS. – Só lembrando. A Retrospectiva do Spotify deve ser lançada na última semana desse mês. Já estou esperando a minha!!!
6 – Considerações finais
Desde os anos 90 já existiam modelos de linguagem que usavam Inteligência Artificial, mas eles muito limitados. O lançamento do ChatGPT trouxe ao cotidiano os modelos LLM e IAs Generativas.
Mesmo potentes, estes modelos têm limitações, devido ao contexto restrito aos dados de treinamento. Foram criadas técnicas para expandir o conhecimento destas IAs e mitigar problemas como adição de dados novos e alucinações.
Uma destas técnicas, que tem se mostrado muito eficaz é o RAG, ou Geração Aumentada por Recuperação. Ela adiciona dados novos sem a necessidade de novos treinamentos nos modelos LLM.
Uma das ferramentas de RAG mais usadas é o NotebookLM, do Google. Ela permite criar uma base de dados própria e obter resumos desse conteúdo, inclusive com saída em áudio tipo podcast, com duas vozes geradas por IA conversando sobre o conteúdo criado.
Eu passei a usá-la nos meus estudos e fiquei impressionado como parece que estou estudando em um grupo de estudo com 3 pessoas discutindo um tema.
Este artigo trata da técnica de RAG e de aplicações feitas com o NotebookLM.
Você já usou? Pois está perdendo tempo! Escolha um tema parta aprender e faça um teste. Garanto que vai se surpreender!
7 – Referências
[1] CHATGPT. “Consulta sobre características, evolução, aplicações e limitações dos modelos LLM”. Disponível em www.chatgpt.com. Acesso em: 03/11/2025.
[2] VASWANI, A. et. al. “Attention is all you need”. Disponível em <https://www.databricks.com/glossary/retrieval-augmented-generation-rag?utm_source=chatgpt.com>. Acesso em: 03/11/2025.
[3] Databricks. Ebook - A Compact Guide to Retrieval Augmented Generation (RAG). Disponível em <https://www.databricks.com/sites/default/files/2024-05/2024-05-EB-A_Compact_GuideTo_RAG.pdf>. Acesso em: 03/11/2025.
[4] PEREIRA, Luiza Cherobini. O que é a Técnica de Retriever Augmented Generation (RAG)? Disponível em: <https://hub.asimov.academy/tutorial/o-que-e-a-tecnica-de-retriever-augmented-generation-rag/>. Acesso em: 03/11/2025.
[5] MCKEE, Amberle. NotebookLM: Um guia com exemplos práticos. Disponível em: <https://www.datacamp.com/pt/tutorial/notebooklm>. Acesso em: 13/11/2025.
[6] AMORIM, Diego. NotebookLM agora tem contexto 8x maior e respostas mais precisas. Disponível em: <https://tecnoblog.net/noticias/notebooklm-agora-tem-contexto-8x-maior-e-respostas-mais-precisas/>. Acesso em: 13/11/2025.
[7] ORLAND, Kyle. “Fake AI “podcasters” are reviewing my book and it’s freaking me out”. Disponível em: <https://arstechnica.com/ai/2024/09/fake-ai-podcasters-are-reviewing-my-book-and-its-freaking-me-out/>. Acesso em: 13/01/2025
[8] PEREZ, Sarah. “Spotify Wrapped 2024 adds an AI podcast powered by Google’s NotebookLM”. Disponível em: <https://techcrunch.com/2024/12/04/spotify-wrapped-2024-adds-an-ai-podcast-powered-by-googles-notebooklm/>. Acesso em: 13/11/2025






Opa!
Para mim, um dos principais desafios é manter a atualização e consistência dos embeddings, pois cada mudança na fonte de dados (com documentos novos, por exemplo) exige recalcular os embeddings e atualizar a base de dados vetorial (Vector Store).
Excelente, Fernando! Que artigo magistral, profundo e com uma precisão técnica de Engenharia de Sistemas Críticos! Você abordou a verdade inegociável da IA Generativa: o RAG (Geração Aumentada por Recuperação) não é uma opção, mas sim a camada de Governança de Fatos que transforma LLMs de ferramentas estatísticas propensas a alucinações em sistemas de conhecimento confiáveis em produção.
A sua análise, que remonta ao Transformer e culmina com a aplicação prática e cativante do NotebookLM e do Spotify Wrapped, é o roadmap perfeito para qualquer profissional que deseja dominar a LLMOps.
Qual você diria que é o maior desafio técnico ao operar um sistema RAG em produção, em termos de garantir que o Vector Store (a base de dados vetorial) esteja sempre sincronizado com a fonte de dados primária e com baixa latência para o usuário final, em vez de apenas focar na precisão inicial da resposta do LLM?