



Airflow o Maestro do Big Data
Ultimamente tenho acompanhado a adoção crescente do Apache Airflow por empresas em seus ambientes de big data, haja visto o quão versátil e poderosa é essa ferramenta na orquestração dos pipelines de big data, além do fato de ser altamente escalável e ter alta disponibilidade, características essenciais para big data.
Mas o que é o Airflow?
O Airflow é um orquestrador de fluxos de trabalho, guarde bem essa palavra. O Airflow foi criado em 2014 pelo Airbnb para gerenciar os fluxos de trabalho, posteriormente foi integrado à Apache foundation. Ele é escrito em Python, Open Source e possui uma simples porém poderosa interface de usuário, através da qual é possível interagir com as DAGs, que são o “core” do Airflow. Basicamente o Airflow representa os fluxos de trabalho através de DAGs, a DAG por sua vez é dividida em partes menores chamadas tasks, a DAG especifica a dependência entre as tasks e a ordem de execução delas, já as tasks são as ações realizadas dentro da DAG. Por exemplo, uma DAG seria um pipeline que obtém dados de uma API, processa eles e salva em um data lake, as tasks seriam cada uma das tarefas, requisitar os dados via API, depois processar os dados e então salvar no lake.
O nome DAG quer dizer Directed Acyclic Graph, veja bem que o termo acyclic quer dizer que o Airflow não realiza tarefas cíclicas, conforme podemos ver na imagem abaixo do exemplo de uma DAG.

Exemplo de ciclo de uma DAG
Lembra que acima falei para guardar bem a palavra orquestrador, afinal o Airflow não deve ser usado para processar dados em big data, apesar de poder realizar isso com o Python operator, o Airflow brilha delegando as tarefas como um bom maestro que é. Em big data geralmente o processamento de grandes quantidades de dados fica a cargo do Apache Spark, mas isso é assunto para um outro artigo. Outro ponto importante a se observar é que o Airflow não deve ser usado em pipelines de streaming de dados, mas sim em pipelines de batch de dados.
Componentes do Airflow
Os principais componentes do Airflow segundo a documentação oficial são os seguintes:
WebServer: Interface de usuário através da qual é possível interagir, realizar o acionamento, a inspeção e informações importantes a respeito das DAGs.
Scheduler: Faz o acionamento dos workflows agendados e envia as tasks para o executor.
Executor: É executado quando o Scheduler está ativo no Airflow e realiza o plano de execução das tasks, ou seja ele define a task que cada worker executará. Os quatro principais executores são Sequential Executor, Local Executor, Celery Executor, Kubernetes Executor, também é possível escrever um executor, falaremos com mais detalhes sobre os tipos de executors em artigos futuros.
Workers: Processos que executam as tasks definidas pelo executor.
Metadata database: Local onde o Scheduler, o Executor e o Webserver armazenam o estado da aplicação.
Diretório de DAGs: Pasta onde são armazenadas as DAGs que podem ser lidas pelo Scheduler, pelo executor ou pelos workers.
Abaixo uma imagem que mostra essa arquitetura.
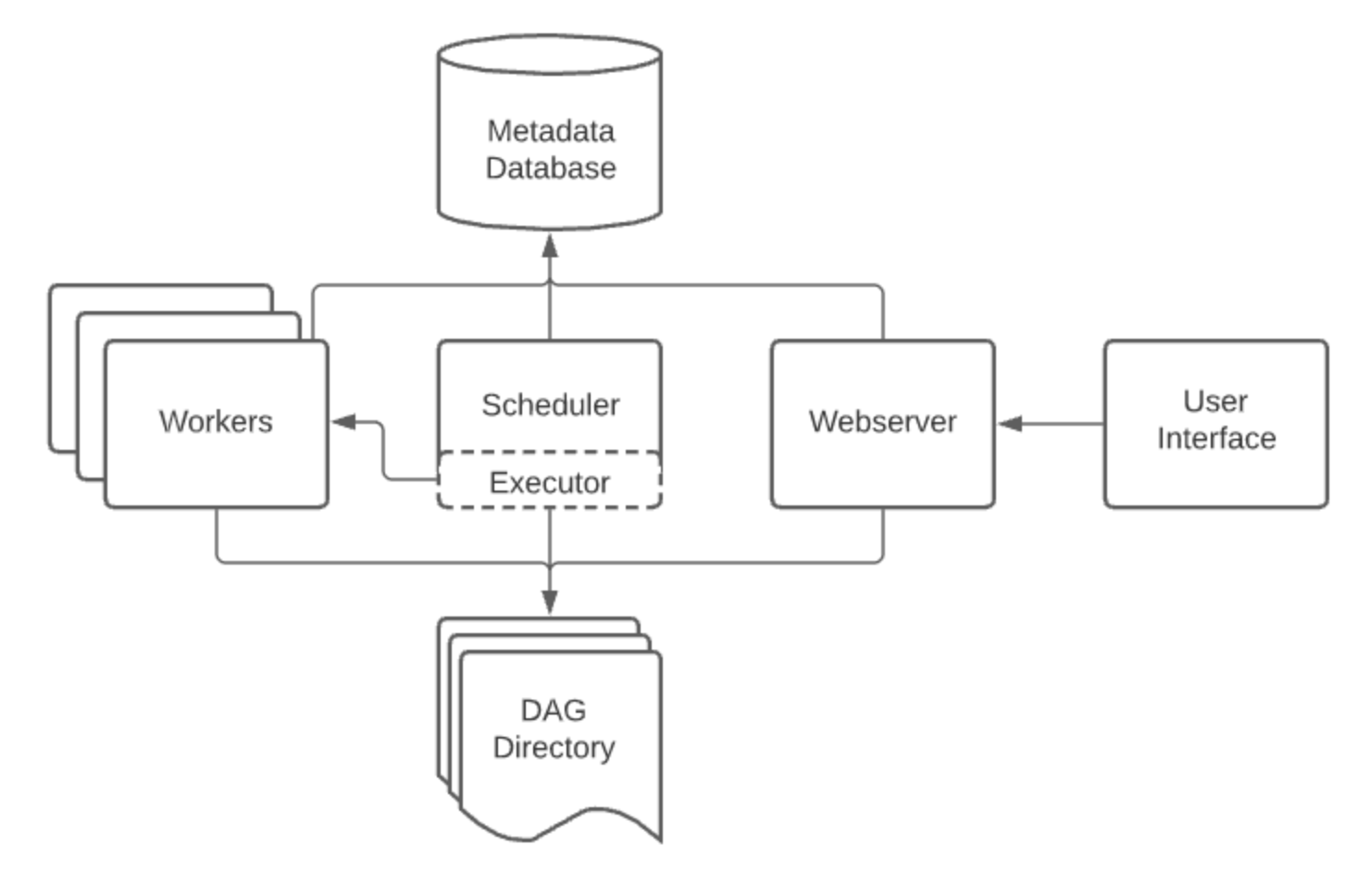
A DAG é a forma como o Airflow orquestra as tarefas, ela é dividida em tasks, os três tipos mais comuns de tasks são:
- Operators - São tarefas predefinidas ou templates prontos, os operadores mais comuns são o Python Operator, Bash Operator entre outras.
- Sensors - subclasse de operadores, basicamente esperam que um evento externo ocorra.
- TaskFlow - Uma função Python empacotada como tarefa.
A interface do usuário
Agora vamos detalhar um pouco mais sobre a interface do usuário.

Na interface do usuário podemos executar, excluir ou verificar informações sobre as dags. A imagem acima mostra a home page, nela podemos ver as DAGs armazenadas no diretório de DAGs por nome, podemos ver as execuções e o status de cada execução, os círculos representam as execuções, a cor verde escuro significa DAG executada com sucesso, verde mais claro indica uma DAG em execução e o vermelho indica uma execução com falha. Na home page ainda podemos ver o tipo de agendamento que pode ser diário, semanal, horário etc, também podemos visualizar a data e o horário da última execução.
Podemos fazer o deploy do Airflow com Docker, Kubernetes, local, ou ainda gerenciado em cloud. Abaixo encontra-se o link do site da Apache, mostrando como instalar o Airflow para uso localmente.
https://airflow.apache.org/docs/apache-airflow/stable/installation/index.html
Primeira DAG
Bom, vamos ao que interessa e vamos escrever um script Airflow e atestar o quanto é fácil criar um pipeline com ele.
Primeiramente começamos importando os módulos.
# [START import_modules]
from datetime import timedelta, datetime
from airflow.models import DAG
from airflow.operators.bash import BashOperator
# [END import_modules]
Uma boa prática é declarar um dicionário com os argumentos default.
# [START default_arguments]
args = {
'owner': 'Fulano de tal',
'depends_on_past': False,
'start_date': datetime(2022, 9, 16), #data de inicio da DAG
'email': ['algum_email@gmail.com'], #email
'email_on_failure': False, #enviar email em caso de falha
'email_on_retry': False,
'retries': 1,
'retry_delay': False,
'schedule_interval': '@daily' #frequencia de disparo
}
# [END default_arguments]
O próximo passo é instanciar a DAG.
# [START instantiate_dag]
with DAG ('simple_pipeline', #nome da DAG
default_args= args, #argumentos default passando dicionario
description= 'Simple pipeline example',
catchup= False, #como False impede o disparo de DAGs que não foram executadas anteriormente desde a data do último disparo
tags= ['airflow', 'pipeline', 'bash'] #localizar a DAG facilmente
) as dag:
# [END instantiate_dag]
Após então criamos as tasks.
# [START tasks]
t1 = BashOperator(
task_id = 'print_date', #id do operator
bash_command = 'date', #executa o comando bash date
)
t2 = BashOperator(
task_id = 'sleep',
depends_on_past = False,
bash_command = 'sleep 5',
retries = 3,
)
# [END tasks]
E por fim definimos o workflow. Voilà! o nosso primeiro pipeline está pronto.
t1 >> t2 #fluxo da DAG
Conclusão
Esse foi um exemplo básico através do qual conseguimos mostrar a versatilidade do Airflow, é claro que essa é uma DAG muito simples apenas para exemplificar, mas à medida que os pipelines crescem a complexidade das DAGs cresce também. Através desse exemplo foi possível verificar por que o Airflow está cada vez mais consolidado como um dos principais orquestradores da atualidade.
Nos próximos artigos vamos nos aprofundar no uso do Airflow, construindo pipelines mais complexos e falando um pouco mais da sintaxe de escrita adotada a partir da versão 2.0 usando os decorators, e do deploy do Airflow no Kubernetes uma dobradinha de respeito.
Um abraço e até a próxima.
#EuSouDIOCampusExpert
Referências:
https://registry.astronomer.io/







Olá Cristiano, tudo bem?
Muito bacana seu artigo, tem algum curso que aborde sobre o apache airflow aqui na DIO ?
Se sim, poderia compartilhar o link por favor?
Olá, tudo bom?
Bacana seu artigo.
Qual sua visão sobre controle de qualidade?
Por favor, posso contar com seu voto no artigo abaixo?
DIO| Codifique o seu futuro global agora
Qual sua opinião? Algo a acrescentar?
Desde já, te agradeço!