
Como a Recuperação de Conhecimento Está Moldando a Próxima Era da Inteligência Artificial
Introdução: Por que falar de IA Generativa e RAG agora?
A IA generativa explodiu como um dos assuntos mais comentados dos últimos anos. Seja criando textos, códigos, músicas ou imagens, ela já está integrada ao dia a dia de estudantes, profissionais e empresas.
Mas existe um elemento que muitas pessoas ainda não conhecem — e que está transformando silenciosamente a maneira como usamos a IA: o RAG (Retrieval-Augmented Generation).
Se a IA generativa é um carro esportivo, o RAG é o GPS que evita que ele se perca.
Neste artigo, vamos entender como essas duas tecnologias se conectam e por que esse casamento é tão poderoso.
Passagem Histórica e Contextualização: De ELIZA aos Transformers, uma Jornada Épica
Embora o RAG pareça fresquinho do forno, a IA tem uma história cheia de altos e baixos desde os anos 1950. Em 1956, na Conferência de Dartmouth, o termo "Inteligência Artificial" nasceu, dando nome a um campo que já borbulhava entre matemáticos e engenheiros visionários. Nos anos 1960, inovações como a miniaturização eletrônica abriram portas para computadores pessoais – e para a cultura geek que amamos hoje.

Nesse caldeirão de ideias, surgiu ELIZA, o chatbot pioneiro que simulava conversas como um terapeuta freudiano (mas sem o divã). Pule para os anos 2000: com explosão de dados e poder computacional, o deep learning decolou com invenções como Restricted Boltzmann Machines (RBMs), autoencoders, LSTMs e GANs. Em 2012, a AlexNet arrasou no ImageNet, selando o reinado do deep learning em visão computacional.
Então vieram os Large Language Models (LLMs) – pense em GPT, Claude ou Gemini –, impulsionados pela arquitetura Transformer de 2017. Eles tornaram as interações homem-máquina naturais como uma conversa de café. Mas aí vem o calcanhar de Aquiles: LLMs são treinados em dados fixos, ficando desatualizados ou imprecisos em tópicos nichados ou fresquinhos. É aqui que o RAG entra como o sidekick perfeito, mesclando a criatividade dos LLMs com buscas em tempo real em fontes externas. Resultado? Respostas que não são só bonitas, mas também atualizadas e confiáveis.
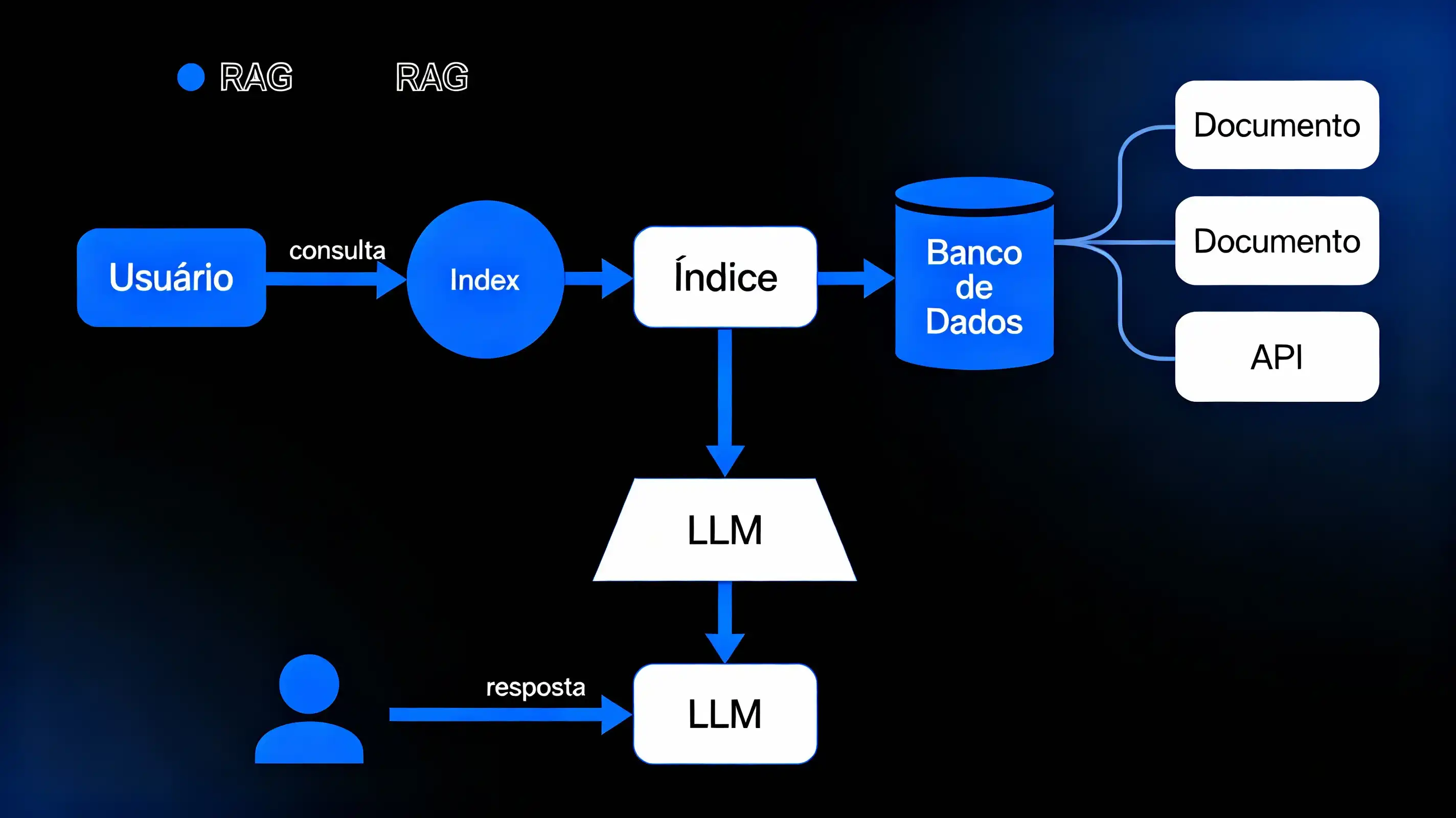
O que é RAG: Conceitos e Arquitetura – Simples como um Café com Leite, Técnico como um Código Limpo
Vamos descomplicar: RAG é como dar óculos de super-herói para um LLM. Em vez de confiar só na "memória" estática do treinamento, ele consulta fontes externas em tempo real para gerar respostas. Tecnicamente, Retrieval-Augmented Generation combina um "retriever" (que busca dados relevantes) com um "generator" (o LLM que compõe a resposta). Diferente de um LLM puro, que pode "alucinar" fatos inventados, o RAG puxa chunks de documentos, bancos de dados ou APIs para embasar tudo.
Arquitetura Básica (Diagrama Descritivo Simples):
Entrada: Query do usuário.
Retriever: Usa embeddings (vetores numéricos que capturam semântica) para buscar em um banco vetorial (como Pinecone ou Weaviate).
Augmenter: Monta o contexto com os melhores resultados.
Generator: LLM processa query + contexto para output.
Saída: Resposta precisa, com menos bobagens.
Isso reduz alucinações porque o LLM é "ancorado" em fatos reais. Comparando: um LLM tradicional é como um contador de histórias solitário; RAG é ele com uma biblioteca infinita ao alcance.
Como Funciona RAG na Prática: Passo a Passo, Sem Enrolação
Imagine uma query: "Quais as regras de devolução da loja X em novembro de 2025?"
Recepção da Query: O usuário pergunta, e o sistema transforma em embedding (usando modelos como OpenAI's text-embedding-ada-002 para capturar essência semântica).
Busca Externa (Retrieval): O retriever compara o embedding da query com índices vetorizados em um banco (ex.: FAISS ou Milvus). Ele usa métricas como cosine similarity para puxar os chunks mais relevantes – pense em blocos de texto de 128-512 tokens, com overlap para não perder contexto.
Construção de Contexto: Ranqueia os top-K (ex.: top-5) e concatena no prompt: "Baseado nestes docs: [chunk1] [chunk2]..., responda: [query]".
Geração de Resposta: O LLM (como GPT-4) gera o output, citando fontes para transparência.
Opcional: Reranking: Um modelo cross-encoder (ex.: BGE-reranker) reordena para máxima relevância, evitando ruído.
Exemplo de Diferença: Sem RAG, um LLM poderia dizer "Devoluções em 30 dias" baseado em dados velhos. Com RAG, ele puxa a política atualizada e responde: "Em novembro de 2025, devoluções em 45 dias para itens sazonais, conforme doc X [citação]". Menos drama, mais precisão!
O que é IA Generativa?
A IA generativa é um tipo de inteligência artificial capaz de criar conteúdo novo. Ela não copia textos, imagens ou informações. Em vez disso, ela gera algo baseado em padrões aprendidos durante seu treinamento.
Pense assim:
É como pedir para alguém que já leu milhares de livros escrever uma história nova. O texto é original, mas inspirado no que ela aprendeu.
Ela pode gerar:
Textos
Códigos
Imagens
Vídeos
Áudio
Resumos
Explicações
E muito mais.
A mágica acontece por meio de modelos conhecidos como LLMs (Large Language Models), que usam bilhões de frases para aprender padrões da linguagem.
Mas, apesar de incríveis, esses modelos têm uma limitação importante:
Eles não sabem tudo — e pior — eles podem "inventar" respostas.
É aí que entra o RAG.
O que é RAG e por que ele importa tanto?
O RAG, ou Retrieval-Augmented Generation, é uma técnica que combina:
Recuperação de informações reais e atualizadas com
Geração de texto baseada nos modelos linguísticos
Imagine que a IA consultasse uma mini biblioteca antes de te responder.
Isso é o RAG.
Em vez de confiar apenas na memória do modelo (treinamento), ele busca dados externos (documentos, PDFs, bases internas, artigos, bancos de dados etc.).
Depois, usa essas informações para gerar uma resposta mais correta, atualizada e contextualizada.
É como juntar:
Google (busca de dados)
com
ChatGPT (geração de linguagem)
Tudo em um único fluxo.
Uma analogia rápida: IA Generativa vs IA Generativa + RAG
Pense que a IA generativa é como um motorista experiente.
Ele geralmente sabe o caminho e dirige bem.
Mas às vezes se confunde — especialmente em ruas novas ou cidades desconhecidas.
Quando você adiciona RAG, é como dar ao motorista um GPS atualizado.
Ele para de confiar somente na memória e passa a usar informações frescas, evitando erros.
Estrutura básica de um sistema RAG
Para entender RAG com clareza, vamos dividir em etapas simples:
1- Ingestão dos dados
Documentos são processados e convertidos em pequenos trechos.
2- Vetorização
Cada trecho vira um vetor matemático.
3- Armazenamento
Os vetores são guardados em um banco vetorial.
4- Recuperação
Quando você faz uma pergunta, o sistema procura vetores semelhantes.
5- Geração com contexto
A IA recebe os trechos relevantes e cria uma resposta fundamentada.
Por que o RAG se tornou essencial para a IA Generativa?
A IA generativa é ótima para criar.
Mas ela tem três limitações sérias:
Não é atualizada constantemente
Pode alucinar (inventar fatos)
Não tem contexto local ou privado
O RAG resolve exatamente isso:
✓ Atualização
Você pode adicionar novos documentos quando quiser.
✓ Veracidade
Ela consulta informações reais antes de responder.
✓ Segurança e privacidade
Empresas podem usar suas próprias bases internas de forma segura.
RAG na IA Generativa: O casamento perfeito para empresas
Quando falamos do uso corporativo da IA generativa, o RAG deixa de ser um extra e passa a ser um pré-requisito.
Imagine uma empresa com:
Políticas internas
Documentos estratégicos
Procedimentos
Normas
Manuais
Dados técnicos
Informações sensíveis
Um modelo de IA sem RAG jamais poderia acessar esses conteúdos.
Com RAG, isso se torna possível e seguro.
Uma história rápida: Meu primeiro contato com RAG
Quando ouvi falar de RAG pela primeira vez, confesso que pensei:
"Isso é só um buscador glorificado."
Mas quando comecei a testar na prática, percebi como era diferente.
Eu fiz um experimento simples: alimentei o sistema com um PDF de 50 páginas e fiz perguntas sobre detalhes específicos.
Sem RAG?
A IA chutava.
Com RAG?
Ela respondia com trechos precisos, como se tivesse acabado de ler o documento.
Ali percebi:
RAG não é um complemento.
É uma camada essencial.
Imagem ilustrativa: Comparação entre IA pura e RAG

IA Generativa + RAG = Menos alucinação
“Alucinação” é quando a IA inventa um dado.
Não porque quer enganar, mas porque tenta preencher uma lacuna.
Com RAG, a IA passa a trabalhar com:
dados reais,
evidências,
trechos concretos.
Isso reduz drasticamente respostas incorretas.
Como construir um sistema RAG (explicação simples)
Aqui vai um passo a passo didático:
1. Prepare seus documentos
Organize PDFs, textos e bases.
2. Divida em partes pequenas
Geralmente entre 200 e 500 caracteres.
3. Converta para vetores
Use modelos de embeddings.
4. Armazene tudo
Sistemas populares:
Pinecone
Milvus
Weaviate
5. Faça uma consulta
O usuário faz a pergunta.
6. Recupere trechos relevantes
O sistema encontra vetores parecidos.
7. Geração final
A IA combina tudo e produz a resposta.
Ferramentas que usam RAG hoje
ChatGPT Memory / Retrieval
LangChain
LlamaIndex
OpenAI Assistants API
Azure AI Search
Pinecone
Estratégias avançadas e boas práticas
RAG vs. Prompt Engineering: Quando usar, limitações e sinergias
Prompt Engineering envolve criar prompts estrategicamente detalhados para “guiar” o LLM usando apenas seu conhecimento embutido. Isso funciona bem quando sua base é estável, o domínio é amplo, e você deseja rapidez, reusabilidade e baixo custo de implementação.
RAG deve ser aplicado quando você:
Precisa de precisão ligada a fontes documentais e atualizadas;
Quer minimizar alucinações na resposta;
Precisa adaptar respostas a regulamentações e contextos mutáveis (medicina, direito, finanças);
Não deseja retrain constante do modelo, apenas atualizar o dado externo.
Principais diferenças técnicas:
Aspecto Prompt Engineering RAG
Fontes de resposta “Memória” do modelo Dados externos recuperados em tempo real
Setup Simples, barato Mais complexo e custoso (infraestrutura extra)
Atualização Precisa de retrain Simples: atualize o dado, não o modelo
Consistência Sensível ao prompt Mais robusto (se retrieval estiver bem configurado)
Performance Rápido, mas limitado Pode ser mais lento (retrieval), mais escalável
Sinergia: Em muitos cenários RAG e prompt engineering são complementares: prompts são usados para determinar o formato, tom e recortes do output — e o RAG garante que o conteúdo seja relevante e referenciável. Por exemplo: no suporte jurídico, prompts são usados para pedir “compare estes precedentes”, enquanto o RAG busca os casos a serem usados.
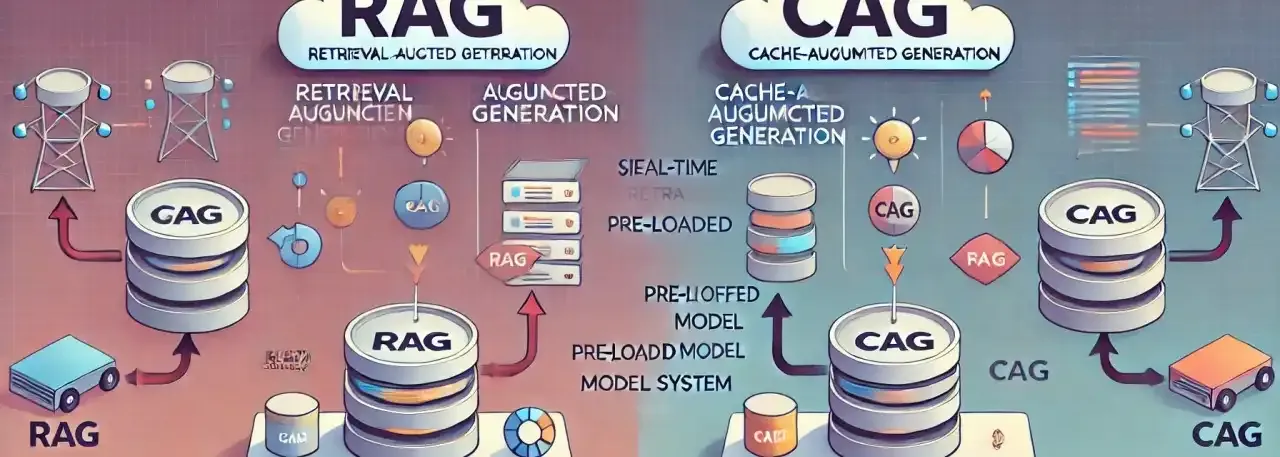
Avanço: Cache-Augmented Generation (CAG) e fusão com RAG
Um problema comum no RAG é o retriever relembrar trechos estáticos que raramente mudam (ex.: políticas da empresa) em todas as queries, o que gera redundância, custo e latência. Cache-Augmented Generation (CAG) resolve isso: as informações estáticas são “cacheadas” (armazenadas na memória interna/KV memory do modelo), enquanto só dados dinâmicos vão para a busca ativa.
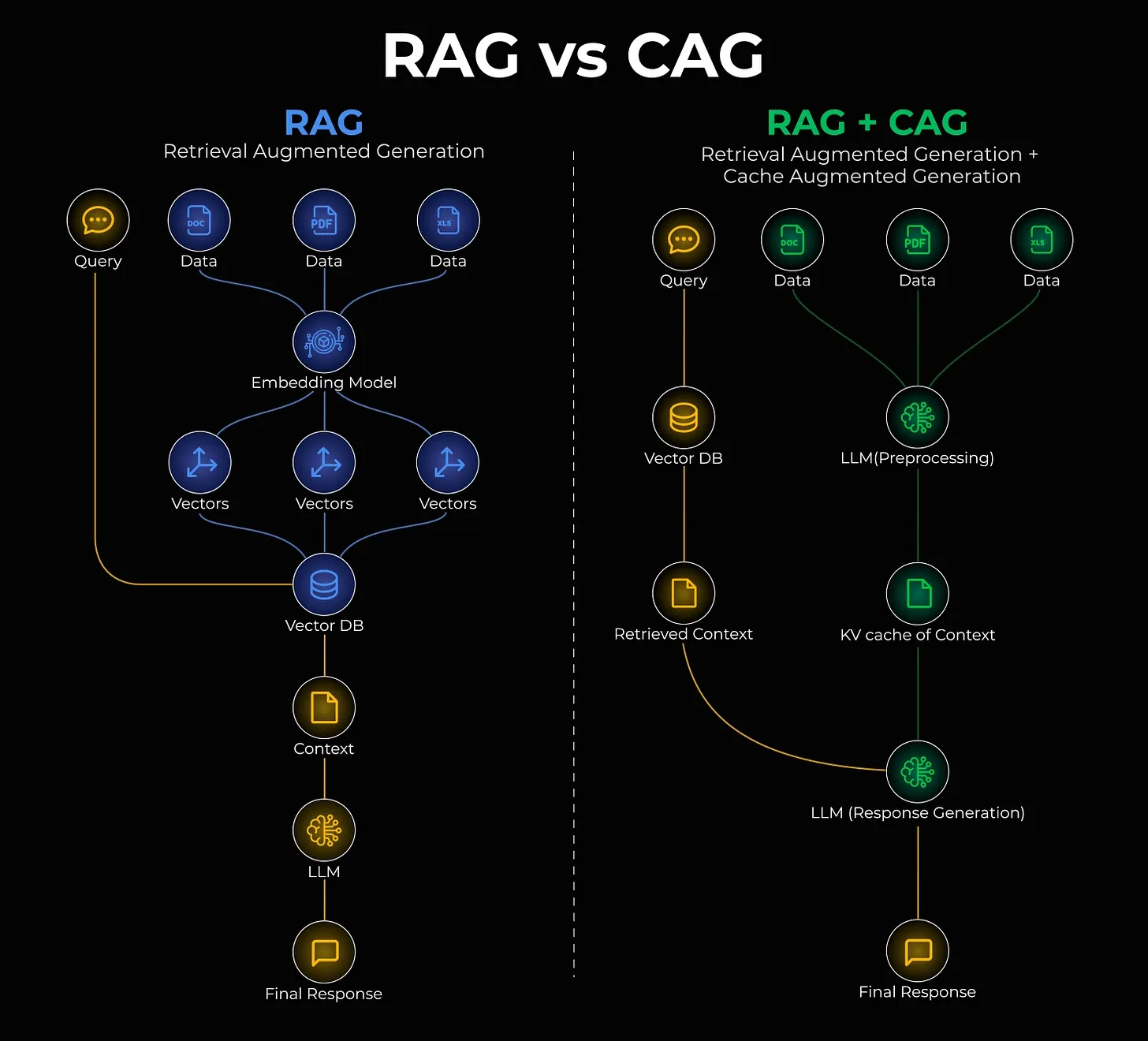
Aplicações Reais e Casos de uso
Exemplo prático: Em um chatbot de RH, as políticas internas podem ser mantidas em cache (CAG), enquanto dúvidas de folhas de ponto recentes são buscadas via RAG. Isso resulta em respostas mais rápidas e eficientes, otimizando o pipeline sem sobrecarregar o modelo ou o banco de dados.
Ponto chave: Para manter eficiência, separe dados "friáveis"/voláteis (RAG) e estáticos (CAG); evite congestionamento de contexto cacheando tudo.
Desafios Técnicos do RAG
Latência e custo: retrieval+generation soma camadas, tornando a resposta mais lenta e cara (infra necessária: banco vetorial, orquestração, manutenção dos índices).
Complexidade arquitetural: configurar corretamente chunking, embeddings, rerankers e monitorando a qualidade dos dados externos é tarefa não trivial.
Dependências e erros de busca: se o retrieval recuperar conteúdo impreciso/incompleto, o LLM pode produzir uma resposta bem escrita, mas incorreta (erro de confiança).
Pipeline Conceitual de um Sistema RAG
Vamos imaginar, passo a passo, o funcionamento de um sistema RAG típico – e por que cada etapa importa:
Usuário faz a pergunta:
Ex: “Quais são as regras de devolução da loja X em novembro de 2025?”
Transformação e busca da query:
A pergunta é convertida em um vetor semântico (embedding) e enviada ao banco de dados vetorial. Esse banco já contém índices/representações vetorizadas dos documentos, contratos e políticas relevantes da loja.
Recuperação dos documentos mais próximos (retrieval):
Com base na semelhança vetorial, o sistema seleciona os trechos (chunks) mais relacionados à pergunta.
Composição do contexto:
O sistema monta um pacote de contexto, geralmente os top-3/topp-5 trechos encontrados, e insere tudo no prompt.
Geração da resposta:
O LLM recebe a query original + contexto relevante e gera uma resposta, citando ou parafraseando trechos extraídos.
(Opcional) Reranking e filtros:
Em sistemas avançados, um segundo modelo (reranker) ordena/revalida as melhores evidências, e filtros removem textos redundantes ou irrelevantes.
Fluxograma descritivo:
Usuário → Embedding da Query → Busca Vetorial → Seleção dos melhores chunks → Prompt LLM → Resposta fundamentada
Exemplo Prático: Código Simplificado com Pseudocódigo
python
# Supondo uso de um framework como LangChain
query = "Como pedir reembolso?"
embedding = gerar_embedding(query)
chunks = buscar_vetorial(embedding, top_k=3) # Busca no banco vetorial
prompt = montar_prompt(query, chunks)
resposta = LLM.gerar_resposta(prompt)
Aqui, gerar_embedding converte texto em vetor, buscar_vetorial retorna os melhores trechos, montar_prompt estrutura o input final. O LLM então responde baseado nesse contexto.
Benefícios do RAG para negócios
Aqui vai uma lista rápida de vantagens reais:
Redução de erros
Respostas consistentes
Menos treinamento necessário
Atualização instantânea
Uso seguro de dados privados
Integração com fluxos internos
Aplicações reais de RAG com IA Generativa
Atendimento ao cliente
Chatbots que usam políticas internas reais.
Jurídico
Consulta a contratos e legislações.
Saúde
Uso de protocolos seguros (com conformidade).
Educação
Explicações baseadas em materiais específicos.
Desenvolvimento
Assistentes que consultam documentação interna.
Visualizando tudo: Como IA Generativa e RAG se complementam
Conclusão: O futuro da IA generativa passa obrigatoriamente pelo RAG
A IA generativa mudou como trabalhamos, aprendemos e criamos.
Mas sozinha, ela ainda tropeça, inventa fatos ou ignora dados recentes.
O RAG surge como a peça que faltava.
Ele transforma a IA em um sistema conectado ao mundo real — capaz de consultar informação atualizada e entregar respostas mais precisas e confiáveis.
Em outras palavras:
A IA generativa é poderosa.
Mas com RAG, ela se torna útil de verdade.
E essa combinação é o que marcará a próxima fase da inteligência artificial.
Referências utilizadas
Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, 2020.
OpenAI Documentation – Retrieval, 2024.
Pinecone Docs – Vector Databases Overview, 2023.
LangChain Documentation – Retrieval Systems, 2024.
Google DeepMind – RAG Architectures Overview, 2023.
https://www.ibm.com/think/topics/rag-vs-fine-tuning-vs-prompt-engineering, 2025
https://www.datacamp.com/tutorial/how-to-improve-rag-performance-5-key-techniques-with-examples, 2025
https://www.meilisearch.com/blog/rag-vs-prompt-engineering?ref=dailydev, 2025
https://blog.dailydoseofds.com/p/rag-vs-cag-explained-visually?ref=dailydev, 2025






Excelente, Teófilo! Que artigo magistral, profundo e absolutamente essencial sobre IA Generativa! Você tocou no ponto crucial: o LLMOps é a próxima fronteira da engenharia de software, garantindo que as soluções de IA não sejam apenas experimentos, mas sistemas confiáveis e escaláveis em produção.
É fascinante ver como você aborda o tema, mostrando que a sinergia entre os Quatro Pilares é o que transforma a promessa da GenAI em realidade corporativa.
Qual você diria que é o maior desafio para um desenvolvedor ao implementar os princípios de IA responsável em um projeto, em termos de balancear a inovação e a eficiência com a ética e a privacidade, em vez de apenas focar em funcionalidades?