


Explorando o ciclo completo de QA 🔎🪲
Testes manuais, automação, bug report e Pull Request, o que aprendi transformando uma aula prática em portfólio real.
Tenho explorado QA como forma de evoluir na carreira, entendendo o processo de ponta a ponta. Foi nesse contexto que participei do Workshop de QA da EBAC.
O que começou como uma tarefa simples terminou com dois repositórios no GitHub, uma Issue aberta em um projeto open source e um Pull Request com a correção de um bug no código-fonte da aplicação que estava testando.
Esse artigo conta como isso aconteceu, e por que o processo importa tanto quanto o resultado.
O começo: uma aula, uma aplicação, dez casos de teste
A proposta do exercício era testar o formulário de cadastro do BugBank, uma aplicação criada para prática de QA, um banco digital fictício cheio de bugs intencionais.
Comecei como qualquer pessoa começa: abrindo o navegador e testando pela interface. Preenchendo campos, clicando em botões, observando o que acontecia. Mas alguns comportamentos não faziam sentido. Mensagens de erro que apareciam em lugares inesperados. Campos que reagiam de formas inconsistentes.
Isso me levou a um passo além, fui até o repositório do BugBank no GitHub para entender o que estava por baixo. Nesse processo, usei IA para me ajudar a interpretar trechos do código que ainda não eram familiares para mim.
Com esse embasamento, escrevi 10 casos de teste estruturados com cenário, pré-condição, passos, resultado esperado. E evolui o documento com rastreabilidade de requisitos.
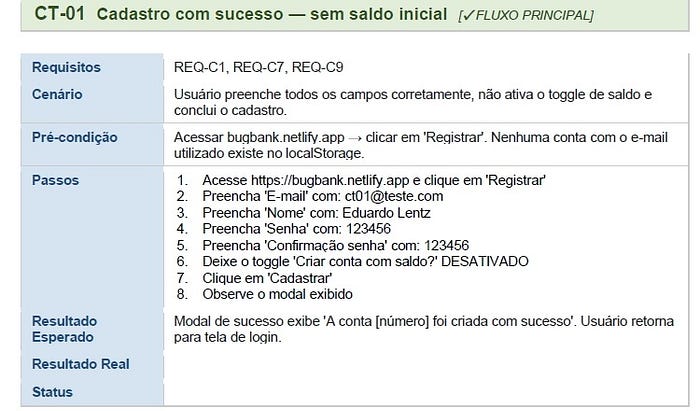
E no processo, encontrei algo inesperado 🔎🪲
O bug que ninguém havia documentado
Ao testar o cadastro com um e-mail que já existia no sistema, esperava ver algo como “E-mail já cadastrado”.
O que aconteceu foi diferente. O sistema aceitou o segundo cadastro sem nenhum erro. A conta anterior foi sobrescrita silenciosamente. A senha original parou de funcionar. Os dados da conta original desapareceram.
Documentei, marquei como bug e segui em frente.
Naquele momento era só uma linha no meu documento. Mas aquele bug seria o fio condutor de todo o restante do projeto.
A virada: de exercício para projeto real
Terminada a etapa manual, veio a pergunta: e se eu automatizasse isso? 🤔
Testes manuais são essenciais, mas têm um limite. Com automação, a mesma suíte que levaria horas rodando manualmente executa em menos de um minuto, e pode rodar toda vez que o código mudar. Decidi automatizar todos os 10 casos de teste usando Playwright com Python, aplicando o padrão Page Object Model: uma forma de organizar o código que separa como navegar na página de o que testar, tornando tudo mais fácil de manter.
O processo não foi linear. Apareceram obstáculos reais, e cada um virou aprendizado.
Obstáculo 1: Dois formulários, um seletor
O BugBank renderiza login e cadastro simultaneamente na página. Quando o Playwright buscava o campo de e-mail, encontrava dois elementos e travava:
strict mode violation: locator("input[name="email"]") resolved to 2 elements
A solução foi identificar um elemento único do formulário de cadastro, o link “Voltar ao login”, e usá-lo como âncora para todos os seletores:
# Âncora: só o formulário de cadastro tem esse link
self.formulario = page.locator('#btnBackButton').locator('../..')
# Agora todos os campos buscam dentro do formulário certo
self.campo_email = self.formulario.locator('input[name="email"]')
Obstáculo 2: O id não estava onde eu esperava
O código-fonte define id="btnRegister" no componente <Button>. Parecia óbvio. Mas após a compilação do React, esse id fica em um <span> interno, não no <button>. O Playwright não encontrava nada e o teste travava esperando 30 segundos.
Escrevi um script de diagnóstico para inspecionar o DOM real:
seletores = ["#btnRegister", "button:has-text('Cadastrar')"]
for s in seletores:
print(page.locator(s).count(), s)
# Resultado:
# 0 #btnRegister ← não encontrou
# 1 button:has-text('Cadastrar') ← este funciona
Esse tipo de investigação, inspecionar o DOM real em vez de confiar no código-fonte, é uma habilidade fundamental em automação. Frameworks como React compilam componentes de formas que nem sempre correspondem ao que está escrito.
O resultado final
Depois de resolver cada obstáculo, a suíte ficou verde:
10 passed in 37.92s
Dez casos de teste. Todos verdes. Em menos de quarenta segundos.
O que ninguém te conta: testes sem evidência não existem
Com a suíte funcionando, percebi que faltava algo importante.
Em ambiente profissional, executar testes não é suficiente, você precisa provar que executou. Precisa de evidência: data, hora, o que passou, o que falhou, quanto tempo levou.
Construí um plugin do pytest que intercepta os resultados e grava automaticamente um relatório a cada execução:
=================================================================
RELATÓRIO DE EXECUÇÃO, BugBank QA Automation
=================================================================
Data/hora início : 02/06/2026 23:24:01
Data/hora fim : 02/06/2026 23:24:55
Duração total : 54s
Ambiente : https://bugbank.netlify.app
-----------------------------------------------------------------
Total de testes : 12 Passaram : 11 Falharam : 0
=================================================================
RESULTADO POR CASO DE TESTE
-----------------------------------------------------------------
PASSOU ✓ | test_ct01_cadastro_sem_saldo (2.66s)
PASSOU ✓ | test_ct02_cadastro_com_saldo (4.77s)
PASSOU ✓ | test_ct03_nome_em_branco (2.35s)
...
XFAIL - | test_bug_001_email_duplicado (6.32s)
=================================================================
RESULTADO FINAL: TODOS OS TESTES PASSARAM
=================================================================
Repara no XFAIL. Esse é o BUG-001, o e-mail duplicado.
Em vez de deixar o teste falhar e quebrar a suíte inteira, usei @pytest.mark.xfail: uma marcação que diz ao pytest "esse teste vai falhar, e isso é esperado enquanto o bug existir". Quando o bug for corrigido, ele aparece como XPASS, nos avisando que a documentação precisa ser atualizada. O bug também ganhou seu próprio relatório em Markdown, gerado automaticamente pelo teste, com descrição, passos e análise técnica.
Fechar o ciclo: do bug ao Pull Request
Com tudo documentado, ficou evidente o próximo passo.
Abri a Issue #61 no repositório original do BugBank com descrição precisa, passos para reproduzir, causa raiz identificada no código e link para o repositório de automação como evidência.
Depois fiz um Fork do projeto, criei uma branch dedicada e apliquei a correção. Foram quatro linhas adicionadas em src/components/FormRegister/index.tsx, logo antes de salvar o cadastro:
// ✅ Correção BUG-001, verifica e-mail duplicado antes de salvar
if (localStorage.getItem(email)) {
onCallModal('error', 'E-mail já cadastrado.\n');
return;
}
O PR #62 foi aberto referenciando a Issue. O ciclo estava fechado:
Testes manuais → Automação → Relatório → Bug report → Bug fix
O que esse processo ensinou
Olhando para o que construí, o que mais me marcou não foi nenhuma ferramenta ou linha de código. Foi perceber como cada etapa alimenta a próxima.
Os testes manuais definiram o escopo da automação. A automação gerou evidências e documentou o bug. O bug documentado embasou a Issue. A Issue fundamentou o PR. Nada foi isolado.
Em QA, tendemos a pensar nas etapas separadamente, “agora faço os testes manuais”, “agora automatizo”. Mas o valor real aparece quando elas se conectam. Quando o bug que você encontrou manualmente vira um teste automatizado, que vira um relatório, que vira uma Issue, que vira uma correção no código.
Esse é o ciclo. E percorrê-lo do início ao fim, mesmo em escala pequena, mudou como eu entendo o trabalho de QA.
Repositórios do projeto:
Certificado
E fica aqui o certificado dessa experiência. Que venham mais desafios.

. . . . . . . . . . .
Eduardo O. Lentz
💻 Portfolio | 🔗 LinkedIn | 📂 GitHub | 📝 Medium | 📸 Instagram






