

LATÊNCIA EM PRODUÇÃO: POR QUE “MAIS CPU” QUASE NUNCA RESOLVE
- #Java
Domain - Performance & Production Engineering
Reading Time - 10m 30s
Complexity - Advanced
Opening thesis
Em sistemas Java de alta concorrência, latência raramente é causada simplesmente por falta de CPU.
Na maioria dos ambientes de produção maduros, CPU elevada é consequência de degradação operacional progressiva, e não sua origem. O comportamento observado em produção normalmente emerge da interação entre filas, contenção de sincronização, pressão de heap, espera em recursos compartilhados e dependências externas lentas.
O problema é que muitos sistemas começam a degradar de forma silenciosa antes do colapso perceptível. Nesse estágio, a aplicação ainda responde, os dashboards ainda parecem “aceitáveis” e a infraestrutura aparentemente continua saudável. O aumento de latência é tratado como um problema de escala computacional, quando na realidade o sistema já entrou em um estado de propagação de pressão distribuída.
É exatamente nesse ponto que decisões técnicas equivocadas começam a amplificar o custo sem resolver a causalidade.
Adicionar instâncias antes de entender o comportamento operacional da aplicação é uma das formas mais comuns e mais caras de mascarar gargalos arquiteturais.
Performance madura não começa em autoscaling.
Começa pela explicabilidade operacional.
O erro operacional mais comum em produção.
Em ambientes financeiros de alta carga, o comportamento observado em produção frequentemente engana. Um aumento progressivo de P99 normalmente dispara uma reação quase automática:
latência sobe→ CPU aumenta→ adiciona mais instâncias
À primeira vista, a decisão parece lógica. Afinal, se o sistema está “sobrecarregado”, mais capacidade computacional deveria aliviar a pressão.
Mas sistemas distribuídos raramente degradam de maneira linear.
O que normalmente acontece é mais sutil. Threads começam a esperar recursos compartilhados. Filas internas crescem silenciosamente. Pools entram em saturação parcial. Dependências downstream passam a responder mais lentamente. O heap permanece continuamente pressionado. O tempo gasto em coordenação aumenta. Então, apenas como consequência desse acúmulo operacional, a CPU finalmente sobe.
Nesse estágio, escalar infraestrutura apenas redistribui pressão temporariamente.
O gargalo estrutural continua existindo.
Esse comportamento é extremamente comum em plataformas Java financeiras porque throughput elevado aumenta sensibilidade a:
- Espera;
- Contenção;
- Coordenação temporal;
- Propagação de latência;
- Pressão de alocação.
Sistemas raramente “quebram” instantaneamente.
Eles degradam progressivamente até que a degradação finalmente se torne visível.
Latência não é
Uma das interpretações mais perigosas em troubleshooting é tratar a latência como um problema localizado.
Em produção, latência quase nunca nasce em um único ponto do sistema. Ela emerge da interação entre múltiplos mecanismos operacionais concorrentes.
Uma requisição aparentemente lenta pode, na realidade:
- Estar aguardando uma conexão;
- Esperando lock;
- Bloqueada por I/O;
- Presa em backlog interno;
- Aguardando CPU após saturação de pool;
- Sofrendo impacto indireto de pressão de heap;
- Acumulando retries downstream.
Isso muda completamente a forma correta de diagnosticar sistemas.
O problema deixa de ser:
“Qual método está lento?”
E passa a ser:
“Qual mecanismo operacional está propagando pressão através do sistema?”
Essa distinção é crítica.
Porque throughput degradado frequentemente é resultado de coordenação ineficiente sob carga crescente, e não simplesmente de processamento insuficiente.
A ilusão da CPU alta
CPU é um dos sinais mais mal interpretados em observabilidade.
Muitos times tratam CPU elevada como evidência imediata de falta de capacidade computacional. Porém, em sistemas Java concorrentes, a CPU frequentemente sobe depois que o sistema já entrou em degradação operacional.
Threads em espera aumentam a pressão de coordenação. Context switching cresce. Pools saturados elevam backlog. Requisições passam mais tempo vivas. Objetos permanecem mais tempo no heap. A pressão de alocação aumenta. O GC trabalha mais intensamente. Finalmente, o sistema começa a consumir CPU de forma agressiva.
Nesse cenário, CPU é sintoma.
Não causa.
Isso explica por que tantas estratégias de escala falham em estabilizar a latência de forma duradoura. O sistema recebe mais capacidade computacional sem que o comportamento responsável pela degradação tenha sido realmente corrigido.
O que sistemas maduros medem primeiro?
Times operacionalmente maduros raramente iniciam o troubleshooting olhando apenas dashboards superficiais.
Eles tentam reconstruir causalidade operacional.
Antes de qualquer decisão de escala, normalmente investigam:
- Comportamento de threads sob carga real;
- Tempo gasto em espera;
- Contenção de sincronização;
- Allocation rate;
- Pressão contínua de heap;
- Saturação de pools;
- Crescimento de filas internas;
- Latência downstream;
- Percentis P95 e P99;
- Frequência e duração de pausas de GC.
Isso acontece porque médias escondem degradação progressiva.
O sistema pode apresentar tempo médio aceitável enquanto percentis extremos já demonstram comportamento instável sob pressão.
P99 elevado frequentemente é um dos primeiros sinais reais de propagação operacional.
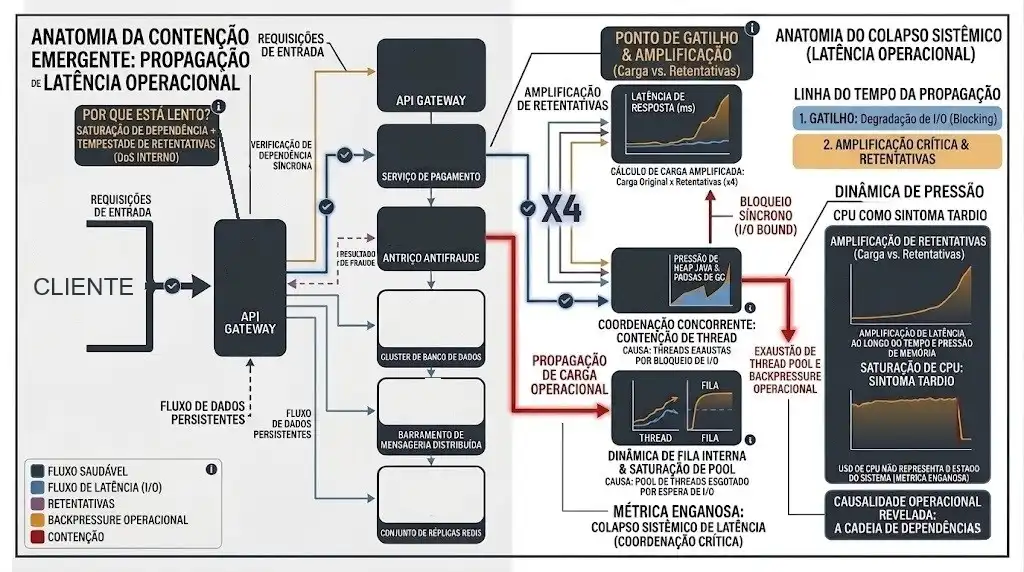
Propagação Sistêmica de Latência - Fonte: Arcevo pessoal.
Profiling não é otimização. É uma explicação
Muitas iniciativas de performance falham porque começam tentando “otimizar” antes de explicar.
Sem profiling adequado, tuning vira tentativa e erro operacional.
O problema é que sistemas modernos possuem comportamento emergente. Gargalos raramente aparecem explicitamente no código-fonte. Eles emergem da forma como:
- Threads competem;
- Memória é alocada;
- Recursos são compartilhados;
- Workloads se acumulam;
- Dependências interagem sob pressão.
É por isso que profiling maduro não procura apenas métodos lentos.
Ele tenta reconstruir a dinâmica de execução.
Flame graphs, allocation rate, waiting threads, hot methods e lock contention não são métricas isoladas. Eles são mecanismos de interpretação comportamental do runtime.
Sem isso, qualquer ajuste é apenas hipótese operacional.
Virtual threads não eliminam gargalos sistêmicos
A chegada das Virtual Threads gerou uma interpretação perigosa em parte da comunidade Java: a ideia de que a concorrência barata resolve automaticamente o throughput.
Mas concorrência e capacidade computacional são problemas diferentes.
Virtual Threads melhoram drasticamente workloads I/O bound porque reduzem o custo operacional da espera. Elas permitem que milhares de operações bloqueantes coexistam sem o mesmo overhead das platform threads tradicionais.
Isso é extremamente poderoso em:
- Chamadas externas;
- APIs lentas;
- Operações de banco;
- Workloads altamente bloqueantes.
Mas nada disso elimina:
- Saturação de CPU;
- Algoritmos ineficientes;
- Lock contention;
- Pressão de heap;
- Downstream lento;
- Coordenação excessiva.
Se o sistema é predominantemente CPU-bound, o ganho tende a ser muito menor do que o esperado.
Virtual Threads reduzem custo de blocking.
Elas não removem limites físicos de processamento.
GC e a falsa sensação de “Problema no coletor”
Outro erro recorrente em troubleshooting é assumir que pausas de GC significam necessariamente um “GC ruim”.
Na prática, GC frequentemente apenas expõe comportamento inadequado de alocação.
Quando workloads geram pressão contínua de objetos temporários sob throughput elevado, o heap permanece constantemente tensionado. O coletor então passa a trabalhar de maneira mais agressiva para sustentar a estabilidade operacional.
Nesse cenário, trocar coletor sem entender causalidade raramente resolve o problema estrutural.
Os sinais mais comuns incluem:
- Spikes de latência;
- P99 degradado;
- Full GC frequente;
- Heap persistentemente pressionado;
- Allocation rate incompatível com o perfil de carga.
O coletor normalmente não é o mecanismo primário da degradação.
Ele apenas torna visível um comportamento operacional já instável.
Sob a perspectiva do FSE, latência não é apenas um problema de performance.
Ela é manifestação operacional de pressão distribuída sob coordenação imperfeita.
O sistema começa apenas “mais lento”. Depois:
- Filas aumentam;
- Threads aguardam;
- Pools saturam;
- Heap pressiona;
- GC intensifica atividade;
- Retries ampliam carga;
- Downstream acumula espera.
Em algum momento, a degradação deixa de ser localizada.
Ela passa a se propagar sistemicamente.
Distributed pressure propagation
A ideia de que pressão operacional se move progressivamente através:
- Da concorrência;
- Da coordenação;
- Da espera;
- Da sincronização;
- Da saturação compartilhada.
Esse mesmo comportamento reaparece em:
- Retry storms;
- Filas distribuídas;
- Degradação de throughput;
- Saturação de consumers;
- Amplificação de timeout.
Ou seja: o problema nunca foi apenas “latência”.
O problema é como sistemas distribuídos propagam pressão sob carga crescente.
Grande parte das decisões equivocadas em performance nasce de uma interpretação superficial do comportamento operacional.
Quando a CPU sobe, a tendência natural é adicionar capacidade. Quando P99 degrada, a reação imediata costuma ser escalar infraestrutura. Mas sistemas distribuídos modernos raramente falham por ausência simples de processamento.
Eles degradam porque a coordenação sob pressão é difícil.
Latência emerge de espera acumulada. Filas aumentam porque recursos compartilhados começam a competir sob carga crescente. O heap permanece pressionado porque requisições vivem mais tempo no sistema. O GC intensifica a atividade porque o throughput operacional já entrou em instabilidade parcial. Então, apenas no estágio final da degradação, a CPU finalmente sobe.
Nesse ponto, escalar infraestrutura sem compreender causalidade operacional apenas redistribui pressão temporariamente.
Não corrige o comportamento responsável pela degradação.
Esse é o motivo pelo qual a engenharia de performance madura não começa tentando aumentar a capacidade computacional. Ela começa tentando explicar o comportamento sistêmico.
Porque sistemas distribuídos não falham apenas por falta de recursos.
Eles falham quando a pressão operacional deixa de ser controlável.
E o mesmo padrão discutido neste artigo reaparece continuamente em retry storms, saturação de filas, degradação progressiva de throughput e falhas de coordenação distribuída, temas que continuarão expandindo os modelos operacionais do framework FSE nas próximas publicações.
Conceitos relacionados a este artigo
- Queue Saturation.
- GC pressure.
- Distributed pressure propagation.
- Backpressure.
- Virtual threads.
- Lock Contention.
- Profiling em Runtime.




