

O que é o Machine Learning?
- #Machine Learning
Você já utiliza Machine Learning no seu dia a dia sem perceber! Por exemplo, quando você faz uma busca no Google para encontrar uma receita de jantar ou pesquisar um restaurante para ir, o buscador funciona bem porque utiliza algoritmos de Machine Learning para classificar as páginas da web. Da mesma forma, quando você assiste a um filme no seu aplicativo de streaming favorito e ele sugere outros filmes que podem te agradar, isso também é resultado do uso de aprendizado de máquina.
Afinal, o que é de fato Machine Learning?
Machine Learning (ML), ou Aprendizado de Máquina em português, é uma área da inteligência artificial (IA) que se concentra em construir algoritmos e modelos estatísticos capazes de executar tarefas específicas sem receber instruções explícitas. Imagine ensinar um computador a aprender por conta própria, sem programá-lo diretamente.
Como surgiu o Machine Learning?
O termo “Machine Learning” surgiu pela primeira vez em 1950 por Arthur Samuel. Ele escreveu um programa para jogar damas, mesmo não sendo um bom jogador. O que Samuel fez foi programar o programa para jogar milhares de partidas contra si mesmo, capturando as posições vencedoras e as derrotadas. Com o tempo, o programa aprendeu sozinho a jogar damas, derrotando Samuel nas partidas.
Nas últimas décadas, os avanços tecnológicos criaram muitas oportunidades para o desenvolvimento do aprendizado de máquina. Hoje, muito se fala sobre Deep Learning, Processamento de Linguagem Natural e Visão Computacional. No entanto, antes de nos aprofundarmos nesses tópicos, é essencial entender a base e o funcionamento dos principais algoritmos de aprendizado de máquina.
Como é construido um modelo de Machine Learning?
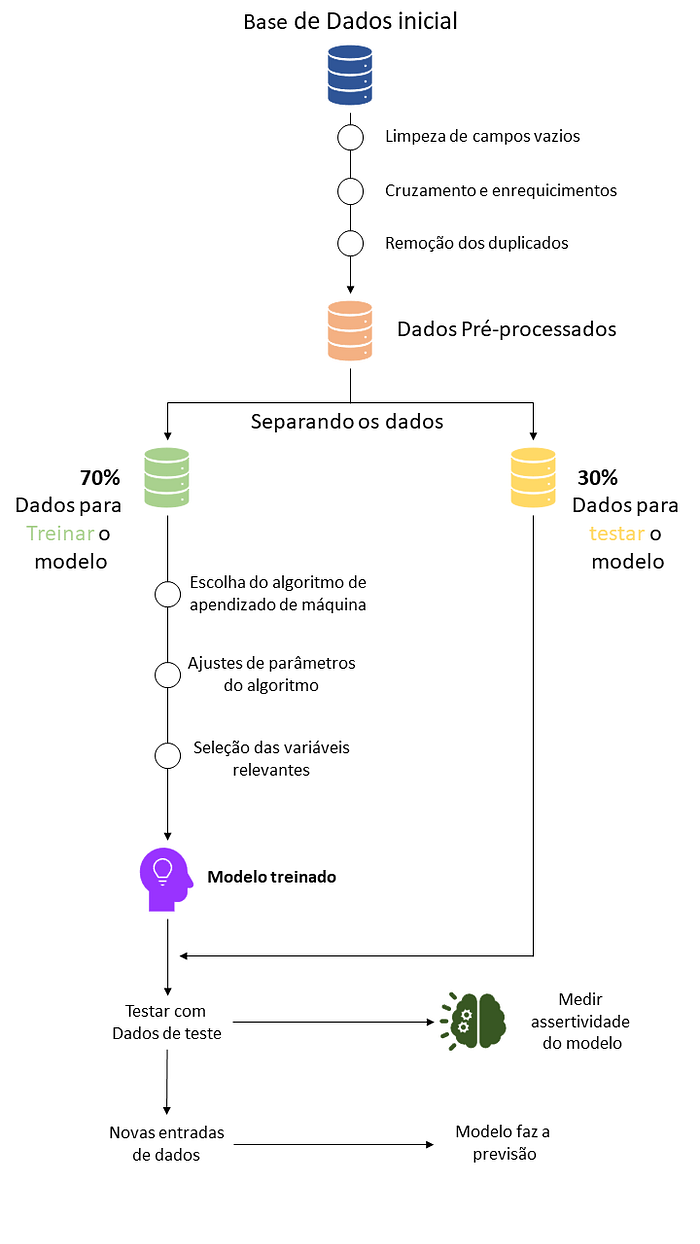
Antes de entrarmos nos algoritmos e entendermos melhor como funcionam os cálculos, e qual o melhor algoritmo para cada situação, vamos compreender como funciona a criação de um modelo. Principalmente para quem está chegando novo no assunto, pode parecer um pouco abstrato entender qual é realmente o fluxo dessa criação de modelos.
-Parte 1 — Dados Iniciais: Aqui é onde começamos, com nosso banco de dados. Esses dados, em sua grande maioria, estão “cru”, então precisamos realizar o que chamamos de tratamento de dados e/ou modelagem. Isso envolve limpar campos vazios, fazer cruzamentos e enriquecimentos, aplicar regras de negócios, remover duplicados e detectar outliers.
-Parte 2 — Dados Pré-processados: Nessa etapa, realizamos a separação dos dados entre variáveis de características e a variável preditora. Vamos pegar um exemplo: se temos um conjunto de dados com características de animais e queremos descobrir se é um cachorro ou não, as variáveis de características seriam o número de patas, a cor do pelo, o comprimento do pelo, o formato do focinho, etc. A variável preditora seria se ele é ou não um cachorro.
-Parte 3 — Separação dos Dados: Aqui é onde dividimos nossos dados entre dados de treinamento e dados de teste. Não é uma regra fixa, mas podemos fazer uma divisão, por exemplo, de 70% para treinamento e 30% para teste. Podemos fazer uma analogia com a escola: os 70% representam as aulas, trabalhos e afins, que são utilizados para nosso aprendizado e conhecimento, enquanto os 30% representam as provas, onde demonstramos que realmente aprendemos o conteúdo e sabemos aplicá-lo.
-Parte 4 (ou 3.5) — Treinamento: Dentro dos 70% de dados de treinamento, precisamos selecionar o algoritmo desejado. Esse é um passo muito importante, pois depende diretamente do tipo de dado que estamos tratando e do resultado esperado. Mais adiante neste mesmo artigo, veremos os diferentes tipos de algoritmos disponíveis para o Machine Learning.
Aplicamos os ajustes. Quando nos aprofundarmos em cada algoritmo, poderemos observar que existem ajustes que podem ser realizados para nos ajudar a obter resultados de maneira mais eficiente.
Seleção das Variáveis Relevantes: Nem todas as variáveis disponíveis em nosso banco de dados serão relevantes para o Machine Learning. Isso dependerá muito do que temos disponível e do resultado almejado.
Parte 5 — Teste: Após treinar a máquina com os 70%, vamos testá-la com os 30% restantes. É hora da prova! Nesse momento, medimos a acurácia. No nosso exemplo, vamos considerar que a acurácia desejada seja de 80%.
Uma vez que a máquina passa pela fase de teste, podemos começar a alimentá-la com novos inputs, ou seja, variáveis de características sem sabermos o resultado correto, e aguardar a máquina realizar a predição.
Construindo um modelo de Machine Learning
É importante ressaltar que esse fluxo não é uma regra a ser seguida à risca, mas na grande maioria dos casos, é seguido de forma muito próxima ao que vimos aqui.
Quais são os algortimos?
Dentro dos algoritmos hoje conhecidos e utilizados, podemos dividi-los em dois principais grupos: Aprendizado Não Supervisionado e Aprendizado Supervisionado. Neste artigo, não vamos nos aprofundar em cada algoritmo, mas iremos entender um pouco sobre as principais diferenças.
Aprendizado supervisionado
A abordagem do aprendizado supervisionado emprega conjuntos de dados rotulados que são treinados para classificar ou prever os resultados. Aqui a máquina é treinada com uma amostragem de dados já conhecidos. O objetivo é fazer com que o modelo aprenda a mapear entradas (características) para saídas (rótulos) com base nos exemplos fornecidos. São dois os principais algortimos:
- Classificação: Classifica os dados em segmentos específicos. Aqui o rótulo é uma categorização (ou classe).
- Regressão: Avali a relação entre uma variável independente com um ou diversos fatores isolados. Aqui o rótulo é um valor numérico.
Aprendizado não supervisionado
Já com o aprendizado não supervisionado vai trabalhar com conjuntos de dados sem rótulos conhecidos, vai coorelacionar os dados e classificar as semelhanças, identificando assim padrões. O principal algoritimos é:
- Clustering: Tem base nas semelhanças e diferenças entre os dados, argupando as similhares.
Já sei o que é Machile Learning, e agora?
Este artigo trouxe apenas um resumo do que é Machine Learning (ML), para que você comece a entender todo o ecossistema. A partir daqui, vamos nos aprofundar em cada algoritmo de aprendizado e iniciar os laboratórios para colocar toda nossa bagagem teórica em prática.
Nos vemos nos próximos capitulos!
Font: https://medium.com/@diogoroehrs/o-que-%C3%A9-o-machine-learning-100500ac847




