

Rodando modelo IA phi4-mini da Microsoft no linux localmente
A um tempo atrás fiz alguns testes com o modelo phi4-mini localmente via ollama e gostaria de compartilhar como é facil e interessante rodar um modelo local.
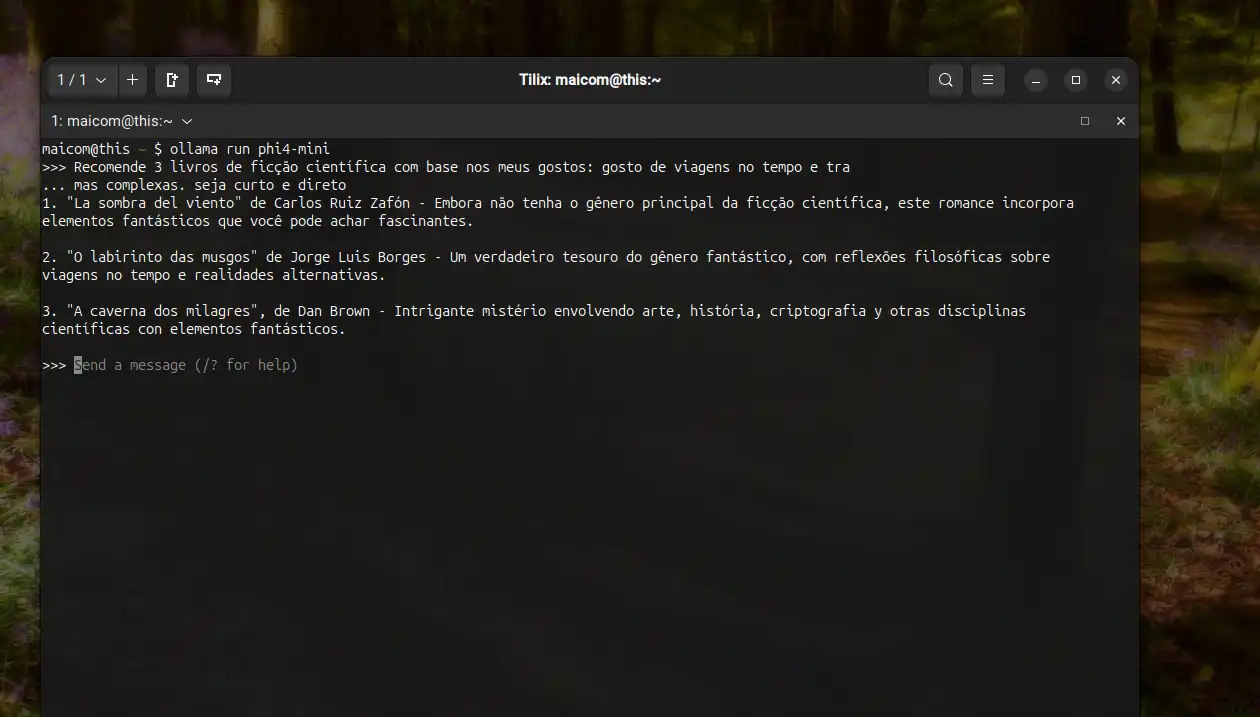
O mais interessante desse modelo é que apesar de ser capaz de utilizar GPU ele roda muito bem no CPU.
Meu notebook é um Dell 11th Gen Intel® Core™ i7-1165G7 × 8 - 16GB RAM
Como instalar:
O melhor é que eu não baixo o modelo diretamente e sim via ollama que é uma especie de gerenciador de modelos, ou seja, consigo baixar vários modelos diferentes.
Via terminal os comandos úteis que eu mais utilizei foram
Para baixar o modelo phi4-mini:
$ ollama pull phi4-mini
O modelo é grande e pode baixar quase 6GB
Depois de baixado pode ver os modelos com ollama list
$ ollama list
NAME ID SIZE MODIFIED
phi3:latest 4f2222927938 2.2 GB 2 weeks ago
phi4-mini:latest 78fad5d182a7 2.5 GB 2 weeks ago
e para rodar simplesmente execute
ollama run <nomedomodelo>
Como instalar o ollama?
No proprio site você pode rodar o comando que irão sugerir no terminal
https://ollama.com/download
Também é possível executar no windows e no mac, mas não cheguei a testar.
Eu analisei a velocidade que o modelo tende a responder depende da complexidade e tamanho do prompt, quando mais simples mais rapido, mas vai variar muito dependendo do seu hardware e sempre que possível use GPU(o que é meio chato de configurar no ollama para esses modelos)
Geralmente eu coloco no prompt para responder em português e de forma curta(esse modelo tende a gerar textos gigantes se deixar) mas pode criar uma especie de skill para inicializar como prompt inicial e evitar já no automático esses problemas.




