

🚀 Vibe Coding Seguro: produtividade com segurança desde o Pull Request 🔐
- #IA Consciente
- #Segurança da Informação
- #Vibe Coding
Muito se fala em Vibe Coding como sinônimo de produtividade extrema, criatividade acelerada e desenvolvimento assistido por IA. Ferramentas modernas como Lovable, Antigravity, automações inteligentes e geração de código estão mudando completamente a forma como aplicações são construídas.
Mas junto dessa evolução surgiu uma crítica muito forte:
“Vibe Coding é rápido… porém inseguro.”
Será mesmo?
Recentemente resolvi transformar essa discussão em um experimento prático e validar, na prática, se é possível construir uma aplicação moderna utilizando puro Vibe Coding sem abrir mão de segurança, qualidade e governança.
E o resultado foi muito mais interessante do que eu imaginava.
🧪 O experimento
Desenvolvi uma aplicação utilizando uma abordagem fortemente baseada em automação e IA, com foco em produtividade extrema.
A aplicação foi construída utilizando:
- Lovable
- Antigravity
- automações de desenvolvimento
- geração assistida por IA
- workflows modernos de CI/CD
Mas o ponto principal não era apenas desenvolver rápido.
O verdadeiro objetivo era responder uma pergunta crítica:
“É possível tornar o Vibe Coding confiável em ambientes reais?”
🎯 Objetivo do estudo de caso
O experimento tinha três pilares principais:
✅ Validar produtividade real com Vibe Coding
✅ Aplicar DevSecOps desde o Pull Request
✅ Garantir segurança contínua sem reduzir velocidade
A ideia era simples:
Se a IA acelera o desenvolvimento, então a segurança também precisa acelerar junto.
Em vez de revisar segurança apenas no final do projeto, toda a aplicação passou a ser monitorada continuamente através de uma pipeline automatizada de segurança executada a cada Pull Request.
Ou seja:
Cada alteração de código precisava sobreviver a uma bateria de validações antes do deploy.
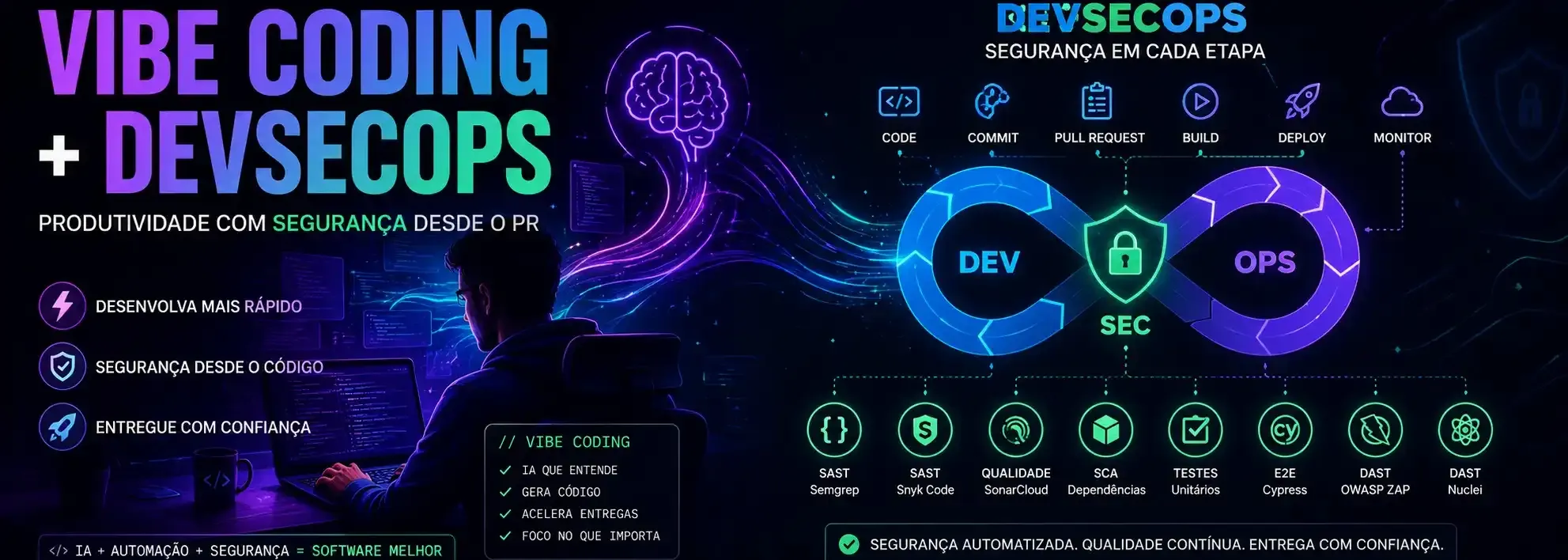
🔄 Arquitetura da pipeline
A pipeline foi estruturada seguindo princípios de:
- Shift Left Security
- Secure by Design
- CI/CD seguro
- automação contínua
- AppSec integrada ao fluxo DevOps
Abaixo está a visão da pipeline utilizada no experimento:
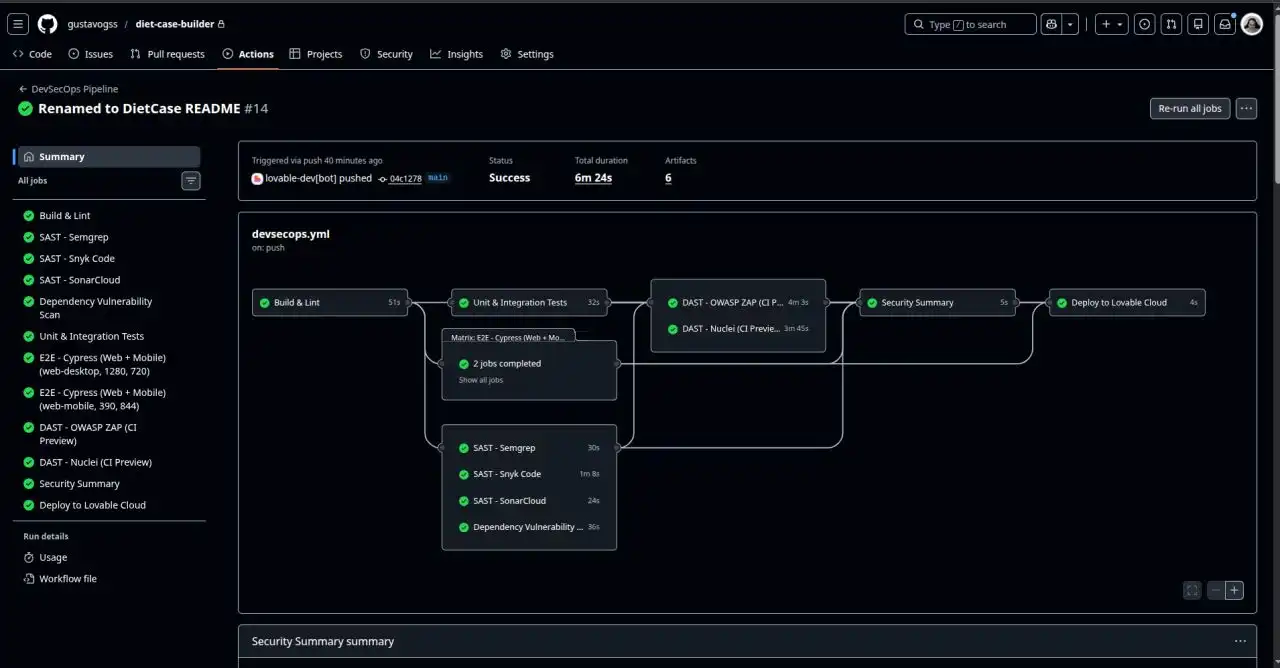
🛠 Etapas da pipeline de segurança
A pipeline foi executada automaticamente a cada Pull Request.
Isso significa que nenhuma alteração chegava em produção sem passar por validações técnicas e testes de segurança.
✔ Build & Lint
Primeira camada da pipeline.
Responsável por:
- validar compilação,
- padronização,
- qualidade inicial do código,
- evitar problemas básicos antes das análises profundas.
Essa etapa já reduz muito ruído operacional.
✔ Semgrep — SAST
O Semgrep foi utilizado para análise estática de segurança (Static Application Security Testing).
Ele identifica:
- padrões inseguros,
- hardcoded secrets,
- validações frágeis,
- vulnerabilidades comuns,
- más práticas de desenvolvimento.
O interessante aqui é que o feedback acontece ainda no Pull Request.
O desenvolvedor corrige antes mesmo do merge.
✔ Snyk Code — análise semântica
Enquanto o Semgrep trabalha fortemente com padrões, o Snyk adiciona análise semântica mais profunda.
Ele consegue detectar:
- fluxos vulneráveis,
- uso inseguro de bibliotecas,
- riscos reais de exploração.
Isso reduz bastante falsos positivos.
✔ SonarCloud — qualidade e segurança
O SonarCloud foi utilizado para:
- code smells,
- bugs,
- duplicações,
- security hotspots,
- maintainability.
Esse ponto é importante porque segurança não é apenas CVE.
Código mal estruturado também gera risco operacional.
✔ Dependency Vulnerability Scan (SCA)
Uma das maiores superfícies de ataque atuais está na supply chain.
Por isso, a pipeline também executa análise de dependências vulneráveis.
Esse processo identifica:
- bibliotecas comprometidas,
- CVEs conhecidas,
- versões inseguras,
- riscos transitivos.
Hoje praticamente toda aplicação moderna depende de dezenas ou centenas de pacotes externos.
Ignorar isso é extremamente perigoso.
🧪 Testes automatizados
Segurança sem testes consistentes não escala.
Por isso a pipeline também incluía múltiplas camadas de testes automatizados.
✔ Testes unitários e integração
Garantem:
- regras de negócio,
- estabilidade,
- previsibilidade,
- confiabilidade funcional.
✔ Cypress — testes E2E
Aqui a aplicação é validada do ponto de vista do usuário real.
Fluxos completos são executados automaticamente:
- login,
- navegação,
- formulários,
- interações críticas.
Isso reduz regressões e melhora confiança no deploy.
🔐 Segurança ofensiva automatizada
Esse foi o ponto mais interessante do experimento.
Além de validações estáticas, a aplicação também sofreu testes ofensivos automatizados.
✔ OWASP ZAP — DAST
O ZAP executa análises dinâmicas simulando ataques reais contra a aplicação.
Isso inclui:
- headers inseguros,
- exposições indevidas,
- falhas comuns da OWASP,
- endpoints vulneráveis.
Ou seja:
A aplicação não era apenas analisada “parada”.
Ela era atacada continuamente durante a pipeline.
✔ Nuclei — detecção de CVEs e misconfigurations
O Nuclei adicionou uma camada extremamente poderosa de detecção automatizada.
Ele identifica:
- CVEs conhecidas,
- exposições públicas,
- configurações inseguras,
- fingerprints vulneráveis,
- falhas de infraestrutura.
Isso aproxima bastante a pipeline de uma abordagem real de AppSec contínuo.
📊 Resultado do experimento
Os resultados foram extremamente positivos.
Mesmo utilizando uma abordagem fortemente acelerada por IA e automação:
✅ A aplicação manteve estabilidade
✅ Os riscos ficaram visíveis no PR
✅ Vulnerabilidades passaram a ser tratadas cedo
✅ O deploy ficou condicionado à aprovação de segurança
✅ O fluxo continuou extremamente rápido
E talvez o principal:
O Vibe Coding deixou de ser um processo baseado em confiança cega.
A pipeline passou a atuar como uma camada contínua de validação técnica.
💡 O maior aprendizado
Existe uma ideia equivocada de que produtividade e segurança competem entre si.
Na prática, o experimento mostrou o contrário.
Quando a segurança é automatizada:
- o time ganha velocidade,
- reduz retrabalho,
- aumenta previsibilidade,
- melhora governança,
- e entrega software mais confiável.
O problema nunca foi desenvolver rápido.
O problema é desenvolver rápido sem observabilidade, sem validação e sem controles.
🚨 O futuro do desenvolvimento provavelmente será híbrido
A tendência é clara:
IA vai acelerar cada vez mais o desenvolvimento.
Mas isso cria um novo desafio:
- mais código,
- mais dependências,
- mais automação,
- mais superfície de ataque.
Por isso DevSecOps tende a se tornar obrigatório dentro desse novo modelo de engenharia de software.
Não basta gerar código.
Será necessário:
- validar,
- monitorar,
- testar,
- analisar riscos,
- automatizar segurança continuamente.
🔥 Conclusão
Depois desse estudo de caso, minha conclusão ficou muito clara:
Vibe Coding não precisa ser “codar e rezar”.
Com uma pipeline bem estruturada contendo:
- SAST,
- DAST,
- SCA,
- testes automatizados,
- análise contínua,
- governança de PR,
é totalmente possível construir aplicações modernas com:
- velocidade,
- segurança,
- qualidade,
- escalabilidade,
- e confiança operacional.
O futuro provavelmente não será:
“IA vs Segurança”
Mas sim:
“IA + Segurança automatizada desde o primeiro commit.”
📌 Stack utilizada
- Lovable
- Antigravity
- GitHub Actions
- Semgrep
- Snyk Code
- SonarCloud
- Cypress
- OWASP ZAP
- Nuclei
- CI/CD automatizado
🚀 E você?
Você acredita que o futuro do desenvolvimento será baseado em Vibe Coding com DevSecOps integrado?
Ou ainda considera esse modelo arriscado para aplicações reais?
Compartilha sua visão nos comentários. 👇
#VibeCoding #DevSecOps #AppSec #SecureByDesign #ShiftLeft #CICD #CloudSecurity #OWASP #Automation #SecurityPipeline




