

Você tem um monolito disfarçado.
Banco de Dados por Serviço na Prática: Como Separar o Banco Sem Quebrar o que Já Existe
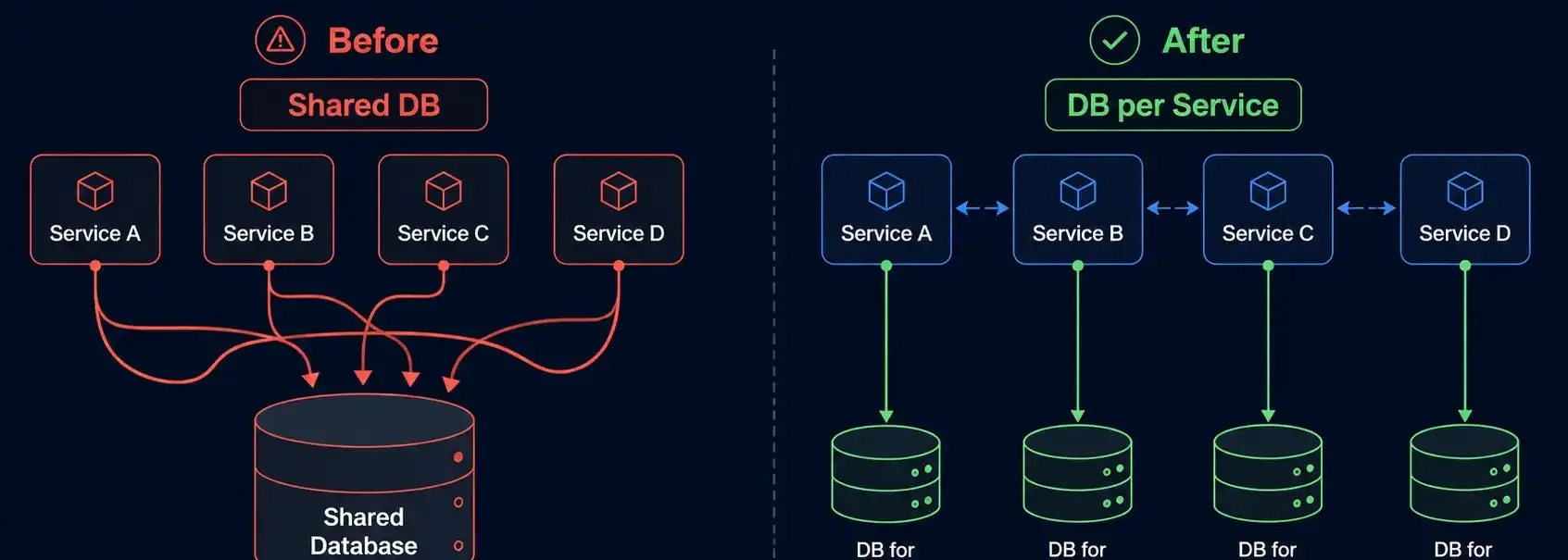
Seu sistema tem microsserviços, mas todos apontam pro mesmo banco?
Parabéns — você tem um monolito disfarçado. E eu sei disso porque trabalhei em um.
O cenário real: 6 microsserviços, 1 banco, e uma fila de problemas
Em uma de minhas atuações trabalhei com um sistema que processava até 100 mil requisições diárias. A arquitetura tinha microsserviços bem definidos por domínio:
→ Orders — gestão das ordens de entrega logística
→ Motoristas — cadastro, disponibilidade e rastreamento
→ Financeiro — cálculo de frete, repasses e cobranças
→ Notificação — envio de alertas para clientes e parceiros
→ Integração — comunicação com sistemas externos e parceiros
→ Averbação — registro e cobertura das entregas junto à seguradora
Na teoria, cada um tinha sua responsabilidade clara. Na prática, todos apontavam para o mesmo banco PostgreSQL.
Por um tempo, funcionou. O sistema cresceu, o volume aumentou, e o banco foi aguentando. Até o dia em que parou de aguentar.
E quando um banco compartilhado começa a ceder sob carga, ele não avisa com antecedência.
Os problemas que um banco compartilhado gera na prática
O primeiro sintoma foi o mais silencioso: queries que antes demoravam milissegundos começaram a demorar segundos. Sem motivo aparente.
A causa era clássica: o serviço de Orders rodava uma view materializada com alto volume de dados no mesmo momento em que o serviço Financeiro tentava executar queries transacionais. O banco tinha que gerenciar locks concorrentes entre operações que, conceitualmente, não tinham nada a ver uma com a outra — mas compartilhavam tabelas.
Com o tempo, os problemas foram se acumulando:
→ Travamentos de tabela em produção causados por queries pesadas de um domínio bloqueando operações de outro
→ Qualquer mudança de schema virava uma operação de risco — ninguém sabia ao certo quem mais dependia daquelas colunas
→ Impossível escalar um serviço de forma independente: o gargalo estava sempre no banco
→ Índices criados para otimizar um serviço impactavam negativamente a performance de outro
→ Incidentes em produção eram difíceis de isolar — tudo estava acoplado no mesmo ponto
O banco compartilhado não era um detalhe técnico. Era uma bomba-relógio esperando o volume certo para explodir.
Por que isso acontece — mesmo em times experientes
Ninguém decide conscientemente criar um monolito de banco. O que acontece é que o sistema começa pequeno, com poucos serviços, e separar o banco "depois" sempre parece mais arriscado do que deixar como está.
Cada sprint tem prioridades. A dívida técnica vai crescendo. E o argumento que mantém o problema vivo por anos é sempre o mesmo:
"Separar agora vai quebrar tudo. Melhor deixar pra depois."
Esse argumento tem uma base real. Uma migração mal planejada pode causar mais problemas do que resolve. Mas o ponto central é que a separação não precisa ser uma grande migração feita de uma vez. Ela precisa ser incremental.
Como separar sem quebrar o que já existe: um processo em 5 etapas
A diferença entre uma migração bem-sucedida e um desastre costuma estar na estratégia de execução — não na complexidade técnica. Veja o que funciona na prática:
1. Mapeie quem escreve em cada tabela
Antes de mover qualquer dado, identifique os donos reais de cada tabela. Leitura compartilhada é tolerável no curto prazo. Escrita compartilhada é o problema — é ela que gera conflitos de schema, travamentos e os acoplamentos mais difíceis de desfazer. No nosso caso, o serviço de Averbação precisava de dados de Orders para gerar romaneios, mas escrevia na mesma tabela de entregas. Esse acoplamento de escrita foi um dos primeiros a ser isolado.
2. Comece pelo serviço mais isolado — não pelo mais crítico
A primeira separação serve para validar o processo, não para resolver o maior problema. No contexto de uma plataforma logística, o serviço de Notificação costuma ser um bom candidato: ele consome dados de outros serviços, mas raramente é consumido por eles. Isolar esse banco primeiro permite que a equipe aprenda o fluxo de migração com risco baixo, antes de tocar em Orders ou Financeiro.
3. Aplique o padrão Strangler Fig no banco
O mesmo padrão usado para migrar código legado funciona aqui. O novo serviço passa a ter seu próprio banco. Os dados que ele precisa de outros domínios chegam via evento ou via chamada de API — nunca via JOIN direto entre bancos.
Na prática: quando o serviço de Averbação precisava dos dados de carga de uma entrega, em vez de fazer JOIN com a tabela de Orders, passamos a publicar um evento OrderDispatched com os dados necessários. O serviço de Averbação consumia esse evento e armazenava o que precisava no próprio banco — sem depender do banco de Orders para operar.
4. Elimine os JOINs entre domínios gradualmente
Esse é o passo mais doloroso. JOINs entre tabelas de domínios diferentes geralmente indicam uma de duas situações:
→ Você precisa desnormalizar e replicar o dado necessário no serviço que o consome
→ A fronteira entre os serviços está mal definida e precisa ser repensada antes da separação técnica
No caso do serviço Financeiro, havia JOINs com a tabela de Motoristas para calcular repasses. A solução foi o serviço Financeiro passar a manter uma projeção local dos dados de motorista que precisava — atualizada via eventos sempre que o cadastro mudava. Mais dados para gerenciar, sim. Mas sem o acoplamento que travava a operação.
5. Defina uma data de corte para duplicação temporária de dados
Dados históricos às vezes precisam existir nos dois lugares por um período de transição. Isso é aceitável — desde que tenha prazo definido e monitoramento ativo. Sem prazo, duplicação temporária vira arquitetura permanente, e você criou um novo problema no lugar do antigo.
O que muda depois que você separa
Depois de isolar os primeiros serviços, alguns problemas simplesmente desaparecem:
✅ A query pesada do serviço de Orders não trava mais o Financeiro — são bancos separados
✅ Falha em um serviço não provoca efeito cascata nos outros
✅ Cada banco reflete apenas o domínio dele — sem colunas herdadas de contextos diferentes
✅ Deploy, escala e otimização passam a ser decisões independentes por serviço
✅ Schema deixa de ser um campo minado compartilhado entre times
Atenção: separar o banco sem definir domínio é trocar um problema por outro
Esse é o ponto que costuma ser ignorado. A separação técnica do banco resolve o sintoma — mas não necessariamente a causa.
O banco compartilhado é o sintoma. Fronteira de domínio mal definida é a causa.
Enquanto os times não tiverem clareza sobre quem é o dono de cada dado, o acoplamento vai reaparecer em outra camada: via chamadas síncronas excessivas entre serviços, via replicação inconsistente de dados, via eventos usados como substitutos de JOINs sem nenhuma consistência garantida. O problema muda de forma, mas não desaparece.
Conclusão
Separar banco em microsserviços não é uma tarefa técnica pontual. É um trabalho contínuo de definição de domínio, disciplina de equipe e migração incremental.
Trabalhei num sistema onde esse problema era real, com volume real e consequências reais em produção. A separação não aconteceu de uma vez — aconteceu serviço por serviço, tabela por tabela, com aprendizado acumulado a cada etapa.
A separação bem feita não é heroica. É incremental, documentada e feita com os domínios bem definidos antes de qualquer linha de código ser movida.
Você já passou por uma migração assim? Como foi no seu contexto?
Conta nos comentários — cada sistema tem suas particularidades, e a troca de experiência entre quem viveu isso na prática vale muito mais do que qualquer tutorial.
https://www.linkedin.com/pulse/voc%C3%AA-tem-um-monolito-disfar%C3%A7ado-mateus-souza-yzphf/




