

Manual de Requalificação Técnica: O Engenheiro de Dados na Era da IA
A Grande Convergência: Do Pipeline Estático à Orquestração Inteligente
A engenharia de dados está mudando mais rápido agora do que em qualquer momento nos últimos 20 anos.
Durante décadas, o engenheiro de dados foi responsável por mover dados entre sistemas.
Na era da IA generativa, essa função deixou de ser suficiente.
O novo perfil Engenheiro de Dados surge como o arquiteto da inteligência, transformando o dado de um ativo passivo em sistemas que tomam decisões. Esta transição marca a mudança definitiva dos "Sistemas de Registo" com a agregação, armazenamento e dashboards de dados históricos para os Sistemas de Ação, que utilizam a inteligência de dados para executar tarefas e processos de forma proativa, reduzindo drasticamente o tempo entre o insight e a execução.
No paradigma anterior, o sucesso era medido pelo time-to-insight (geração de relatórios). Hoje, a métrica crítica é o time-to-execution: a latência entre a captura de um dado e o disparo de uma ação automatizada por agentes de IA.
Para o novo engenheiro a "Sistematização da Ação" é o único caminho para extrair valor de negócio real, movendo-se além da mera visualização para a criação de sistemas que decidem e operam de forma autônoma.
O Novo Perfil: Análise Comparativa de Competências
A requalificação do novo profissional não é uma a substituição das bases clássicas, mas uma expansão obrigatória. O Engenheiro deve dominar agora as camadas de abstração e modelagem que permitem à IA compreender o contexto organizacional profundo.
Pontos chave de mudança:
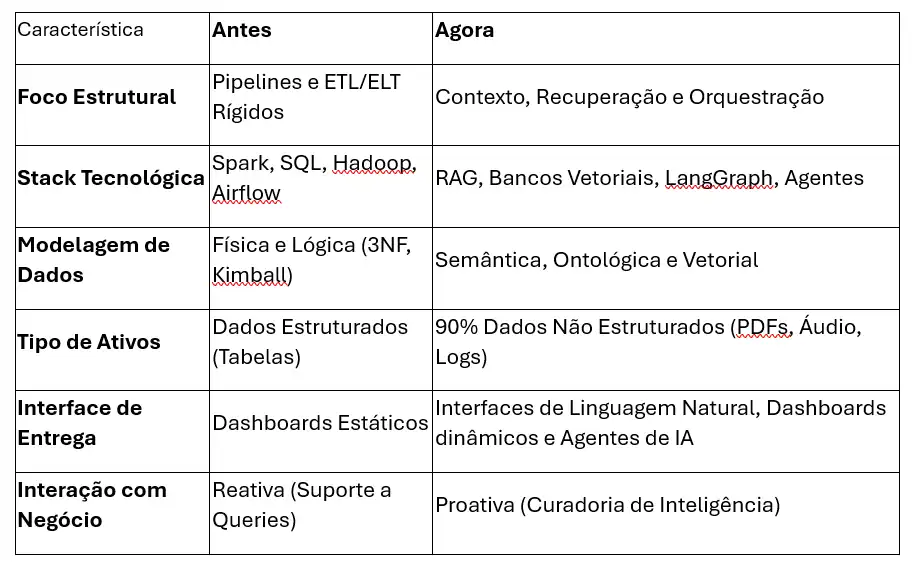
“So What?": O que muda de fato? O Engenheiro agora adota o vibe coding (termo cunhado por Andrej Karpathy, cofundador da OpenAI e ex-diretor de IA da Tesla, em fevereiro de 2025), é uma prática emergente onde o desenvolvedor delega a codificação procedural/operacional à IA para se focar na arquitetura e na lógica do sistema.
Num mercado onde a vasta maioria dos dados empresariais não são estruturados ("dark data"), agora a produtividade escala através da orquestração interdisciplinar.
1. Fundamentos de Vetorização, Embeddings e o "Gap de Dark Data"
O novo perfil de engenheiro de dados enfrenta o Enterprise Data Gap, onde dados do Goby Benchmark (Kayali et al.) revelam que LLMs treinados em dados públicos sofrem uma queda de 14.1% na precisão e um gap de 0.18 no F1-score (uma métrica usada em aprendizado de máquina que combina Precisão e Recall para gerar um único valor que representa o desempenho do modelo) quando confrontados com dados proprietários (Dark Data). Para mitigar este problema, o engenheiro deve dominar as seguintes disciplinas técnicas:
- Embeddings & Vector DBs: Transformação de dados em vetores numéricos para busca semântica em sistemas como Milvus ou Chroma.
- Chunking e Overlap Estratégico: Divisão de documentos em fragmentos (chunks) gerando informação complexa e volumosa em unidades menores e mais manejáveis, mantendo o foco no que é relevante. O Overlap é a técnica de repetir uma pequena parte do final de um fragmento (chunk) no início do próximo, para garantir que a IA mantenha a Coerência e o encadeamento lógico das ideias.
- Tree Serialization (Serialização de Árvore): Processo de converter uma estrutura de dados de árvore (nós e referências) em um formato linear, como uma string, sequência de bytes ou JSON, permitindo que ela seja facilmente armazenada em arquivos/banco de dados ou transmitida via rede. O engenheiro deve entender este processo para codificar as hierarquias (ontologias/abstrações semânticas) dentro de um modelo de linguagem para tarefas de classificação, como a anotação de tipos semânticos em colunas de dados.
- Similarity Search: As ontologias permitem realizar a procura por similaridade semântica, onde as consultas dos utilizadores são mapeadas para conceitos ontológicos num grafo de conhecimento, em vez de dependerem apenas de palavras-chave exatas, como a FAISS (Facebook AI Similarity Search) que é uma biblioteca de código aberta.
2. Retrieval-Augmented Generation (RAG) vs. Fine-Tuning
A distinção estratégica entre Domínio e Contexto é o que separa o sucesso do fracasso financeiro.
- Analogia do Cardiologista: O Fine-Tuning representa os anos de estudo (Domínio), ou seja, um modelo pré-treinado em grandes volumes de dados genéricos. O RAG representa a consulta ao prontuário do paciente em tempo real (Contexto), melhorando a precisão de Modelos de Linguagem Grandes (LLMs) (como GPT) ao permitir que eles consultem fontes de dados externas e confiáveis antes de responder.
- Risco de "Population Drift": Pesquisas em instituições financeiras indicam que modelos baseados apenas em aprendizagem (fine-tuning) tornam-se ineficazes em apenas dois meses devido à mudança na distribuição dos dados.
- Diretiva atual: O Engenheiro agora prioriza o RAG para contextualização dinâmica, garantindo menor custo, atualização em tempo real e redução de alucinações através do pipeline: Ingestion -> Vectorization -> Retrieval -> Augmentation -> Generation.
Por exemplo, um banco pode usar RAG para permitir que um assistente interno responda perguntas sobre políticas de crédito consultando documentos internos, contratos e manuais operacionais armazenados em um Vector Database.
Já uma operadora de telecom recebe diariamente milhares de tickets de suporte vindos de diferentes canais (app, chatbot, e-mail e call center). Cada ticket precisa ser classificado corretamente em categorias específicas como: Falha de rede, Problema de faturamento, Solicitação de portabilidade, Cancelamento de serviço e Problemas técnicos de modem ou roteador. Embora um LLM genérico consiga compreender linguagem natural, ele não conhece a taxonomia interna da empresa, que pode conter dezenas ou centenas de categorias específicas. Para resolver isso, a empresa realiza fine-tuning do modelo utilizando milhares de tickets históricos já classificados por especialistas.
3. IA Agêntica e a "Agentic AI Mesh"
A IA evoluiu de assistentes reativos para agentes autónomos que planeiam e executam tarefas. Segundo o CEO da Nvidia, Jensen Huang, a IA agêntica representa uma "oportunidade de triliões de dólares".
Taxonomia de Agentes e Governança:
- Reativos: Triagem e tarefas simples.
- Baseados em Modelos: Logística e predição.
- Baseados em Objetivos: Assistentes de projeto focados em resultados (outcomes).
- Baseados em Utilidade: Decisões complexas com trade-offs (ex: finanças).
- Aprendizes: Evolução por tentativa e erro (ex: cibersegurança).
Por exemplo, um agente pode monitorar transações suspeitas em tempo real, consultar histórico do cliente e acionar automaticamente um fluxo de verificação antifraude.
O Imperativo da Agentic AI Mesh, uma arquitetura de múltiplos agentes de IA especializados que cooperam entre si para planejar e executar tarefas complexas de forma coordenada e governada. Dados da Gartner indicam que 30% dos projetos de GenAI serão abandonados após o PoC devido à baixa qualidade dos dados e falta de ROI. O engenheiro agora deverá contribuir para eliminar este risco implementando a Agentic Mesh (conceito desenvolvido por Eric Broda, que consiste em uma arquitetura de ecossistema desenhada para permitir que agentes de IA autônomos se descubram, colaborem e transacionem entre si de forma segura e escalável em ambiente empresarial).
4. A Evolução do BI: Da Dashboard ao Sistema AUTOBIR
O declínio dos dashboards estáticos é iminente. O Engenheiro deve implementar o Business Intelligence Generativo, onde a interface é o diálogo e a ação é imediata. Para automatizar os requisitos de BI sem perder o rigor técnico, utiliza-se o sistema AutoBIR (Automating Business Intelligence Requirements), que consiste em um conjunto de componentes responsáveis por descobrir (OntoDis), gerenciar (OntoManager) e indexar (OntoSearch) semanticamente ontologias de dados corporativos, permitindo consultas em linguagem natural e tradução automática para consultas estruturadas.
- OntoDis (Ontology Discovery): Construção automática do modelo de dados ontológico a partir de metadados.
- OntoManager (Cataloging): Gestão de conexões, modelos e vinculação (bindings) de dados.
- OntoSearch (Semantic Indexing): Indexação semântica da ontologia para permitir consultas Text-to-SQL precisas.
Esta arquitetura abstrai a complexidade física (3NF/SQL) para o LLM, permitindo que os usuários finais operem os sistemas de ações baseados em linguagem natural.
5. Governança, Segurança e FinOps
A estratégia de IA falha quando aplicada sem controles rigorosos. O engenheiro deverá atuar como o guardião da integridade e do custo.
Protocolo de Operação:
- Privacidade e Segurança: É mandatório a adoção de uma abordagem de "Menor Privilégio" via Unity Catalog, permitindo uma governança centralizada via RBAC (Role-Based Access Control, ou Controle de Acesso Baseado em Funções) e mascaramento de PII (dados sensíveis) em todo o Lakehouse.
- FinOps e Model Cascading: Gestão inteligente de tokens. O engenheiro implementa o cascateamento de modelos: utiliza modelos robustos (GPT-5.4 Pro) para raciocínio complexo e modelos especializados/leves (GPT-4 mini ou Llama local, por exemplo) para extração e tarefas rotineiras, além de implementar sistemas de cache.
- Monitorização Contínua: A utilização de ferramentas de observabilidade e rastreamento (traces) de logs (ex: LangSmith, Jaeger e OpenTelemetry) é uma despesa operacional (OPEX) permanente. Não é possível gerir o que não se audita; o "raciocínio" dos agentes deve ser rastreável para garantir conformidade com regras e leis vigentes, como por exemplo a EU AI Act (Lei da Inteligência Artificial da União Europeia).
Conclusão: Roteiro para a Requalificação Profissional
O futuro da engenharia de dados não está em acumular dados.
Está em orquestrar a sua utilidade.
O engenheiro é o pivô que une infraestrutura técnica e valor estratégico.
Plano de Ação Imediato:
- Dominar a Orquestração: Aprender frameworks de estado como LangChain e LangGraph.
- Sintetizar Ontologias: Transitar de dicionários de dados simples para ontologias semânticas complexas.
- Masterizar Tree Serialization: Implementar métodos de codificação que preservem a hierarquia dos dados proprietários.
- Implementar Governança Ativa: Configurar catálogos de dados (ex.: Unity Catalog) e ferramentas de observabilidade (ex.: LangSmith).
A integração da inteligência humana com a artificial, sob a regência da governança e de guardrails com técnicas avançadas, é o único caminho para a inovação segura e sustentável.
A pergunta que fica para engenheiros de dados hoje é simples:
Você está apenas construindo pipelines… ou está construindo sistemas que tomam decisões?




