

A Revolução das Máquinas Começou: Tudo o que Você Precisa Saber sobre LLms
- #IA Generativa
🚀 A Revolução das Máquinas Começou: Tudo o que Você Precisa Saber sobre LLMs e Como Usá-las Sem Alucinar
A Revolução das Máquinas Começou 🤖
As três consoantes mais faladas do momento: LLM — o que é e como funciona. Os Modelos de Linguagem de Grande Escala (Large Language Models, o reverendo LLMs) — cujo é o salvador, professor, amigo e muitos outros adjetivos carinhosos de estudantes, profissionais e curiosos que usufruem dessa valiosa ferramenta — são um dos principais avanços tecnológicos desse século. ✨
Transformando nosso jeito de trabalhar, viver, relacionar com os códigos — ou seja, interagir com a máquina e como entendemos seus outputs, resultados das nossas requisições enviadas a uma máquina com um poder de processamento incomparável com o ser humaninho, vindas de um prompt bem elaborado ou não. Esses sistemas de inteligência artificial não somente conseguem entender e responder perguntas em linguagem natural, como também geram textos, códigos e conteúdo que são muitas vezes indistinguíveis da criação humana.
📚 A História e o Marco dos LLMs
O Marco que inaugurou a era dos LLMs modernos foi a **arquitetura Transformer**, proposta em 2017 no artigo seminário "Attention is All You Need"[1]. A partir dela surgiram modelos capazes de processar contextos amplos e eficientemente, mudando o rumo das pesquisas em linguagem natural.
O **BERT**, lançado pelo Google em 2018[2], foi o primeiro modelo amplamente reconhecido como LLM por usar plenamente a arquitetura Transformer e introduzir uma compreensão contextual bidirecional mais robusta. Em seguida, a série **GPT** (OpenAI) destacou-se pelo foco em geração de texto[3]; modelos como GPT-2 (2019) e GPT-3 (2020) ampliaram drasticamente o número de parâmetros e as capacidades de geração e raciocínio em linguagem natural.
Em 2022, o lançamento do **ChatGPT**[4] tornou esses avanços amplamente visíveis ao público, levando a tecnologia ao debate público e ao uso cotidiano, transformando a forma como bilhões de pessoas interagem com a inteligência artificial.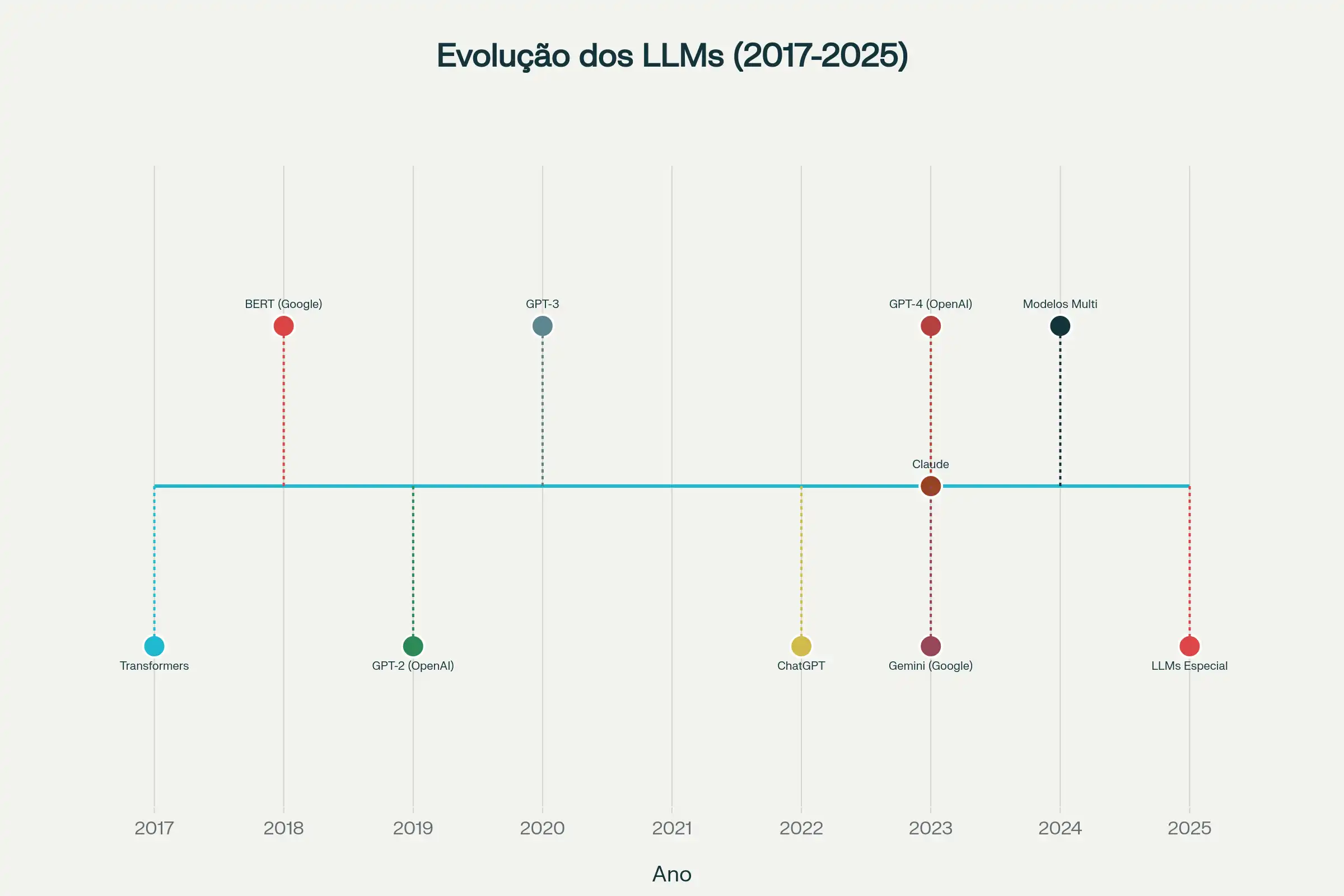
🧠 Como Funciona o LLM
Um Large Language Model (LLM) é um pacotão de dados (informações) treinados — ou seja, reconheço, não reconheço, e a partir do reconhecimento algumas máquinas aprendem sozinhas (Machine Learning)[5] — em quantidades enormes de texto — bilhões de palavras extraídas de livros, artigos acadêmicos, sites, código-fonte e outros documentos, até mesmo geolocalização, computação visual, sons — para aprender padrões linguísticos e gerar texto coerente por probabilidade e predição.
De forma simples, imagine que você inicia uma frase no seu corretor de texto no smartphone: *"O céu está..."*. Uma LLM, através de todo o conhecimento aprendido durante seu treinamento, inicia geralmente com uma biblioteca de palavras e calcula a probabilidade de diferentes palavras seguirem. A palavra "azul" teria uma probabilidade muito alta, enquanto "crocante" teria uma probabilidade muito baixa. O modelo então seleciona uma palavra (frequentemente a mais provável), repete o processo para a próxima posição e continua até gerar uma resposta completa e coerente.
A Sofisticação por Trás da Simplicidade 🎪
Essa simplicidade conceitual é tipo um **tricô feito por um monge zen**: parece fácil, mas por baixo tem um milhão de nós bem alinhados. Um LLM moderno guarda **bilhões de parâmetros** — pense neles como neurônios virtuais hiperativos ou talvez como centenas de milhões de estagiários matemáticos tomando notas freneticamente — que capturam nuances, contextos, sussurros e até os choques elétricos da língua humana.
Quanto mais parâmetros, mais o modelo vira aquele **amigo erudito que sabe citar Shakespeare** e ainda explicar por que a piada do tio caiu tão mal, entregando respostas afiadas, contextualizadas e com menos chance de virar meme involuntário[6].
⚡ Da Teoria à Prática: Como um LLM Realmente Gera Sua Resposta
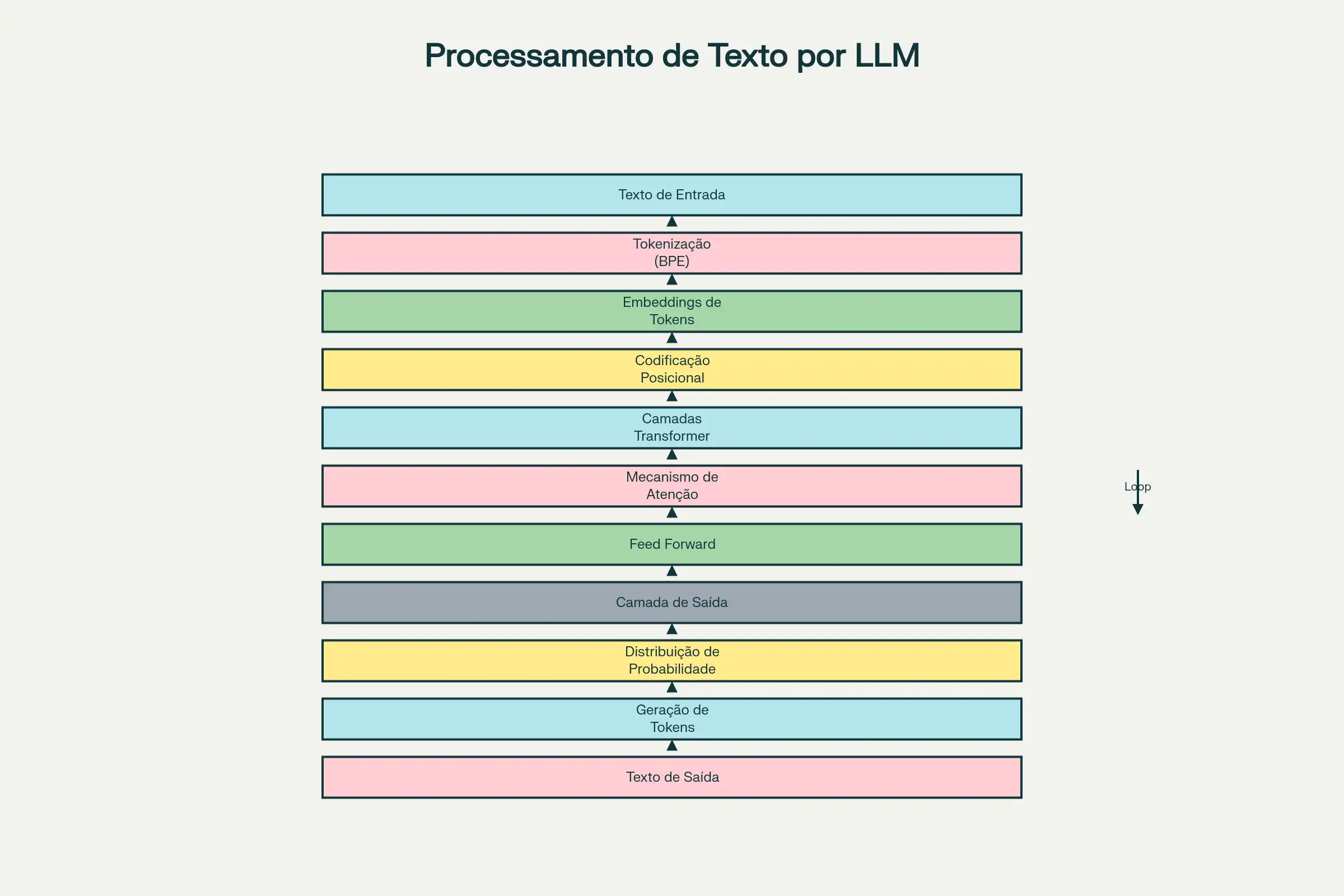
Quando você digita uma pergunta em um chatbot alimentado por LLM, uma sequência complexa de eventos ocorre em **milissegundos**. Vamos seguir este processo passo a passo para desmistificar a "magia" por trás da resposta:
1. Seu texto é tokenizado:🔤
A plataforma divide sua entrada em tokens usando o algoritmo BPE[7]. *"Qual é a capital da França?"* poderia tornar-se algo como `["Qual", "é", "a", "capital", "da", "França", "?"]`.
2. Os tokens são convertidos em embeddings:📍
Cada token é transformado em um vetor numérico no espaço vetorial do modelo, carregando informação semântica.
3. Posição importa:🗺️
O modelo adiciona informação sobre a posição de cada token (primeira palavra, segunda palavra, etc.) aos embeddings, porque *"gato comeu rato"* é muito diferente de *"rato comeu gato"*.
4. As camadas do Transformer processam: 🧬
Os embeddings passam através de múltiplas camadas do Transformer, cada uma com seus próprios mecanismos de autoatenção multihead. Em cada camada, o modelo refina sua compreensão do contexto, capturando relacionamentos cada vez mais sofisticados.
5. Cálculo de probabilidades:📊
Após passar por todas as camadas, o modelo gera um vetor que representa, essencialmente, a "distribuição de probabilidade" sobre todas as palavras possíveis no seu vocabulário. Se seu vocabulário tem 50.000 tokens, o modelo calcula efetivamente a probabilidade de cada um deles ser o próximo token.
O modelo seleciona um token (frequentemente o mais provável, mas com alguma variabilidade para manter as respostas naturais), adiciona-o à sequência, e repete o processo. Tokenização, embedding, processamento pelo Transformer, seleção da próxima palavra — tudo isso novamente, iteradamente, até que o modelo decida terminar a resposta.
Esse processo ocorre **não uma vez, mas potencialmente centenas de vezes** para uma resposta longa, tudo acontecendo em poucos segundos na maioria dos modelos modernos.
💎 Princípios da Engenharia de Prompt: A Arte de Conversar com a Inteligência Artificial
A Engenharia de Prompt emergiu como uma das habilidades mais valiosas da era da inteligência artificial generativa[8]. Enquanto milhões de pessoas interagem diariamente com sistemas como ChatGPT, Claude e Gemini, poucos compreendem que a qualidade das respostas que recebem depende fundamentalmente de como eles fazem suas perguntas.
A Engenharia de Prompt é tipo ensinar um papagaio super intelectual a responder sem inventar história** — se você fala certinho, ele responde; se você fala enrolado, ele devolve poesia abstrata ou um *"não sei"* chique. Enquanto milhões perguntam ao ChatGPT, Claude e Gemini como se estivessem pedindo pizza às 3 da manhã, poucos sabem que o segredo está em saber pedir a pizza certa, com borda, sem cebola e com instruções claras para o entregador digital.
📎 O que é Prompt Engineering Afinal?
É o processo de criar, ajustar e testar **instruções** — os famosos prompts — para fazer um modelo de linguagem entender o que você quer de verdade. Não é mágica, é **quase alquimia**: uma pitada de palavra certa, um fio de contexto, e *bum* — uma resposta que não parece ter sido gerada por uma cafeteira com doutorado.
Por Que Deveria Importar para Você? 🎯
Porque LLMs não "pensam", eles apostam no próximo pedaço de texto mais provável. Dê um prompt vago e ele responde como um consultor cansado: com generalidades e passos genéricos. Dê um prompt bem esculpido e ele vira o **assistente que você sempre quis** — aquele que lembra seu café preferido e ainda resolve planilha.
Benefícios Práticos (ou Como Economizar Tempo e Paciência):
-🔷 Mais precisão: menos respostas no modo *"vai tentando"* e mais solução de verdade.
- 🔷Economia de tempo: evita aquele loop infinito de *"não era isso que eu quis"*.
- 🔷 Personalização: transforma respostas genéricas em algo com a sua cara (ou pelo menos com seu briefing).
- 🔷Produtividade turbo: em contexto profissional, quem domina isso automatiza tarefas e produz conteúdo como se tivesse um exército de estagiários organizados.
🧑🏽🏫Você sabia que🧩: dominar prompts é aprender a conversar com uma IA sem precisar traduzir para "robotês. Faça o pedido certo, colha a resposta certa — e, de quebra, pare de culpar a máquina quando a culpa era sua desde o primeiro prompt *"Me explica"*. O processo é tão rápido que cria uma ilusão de que o modelo "conhece" informações que, na verdade, ele está buscando no seu lago de dados dinamicamente.
🏛️ Os Cinco Pilares Fundamentais da Engenharia de Prompt: C.P.T.E.C
A arte de criar prompts que não viram mensagem perdida no limbo da internet repousa em cinco mandamentos sagrados do **C.P.T.E.C**: Contexto, Persona, Tarefa, Exemplos e Constraints[9].
- 🚧Contexto🌍: O café forte antes da conversa. Sem ele, tudo fica sonolento e vago.
-🚧Persona🎭: A fantasia que você empresta pro modelo — médico? poeta? troll educado? Escolha bem ou vai sair conselhos de amor em tom jurídico.
- 🚧Tarefa ✅: O pedido claro. Se você fala *"me ajuda"*, o modelo pergunta *"como?"* e aí começa a novela.
- 🚧Exemplos 📋: O atalho para evitar respostas estilo *"improvise"*. Mostre um modelo do que você quer e ele tenta imitar com menos drama.
- 🚧Constraints🚧: As rédeas. Limite o tamanho, o tom, ou proíba que vire um sermão existencial.
🔍 O Que é RAG (Retrieval Augmented Generation)
RAG significa **Retrieval Augmented Generation** — e se a IA fosse um amigo de bar, RAG seria o amigo que consulta o Google antes de responder qualquer coisa — e reduzir alucinações seria ensinar esse amigo a não inventar histórias quando não tem certeza[10].
É uma técnica que combina a fluidez dos grandes modelos de linguagem com uma **camada de busca por informação** em bancos de dados, documentos ou repositórios específicos. O modelo recupera trechos relevantes e os usa como base para gerar respostas mais precisas e atualizadas[11].
Como Usar RAG na Prática 🛠️
Monte um pipeline simples:
1. Indexe seus documentos em um banco vetorial;
2. Na consulta do usuário, recupere os vetores mais relevantes;
3. Passe esses trechos como contexto (ou "prompt") ao modelo para gerar a resposta final.
Isso permite respostas contextuais sem re-treinar o modelo inteiro, economizando tempo e recursos computacionais.
Por Que RAG Ajuda Contra Alucinações 💡
Quando o modelo tem acesso a **evidências concretas** vindas do seu repositório, tende a "colar" nas fontes em vez de inventar fatos plausíveis — ou seja, você dá o mapa e a IA segue o caminho em vez de imaginar atalhos. É a diferença entre um historiador com fontes primárias e um colega que "acha que lembra" de algo.
🛠️ O Guia Descontraído para "Calibrar" Sua GenAI e Parar de Inventar Histórias!
Sabe quando a Inteligência Artificial começa a **inventar fatos com uma confiança impressionante**? É a famosa **alucinação** 👻. A boa notícia é que a comunidade tech tem **9 estratégias de mestre** para colocar a IA na linha e fazer ela falar a verdade:
1. 🎯 RAG (O Tira-Teima da Biblioteca)
Esta é a tática de ouro! Antes de responder, a IA é obrigada a consultar uma base de dados externa e real[12]. Em vez de depender da memória (que pode ser falha), ela busca e cita a fonte. É como mandar a IA fazer a lição de casa com consulta.
2. 📖 Engenharia de Prompt (O Manual de Boas Maneiras)
Aqui, a gente instrui a IA a ser honesta. Usamos prompts que a ensinam a dizer: *"Não sei essa resposta"* em vez de inventar[13]. A técnica **Chain-of-Thought** (Cadeia de Pensamento) ainda força a IA a explicar seu raciocínio passo a passo, evitando saltos lógicos.
3. 👨⚖️ RLHF (A Nota do Avaliador Humano)
Humanos dão notas para as respostas da IA (ótima, boa, péssima). Esse feedback ensina o modelo a priorizar a precisão e a utilidade, alinhando-o ao que nós, humanos, consideramos *"verdade"*[14].
4. 🥗 Curadoria de Dados (A Dieta da IA)
Se a IA come lixo, ela fala besteira. Essa estratégia é sobre alimentá-la apenas com dados verificados, de alta qualidade e atualizados. É o **controle de qualidade na fonte**[15].
5. 🔎 Verificação Factual Automática (O Professor Corretor)
Módulos automáticos de fact-checking analisam a resposta da IA depois dela ser gerada, comparando as afirmações com a web ou bases de conhecimento para garantir que tudo esteja correto[16].
6. 🧊 Ajuste de Temperatura (O "Chill Pill")
A "temperatura" controla a criatividade da IA. Para coisas sérias, é só diminuir a temperatura (para 0.1-0.3) para que ela seja mais conservadora e menos propensa a chutar[17].
7. 🎓 Fine-Tuning (A Pós-Graduação)
Treinamento extra com dados muito específicos (médicos, jurídicos, técnicos) para que a IA se torne uma **especialista em um domínio**, reduzindo a chance de erros factuais naquela área[18].
8. 🛡️ Guardrails (As Grades de Proteção)
São filtros e regras que bloqueiam a saída de respostas obviamente erradas ou absurdas antes que cheguem ao usuário[19].
9. 👁️ Supervisão Humana (O Olho do Dono)
Manter especialistas revisando o que a IA está produzindo, especialmente em áreas de alto risco, é a **última linha de defesa** para garantir a precisão[20].
🎪 Conclusão: A Receita Secreta
Em resumo, é um **esforço conjunto**: dar as fontes certas (RAG), ensiná-la a ser humilde (Prompt Engineering), fazê-la comer bem (Curadoria de Dados) e sempre ter um humano por perto para a auditoria final!
A revolução das máquinas não é sobre a IA tomar conta — é sobre nós aprendendo a trabalhar com ela de forma inteligente. Dominar LLMs, Engenharia de Prompt e técnicas como RAG é dominar uma das habilidades mais valiosas do século XXI. Então comece hoje: estruture seu prompt, recupere suas fontes, calibre sua temperatura e seja o maestro dessa sinfonia digital! 🎼✨
📖 Referências:
[1] Vaswani, A., et al. (2017). "Attention is All You Need." Conference paper apresentado em conferência de machine learning.
[2] Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2018). "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding."
[3] Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2019). "Language Models are Unsupervised Multitask Learners." OpenAI Blog.
[4] OpenAI. (2022). "ChatGPT: Optimizing Language Models for Dialogue." OpenAI Blog.
[5] Domingos, P. (2015). "The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World."
[6] Kaplan, J., et al. (2020). "Scaling Laws for Neural Language Models." arXiv preprint.
[7] Sennrich, R., Haddow, B., & Birch, A. (2016). "Neural Machine Translation of Rare Words with Subword Units."
[8] Wei, J., et al. (2022). "Emergent Abilities of Large Language Models." arXiv preprint.
[9] Brown, T., et al. (2020). "Language Models are Few-Shot Learners." OpenAI GPT-3 paper.
[10] Lewis, P., et al. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Facebook AI Research.
[11] Karpukhin, V., et al. (2020). "Dense Passage Retrieval for Open-Domain Question Answering."
[12] Robertson, S., & Zaragoza, H. (2009). "The Probabilistic Relevance Framework: BM25 and Beyond."
[13] Thawani, A., et al. (2021). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models."
[14] Christiano, P., et al. (2023). "Deep reinforcement learning from human preferences." OpenAI.
[15] Birhane, A., & van Dijk, J. (2020). "Robot Rights? Let's Talk About Human Welfare."
[16] Thorne, J., Vlachos, A., Christodoulopoulos, C., & Mittal, A. (2018). "FEVER: a large-scale dataset for Fact Extraction and VERification."
[17] Vig, J., & Belinkov, Y. (2019). "Analyzing the Structure of Attention in a Transformer Language Model."
[18] Zhang, T., et al. (2021). "Fine-Tuning Pre-Trained Language Models: Weight Initializations, Data Orders, and Early Stopping."
[19] Solaiman, I., et al. (2019). "Release Strategies and the Social Impacts of Language Models." OpenAI.
[20] Bommasani, R., et al. (2021). "On the Opportunities and Risks of Foundation Models." Stanford HAI Report.





