


Classificação Sem Código com AWS SageMaker Canvas: Desvendando o Mistério do Titanic
- #Machine Learning
- #AWS
👋 Minha Jornada de ML na DIO
Olá a todos! Meu nome é Lucindo Tomiosso Jr, e estou imerso na incrível jornada de Machine Learning através do Bootcamp DIO NEXA: Machine Learning e GenAI na Prática. Para consolidar o que estamos aprendendo e encorajar a comunidade a colocar a mão na massa, decidi abordar o desafio clássico do Titanic usando uma ferramenta poderosa e acessível: o AWS SageMaker Canvas.
Este artigo é um guia prático, passo a passo, de como construir e interpretar um modelo preditivo. Meu objetivo é mostrar que o ML é acessível a todos.
Mas fica a pergunta: Será que o Jack e a Rose do filme Titanic sobreviveriam ao naufrágio se fossem personagens reais, baseados nas estatísticas? Vamos descobrir juntos!
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
🚢 Introdução: SageMaker Canvas e o Aprendizado de Máquina (ML)
O naufrágio do Titanic em 1912 é um dos eventos mais notórios da história, e seu registro de passageiros se tornou o dataset mais famoso para quem inicia em Machine Learning (ML). Neste artigo, vamos usar o AWS SageMaker Canvas para construir um modelo preditivo para este clássico desafio.
O que é o AWS SageMaker Canvas?
O Amazon SageMaker Canvas é uma interface de usuário visual e low-code/no-code (sem código/pouco código) dentro do ecossistema Amazon Web Services (AWS). Ele é projetado para analistas de negócios e usuários que desejam construir modelos de Machine Learning robustos sem precisar escrever código ou ter experiência profunda em ciência de dados.
Principais Vantagens:
- Acessibilidade: Democratiza o ML, permitindo que qualquer pessoa utilize o poder dos algoritmos da AWS.
- Velocidade: Automatiza etapas complexas, como a seleção e o ajuste de algoritmos (Auto-ML).
- Interpretabilidade: Fornece relatórios claros de Importância da Variável (Feature Importance) e desempenho do modelo.
Utilizaremos o Canvas para entender as etapas de ML focando na Classificação Binária e na Interpretabilidade do modelo, aplicada ao nosso desafio: Quais passageiros sobreviveram?
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1. O Desafio e o Glossário Inicial
O problema do Titanic é um clássico de Classificação Binária, onde a variável alvo (Survived) possui apenas duas classes: 0 (Não Sobreviveu) ou 1 (Sobreviveu).
No Canvas, trabalhamos com o conceito de Aprendizado Supervisionado, onde o modelo aprende a partir de um gabarito.

1.1. Glossário Essencial de ML
- Aprendizado Supervisionado: O modelo aprende a partir de um gabarito (a coluna Survived preenchida no seu dataset de treino).
- Dataset de Treino: O conjunto de dados que o modelo usa para aprender os padrões (no Titanic, é o arquivo train.csv).
- Dataset de Teste: O conjunto de dados usado para avaliar a capacidade do modelo de generalizar para dados nunca vistos (no Titanic, é o arquivo test.csv, onde a coluna Survived está vazia).
- Outlier (Ponto Fora da Curva): Um valor que está muito distante da maioria dos outros dados. Exemplo: Um bebê de 6 meses é um outlier de idade em uma lista de adultos.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2. Passo a Passo Prático
- Dados: Leia as regras do desafio oficial do Titanic no Kaggle e baixe o dataset.
- Importação: Acesse o AWS SageMaker Canvas* e carregue o train.csv.
- Limpeza: Para a coluna Age, utilize a Imputação pela Mediana para preencher valores nulos sem distorcer o aprendizado.
⚠️ Aviso Importante sobre Custos AWS
O Amazon SageMaker Canvas oferece um nível gratuito de 2 meses. Este nível gratuito inclui uso de instâncias de workspace (Session-Hrs) de até 160 horas/mês para uso do aplicativo SageMaker Canvas. Fique atento ao uso para evitar cobranças após o período gratuito. Mais informações sobre preços podem ser encontradas na documentação oficial da AWS: Aprendizado de Máquina sem código
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
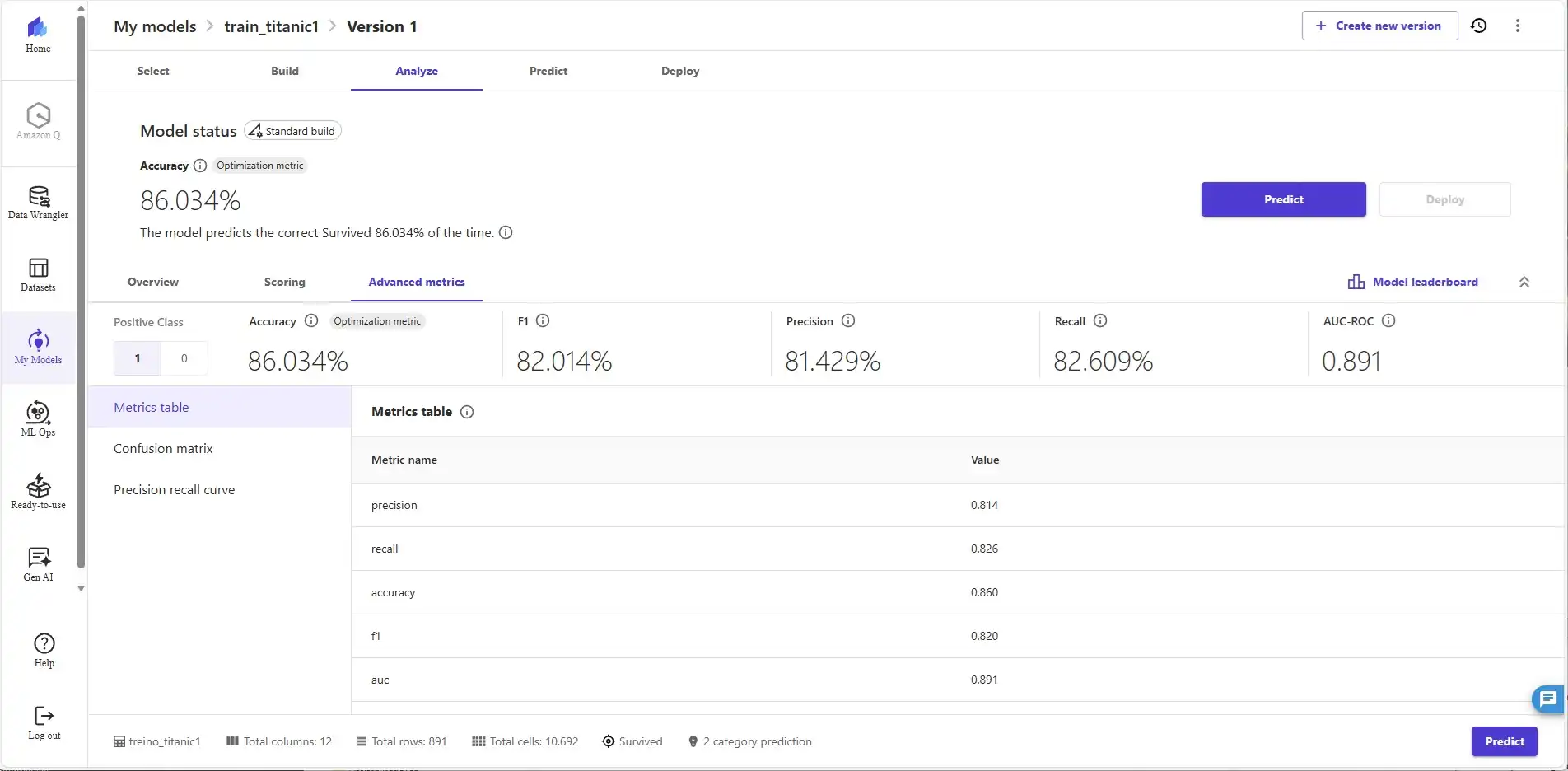
3.Treinamento e Meus Resultados Reais
Utilizei o "Standard Build" e obtive métricas excelentes que comprovam a eficiência do Auto-ML da AWS com os dados que processei:
- Accuracy: 86.034% (Taxa de acerto muito alta!)
- F1 Score: 82.014% (Equilíbrio entre precisão e recall)
- Precision: 81.429%
- Recall: 82.609%
- AUC-ROC: 0.891 (Capacidade de distinção considerada excelente)
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
4. Simulação: Jack e Rose sobreviveriam?
Para testar o modelo, criei um arquivo de predição em lote (batch prediction) com os dados dos protagonistas conforme as especificações técnicas exigidas pelo Canvas.
📄 Salve o conteúdo abaixo como um arquivo: simulacao_jackRose.csv
PassengerId,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
1000,1,DeWitt Bukater, Miss. Rose,female,17,1,1,PC 17599,71.2833,B28,C
1001,3,Dawson, Mr. Jack,male,20,0,0,345063,7.25,,S
💡 O que significa cada coluna preenchida para eles:
- PassengerId: Apenas IDs fictícios (1000 e 1001).
- Pclass: Rose na 1ª classe e Jack na 3ª classe.
- SibSp (Irmãos/Cônjuges a bordo): Coloquei 1 para Rose (considerando o noivo Cal Hockley) e 0 para Jack.
- Parch (Pais/Filhos a bordo): Coloquei 1 para Rose (ela viajava com a mãe, Ruth).
- Ticket / Fare: Valores e números de tickets aleatórios, mas condizentes com a classe (Rose com tarifa cara, Jack com a mais barata).
- Cabin: Rose na cabine B28. Jack, como muitos da 3ª classe, fica com esse campo vazio.
- Embarked: C (Cherbourg) para Rose e S (Southampton) para Jack.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
🥁🥁🥁 O Veredito da IA: 🥁🥁🥁
Ao rodar a simulação no Canvas, o resultado foi: Rose (Sobrevivente - 1) e Jack (Não Sobrevivente - 0). A estatística é fria: ser homem na 3ª classe era o cenário de maior risco, independentemente do heroísmo mostrado no filme. Pois é Jack, não deu pra você. Apesar das liberdades poéticas apresentadas no filme, o diretor James Cameron finalizou a jornada dos protagonistas com o resultado mais previsível de acordo com as estatísticas do acidente e isso é muito interessante!

-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
4.1. Submissão ao Kaggle: Do Canvas para o Ranking Mundial
Após validar o modelo com os protagonistas, exportei as predições para todos os 418 passageiros do arquivo de teste oficial do Kaggle.
Resultado da Submissão:
- Score Final:
0.77033(77,03% de acerto). - Posição no Ranking: 10.955º lugar mundial.
🤔 Por que a diferença entre os 86% do Canvas e os 77% do Kaggle?
Essa é uma das lições mais valiosas do Machine Learning! Os 86,03% que o SageMaker reportou são baseados em dados de validação (partes do dataset de treino que ele separou para teste).
Já os 77,03% do Kaggle são a capacidade de generalização do modelo em dados que ele nunca "viu" antes. Essa queda é comum e acontece devido ao Overfitting (quando o modelo fica muito bom em decorar os dados de treino, mas encontra dificuldades em cenários totalmente novos). Para um modelo construído totalmente via Low-code, alcançar a barreira dos 77% logo na primeira tentativa é um resultado excelente! Muitos competidores que usam códigos complexos em Python ficam exatamente nessa mesma faixa de pontuação. Provei que uma ferramenta No-Code consegue competir de igual para igual com modelos feitos à mão.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
5. Expandindo Horizontes: Tipos de Problemas em ML
O exercício do Titanic é uma excelente introdução à Classificação Binária. Contudo, o ML oferece um universo de problemas:
- Classificação Multiclasse: Prever uma categoria entre mais de duas opções. Exemplo: Classificar uma imagem como Gato, Cachorro ou Pássaro. Métricas: Acurácia, F1-Score.
- Regressão: Prever um valor numérico contínuo. Exemplo: Estimar o preço de uma casa com base em seu tamanho e localização. Métricas: RMSE, MAE (Erros em Unidades).
- Série Temporal (Time Series): Prever um valor futuro com base em dados dependentes do tempo. Ex: Prever vendas de um produto no próximo mês ou ano. Métricas: RMSE, MAPE.
- Clusterização (Não Supervisionada): Agrupar pontos de dados semelhantes sem um gabarito inicial. Ex: Segmentação de clientes com base em hábitos de compra. Métrica: Coeficiente de Silhueta.
Esses diferentes tipos de exercícios são a base da área e, como o Titanic demonstra, podem ser explorados com ferramentas no-code como o SageMaker Canvas.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Chamada para Ação:
Agora que você viu o potencial do SageMaker Canvas e o resultado real no ranking do Kaggle, te encorajo a replicar o exercício e explorar outros tipos de projetos!
Meus próximos passos envolverão a aplicação dessas técnicas de Regressão e Série Temporal em dados reais. Você pode acompanhar meus dados e resultados do Titanic, assim como outros projetos, em meu GitHub.
Vamos juntos nessa jornada de aprendizado! 🚀
#AWS #DIO #NEXA #ML #IA #KAGGLE



