


Como o RAG Mitiga Alucinações em IA Generativa
- #IA Generativa
Explorando como a Geração Aumentada de Recuperação transforma respostas especulativas em informações confiáveis
Resumo
Este artigo analisa como a Geração Aumentada de Recuperação (RAG — Retrieval-Augmented Generation) atua como um mecanismo de mitigação das alucinações em modelos de linguagem generativa (GenAI). Ao integrar o raciocínio linguístico de grandes modelos de linguagem (LLMs) com a precisão factual de mecanismos de busca, o RAG transforma respostas especulativas em construções informacionais fundamentadas. São discutidos seus princípios, aplicações práticas, limitações e perspectivas futuras para o desenvolvimento de sistemas de IA mais responsáveis, transparentes e confiáveis.
Palavras-chave: Geração Aumentada de Recuperação; RAG; Inteligência Artificial Generativa; Alucinações; LLMs.
1. Introdução
A Inteligência Artificial Generativa (GenAI) tem alcançado avanços notáveis em diversas áreas, mas enfrenta um problema persistente: as chamadas alucinações, respostas que parecem corretas, porém não se baseiam em fatos reais. Para reduzir esse fenômeno, surge a abordagem Retrieval-Augmented Generation (RAG), que combina a geração de linguagem natural com a recuperação de informações de fontes externas.
O RAG funciona como uma espécie de “consciência crítica” dos modelos generativos, conectando-os a bases de conhecimento verificáveis. Essa integração promove um salto qualitativo na confiabilidade das respostas produzidas e representa um passo fundamental rumo a uma IA responsável e verificável.
2. Fundamentos do RAG: O Que É e Por Que Importa

A Geração Aumentada de Recuperação (RAG) é uma arquitetura híbrida que une a geração linguística dos LLMs à busca de informações factuais em bases externas (LEWIS et al., 2020)
Em vez de confiar apenas na memória interna do modelo, o RAG consulta fontes externas como bases de dados, documentos ou mecanismos de busca antes de formular uma resposta.
Isso transforma o modelo de um "palpiteiro eloquente" em um "pesquisador articulado", fundamentando suas respostas em informações verificáveis. Seus princípios fundamentais incluem:
- Consulta ativa de bases de conhecimento externas antes da geração de texto;
- Integração contínua entre recuperação de informação e geração de linguagem natural;
- Capacidade de atualização sem necessidade de re-treinamento completo do modelo;
- Transparência e rastreabilidade das fontes citadas.
Essa abordagem é especialmente relevante em contextos onde a precisão é essencial: educação, saúde, direito, ciência, jornalismo e tomada de decisões corporativas.
Afinal, ninguém quer um modelo que inventa dados sobre medicamentos ou jurisprudência só porque "soou convincente" (Lewis et al., 2020).
Ele conecta o modelo a uma base de conhecimento real antes de gerar conteúdo, estabelecendo um lastro factual que reduz significativamente o risco de alucinações.
Os modelos de linguagem tradicionais armazenam o conhecimento em parâmetros internos. O RAG introduz uma camada não-parametrizada, que busca informações externas em tempo real, complementando o raciocínio aprendido pelo modelo com dados atualizados (ZHANG et al., 2023).
Esta dualidade permite que o sistema combine raciocínio aprendido (do modelo) com fatos verificáveis (da base de conhecimento), criando uma sinergia única.
O resultado é um sistema mais robusto, adaptável e, crucialmente, menos propenso a fabricar informações quando confrontado com lacunas em seu conhecimento parametrizado.
3. Casos de Uso Práticos
A aplicação de RAG para mitigar alucinações transcende a teoria acadêmica e se manifesta em soluções práticas que já estão transformando diversos setores.
- Saúde e Medicina: Assistentes médicos baseados em RAG consultam literatura científica, protocolos clínicos e bases de dados de medicamentos antes de fornecer informações. Isto reduz drasticamente o risco de recomendações incorretas ou desatualizadas, tornando a tecnologia mais segura para apoio à decisão clínica.
- Direito e Jurisprudência: Sistemas jurídicos com RAG acessam bancos de dados de leis, precedentes e decisões judiciais para fundamentar análises legais. Advogados podem confiar em respostas que citam casos específicos e legislação vigente, ao invés de interpretações potencialmente inventadas.
- Educação e Pesquisa Acadêmica: Tutores inteligentes equipados com RAG consultam livros didáticos, artigos científicos e bases de conhecimento curricular.Estudantes recebem explicações fundamentadas em fontes verificáveis, com referências que podem ser consultadas para aprofundamento.
- Corporativo e Atendimento ao Cliente: Chatbots empresariais com RAG acessam documentação interna, políticas da empresa e bases de conhecimento de produtos. Isto garante que clientes recebam informações precisas sobre produtos, serviços e políticas, reduzindo erros custosos.
Em todos esses contextos, a redução de alucinações não é apenas desejável — é imperativa para a adoção responsável de sistemas de IA generativa.
4. Efeitos diretos na mitigação de alucinações

Quando implementado corretamente, o RAG promove uma transformação profunda na forma como os modelos generativos produzem conteúdo.
Os benefícios são mensuráveis e impactam diretamente a confiabilidade das respostas geradas.
Com RAG, o modelo passa a:
- Citar fontes específicas e verificáveis para cada afirmação feita;
- Basear respostas em fatos recuperados de repositórios confiáveis;
- Atualizar conhecimento sem necessidade de ser re-treinado completamente;
- Validar informações contra um repositório de confiança em tempo real;
- Reduzir drasticamente a taxa de informações fabricadas ou imprecisas.
Segundo Zhang et al. (2023), implementações de RAG demonstraram redução de até 60% nas taxas de alucinação comparadas a modelos puramente generativos.
5. Implementação Técnica
Compreender a implementação técnica do RAG é fundamental para apreciar como ele mitiga alucinações de forma tão eficaz. O processo pode ser visualizado por meio do fluxo apresentado na imagem 3:
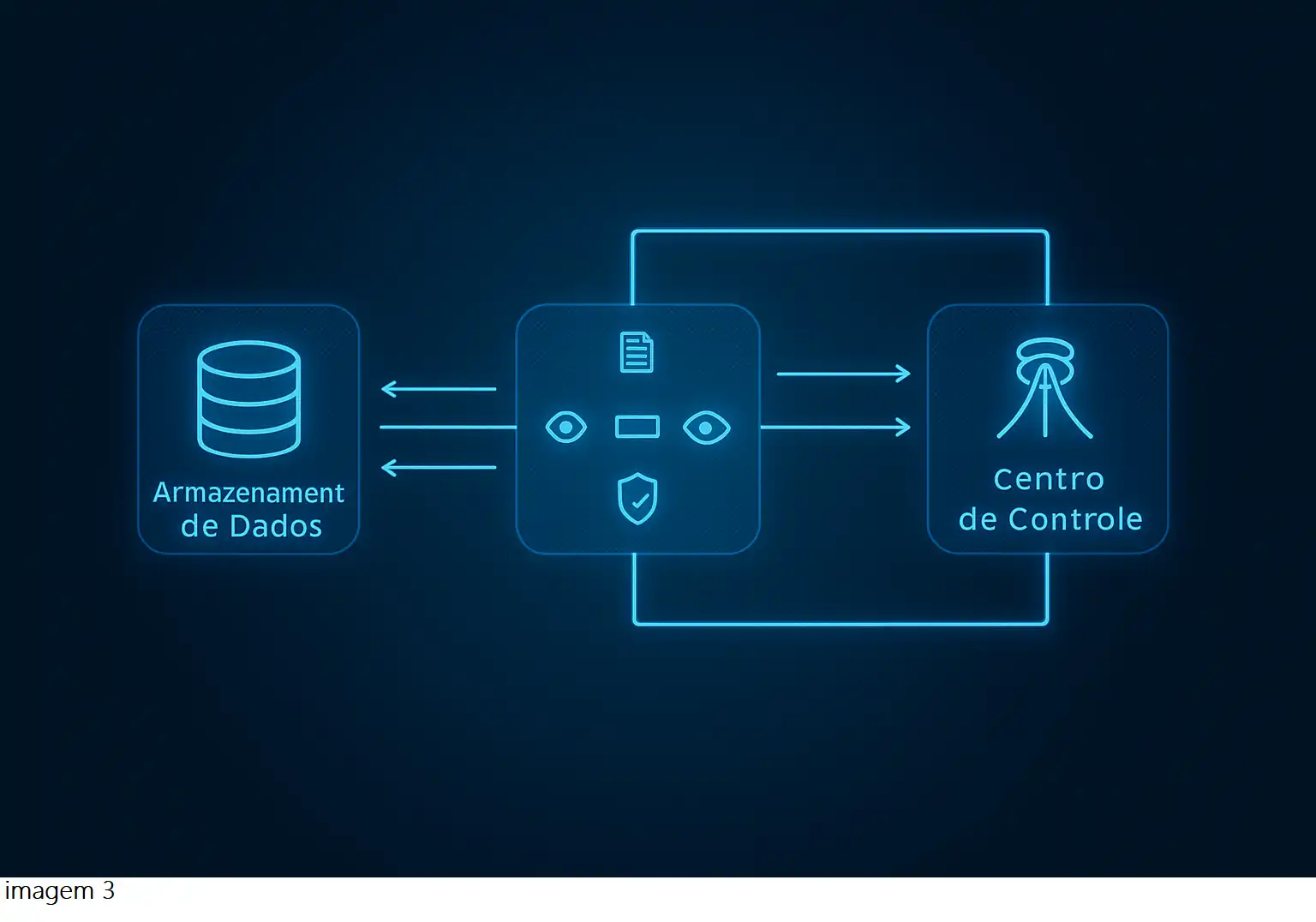
A imagem apresenta um fluxo simplificado de funcionamento do RAG (Retrieval-Augmented Generation), destacando as principais etapas de interação entre o armazenamento de dados, o módulo de processamento e análise, e o centro de controle de IA.
- Armazenamento de Dados: Representa as fontes de conhecimento do sistema, que podem incluir bancos de dados internos, documentos técnicos, artigos científicos e APIs externas. É nesse repositório que o RAG busca informações relevantes para responder às consultas do usuário.
Função principal: fornecer dados factuais e atualizados ao modelo generativo.
- Processamento e Análise de Dados: Este é o núcleo operacional do RAG. Nessa camada, ocorre a busca semântica, a recuperação de contexto e a verificação de segurança e coerência das informações antes da geração textual.
Responsabilidades: converter a consulta do usuário em embeddings, encontrar informações relacionadas e estruturar o contexto que guiará a geração da resposta.
- Centro de Controle de IA: O centro de controle é o modelo generativo principal, responsável por sintetizar a resposta final com base nas informações recuperadas. Esse módulo combina raciocínio linguístico com dados verificáveis, garantindo clareza e precisão.
Função: produzir respostas fundamentadas, transparentes e rastreáveis.
- Ciclo de Retroalimentação: As setas bidirecionais no diagrama indicam um processo contínuo de comunicação e aprendizado. O modelo central envia feedback ao módulo de processamento, que atualiza o armazenamento de dados com novos registros e correções verificadas.
Esse ciclo garante que o sistema permaneça dinâmico, atualizado e cada vez mais confiável.
- Síntese Conceitual: Em termos práticos, o RAG transforma o processo de geração de linguagem ao integrar consulta, verificação e síntese em um fluxo contínuo de informação.
Assim, o modelo deixa de “inventar” respostas e passa a agir como um agente informacional inteligente, capaz de pesquisar antes de responder — essência de sua eficácia contra alucinações em GenAI.
Pipeline Típico de RAG:
- Recepção da Query: O usuário formula uma pergunta ou solicitação ao sistema;
- Embedding da Query: A pergunta é convertida em representação vetorial que captura seu significado semântico;
- Busca Semântica: Sistema busca nos documentos indexados aqueles mais relevantes semanticamente;
- Recuperação de Contexto: Os documentos mais relevantes são extraídos e preparados como contexto;
- Prompt Augmentation: A query original é combinada com o contexto recuperado em um prompt enriquecido;
- Geração Fundamentada: O LLM gera resposta baseada tanto em seu conhecimento quanto no contexto fornecido;
Citação de Fontes: Sistema identifica e apresenta as fontes específicas utilizadas na resposta.
Componentes Tecnológicos Essenciais
- Vector Databases: Bancos de dados especializados como Pinecone, Weaviate ou Milvus que armazenam e buscam eficientemente embeddings vetoriais de documentos.
- Embedding Models: Modelos como Sentence-BERT ou OpenAI embeddings que transformam texto em representações vetoriais densas preservando significado semântico.
- Document Processors: Sistemas que segmentam, limpam e indexam documentos, preparando-os para busca eficiente mantendo contexto relevante.
- Orchestration Layer: Frameworks como LangChain ou LlamaIndex que coordenam todo pipeline de recuperação, contextualização e geração.
Cada componente desempenha papel crítico em garantir que informações factuais sejam recuperadas, contextualizadas e integradas ao processo generativo, minimizando oportunidades para alucinações.
6. Por Que o RAG é eficaz
A alucinação em modelos de linguagem nasce fundamentalmente da falta de lastro factual. O modelo aprende padrões estatísticos durante o treinamento, mas não possui mecanismos internos para verificar a veracidade das informações que gera.
RAG resolve este problema fundamental ao fornecer ao modelo um conjunto robusto de ferramentas cognitivas (GAO et al., 2024).
- Memória Confiável: Acesso a repositórios estruturados de informação verificada, substituindo a "memória" probabilística do modelo por dados factuais.
- Contexto Vivo: Informações atualizadas em tempo real, permitindo que o modelo responda com base em dados recentes e relevantes.
- Base Consultável: Sistema de busca semântica que localiza informações pertinentes antes de cada geração de resposta.
- Verificação Externa: Mecanismo de validação que cruza a resposta gerada com as fontes recuperadas, identificando inconsistências.
Analogia
Pense num médico: existe o que ele sabe de memória, baseado em anos de estudo e experiência. Mas existe também o que ele consulta antes de receitar um remédio - protocolos atualizados, literatura recente, histórico do paciente. Mesma ideia com RAG.
Sem RAG, o modelo "imagina" respostas baseadas em padrões aprendidos, sem garantia de acuracidade. Com RAG, ele pesquisa antes de falar, fundamentando cada afirmação.
Como demonstrado por Gao et al. (2024), a precisão factual aumenta proporcionalmente à qualidade e relevância da base de conhecimento utilizada pelo sistema RAG.
7. RAG Evolutivo: Pipelines Avançados

As versões mais modernas de RAG incorporam múltiplas camadas de inteligência e verificação, incluindo:
- Reordenação de contexto: Prioriza as fontes mais relevantes e confiáveis para cada query específica;
- Filtragem semântica: Remove informações duplicadas ou contraditórias antes da geração;
- Agentes verificadores: Sistemas especializados que validam claims factuais em tempo real;
- Feedback humano e automatizado: Loop contínuo de correção e aprimoramento baseado em avaliações;
- Atualização seletiva do banco de conhecimento: Incorporação inteligente de novas informações verificadas (IZACARD et al., 2023).
Esses mecanismos criam um ciclo virtuoso de melhoria contínua, aproximando o sistema de respostas cada vez mais verificáveis.
O Ciclo Virtuoso do RAG Evolutivo:
- Busca semântica avançada nas fontes mais confiáveis
- Geração fundamentada com base nas informações recuperadas
- Verificação multi-camada contra múltiplas fontes
- Correção automática e aprendizado incremental do sistema
Quase um "treinamento contínuo de verdade", mas sem o caos computacional e financeiro de re-treinar um LLM inteiro (Izacard et al., 2023).
8. Limitações e desafios
Só para ser honesto e realista: RAG não cura tudo. É uma ferramenta poderosa, mas não é mágica e possui limitações importantes que precisam ser reconhecidas.
Compreender essas limitações é fundamental para implementações responsáveis e eficazes.
- Qualidade da Base de Conhecimento: Se a sua base de dados for ruim, incompleta ou tendenciosa, o RAG vai apenas justificar burrices com mais confiança aparente."Garbage in, garbage out" continua sendo uma verdade fundamental (Ji et al., 2023).
- Viés Sistêmico: RAG herda os vieses presentes nas fontes que consulta. Se as fontes refletem preconceitos ou perspectivas limitadas, o modelo reproduzirá esses problemas.
- Conflito de Fontes: Quando diferentes fontes apresentam informações contraditórias, o RAG pode ter dificuldade em determinar qual é a mais confiável ou atual.
- Custo Computacional: Sistemas RAG robustos exigem infraestrutura significativa para busca, recuperação e processamento em tempo real, o que pode ser proibitivo para algumas aplicações.
Princípio Fundamental:
A IA não fica mais inteligente que os dados que alimentam o sistema. Ela só fica mais fundamentada. RAG transforma o modelo em um bibliotecário excepcional, mas não em um pesquisador autônomo.
Portanto, implementar RAG exige investimento contínuo na curadoria e validação das fontes de conhecimento utilizadas.
Além das limitações fundamentais, existem desafios práticos que impactam a eficácia do RAG em reduzir alucinações.
- Latência de Resposta: O processo de busca e recuperação adiciona tempo ao ciclo de resposta, o que pode ser problemático em aplicações que exigem interação em tempo real
- Manutenção de Índices: Bases de conhecimento precisam ser constantemente atualizadas e reindexadas para manter relevância, o que demanda recursos significativos
- Relevância da Recuperação: Se o sistema de busca recuperar documentos irrelevantes ou tangencialmente relacionados, pode confundir o modelo ao invés de ajudá-lo
- Tamanho do Contexto: LLMs têm limites de contexto finitos, então selecionar qual informação incluir no prompt requer estratégias sofisticadas de priorização
Esses desafios não invalidam a utilidade do RAG, mas destacam a importância de implementações cuidadosas e bem arquitetadas para maximizar benefícios na redução de alucinações.
9. RAG e o futuro da IA
Atualmente, o RAG é utilizado como uma ferramenta. Mas em um futuro próximo, ele será a base de um novo protocolo cognitivo essencial para sistemas de IA responsáveis.
A evolução do RAG representa uma mudança profunda na forma como entendemos a inteligência artificial. A IA do futuro não funcionará mais com "memória" no sentido tradicional. Em vez disso, ela irá:
• Consultar bases de conhecimento em tempo real;
• Cruzar informações de diferentes fontes;
• Verificar contradições;
• Aprender continuamente;
• Auditar suas próprias respostas enquanto interage.
Nesse novo cenário, alucinações respostas inventadas ou imprecisas serão vistas como falhas graves, comparáveis a um piloto automático que inventa a altitude ou a um GPS que cria rotas fictícias.
O novo padrão de excelência será baseado em três pilares:
- Verificação Multi-Fonte: A IA consultará automaticamente diversas fontes independentes antes de afirmar qualquer coisa.
- Transparência Total: Cada resposta virá acompanhada de uma trilha completa de evidências, permitindo auditoria e validação por humanos.
- Aprendizado Contínuo: O sistema será capaz de incorporar novos conhecimentos verificados sem precisar ser totalmente reprogramado.
Conclusão
RAG representa uma mudança de paradigma fundamental em como abordamos a confiabilidade de sistemas generativos de IA. Ao ancorar a geração de linguagem em bases factuais verificáveis, conseguimos reduzir drasticamente o problema das alucinações.
No entanto, é importante reconhecer que RAG não é uma solução mágica. Sua eficácia depende criticamente da qualidade das fontes consultadas, da sofisticação dos mecanismos de recuperação e da implementação cuidadosa de sistemas de verificação.
A implementação bem-sucedida de RAG requer compreensão tanto dos aspectos técnicos quanto das limitações inerentes à abordagem. Curadoria de dados, escolha apropriada de componentes tecnológicos e monitoramento contínuo são essenciais.
O futuro da IA responsável passa necessariamente por arquiteturas híbridas como o RAG, que combinam o melhor da criatividade linguística com o rigor da verificação factual. Este é apenas o começo de uma jornada rumo a sistemas de IA verdadeiramente confiáveis, transparentes e úteis para a sociedade.
Referências
Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Proceedings of NeurIPS 2020.
Zhang, Y., et al. (2023). Reducing Hallucinations in Large Language Models via Retrieval-Augmented Generation. Journal of Artificial Intelligence Research, 76, 1247-1289.
Gao, L., et al. (2024). Precision and Recall in RAG Systems: An Empirical Study. Conference on Empirical Methods in NLP.
Izacard, G., et al. (2023). Atlas: Few-shot Learning with Retrieval Augmented Language Models. Journal of Machine Learning Research, 24(23), 1-43.
Ji, Z., et al. (2023). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12), 1-38.
Borgeaud, S., et al. (2022). Improving language models by retrieving from trillions of tokens. International Conference on Machine Learning.
Shuster, K., et al. (2021). Retrieval Augmentation Reduces Hallucination in Conversation. Findings of EMNLP 2021.







