


Como Usar Dados para Reduzir Custos e Atrasos na Construção Civil
- #Data
Como Usar Dados para Reduzir Custos e Atrasos na Construção Civil
Um Guia Técnico e Estratégico com Python e MLOps
Resumo Executivo
O Desafio: Sua construtora gera montanhas de dados (planilhas, fotos, ERP) diariamente, mas 88% das empresas não os transformam em decisões estratégicas preditivas. O resultado? Atrasos caros e desperdício de material.
A Solução Open-Source: Implementar um ecossistema de dados ágil usando Python e ferramentas de código aberto. Comece pequeno e escale conforme o retorno.
O Impacto (ROI Comprovado):
* 15-25% de Redução em custos operacionais e prevenção de desvios no primeiro ano.
* Payback do investimento inicial em apenas 1 a 3 meses.
* Predição: Detecte o risco de atraso 2-4 semanas antes de ocorrer.
Seu Próximo Passo: Escolha um processo crítico (ex: medição diária) e digitalize-o esta semana.
O Fluxo de Dados na Construção Civil
Para um gestor, a complexidade técnica se resume a um ciclo contínuo de transformação. O diagrama a seguir ilustra a jornada do dado, da coleta simples à ação estratégica:
graph TD
A[Coleta em Campo: Forms / Apps] --> B(Bronze: Dados Brutos)
B --> C(dbt / Prefect: Transformação)
C --> D(Silver: Dados Limpos / Integrados)
D --> E(Gold: Agregações / Features p/ ML)
E --> F{ML / BI: Análise Preditiva e Dashboards}
F --> G[Ações em Obra: Decisão Estratégica]
G --> A
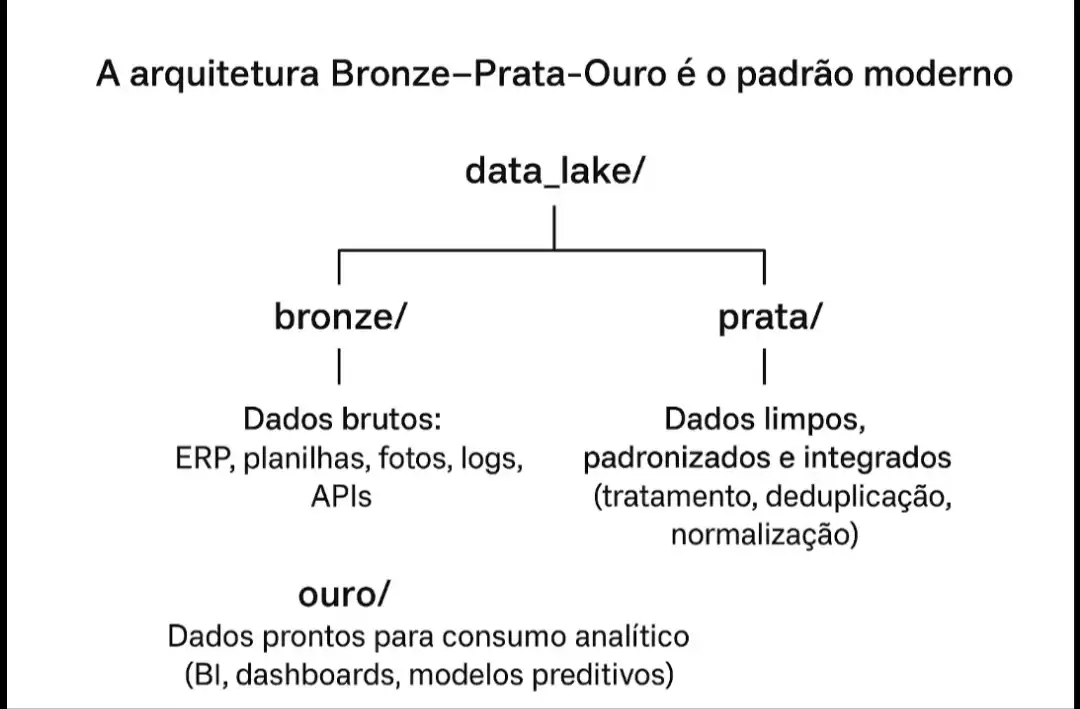
Visão Detalhada (Arquitetura Bronze-Prata-Ouro):
* Bronze: Preservação dos dados originais (auditabilidade).
* Prata: Dados padronizados, limpos e prontos para relatórios.
* Ouro: Dados prontos para o BI (Business Intelligence) e Machine Learning (ML).
1. Arquitetura de Dados: A Fundação Técnica {#1-arquitetura-de-dados-a-fundação-técnica}
A estrutura de dados deve ser flexível para receber dados brutos e otimizada para análise. A arquitetura Bronze-Prata-Ouro é o padrão moderno:
1.1 Data Quality: O Coração da Confiabilidade
Implementar verificações de qualidade é crucial antes de qualquer análise para evitar a "Síndrome do Lixo Entra, Lixo Sai" (Garbage In, Garbage Out).
import pandas as pd
from typing import Dict, List
class DataQualityChecker:
"""Validações essenciais de qualidade de dados na camada Silver"""
def __init__(self):
self.errors = []
def validate_dataset(self, df: pd.DataFrame, rules: Dict) -> bool:
self.errors = []
# 1. Campos obrigatórios (Schema Check)
if 'required_columns' in rules:
missing = set(rules['required_columns']) - set(df.columns)
if missing:
self.errors.append(f"Colunas faltando: {missing}")
# 2. Range de valores (Outlier Check)
if 'value_ranges' in rules:
for col, (min_val, max_val) in rules['value_ranges'].items():
outliers = df[(df[col] < min_val) | (df[col] > max_val)]
if len(outliers) > 0:
self.errors.append(
f"{col}: {len(outliers)} valores fora do range [{min_val}, {max_val}]"
)
# 3. Valores nulos (Integrity Check)
if 'no_nulls' in rules:
for col in rules['no_nulls']:
null_count = df[col].isnull().sum()
if null_count > 0:
self.errors.append(f"{col}: {null_count} valores nulos")
return len(self.errors) == 0
# Exemplo de uso:
# rules = {'value_ranges': {'m2_construidos': (0, 1000)}, 'no_nulls': ['data']}
# is_valid = checker.validate_dataset(df_clean, rules)
2. Stack Tecnológica por Nível de Maturidade {#2-stack-tecnológica-por-nível-de-maturidade}
A jornada deve ser incremental. Comece com o mínimo e adicione complexidade quando o ROI justificar.
| Nível | Objetivo Principal | Stack Recomendada | Custo Mensal Estimado |
|---|---|---|---|
| 1: Fundação | Digitalizar processos, BI básico. | Python, Streamlit (Dashboard), PostgreSQL (Dados). | R$ 50 - 200 |
| 2: Inteligência | Automação de ETL, Análise Preditiva Simples. | Prefect (Orquestração), DuckDB (Análise Rápida), AWS S3 (Data Lake). | R$ 500 - 1.500 |
| 3: Predição | Machine Learning em Produção (MLOps), Visão Computacional. | FastAPI (API de ML), MLflow (Tracking), YOLOv8 (Visão Computacional). | R$ 3.000 - 15.000 |
Nível 2: Orquestração e Integração (ETL)
A automação é fundamental. Usamos Prefect para agendamento e DuckDB para análises rápidas e eficientes em arquivos Parquet no Data Lake (S3).
from prefect import flow, task
from datetime import timedelta
import pandas as pd
@task(retries=3, retry_delay_seconds=30)
def extract_from_erp() -> pd.DataFrame:
"""Extrai dados do ERP, tratando falhas de conexão temporárias."""
# Simulação - em produção, conecta ao SQL Server/SAP B1
# ... código de extração ...
return pd.DataFrame(...)
@task
def transform_data(df: pd.DataFrame) -> pd.DataFrame:
"""Aplica Feature Engineering e Data Quality."""
# Cria features de produtividade (custo/m², m2 acumulado, etc.)
df['custo_m2'] = df['custo_dia'] / df['m2_construidos']
# ... outras transformações para a camada Silver ...
return df
3. Implementação Estratégica e Cultural {#3-implementação-estratégica-e-cultural}
A tecnologia é apenas metade da batalha. A adoção e a cultura de dados são cruciais para o sucesso.
3.1 Superando o Desafio Cultural
* Foco no Valor: Priorize a digitalização de um processo de dor crítica (ex: coleta manual de medição) para entregar valor rápido.
* Treinamento (Data Literacy): Equipes de campo precisam entender como o dado que inserem diretamente impacta seu dia a dia. Use o Streamlit (Nível 1) para dar a eles a visualização imediata dos seus dados.
* Adoção: Adote um processo de "coleta na fonte", como formulários simples (Google Forms/Microsoft Forms), eliminando o retrabalho de planilhas.
3.2 Lidando com Sistemas Legados
A integração de dados (ELT - Extract, Load, Transform) é a chave.
* Extração (E): Use SQLAlchemy (Python) para interagir com bancos de dados legados (SQL Server, Oracle) ou APIs do ERP. Para planilhas descentralizadas, o script de leitura CSV/Excel (pandas) é o extrator do Bronze.
* Transformação (T): No Nível 2, considere adotar o dbt (data build tool). Ele permite que os analistas de dados (não apenas engenheiros) definam as regras de transformação (limpeza, junção de dados) usando apenas SQL, gerenciando a lógica complexa de forma modular e testável.
4. Machine Learning Aplicado: Predição e Visão {#4-4-machine-learning-aplicado-predição-e-visão}
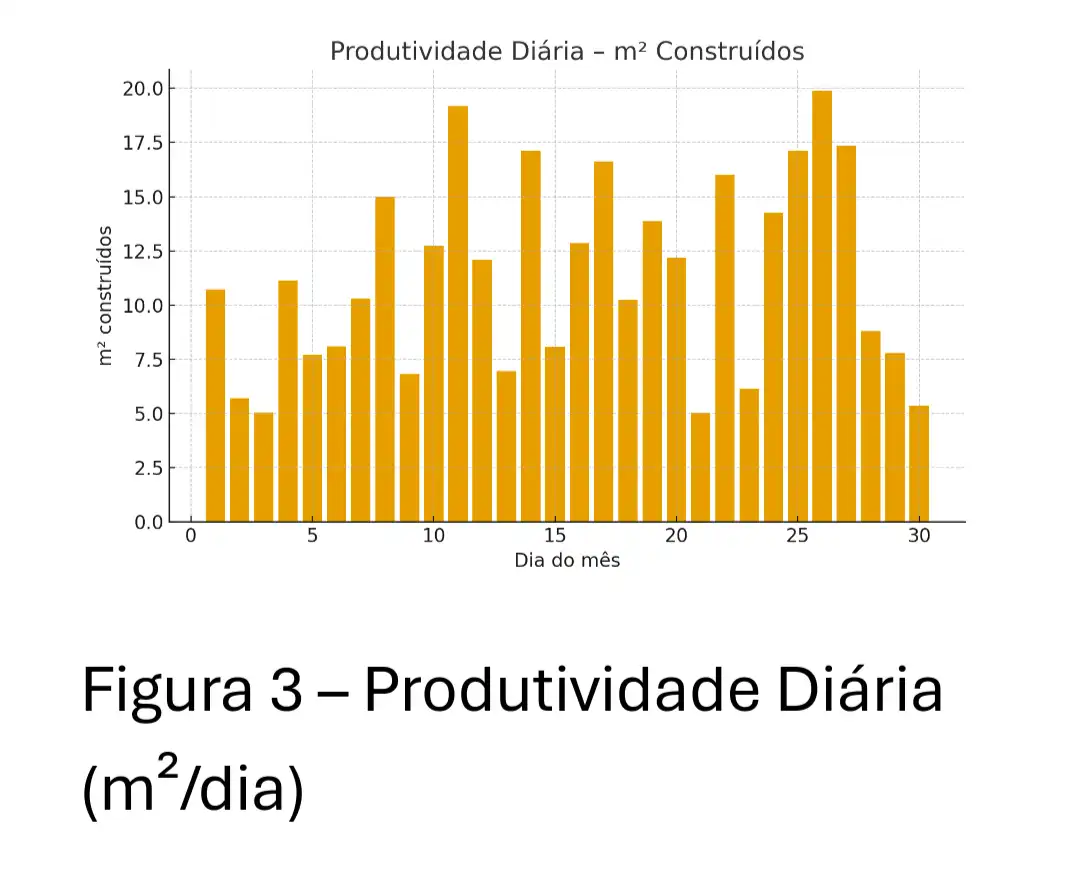
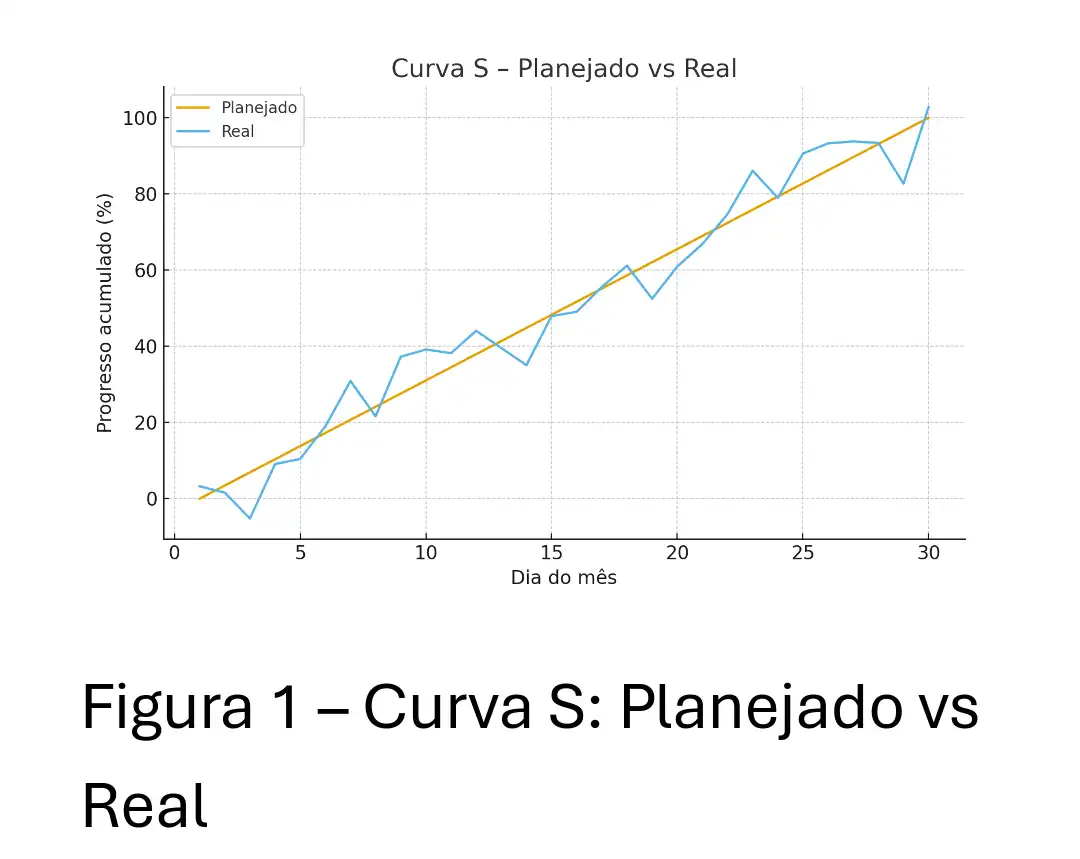
No Nível 3, o foco é em sistemas preditivos que geram recomendações acionáveis.
4.1 Caso Real: Predição de Risco de Atraso
O modelo deve ser preditivo (olhar para o futuro) e explicável.
Features Críticas:
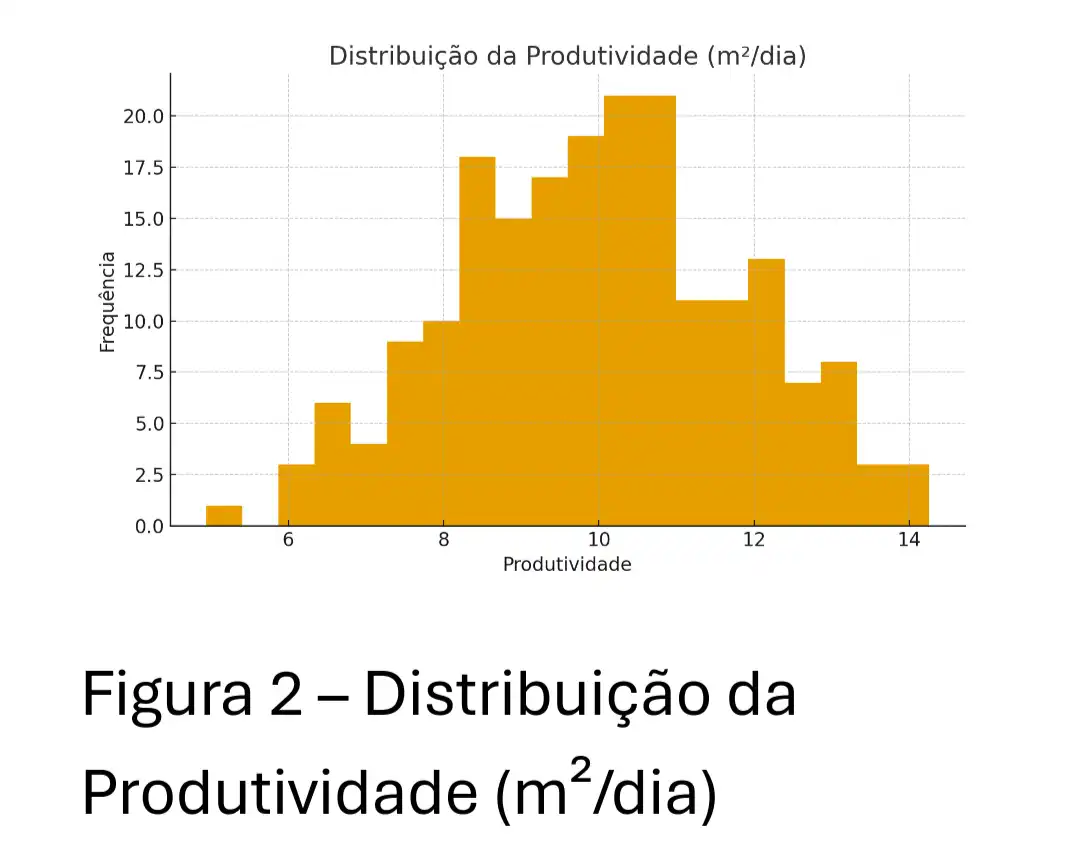
* Produtividade Relativa: Produtividade atual vs Média Histórica daquela atividade.
* Variabilidade (Risco): Desvio Padrão (STD) da Produtividade nos últimos 7 dias.
* Fatores Exógenos: Chuva acumulada, número de não conformidades (indicador de retrabalho).
# Treinamento do modelo de risco (GradientBoostingClassifier)
# ... (código de treino e predict conforme o artigo original) ...
def predict(self, X: pd.DataFrame) -> dict:
"""Predição com Nível de Risco e Explicação Acionável."""
# Supondo que o scaler e o model estejam carregados
# ... (código de predição omitido por brevidade) ...
risk_level = 'ALTO' # ... (calculado) ...
actions = []
if risk_level == 'ALTO':
actions.append(" URGENTE: Revisar insumos e mão de obra imediatamente.")
return {
'probabilidade_atraso': round(prob * 100, 1),
'risco': risk_level,
'acoes_recomendadas': actions
}
4.2 Visão Computacional: Segurança e Produtividade
O uso de YOLOv8 (Ultimaker) para detectar Equipamentos de Proteção Individual (EPIs) ou progresso físico é um dos ROIs de ML mais rápidos.
* Economia: Reduz acidentes (economia indireta massiva) e multas.
* Implementação: O Fine-tuning de um modelo base com 500-1000 imagens da sua obra é suficiente para um MVP de alta precisão.
5. Custos Reais e Análise de ROI Detalhada {#5-custos-reais-e-análise-de-roi-detalhada}
Resultados Práticos e Casos de Sucesso
• Caso Fictício 1: A construtora Alpha Engenharia implementou o Dashboard Diário (Nível 1). Ao monitorar o KPI de custo/m² em tempo real, eles identificaram uma anomalia em uma fundação.
A correção precoce economizou R$ 220.000 em gastos adicionais.
• Caso Fictício 2: A Beta Construções aplicou o Modelo Preditivo (Nível 2). O sistema alertou um risco de atraso 3 semanas antes do previsto.
Com o tempo extra, a gerência reajustou a logística de insumos e mão de obra, reduzindo o atraso final da obra de 30 para 5 dias, o que representou uma redução de 18% no atraso total.
Breakdown de Custos e Pessoal por Estágio
| Nível | Pessoal Principal | Investimento Inicial (R$) | Custo Mensal Recorrente (R$) | ROI Estimado Anual | Payback (Meses) |
|---|---|---|---|---|---|
| 1: Fundação | Eng. de Obra (10% tempo), Consultor Python (40h) | 15.000 | 50 - 200 | R$ 100.000 - 300.000 | 1 - 3 |
| 2: Inteligência | Analista de Dados Júnior | 30.000 | 6.450 | R$ 250.000 - 800.000 | 3 - 6 |
| 3: Predição | Cientista de Dados Sênior, Eng. de ML | 80.000 | 30.000 | R$ 500.000 - 2.000.000+ | 6 - 12 |
Calculadora de ROI
A estimativa conservadora é que a eficiência com dados represente 2% a 10% do faturamento anual.
# Exemplo de uso
calc = ROICalculator(faturamento_anual=50_000_000, num_obras=10)
print(" Análise de ROI com Faturamento Anual de R$ 50 Milhões\n")
for nivel in [1, 2, 3]:
resultado = calc.calculate_roi(nivel)
print(f"Nível {nivel}:")
print(f" Investimento inicial: R$ {resultado['investimento_inicial']:,.0f}")
print(f" Custo ano 1: R$ {resultado['custo_ano_1']:,.0f}")
print(f" Ganho estimado (1º ano): R$ {resultado['ganho_estimado_ano_1']:,.0f}")
print(f" ROI (1º ano): {resultado['roi_ano_1']}%")
print(f" Payback: {resultado['payback_meses']} meses\n")
6. Seu Plano de 30 Dias: A Execução Consistente {#6-seu-plano-de-30-dias-a-execução-consistente}
Semana 1: Setup Técnico e Digitalização
* Dia 1-5: Configurar ambiente Python, Banco de Dados (PostgreSQL) e implementar o Formulário Simples para a Coleta.
Semana 2: Dashboard e Feedback
* Dia 6-14: Implementar Data Quality, criar o Dashboard Streamlit (v1.0) e apresentá-lo à equipe de campo.
Semana 3: Automatização e Data Lake
* Dia 15-21: Conectar a extração de dados do Forms/ERP e construir a transformação Bronze → Prata.
Semana 4: Primeira Análise Preditiva
* Dia 22-30: Criar Features Simples (Produtividade Média) e treinar um Modelo Simples de previsão, integrando o Alerta de Risco ao Dashboard.
Conclusão — Dados Como Base Estrutural da Operação
A construção civil produz diariamente um volume significativo de informações, mas grande parte desse potencial permanece subutilizado por falta de processos, padronização e integração tecnológica.
O objetivo deste guia foi demonstrar que a adoção de uma arquitetura de dados simples, incremental e orientada à operação pode transformar esses registros dispersos em indicadores confiáveis, modelos preditivos funcionais e rotinas de controle que reduzem variabilidade e ineficiências.
Os resultados apresentados não dependem de soluções complexas ou investimentos elevados — dependem de disciplina na coleta, consistência na modelagem e continuidade na automação.
Empresas que conseguem estruturar esse ciclo conseguem antecipar problemas, aumentar a precisão das medições e melhorar a alocação de recursos com base em evidências, não em percepções subjetivas.
Em última análise, a estratégia não consiste em “usar IA”, mas em garantir que os dados estejam organizados, íntegros e acessíveis.
Somente assim é possível aplicar análises confiáveis e evoluir para modelos preditivos que realmente suportem as decisões de campo.
A construção civil sempre lidará com variáveis externas — clima, mão de obra, fornecedores, mudanças de projeto — mas a variabilidade interna pode ser significativamente reduzida.
Processos bem instrumentados e dados estruturados tornam o canteiro mais previsível, permitindo que a engenharia trabalhe com maior precisão e menor incerteza.
Portanto, o próximo passo natural para qualquer empresa é simples: estabelecer uma base de dados consistente e evoluir gradualmente a partir dela.
Essa é a fundação técnica que sustenta toda iniciativa futura de automação, análise e modelagem.
#euSouDioCampusExpert14 #analiseDeDados #cienciaDeDados






