

Conheça as principais bibliotecas de Python em 10 minutos
- #Python
Python é uma linguagem de programação criada por Guido van Rossum em 1989 e lançada a público em 1991.
Seu foco era simplicidade e legibilidade.
Com o tempo, a linguagem ganhou popularidade em várias áreas: ciência de dados, web, automação e inteligência artificial.
Um dos pontos mais fortes do Python é seu ecossistema de bibliotecas.
Elas funcionam como blocos de construção, permitindo que desenvolvedores usem código pronto e testado.
Isso economiza tempo e torna projetos mais produtivos.
O que são bibliotecas em Python
Uma biblioteca em Python é um conjunto de módulos e pacotes que oferecem funcionalidades prontas.
Isso evita reinventar a roda em tarefas comuns, como manipular datas ou gráficos.
Exemplo de biblioteca simples criada pelo usuário:
# arquivo: meu_modulo.py
def saudacao(nome):
return f"Olá, {nome}!"
# programa principal
import meu_modulo
print(meu_modulo.saudacao("Ana"))
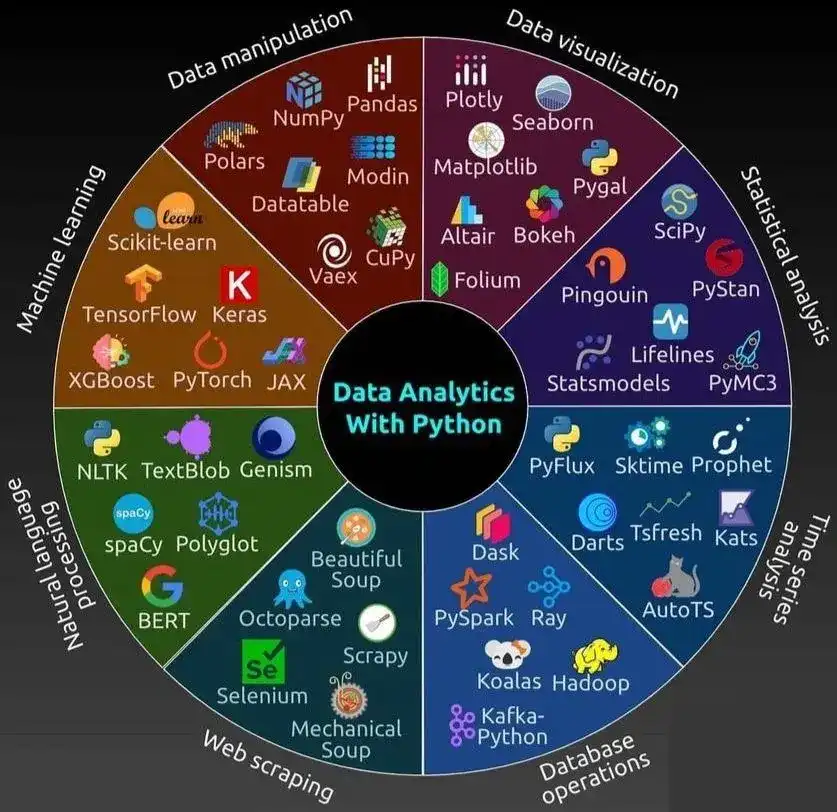
Tipos de bibliotecas
Standard Library
O Python vem com dezenas de módulos prontos para uso.
São chamados de biblioteca padrão.
Principais exemplos:
os→ manipulação de arquivos e pastas.sys→ interação com sistema e argumentos.datetime→ datas e horários.json→ leitura e escrita em JSON.
Exemplo com datetime:
import datetime
hoje = datetime.date.today()
print("Data atual:", hoje)
Bibliotecas de terceiros
São pacotes criados pela comunidade e instalados via pip ou conda.
Exemplos populares:
- NumPy → computação numérica.
- Pandas → análise de dados.
- Matplotlib / Seaborn / Plotly → gráficos.
- Requests → chamadas HTTP.
- Scikit-learn → machine learning.
📊 Comparação rápida:

Bibliotecas essenciais na prática
NumPy
import numpy as np
a = np.array([1,2,3])
b = np.array([4,5,6])
print(a + b) # [5 7 9]
Pandas
import pandas as pd
df = pd.DataFrame({"Nome":["Ana","João"], "Idade":[23,34]})
print(df)
Matplotlib
import matplotlib.pyplot as plt
plt.plot([1,2,3], [2,4,6])
plt.title("Gráfico simples")
plt.show()
Requests
import requests
r = requests.get("https://api.github.com")
print(r.status_code)
Scikit-learn
from sklearn.linear_model import LinearRegression
import numpy as np
X = np.array([[1],[2],[3]])
y = np.array([2,4,6])
modelo = LinearRegression().fit(X,y)
print(modelo.predict([[4]])) # [8.]
Critérios para escolher bibliotecas
- Manutenção ativa → atualizações frequentes.
- Documentação → bons tutoriais e exemplos.
- Desempenho → otimização para grandes volumes.
- Licença → compatibilidade com projetos comerciais.
- Integração → facilidade de combinar com outras libs.
Exemplo: preferir httpx a requests em sistemas assíncronos.
Integração entre bibliotecas
Muitas vezes as bibliotecas trabalham juntas em pipelines:
Requests→ coletar dados da web.Pandas→ organizar em DataFrame.Scikit-learn→ treinar modelo.Matplotlib→ visualizar resultados.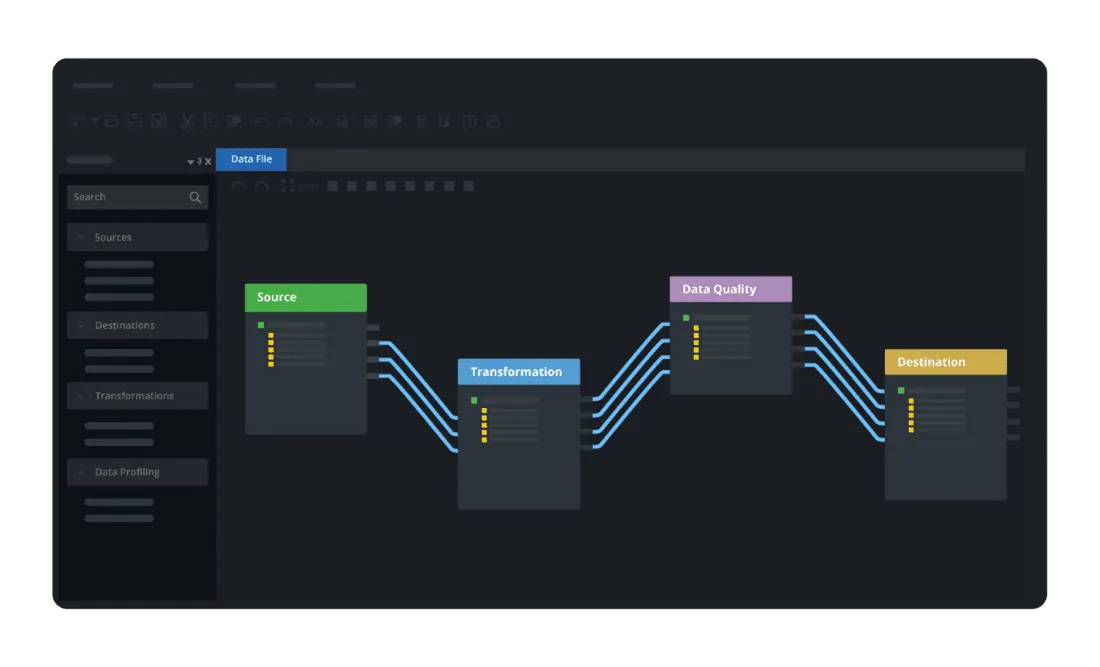
Boas práticas
- Ler a documentação oficial sempre.
- Fixar versões em
requirements.txt. - Usar ambientes virtuais (
venv,conda). - Escrever testes automatizados.
- Monitorar desempenho com
timeoucProfile.
Exemplo de requirements:
numpy==1.26.0
pandas==2.2.0
scikit-learn==1.5.0
Bibliotecas emergentes e tendências
- FastAPI → criação de APIs modernas.
- Polars → alternativa mais rápida ao Pandas.
- Ray e Dask → computação distribuída.
- TensorFlow / PyTorch → aprendizado profundo.
- Hugging Face → processamento de linguagem natural.
Onde as bibliotecas são usadas no cotidiano
Ciência de Dados
- Corporações usam Pandas + NumPy para análises financeiras.
- Hospitais aplicam modelos com Scikit-learn em diagnósticos.
Inteligência Artificial
- Treinamento de redes neurais com PyTorch.
- Processamento de textos com Transformers.
Automação
- Scripts de ETL com Pandas.
- Web scraping com Requests + BeautifulSoup.
Desenvolvimento Web
- FastAPI + Uvicorn para APIs escaláveis.
- Django para sistemas completos.
Exemplos práticos
CSV + Pandas:
Ler um arquivo CSV e calcular a média de uma coluna.
import pandas as pd
# 1. Solicita o caminho do arquivo CSV
caminho_arquivo = input("Digite o caminho do arquivo CSV: ")
try:
# 2. Lê o CSV
df = pd.read_csv(caminho_arquivo)
print("\nColunas disponíveis no arquivo:")
print(df.columns.tolist())
# 3. Solicita o nome da coluna para calcular a média
nome_coluna = input("\nDigite o nome da coluna para calcular a média: ")
if nome_coluna in df.columns:
# 4. Calcula a média (ignorando valores não numéricos ou nulos)
media = pd.to_numeric(df[nome_coluna], errors='coerce').mean()
print(f"\nA média da coluna '{nome_coluna}' é: {media}")
else:
print(f"\nColuna '{nome_coluna}' não encontrada no arquivo.")
except FileNotFoundError:
print("\nArquivo não encontrado. Verifique o caminho e tente novamente.")
except Exception as e:
print(f"\nOcorreu um erro: {e}")
Matplotlib:
Criar um gráfico de barras mostrando vendas por mês.
import matplotlib.pyplot as plt
# Dados de vendas por mês
meses = ['Jan', 'Fev', 'Mar', 'Abr', 'Mai', 'Jun',
'Jul', 'Ago', 'Set', 'Out', 'Nov', 'Dez']
vendas = [1200, 1500, 1700, 1600, 1800, 2000, 2200, 2100, 1900, 2300, 2500, 2700]
# Criando o gráfico
plt.figure(figsize=(10, 6))
plt.bar(meses, vendas, color='steelblue')
# Adicionando títulos e rótulos
plt.title('Vendas por Mês', fontsize=16)
plt.xlabel('Mês')
plt.ylabel('Vendas')
plt.grid(axis='y', linestyle='--', alpha=0.6)
# Exibir o gráfico
plt.tight_layout()
plt.show()
Scikit-learn:
Treinar um modelo de regressão linear simples.
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# Dados simples (listas puras)
X = [[1], [2], [3], [4], [5]]
y = [2, 4, 6, 8, 10] # y = 2x
# Dividir os dados
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Criar e treinar o modelo
model = LinearRegression()
model.fit(X_train, y_train)
# Fazer previsões
y_pred = model.predict(X_test)
# Avaliação
print("Coeficiente angular (slope):", model.coef_[0])
print("Intercepto:", model.intercept_)
print("R²:", r2_score(y_test, y_pred))
print("MSE:", mean_squared_error(y_test, y_pred))
Requests:
Acessar uma API de clima e exibir a temperatura atual.
import requests
def pegar_temperatura(cidade, api_key):
url = f"http://api.openweathermap.org/data/2.5/weather?q={cidade}&appid={api_key}&units=metric&lang=pt_br"
resposta = requests.get(url)
if resposta.status_code == 200:
dados = resposta.json()
temperatura = dados['main']['temp']
print(f"A temperatura atual em {cidade} é {temperatura}°C.")
else:
print("Erro ao acessar a API:", resposta.status_code, resposta.text)
if __name__ == "__main__":
API_KEY = "YOUR_API_KEY"
CIDADE = "São Paulo"
pegar_temperatura(CIDADE, API_KEY)
Conclusão
As bibliotecas são o verdadeiro poder do Python.
Elas transformam a linguagem em uma ferramenta universal para dados, web, automação e inteligência artificial.
Conhecer as principais bibliotecas e adotar boas práticas é fundamental.
Isso garante produtividade, código limpo e projetos de maior impacto.
Python não é apenas uma linguagem.
É um ecossistema vivo, em constante evolução.
Referências
- Python Software Foundation. Documentação oficial do Python 3. https://docs.python.org/3/
- Real Python. Python Standard Library. https://realpython.com
- McKinney, Wes. Data Analysis with Pandas. O’Reilly.
- NumPy Docs: https://numpy.org/doc/
- Pandas Docs: https://pandas.pydata.org/docs/
- Scikit-learn Docs: https://scikit-learn.org/stable/
- arXiv. SciPy 1.0: Fundamental Algorithms for Scientific Computing.
- Hugging Face. Transformers Documentation.





Excelente, Sintique! Que artigo incrível e super completo sobre "Minha Jornada no Universo da Tecnologia: Do Primeiro Passo à Transformação"! É fascinante ver como você aborda a sua jornada na área tech não como uma corrida, mas como uma jornada de aprendizado que tem a tecnologia como um "passaporte para transformar realidades", inclusive a sua própria.
Você demonstrou que a sua paixão por aprender a levou a buscar inspiração em profissionais que já estavam na área e a entender que ninguém cresce sozinho. Sua análise de que a tecnologia exige mais do que técnica, e que a resiliência, a colaboração e o propósito são habilidades essenciais, é um insight valioso para a comunidade.
Qual você diria que é o maior desafio para um profissional ao unir o conhecimento em ciências com a tecnologia, em termos de encontrar a intersecção entre as duas áreas e de traduzir a lógica de uma para a outra, em vez de apenas focar em um deles?