


Engenharia de Navegadores — O que você ainda não sabe!
- #JavaScript
- #Node.js
- #React
Será um diferencial enorme para um desenvolvedor que compreende a natureza do motor de renderização de navegadores e outros componentes envolvidos, neste artigo busco trazer uma visão desse ecossistema.
Navegadores são construídos de Front-end e Back-end, enquanto o Front-end trabalha na camada visual o Back-end manipula as requisições e as transporta, ambos componentes distintos trabalham em conjunto para compor a nossa experiência.
Os 7 componentes dos navegadores
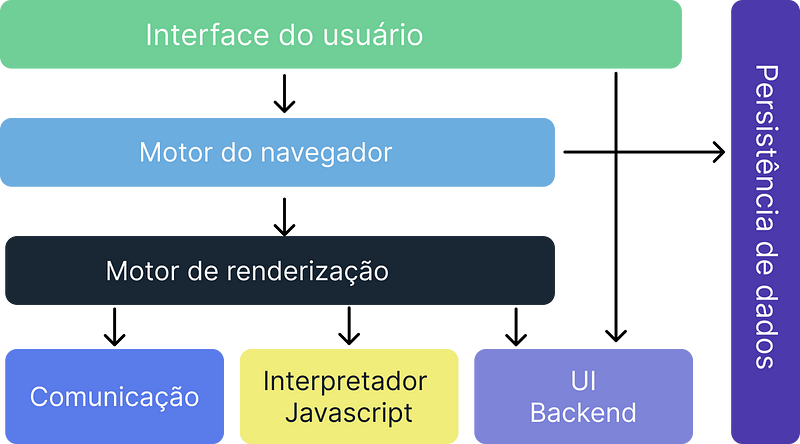
Interface do usuário
Compõem não só a pagina que estamos acessando, mas todas os menus e campos de busca do próprio navegador de forma geral é tudo que podemos ver e interagir.
Motor do navegador
Este é o componente principal, funcionando como uma ponte entre a interface do usuário e o motor de renderização, manipulando o mecanismo de renderização de acordo com as entradas do usuário.
Motor de renderização
Composto de um interpretador HTML e XML e em conjunto com CSS ele interpreta e renderiza um novo layout na interface do usuário.
Cada navegador possui um único motor de renderização, variando de acordo com o ambiente em que esta sendo executado, os motores mais conhecidos atualmente e suas respectivas mantenedoras são Blink (Chrome), WebKit(Apple), Trident (Microsoft) e Gecko (Mozilla).
Como citei acima depende muito do ambiente em que esta sendo utilizado, quando estamos falando de um iPhone, o Chrome precisa utilizar o Webkit para ser executado no iOS.
De forma resumida o motor de renderização tem o objetivo de transformar código HTML e CSS em Pixel, neste artigo eu explico brevemente como o CSS atua em pixels.
Comunicação
Esse componente administra as conexões do tipo HTTP e FTP do navegador, além de problemas de segurança.
Interpretador Javascript
Interpreta e executa o código Javascript em uma pagina, o resultado obtido na fase de execução do código é enviado para o motor de renderização para mostrar ao usuário.
UI Backend
Este componente utiliza elementos nativos do sistema operacional para desenhar janelas e outros elementos do navegador.
Persistência de dados
Dedicado ao armazenamento de informações localmente no browser, persistindo as informações.
Esses são os componentes de um navegador, agora vamos nos aprofundar mais e entender como cada um deles funcionam dentro do fluxo comum ao acessar uma pagina.
Fluxo de um navegador
O motor de renderização inicia recebendo o documento da camada de comunicação, isso acontece em pedaços, digamos que cada pedaço do documento HTML é obtido em “parcelas”.
Construção da DOM
Ao receber o HTML ele converte os elementos em nós DOM (Document Object Model) para uma arvore chamada de “arvore de conteúdo” até esse momento não existe nada visual na tela do usuário, todo esse processo é executado no backend do navegador, a arvore DOM em si não é exibida para o usuário, a imagem ilustra o que exatamente seria o DOM.
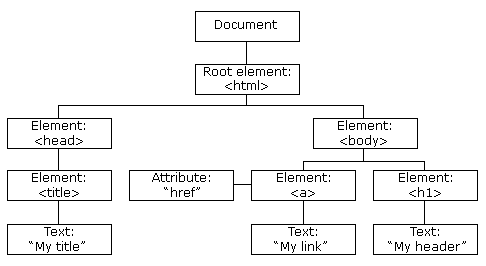
O objetivo da arvore DOM é representar documentos HTML para o mundo exterior, como exemplo o Javascript, digamos que seria o resultado do compilador do HTML, neste documento é possível entender como isso funciona em detalhes.
Analisador HTML
A construção da arvore DOM é feita convertendo o documento para uma estrutura que o código pode utilizar e o resultado é uma estrutura de nós que representa a estrutura do documento HTML, então digamos que temos a expressão (5 + 5) * 2:

A conversão do documento para construir os nós também inclui a analise de sintaxe, seguindo regras gramaticais da linguagem que se esta utilizando.
Na lingua portuguesa existem regras gramaticais, um exemplo bem simples é o uso do “mim” em algumas frases, exemplo “Mim empresta esse lápis?”, dado que o correto seria “Me empresta o lapis?”.
Durante a analise do código é realizado duas operações, analise gramatica da linguagem e analise léxica.
Análise Gramatica
Como explicado, refere-se ao conjunto de regras da linguagem, em programação essas regras são chamadas de sintaxe e temos muitas regras como a criação de variáveis que não devem ser declaradas como nome usuario e assim nomeUsuarioou nome_usuario entre outras.
Análise Léxica
Consiste na análise de todas as palavras validas em uma linguagem, comparando com a lingua portuguesa seria o uso de todas as palavras que estão no dicionário e seu devido significado.
Nos navegadores essa operação é realizada pelo “lexer” e possui o mesmo principio, porém chamamos essas palavras de “tokens” e para o computador compreender ele precisa interpretar-las, temos alguns exemplos disso:
Dado a expressão x = a * b / 3 e os tokens:
Identificador: x, a, b
Palavra chave: if, while, const, let
Separador: }, {, ;, (
Literal: true, "music", 6.02e23
Comentário: /* comment */, // coment
Convertendo a expressão para os tokens, teríamos:
[(identificador, x), (operador, =), (identificador, a), (operador, *),
(identificador, b), (operador, /), (literal, 2)]
Em programação a definição de tokens e regras são definidas utilizando BNF, é como se fosse um tipo de regex que determina o padrão de palavras.
Durante a análise o “lexer” fornece ao analisador os tokens para construir a arvore e faz a combinação deles com as regras de sintaxe. Caso uma regra corresponda ao token, um novo nó será adicionado a arvore, se não houver correspondência ira ocorrer uma exceção, gerando um erro.
Na especificação do HTML você pode visualizar o processo de tokenização em detalhes.
Você nunca verá um erro de sintaxe invalida no HTML, os navegadores resolvem qualquer problema relacionado a tag invalida ou conteúdo, esse não é um recurso que faz parte da especificação do HTML, muitos navegadores fazem isso de forma independente.
Carregamento de Scripts
No HTML temos a tag “<script/>” por vezes adicionada ao topo e outras ao final do documento HTML, o Analisador determina que quando for identificado uma tag script ele deve ser executado imediatamente, caso o script seja externo o analisador interrompe a analise do documento e construção da DOM até que o script seja carregado. Esse recurso esta presente no HTML5 e para evitar que a analise do documento seja interrompida, basta adicionar a propriedade “defer” ao script, mas tome cuidado com esse recurso, mais a frente você ira entender o motivo.
Analisador CSS
O CSS não afetam a arvore DOM, pois são gerados na arvore de renderização e desse modo o carregamento da arvore de DOM não precisa ser interrompido para o carregamento do CSS, ambos são realizados simultaneamente e separados. E como explicado anteriormente, quando é identificado a tag script o carregamento da DOM é interrompido junto ao carregamento de CSS, porém alguns scripts fazem a iteração com elementos do CSS e enquanto esses scripts estão sendo carregados o CSS ainda não foi processado, desse modo pode gerar alguns erros dado que o carregamento do CSS foi interrompido para carregar os scripts.
Para evitar isso alguns navegadores bloqueia o carregamento de scripts quando existe CSS que ainda não foi processado ou bloquei os scripts apenas quando eles tentam acessar propriedades do CSS.
Diferente do HTML, o CSS utiliza análise gramatica e análise léxica explicado anteriormente.
Arvore de renderização
Como dito anteriormente, em paralelo, durante a conversão de HTML para DOM o navegador constrói outra arvore. A arvore de renderização, nesta arvore ficara a representação dos elementos visuais com base em nós DOM convertidos até aquele momento e as declarações de estilos como o CSS.
A adição de elementos visuais a arvore de renderização é feita por um método ou função (se assim tornar melhor o entendimento) chamado attach (anexo), esse método fica em cada nó da arvore DOM e é executado automaticamente toda vez que um novo nó é adicionado a DOM.
As tags html e body da arvore DOM formam a raiz da arvore de renderização, essa raiz é chamada de viewport que contém as dimensões da tela, os demais elementos da tela será inseridos dentro da viewport.
Um dos componentes do navegador, o renderizador quando adiciona um nó ao DOM esse nó carrega consigo uma propriedade chamada “dirty bit” que informa ao renderizador se ele ou os “filhos”necessitam de atualização, assim quando for necessário realizar atualizações o renderizador não precisa carregar a pagina inteira, apenas partes que realmente são necessárias.
Após construir a arvore de renderização o navegador precisa indicar onde esses elementos visuais serão exibidos na tela, pois até esse momento ele não possui posição e nem tamanho.
A arvore de renderização tem o seu mecanismo de hierarquia, a div pai herda o tamanho da viewport, a div filho herda o tamanho do pai e assim por diante, então se definirmos uma div pai com 100%, ela ocupa todo o tamanho da viewport, a mesma coisa acontece com o filho.
E chegando ao momento de realmente exibir os elementos na tela, o render possui um método chamado “paint()” que é chamado para exibir o conteúdo da pagina em tela, utilizando a estrutura de UI do usuário.
Aqui você pode olhar com mais detalhes a ordem de “pintura” na tela, mas de forma resumida ao contrario do que muitos imaginam as paginas são construídas de trás para frente, seguindo uma certa ordem:
- Background color
- Background image
- bordar do elemento
- Em seguida bem outros elementos, como textos.
A ordem de renderização depende muito do tipo do elemento, em uma tabela seria essa ordem:
- Background table
- column group
- column background
- row group
- row background
- cell background
- border table
- E demais elementos
Cada navegador possui o seu motor de renderização e formas de pinta-los na tela como mencionei anteriormente, citando o Blink, Trident, Gecko e Webkit.
Mostrando isso na prática podemos testar isso com o site do G1, um portal de noticias bem conhecido no Brasil. Acessando o dev tools do seu browser e indo na timeline, podemos ver a ordem de carregamento da pagina, nas suas primeiras 4 imagens:
Como explicado anteriormente, primeiro vem as cores de fundo.
Em seguida imagens (Noticia principal) — Borrei a imagem.
Textos (Menu do site) — Lembrando que o icone do g1 é um svg escrita em XML, quase que o equivalente a HTML.
Todas essas construções de layout são salvas em cache, o browser tenta fazer mínimas alterações e refazer esses processos do zero, alterações de cores em um elemento “filho” irá gerar uma ação de re-pintura apenas nesse filho, já mudanças de posicionamento ou alteração de fonte da pagina irá gerar a reconstrução do layout do zero, substituindo valores em cache.
De acordo com a descrição de CSS Box Model cada nó da arvore DOM é uma caixa, um retângulo para ser exato e possuem algumas propriedades ou capacidades como mostrado na imagem:
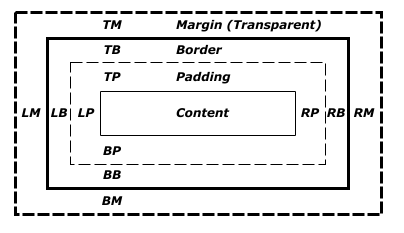
Na imagem existe a abreviação dessas propriedades que ja são bem conhecidas, como:
TM: Top margin
TB: Top border
TP: Top padding
E assim por diante, dado a direção e o nome da propriedade (padding, border e margin) a imagem abaixo ilustra essas caixas em elementos.
Alem disso existem outras propriedades do CSS que imagino que já é do seu conhecimento, como display flex, position e etc..
Um caso interessante é que quando utilizamos um posicionamento normal ou padrão de um elemento ele ocupa na arvore de renderização exatamente a posição que ocupa na arvore DOM esse é o caminho mais proximo que conseguimos chegar de como seria a arvore DOM representado na arvore de renderização, já quando utilizamos outras propriedades como o float ele ocupa outra posição na arvore de renderização.
Para saber em detalhes como o CSS interpreta o DOM e aplica estilos a eles veja aqui o modelo de processamento CSS.
Para realizar todos esses processos que aprendemos até aqui os navegadores utilizam algo chamado Evento Loop, um processo que não morre e sempre esta ali, vivo e aguardando o proximo evento a ser executado de forma sequencial e ordenada.
É importante lembrar que todo esse processo é realizado paralelamente, recebimento do documento da camada de comunicação, conversão de HTML para DOM, arvore de renderização e Layout, ou seja, o browser não espera receber 100% do documento para iniciar os seus processos. De acordo com que recebe ele vai construindo cada camada com base no documento.
Eu julgo ser de vital importância um desenvolvedor entender a natureza desses processos, o caso do carregamento do CSS em conjunto com a DOM e JS é um exemplo disso, caso o seu script esteja configurado para ter prioridade no carregamento e não encontrar uma propriedade CSS, ira gerar infinitos erros ou aquela animação não funcionaria.
Mas agora você sabe disso e acredito que lendo todos os links que deixei em cada seção ira se aprofundar ainda mais no tema e não falando apenas de problemas, mas você também pode criar aplicações mais performáticas com essas informações sabendo como cada elemento é carregado você pode utilizar o sistema ao seu favor.
E claro, somos eternos aprendizes deixei abaixo suas considerações e caso tenha curtido o conteúdo deixe alguns Clap's para ajudar.
Agradeço muito por estar aqui e desejo sucesso na sua jornada, grande abraço.
Github: https://github.com/marcelxsilva
Outras redes: https://linktr.ee/marcelxsilva


