


Explorando as bibliotecas de IA na linguagem Python
A linguagem Python ganhou muita popularidade ao longo dos últimos anos devido a sua sintaxe simples e também devido a várias bibliotecas e frameworks especializados que permitem executar diversas aplicações práticas. E além disso existem ferramentas como o Google Colab e comunidade da empresa Hugging Face que democratizam o acesso a códigos prontos de IA para que qualquer pessoa possa experimentar soluções prontas.
Neste artigo vou mostrar:
- As principais bibliotecas e frameworks da linguagem python e como aplicá-los
- um código simples usando machine Learning Clássico e outro usando usando processamento de linguagem natural ( o NLP)
Analisando o passo-a-passo das etapas de criação de um projeto básico de machine learning de forma simplificada com exemplos de código usando machine learning clássico
A Árvore de Decisão é um algoritmo de aprendizado supervisionado que pode ser usado tanto para problemas de classificação quanto de regressão. A sua principal vantagem para iniciantes é a fácil interpretação do seu código. Uma árvore de decisão é fácil de visualizar e entender, o que facilita a explicação de cada etapa do processo de Machine Learning.
Vamos usar a Árvore de Decisão como exemplo para detalhar cada fase do ciclo de vida de um projeto de Machine Learning, desde a preparação dos dados até o deploy.
1. Preparação dos Dados (Data Preparation)
Esta fase é crucial e geralmente a mais demorada em qualquer projeto de Machine Learning. A qualidade dos dados impacta diretamente a performance do modelo.
- Coleta de Dados: O primeiro passo é coletar os dados relevantes para o problema que você deseja resolver. Para um exemplo com Árvore de Decisão, imagine que queremos prever se um cliente irá cancelar um serviço de assinatura (churn). Precisamos coletar dados sobre os clientes, como idade, tempo de assinatura, uso do serviço, histórico de pagamentos, etc.
- Limpeza de Dados: Dados do mundo real frequentemente contêm erros, valores faltantes ou inconsistências. É necessário limpar os dados para garantir a qualidade. Isso pode incluir:
- Tratar valores faltantes: Remover as linhas com valores faltantes ou preencher com valores médios, medianos ou outros métodos de imputação.
- Remover outliers: Identificar e tratar valores que estão muito fora do padrão.
- Corrigir erros: Corrigir dados inconsistentes ou errados.
- Seleção de Features (Atributos): Nem todos os dados coletados serão relevantes para o estimador. Selecionar as features mais importantes ajuda a simplificar o modelo inteligente, melhorar a performance e reduzir o tempo de treinamento. Para Árvores de Decisão, podemos usar técnicas como importância de features fornecidas pelo próprio algoritmo ou métodos de seleção baseados em estatística.
- Engenharia de Features (Opcional, mas recomendado para aprendizado): Criar novas features a partir das existentes pode melhorar a performance do modelo. Por exemplo, a partir da data de início e data de fim de assinatura, podemos criar uma feature 'tempo de assinatura' em meses.
- Divisão dos Dados: Os dados precisam ser divididos em pelo menos dois conjuntos:
- Conjunto de Treinamento: Usado para treinar o modelo, ou seja, para o algoritmo aprender os padrões nos dados. Geralmente corresponde a 70-80% dos dados.
- Conjunto de Teste: Usado para avaliar a performance do modelo após o treinamento, simulando dados não vistos pelo modelo durante o treinamento. Geralmente 20-30% dos dados.
- Em projetos mais complexos, pode-se usar também um Conjunto de Validação para ajustar hiperparâmetros do modelo durante o treinamento.
2. Treinamento do Modelo (Model Training)
Nesta fase, o algoritmo de Machine Learning aprende com os dados de treinamento.
- Escolha do Algoritmo: Neste caso, escolhemos a Árvore de Decisão. É importante explicar que existem outros algoritmos (Regressão Linear, Regressão Logística, Redes Neurais, etc.), mas a Árvore de Decisão é didática para iniciantes.
- Treinamento do Algoritmo: O algoritmo da Árvore de Decisão aprende a criar regras de decisão com base nos dados de treinamento. Ele faz isso dividindo os dados em subconjuntos menores com base nas features, buscando maximizar a "pureza" (homogeneidade) das classes em cada subconjunto. Conceitos chave para explicar são:
- Nós de decisão: Representam uma feature (atributo) que será testada.
- Ramos: Representam o resultado do teste e levam a outros nós ou nós folha.
- Nós folha (ou terminais): Representam a decisão final ou a previsão.
- O algoritmo busca dividir os dados de forma que a impureza (ex: Entropia ou Gini) seja minimizada a cada divisão.
- Ajuste de Hiperparâmetros (Opcional, mas importante para melhorar o modelo): As Árvores de Decisão têm hiperparâmetros que podem ser ajustados para controlar a complexidade da árvore e evitar overfitting (quando o modelo aprende muito bem os dados de treinamento, mas performa mal em dados novos). Exemplos de hiperparâmetros são a profundidade máxima da árvore (max_depth), número mínimo de amostras para dividir um nó (min_samples_split), etc.
3. Implementação/Construção do Modelo (Model Implementation/Building)
Nesta fase, construímos o modelo utilizando uma biblioteca de Machine Learning.
- Codificação: Usando uma biblioteca como scikit-learn em Python, a implementação de uma Árvore de Decisão é relativamente simples. Veja um exemplo conceitual em Python:
from sklearn.tree import DecisionTreeClassifier # Para classificação
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Suponha que você já preparou os dados X (features) e y (variável alvo)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Divide os dados
arvore_decisao = DecisionTreeClassifier(max_depth=3) # Cria o modelo de Árvore de Decisão, ajustando hiperparâmetro
arvore_decisao.fit(X_train, y_train) # Treina o modelo com os dados de treinamento
Visualização da Árvore (Ótimo para Árvores de Decisão): Uma das grandes vantagens das Árvores de Decisão é que podemos visualizar a árvore gerada. Isso ajuda muito na interpretação e no entendimento de como o modelo toma decisões.
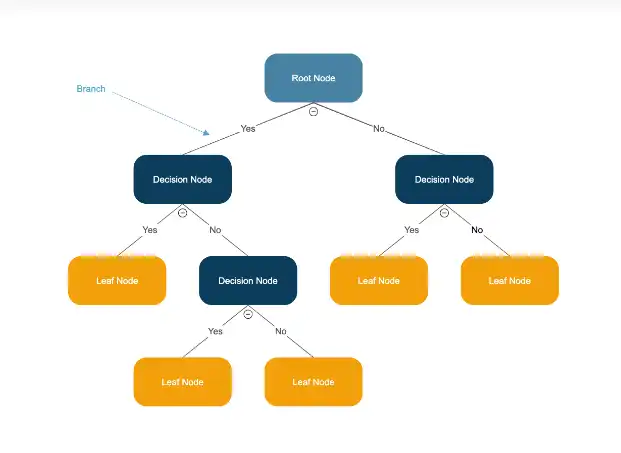
decision tree
4. Testes e Validação do Modelo (Model Testing and Validation)
Após treinar o modelo, precisamos avaliar o quão bem ele performa em dados não vistos (conjunto de teste).
- Previsões no Conjunto de Teste: Usamos o modelo treinado para fazer previsões no conjunto de teste:
y_pred = arvore_decisao.predict(X_test) # Faz previsões nos dados de teste
- Métricas de Avaliação: Precisamos de métricas para quantificar a performance do modelo. As métricas dependem do tipo de problema:
- Para Classificação:
- Acurácia (Accuracy): Proporção de previsões corretas.
- Precisão (Precision): Das previsões positivas, quantas são realmente positivas.
- Recall (Sensibilidade): De todas as instâncias positivas reais, quantas foram corretamente previstas como positivas.
- F1-Score: Média harmônica de Precision e Recall.
- Matriz de Confusão: Visualiza o número de verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos.

- Para Regressão:
- Erro Médio Absoluto (MAE)
- Erro Quadrático Médio (MSE)
- Raiz do Erro Quadrático Médio (RMSE)
- R-squared (Coeficiente de Determinação)
- Validação Cruzada (Opcional, mas recomendado para efetuar uma avaliação mais robusta da performance do algoritmo): Para uma avaliação mais robusta, podemos usar validação cruzada. Ela divide os dados de treinamento em várias partes (folds), treina o modelo em algumas partes e valida em outra, repetindo o processo várias vezes e calculando a média das métricas.
- documentação técnica referente a validação cruzada: (https://scikit-learn.org/stable/modules/cross_validation.html)
- Isso dá uma estimativa mais confiável da performance do modelo em dados não vistos.
5. Deploy (Deployment)
A fase final é colocar o modelo em produção para que ele possa ser usado para fazer previsões em dados reais.
- Integração em um Sistema: O modelo treinado precisa ser integrado em um sistema ou aplicação para ser utilizado. Isso pode ser:
- API (Application Programming Interface): Criar uma API que recebe dados como entrada e retorna a previsão do modelo como saída. Essa API pode ser consumida por outras aplicações web, mobile, etc.
- Incorporação em um Aplicativo Existente: Integrar o modelo diretamente em um aplicativo já existente.
- Batch Processing: Executar o modelo periodicamente para processar um grande volume de dados (ex: previsões de churn de clientes mensalmente).
- Monitoramento do Modelo: Após o deploy, é importante monitorar a performance do modelo em produção. A performance do algoritmo pode se degradar ao longo do tempo devido a mudanças nos dados (drift de dados). É necessário monitorar métricas de performance e retreinar o modelo periodicamente com dados mais recentes, se necessário.
- Exemplo Conceitual de Deploy: Imagine que você criou um modelo de Árvore de Decisão para prever se um email é spam ou não. No deploy, você pode criar um serviço web que recebe o texto de um email como entrada, usa o modelo treinado para classificar o email como "spam" ou "não spam" e retorna essa classificação.
Bibliotecas e frameworks do Python
Pandas: Biblioteca voltada para a manipulação e análise de dados
Matplotlib: para criação de gráficos e visualizações de dados em geral, feita para a linguagem de programação Python e é uma extensão da biblioteca de matemática NumPy.
Numpy: é uma biblioteca para a linguagem de programação Python, que suporta o processamento de grandes, multidimensionais arranjos e matrizes, juntamente com uma grande coleção de funções matemáticas de alto nível para operar sobre estas matrizes
Scipy: é uma biblioteca Open Source em linguagem Python que foi feita para matemáticos, cientistas e engenheiros. Também tem o nome de uma popular conferência de programação científica com Python. A sua biblioteca central é NumPy que fornece uma manipulação conveniente e rápida de um array N-dimensional
OpenCV: é totalmente livre ao uso acadêmico e comercial, para o desenvolvimento de aplicativos na área de Visão computacional e além disso é uma biblioteca que já tem inteligência artificial dentro dela, com ela você consegue facilmente detectar a face das pessoas com poucas linhas de código
Scikit-Learn: Esta biblioteca dispõe de ferramentas simples e eficientes para análise preditiva de dados, é reutilizável em diferentes situações, possui código aberto, sendo acessível a todos e foi construída sobre os pacotes NumPy, SciPy e Matplotlib
Keras: é uma biblioteca de rede neural de código aberto escrita em Python. Ele é capaz de rodar em cima de TensorFlow e Pytorch
Tensor Flow: é uma biblioteca de código aberto criada para aprendizado de máquina, computação numérica e muitas outras tarefas. Foi desenvolvido pelo Google em 2015 e rapidamente se tornou uma das principais ferramentas para machine learning e deep learning.
PyTorch é um framework de aprendizagem profunda de código aberto baseada em software, usada para construir redes neurais, combinando a biblioteca de aprendizado de máquina da Torch com uma API de alto nível baseada em Python. Sua flexibilidade e facilidade de uso, entre outros benefícios, a tornaram a estrutura líder de ML para comunidades acadêmicas e de pesquisa
Transformers: é uma é uma biblioteca de texto pré-treinado, visão computacional, áudio, vídeo e modelos multimodais para inferência e treinamento. Ajuda demais voce a recriar os seus próprios projetos com modelos já prontos, basta adaptar ao seu caso de uso e necessidades do seu projeto.
…… Essas são as principais bibliotecas e frameworks de machine learning do Python
https://www.tensorflow.org/?hl=pt-br
Aplicações de Machine Learning no nosso dia-a-dia
Machine learning
Aplicações com base em modelos de aprendizado lineares
- Regressão Linear
Com ele você consegue efetuar:
Previsão do preço das ações, Previsão do preço da habitação, Previsão do valor da vida útil do cliente
- Regressão logística: Previsão de pontuação de risco de crédito ( muito usado em sistemas bancários) Previsão de rotatividade de clientes
- Regressão Ridge : Estimativa para se efetuar a manutenção preditiva em equipamentos ou máquinas, estimativa de previsão de receita de vendas de automóveis
- Regressão de Lasso: Estimativa da previsão do preço da habitação previsão de resultados clínicos com base em dados de saúde
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
Aplicações com base em modelos de aprendizado de árvore de decisão
Árvore de decisão: Predição de rotatividade de clientes, Modelo ideal para a estimativa de pontuação de crédito, Cálculo de predição de doenças
Floresta randômica: Modelo de pontuação de crédito, efetua a previsão de preços de habitação
Regressão de aumento de gradiente: Cálculo da previsão de emissões de carros, previsão do valor da tarifa de carona
XG Boost: Cálculo da previsão de Churn (cancelamento de assinatura) Processamento de sinistros em seguros
Regressor Light GBM: Previsão do tempo de voo para a companhia aérea Previsão dos níveis de colesterol com base em dados de saúde
Aplicações com base em modelos de aprendizado de clusterização
Algoritmo K-Means: Pode ser usado para efetuar Segmentação de clientes e para Sistemas de recomendação
Agrupamento hierárquico: Detecção de fraude e Agrupamento de documentos com base na semelhança
Modelos de Mistura Gaussiana scikit: Pode ser usado para efetuar Segmentação de clientes e para Sistemas de recomendação
Aplicações com base na Associação
Algoritmo Apriori documentação : Colocações de produtos, Mecanismos de recomendação, Otimização de promoção
Deep Learning:
PLN (processamento de linguagem natural)
Os sistemas de NLP permitem que a tecnologia usada não apenas entenda o significado literal de cada palavra que está sendo dita, como também considere aspectos como:
🡪 Contexto da conversa;
🡪 Significados sintáticos e semânticos;
🡪 Interprete os textos;
🡪 Análise sentimentos e mais.
Redes neurais de classificação para economia de pesticidas e para evitar devastação ambiental em áreas agrícolas (chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/ALGORITMO DE DEEP LEARNING PARA CLASSIFICAÇÃO DE ÁREAS DE LAVOURA COM VANTS
)
Redes neurais de classificação e detecção que veículos autônomos utilizam para ver o trânsito e poderem efetuar o deslocamento do veículo (Análise e fusão de imagens 2D e 3D com vistas para detecção e classificação de sinais…)
Detecção e classificação de pneumonia por meio de radiografias de tórax (chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://rosario.ufma.br/jspui/bitstream/123456789/3508/1/GABRIEL-SOUSA.pdf)
O que é Hugging Face e o como a biblioteca Transformers se relacionam
É uma empresa que nasceu como uma Startup e graças ao investimento de grandes empresas como Google, Microsoft e AWS se tornou uma comunidade colaborativa que reúne milhares de códigos de IA, com o objetivo de democratizar o desenvolvimento de IA para que qualquer pessoa possa experimentar e aprender.
E a biblioteca Transformers democratiza o acesso a modelos complexos de IA, permitindo que desenvolvedores e pesquisadores os utilizem com poucas linhas de código, sem a necessidade de treinar esses modelos do zero (o que exigiria enormes quantidades de dados e poder computacional).
Exemplo prático de código usando processamento de linguagem natural treinado para análise de sentimentos (modelo usado: tbluhm/clf-sentimentos-cmts)
tbluhm/clf-sentimentos-cmts · Hugging Face
modelo chamado tbluhm/clf-sentimentos-cmts no Hugging Face, que foi treinado para classificação de sentimentos em textos em português do Brasil. Ele é baseado na arquitetura XLM-RoBERTa e pode interpretar até mesmo emojis para determinar se um comentário é positivo, negativo ou neutro.
Abaixo está o código para voce testar no Google Colab:
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("text-classification", model="tbluhm/clf-sentimentos-cmts")
# Load model directly
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("tbluhm/clf-sentimentos-cmts")
model = AutoModelForSequenceClassification.from_pretrained("tbluhm/clf-sentimentos-cmts")
A seguir usei uma mensagem apenas para testar o modelo:
from transformers import pipeline
# Criar pipeline de análise de sentimentos
sentiment_analysis = pipeline("sentiment-analysis", model="tbluhm/clf-sentimentos-cmts")
# Mensagem a ser analisada
texto = "Inteligência define o trabalho feito por eles! PARABÉNS! Saude, Sucesso e Progresso!"
# Testar a análise de sentimentos
resultado = sentiment_analysis(texto)
# Exibir o resultado
print(resultado)
Device set to use cpu
[{'label': 'neutral', 'score': 0.7209280729293823}]
o resultado foi o seguinte:
o modelo detectou aproximadamente 72% de sentimento neutro
Quais são os benefícios de usar esse modelo?
- Identificação de Sentimento: A principal função do modelo é classificar o sentimento em textos curtos como positivo, negativo ou neutro. Isso pode ajudar a ter uma visão geral das opiniões expressas nos comentários de vídeos e posts de blogs.
- Português do Brasil: O modelo foi especificamente treinado em português do Brasil, o que o torna mais adequado para analisar comentários e textos neste idioma do que modelos genéricos.
- Interpretação de Emojis: A documentação técnica do modelo menciona que ele inclui a interpretação de emojis, o que é crucial para entender o sentimento em comentários online, onde emojis são frequentemente usados para expressar emoções.
- Automatização: O uso de um modelo como este permite automatizar parcialmente o processo de análise de sentimentos, economizando tempo e esforço em comparação com a leitura e classificação manual de cada comentário.
- Visão Geral Rápida: Ao agregar os resultados da análise de sentimento de muitos comentários, o produtor de conteúdo pode obter rapidamente uma visão geral da polaridade das opiniões (predominantemente positivas, negativas ou neutras).
Considerações e Limitações:
- Contexto e Nuances: Análise de sentimento automática nem sempre captura o contexto completo e as nuances da linguagem humana, como sarcasmo, ironia ou opiniões complexas expressas em várias frases. O modelo pode classificar erroneamente um comentário sarcástico como positivo, por exemplo.
- Textos Longos: O modelo foi treinado em textos curtos. A aplicação direta em textos muito longos, como posts de blogs inteiros, pode não ser ideal. Nesses casos, pode ser necessário dividir o texto em partes menores (parágrafos, comentários) para análise.
- Opiniões Mistas: Comentários ou textos que expressam opiniões mistas (parte positiva, parte negativa) podem ser difíceis de classificar em uma única categoria. O modelo fornecerá uma probabilidade para cada categoria, mas a interpretação pode exigir mais cuidado.
- Moderação de Conteúdo: Embora o modelo possa ajudar a identificar comentários negativos, a decisão final sobre moderação (remover, responder) ainda exigirá intervenção humana, pois o contexto e as políticas de cada plataforma são importantes.
- Qualidade dos Dados de Treinamento: A precisão do modelo depende da qualidade e da representatividade dos dados nos quais foi treinado. É importante estar ciente de que o modelo pode ter vieses e não ser perfeito em todas as situações.
- Necessidade de Adaptação: Dependendo do tipo de conteúdo e do público, pode ser útil ajustar ou complementar a análise do modelo com outras técnicas ou análises qualitativas.
De forma prática você pode usar para produção de conteúdo, porém sempre analise os resultados do modelo se são coerentes.
Como voce pode explorar por voce mesmo e aprender mais sobre python e IA?
Pesquise os modelos disponiveis no hugging Face, use as IAs generativas para que elas te explicam os requisitos técnicos de cada modelo, (esse modelo que testei funciona em qualquer computador, pois é um modelo simples), explora os artigos aqui na comunidade da DIO, leia livros a respeito de Python e IA. E principalmente teste bastante, use o Google Colab para experimentar os modelos, pois ele já pré-configurado com as todas as dependencias técnicas da linguagem python.
Fontes consultadas:
https://didatica.tech/o-que-e-tensorflow-para-que-serve/
https://www.ibm.com/br-pt/topics/pytorch
https://www.datacamp.com/pt/cheat-sheet/machine-learning-cheat-sheet
Análise e fusão de imagens 2D e 3D com vistas para detecção e classificação de sinais...
Deep Learning para a Detecção e Classificação de Pneumonia por Radiografias do Tórax
https://larcc.setrem.com.br/wp-content/uploads/2020/11/SAPS_2020_Anthony.pdf
Processamento de Linguagem Natural
Processamento de Linguagem Natural Fl %aVIa de AlmeIda Barros Jacques RobIn UFPE
O que é a Hugging Face e sua importância na inteligência artificial






Excelente artigo, Maria! Você fez um trabalho muito completo e didático ao explorar as diversas aplicações de Python no desenvolvimento de sistemas inteligentes com IA. A forma como você estruturou o conteúdo é clara e acessível para diferentes níveis de público.
Gostei especialmente do detalhamento das etapas de um projeto de machine learning, incluindo preparação, treinamento, validação e deploy, além da explicação das diferenças entre aprendizado supervisionado e não supervisionado. O destaque para bibliotecas essenciais como TensorFlow, PyTorch, Scikit-learn, OpenCV, Hugging Face e Transformers mostra o quão rico e poderoso é o ecossistema Python para IA.
Qual foi o maior desafio que você enfrentou ao integrar diferentes bibliotecas em seus projetos?