


IA Generativa: o que é um LLM e como funciona (sem enrolação)
A revolução da IA que entende e cria
Nos últimos anos, a Inteligência Artificial Generativa virou o assunto favorito de todo mundo que respira tecnologia.
Modelos como o GPT-5, Claude, Gemini e Mistral já escrevem textos, resolvem códigos, resumem relatórios e até criam piadas melhores que muito humano.
Mas, antes de mergulhar de cabeça nessa onda, vale a pergunta: você realmente entende o que é um LLM e como ele funciona?
A verdade é que muita gente trata esses modelos como uma “caixa preta mágica”. Isso é perigoso — tanto para quem desenvolve soluções, quanto para quem toma decisões baseadas nelas.
Hoje, a ideia é desmistificar o LLM de forma clara, humana e prática. Vamos entender o que acontece por trás do “gerar texto”, quais são os trade-offs reais (custo, latência, privacidade) e como usar essas ferramentas de forma inteligente.
O que é um LLM (Large Language Model)
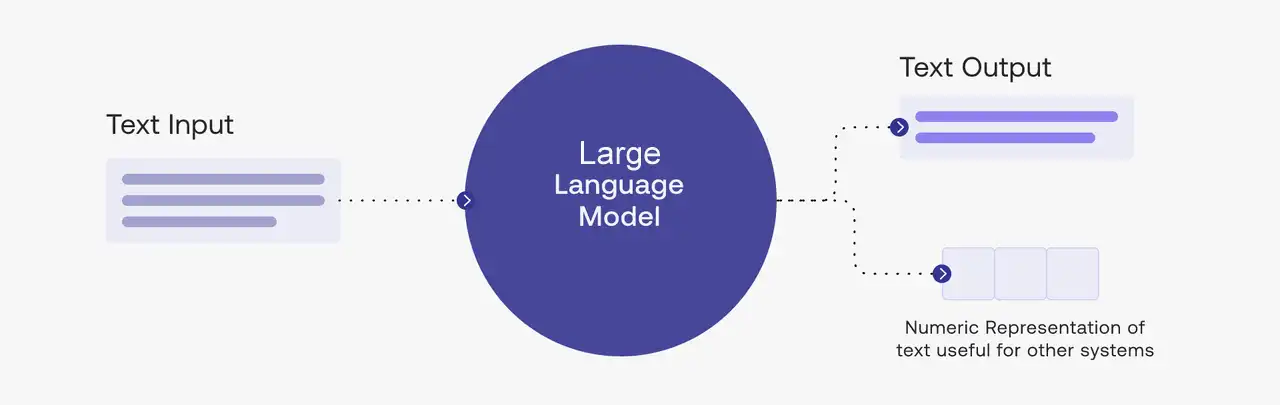
De forma simples, um LLM é uma IA treinada em uma quantidade absurda de textos — livros, artigos, sites, código-fonte — para entender e gerar linguagem humana.
Pense nele como um cérebro digital que aprendeu a prever qual seria a próxima palavra em qualquer frase possível.
Só que esse “cérebro” tem bilhões de conexões neurais e já leu mais do que qualquer pessoa conseguiria ler em mil vidas.
Definição rápida:
LLMs são modelos baseados em transformers — uma arquitetura que usa o mecanismo de self-attention para entender como cada palavra se relaciona com as outras no contexto.
Referências:
- O que é LLM (large language models)?
- O que é um modelo de linguagem ampla (LLM)?
- Wikipedia – LLM (Large Language Model)
Como um LLM realmente funciona
Se a gente “abrisse” um LLM e olhasse o que acontece lá dentro, veria algo como isso:

Vamos traduzir:
1. Tokenização
O texto é quebrado em pequenos pedaços (tokens).
Ex: “IA é incrível” → ["IA", "é", "incrível"]
2. Embeddings
Cada token é transformado em um vetor numérico (representação matemática do significado).
3. Atenção (Attention Mechanism)
O modelo “olha” para todas as palavras ao mesmo tempo e decide quais são mais relevantes para entender o contexto.
4. Previsão
Ele calcula qual é o token mais provável para vir em seguida.
5. Repetição infinita
Repete isso várias vezes, gerando frase por frase até terminar a resposta.
Esse processo é chamado de inference — é o que acontece toda vez que você manda um prompt pro ChatGPT ou outro modelo.
Trade-offs e realidades de bastidor

Nem tudo são flores. Cada LLM tem seus custos, limites e riscos.
Veja o que normalmente está em jogo:
- Custo
- Rodar um LLM — especialmente os grandes — consome muita GPU.
- Mesmo via API, cada token tem um custo. Modelos open source (como Llama 3 ou Mistral 7B) reduzem despesas, mas exigem infraestrutura própria.
- 📚 Leitura recomendada: FrugalGPT – Reduzindo custo sem perder performance
- Latência
- Quanto maior o prompt e o contexto, mais tempo o modelo leva para responder.
- A latência é o preço da inteligência: mais contexto, mais poder de processamento.
- Privacidade
- Enviar dados sensíveis para modelos hospedados na nuvem pode ser um risco.
- Por isso, empresas estão apostando em LLMs privados ou híbridos, que rodam internamente.
- Precisão e confiabilidade
- Nem tudo que o modelo “fala” é verdade.
- Esses deslizes são as famosas alucinações — respostas inventadas que soam corretas.
Mão na massa – Como usar um LLM (na prática!)
Vamos ver o LLM funcionando na vida real, sem complicação.
1️⃣ Defina o objetivo
Quer gerar texto, traduzir, resumir ou responder perguntas?
Isso muda completamente o tipo de prompt e o modelo ideal.
2️⃣ Escolha o modelo
- GPT-4 / GPT-5 → ótimo para generalistas, multimodais e agentes.
- Claude 3 → forte em raciocínio e leitura de PDFs.
- Mistral 7B → ideal para quem quer rodar localmente.
- Llama 3 → bom equilíbrio entre custo e desempenho.
3️⃣ Crie o prompt certo
Prompt é o “briefing” que você dá pra IA.
Um prompt ruim é como mandar um estagiário fazer algo sem contexto. 😅
Exemplo de prompt ruim:
“Resuma esse texto.”
Exemplo de prompt bom:
“Você é um editor especializado. Resuma o texto abaixo em até 100 palavras, mantendo os principais dados numéricos e conclusões.”
Engenharia de Prompt: o tempero secreto
A engenharia de prompt é a arte de conversar com a IA de forma estratégica.
Você não precisa de sorte, e sim de método.
Aqui vão os estilos de prompt que realmente funcionam:
1. Chain of Thought (CoT)
Peça para o modelo “pensar alto”.
Explique passo a passo seu raciocínio antes de responder.
Pergunta: Quantas horas há em 3 dias?
2. ReAct (Reason + Act)
Combine raciocínio com ações (ex: buscar dados, decidir e executar).
Esse padrão é usado em agentes autônomos.
3. Few-Shot Prompting
Dê exemplos de entrada/saída para o modelo aprender o formato desejado.
Entrada: “Oi!” → Saída: “Olá! Como posso ajudar?”
Entrada: “Bom dia” → Saída: “Bom dia! Tudo bem por aí?”
4. Instruções de restrição
Diga o que ele não deve fazer:
“Se não souber a resposta, diga ‘não sei’.”
Essas técnicas reduzem erros e aumentam a precisão.
Como medir se o LLM está mandando bem

Para não depender só da “intuição”, meça desempenho:
- Latência: quanto tempo leva pra responder.
- Acurácia: se a resposta realmente está correta.
- Coerência: se mantém o contexto.
- Custo por uso: tokens de entrada + saída.
- Taxa de alucinação: quantas respostas incorretas surgem.
Dica: registre métricas em planilhas ou dashboards (ex: LangSmith, PromptLayer, Weights & Biases).
Quando usar (ou não usar) um LLM genérico
✅ Use LLMs para:
- Chatbots, assistentes internos, resumos, geração de conteúdo, ideação de produtos.
- Tarefas criativas, automação de atendimento, suporte técnico.
🚫 Evite LLMs puros quando:
- Lida com dados ultra-sensíveis (jurídico, médico, financeiro).
- Precisa de precisão de 100%.
- O custo de erro é alto.
Nesses casos, combine o modelo com RAG (Retrieval-Augmented Generation) ou fine-tuning específico.
O futuro dos LLMs
O próximo passo da IA generativa está na especialização e integração.
Modelos menores, rápidos e especializados vão dominar, conectados a bases de dados via RAG.
Além disso, o foco agora é avaliar IAs com critérios éticos, sustentáveis e interpretáveis.
Algumas tendências quentes pra ficar de olho:
- LLMs multimodais: texto + imagem + áudio.
- LLMs locais (on-device): privacidade e zero latência.
- Fine-tuning com dados sintéticos: treinar modelos sem violar direitos autorais.
- Avaliação automática de prompts: medir qualidade em tempo real.
Fonte:
Conclusão – O poder está no entendimento
A IA generativa é incrível, mas só entrega valor real quando você entende como e por que ela funciona.
O LLM é o motor — mas quem dirige é você.
Entender as engrenagens (tokenização, embeddings, atenção, prompts) é o primeiro passo pra criar soluções mais seguras, criativas e acessíveis.
E o melhor: com as ferramentas certas, qualquer pessoa curiosa pode começar agora.
Bora praticar?
- 1️⃣ Pegue um LLM (ChatGPT, Claude, Llama 3, Mistral).
- 2️⃣ Crie dois prompts diferentes para a mesma tarefa.
- 3️⃣ Compare as respostas — tempo, qualidade, custo.
Poste seu resultado e marque a hashtag #PromptChallenge
Curtiu o artigo?
💭 Deixe seu comentário,
📢 compartilhe com aquele amigo que vive testando IA.







