


Quem vigia os vigilantes do Machine Learning?
- #Machine Learning
Série: Construindo uma Machine Learning Trust Platform (1/8)
Nos últimos anos, Machine Learning saiu dos laboratórios acadêmicos e foi direto para o coração das decisões de negócios.
Hoje modelos definem:
- aprovação de crédito
- detecção de fraude
- risco de seguros
- diagnósticos médicos
- previsão de demanda
- operações financeiras
Mas uma pergunta incômoda raramente é feita:
Quem verifica se os resultados desses modelos realmente fazem sentido?
_____________________________________________________________________________________________________________________________________________________
O paradoxo do Machine Learning moderno
Ferramentas modernas tornaram o Machine Learning incrivelmente acessível.
Hoje é possível treinar modelos com apenas alguns cliques ou poucas linhas de código usando bibliotecas e plataformas populares como:
- Scikit-learn
- H2O AutoML
- AutoGluon
- DataRobot
- Azure Machine Learning
- Amazon SageMaker AutoML
Essas ferramentas são poderosas e representam um enorme avanço na democratização da ciência de dados.
Mas existe um paradoxo curioso.
Quanto mais automatizado o Machine Learning se torna, menos visível fica o que realmente está acontecendo dentro do pipeline.
Na prática, muitas dessas soluções funcionam como caixas-pretas operacionais.
O usuário recebe:
- métricas de performance
- gráficos de avaliação
- rankings de modelos
- previsões prontas para uso
Mas raramente vê de forma clara:
- quais algoritmos foram realmente treinados
- quais transformações foram aplicadas no dataset
- como variáveis categóricas foram codificadas
- se houve tratamento de outliers
- se houve risco de data leakage
- se houve multicolinearidade relevante
- se a métrica exibida corresponde exatamente ao gráfico apresentado
Em muitos casos, o pipeline executa dezenas de etapas automaticamente:
- cleaning
- encoding
- scaling
- feature engineering
- model selection
- cross-validation
- ensembling
- threshold optimization
Mas o usuário final vê apenas o resultado final. Isso cria um efeito curioso: o modelo parece extremamente sofisticado, mas a visibilidade metodológica diminui.
Para quem trabalha com ciência de dados no dia a dia, isso levanta uma pergunta importante:
“até que ponto estamos avaliando o modelo… ou apenas confiando na ferramenta que o produziu? “
O problema não é a automação.
A automação é essencial para escalar Machine Learning.
O verdadeiro desafio é garantir que a automação não esconda a integridade científica do experimento.
Porque métricas altas, por si só, não garantem que o processo que levou até elas estejam metodologicamente correto.
_____________________________________________________________________________________________________________________________________________________
Em outras palavras: estamos ficando muito bons em treinar modelos, mas ainda estamos aprendendo a auditar experimentos de Machine Learning.
_____________________________________________________________________________________________________________________________________________________
Um exemplo simples (e assustador)
Imagine um modelo com:
AUC = 0.87
Isso parece excelente.
Mas se o gráfico ROC estiver sendo calculado com a probabilidade da classe errada, o valor real pode ser:
AUC ≈ 0.43
Ou seja:
o modelo parece ótimo quando na verdade é pior que um classificador aleatório.
E isso pode acontecer sem nenhum erro visível no pipeline.
_____________________________________________________________________________________________________________
O problema estrutural
Grande parte do ecossistema de ML foi construída para otimizar performance, não necessariamente para auditar consistência científica.
Isso cria um risco silencioso:
modelos são avaliados com base em resultados que poucas pessoas verificam profundamente.
Em outras palavras:
quem vigia os vigilantes?
_____________________________________________________________________________________________________________
Talvez este seja o próximo grande passo do Machine Learning aplicado
Durante muito tempo, o foco do Machine Learning foi claro:
- treinar modelos cada vez melhores.
- mais dados. Mais algoritmos. Mais poder computacional.
E isso nos trouxe até aqui.
Hoje conseguimos treinar modelos sofisticados em minutos, algo que há poucos anos exigia equipes inteiras de engenharia e infraestrutura complexa.
Mas à medida que o Machine Learning começa a influenciar decisões críticas — financeiras, operacionais e até médicas — surge uma nova pergunta:
não deveríamos também evoluir na forma como verificamos esses experimentos?
Talvez o próximo salto de maturidade do Machine Learning não esteja apenas em modelos mais complexos.
Talvez esteja em algo mais fundamental:
garantir que os resultados produzidos por esses modelos sejam metodologicamente confiáveis.
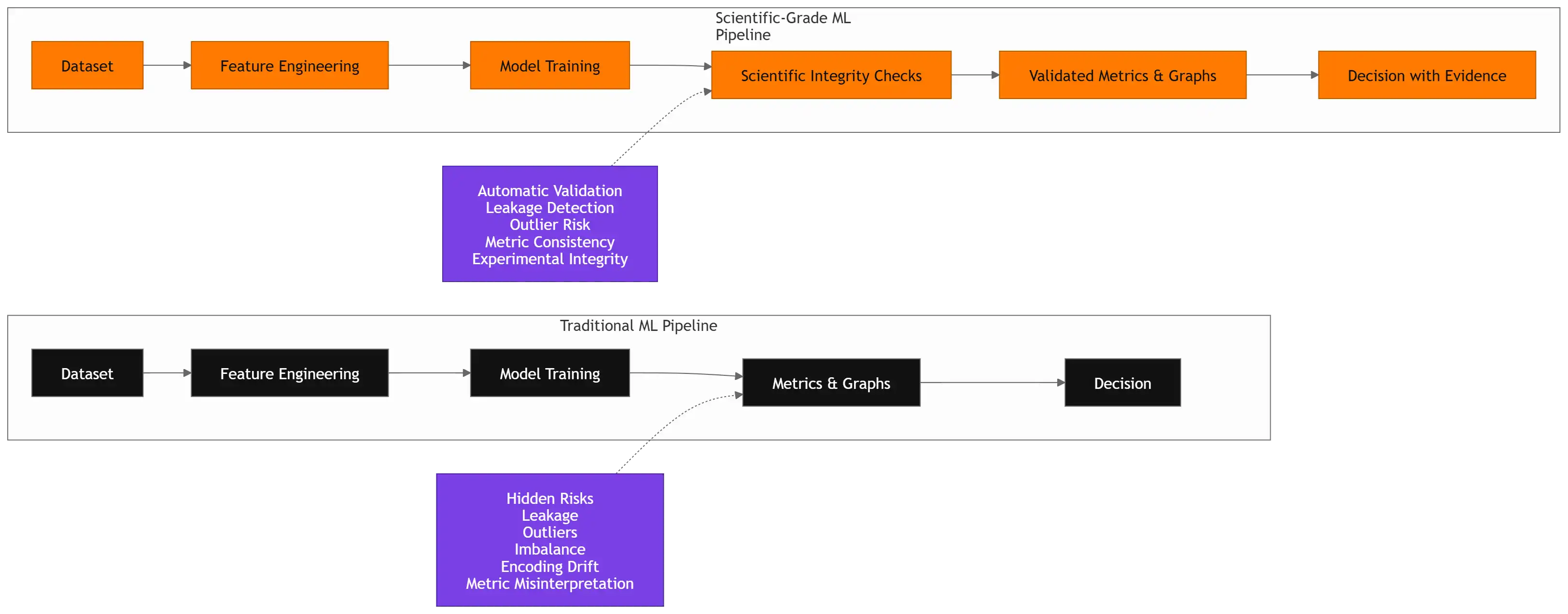
Comparativo entre fluxo de ML tradicional x proposta de pipeline de ML de nível científico
Isso significa olhar além das métricas e perguntar:
- o experimento é consistente?
- as métricas correspondem aos gráficos apresentados?
- existe risco de data leakage?
- existem outliers distorcendo o modelo?
- o pipeline de transformação é transparente?
- os resultados podem ser reproduzidos?
Essas perguntas são comuns no meio acadêmico.
Mas no ambiente corporativo, muitas vezes ficam em segundo plano.
E talvez não devam.
Porque no final do dia, decisões importantes estão sendo tomadas com base nesses modelos.
_____________________________________________________________________________________________________________
Uma provocação final
Talvez a pergunta mais importante para o futuro do Machine Learning não seja:
“Qual modelo performa melhor?”
Talvez seja:
“Podemos confiar que esse experimento está correto?”
Essa é uma questão que tenho explorado a fundo num projeto atual.
E tenho a sensação de que, nos próximos anos, ferramentas capazes de auditar a integridade científica de experimentos de Machine Learning podem se tornar tão importantes quanto as ferramentas que os treinam.
Mas uma coisa parece clara:
“Talvez o futuro do ML não seja apenas treinar modelos melhores. Talvez seja confiar melhor nos resultados que eles produzem.”




