

RAG: A Revolução Acessível na Recuperação de Informações com IA Generativa
- #IA Generativa
🧾Introdução
Você já se perguntou como fazer uma IA responder perguntas específicas sobre seus próprios dados sem precisar retreinar modelos bilionários ou gastar com APIs caras? RAG (Retrieval-Augmented Generation) é a resposta: uma arquitetura que combina o poder dos LLMs com a precisão da busca semântica, e o melhor — você pode implementar tudo isso gratuitamente usando ferramentas open-source e, o mais importante, totalmente fora da internet, garantindo segurança e privacidade dos seus dados.
Imagine poder analisar documentos confidenciais com o auxílio e a inteligência da IA, sem expor informações sensíveis a serviços externos. Já pensou em ter um assistente de suporte disponível 24 horas, capaz de compreender, buscar e responder sobre todos os processos, procedimentos e normativas da sua empresa?
Neste artigo, você vai aprender exatamente como o RAG funciona, quando usar essa técnica, e como implementar um pipeline completo usando apenas tecnologias gratuitas.
Prepare-se para transformar bases de conhecimento estáticas em assistentes inteligentes, seguros, privados e totalmente sob seu controle.
🎯 Neste artigo, você vai aprender:
- O que é RAG e por que ele importa
- Como montar um pipeline completo com ferramentas open-source
- Técnicas avançadas (HyDE, reranking, caching)
- Métricas de avaliação e otimização de performance
⛓️💥O Problema: Limitações dos LLMs Tradicionais
Os Large Language Models (LLMs) como GPT, Gemini, Claude, Llama, Mistral, Gemma entre outros possuem conhecimento vasto, mas enfrentam três desafios críticos:
1. Knowledge Cutoff:
- Modelos são treinados até uma data específica e não sabem sobre eventos posteriores.
- Neste ponto, você se depara com aquela tecnologia ou documentação que acabou de sair e não consegue extrair informações consistentes.
2. Alucinações:
- Quando não têm informação precisa, LLMs podem "inventar" respostas que parecem plausíveis mas são incorretas.
- Quem nunca se deparou com a entrega de uma informação que de cara estava errada ou ao validar não era bem daquele jeito, ai você "fala" para a IA "Ei isso aqui não esta certo" e ela concorda com você. 😅
3. Dados Proprietários:
- Modelos públicos não têm acesso a documentos internos, políticas empresariais ou bases de conhecimento específicas.
- Segundo pesquisadores da Meta AI no paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks", RAG permite que modelos acessem informações externas durante a geração, reduzindo significativamente alucinações e mantendo respostas atualizadas.
🤔O Que É RAG?
Retrieval-Augmented Generation é uma arquitetura que aumenta as capacidades de LLMs integrando um sistema de recuperação de informações. Em vez de depender apenas do conhecimento parametrizado do modelo, RAG busca documentos relevantes em tempo real e os injeta como contexto na prompt.
Como Funciona o Pipeline RAG
O pipeline RAG pode ser dividido em duas fases principais:
Fase 1: Indexação (Offline)
Aqui preparamos a base de conhecimento para buscas eficientes:
- Documentos → Chunking → Embeddings → Vector Database
Fase 2: Recuperação e Geração (Runtime)
Quando o usuário faz uma pergunta:
- Query → Embedding → Busca Semântica → Contexto + Prompt → LLM → Resposta
Arquitetura Detalhada: Os 5 Componentes Essenciais
1. Document Loading e Preprocessing
O primeiro passo é ingerir documentos de diversas fontes. Para isso, usaremos bibliotecas Python gratuitas como PyPDF2 para PDFs, mas também podemos utilizar python-docx para Word, e Beautiful Soup para HTML.
Boas práticas:
- Remova headers, footers e elementos não informativos
- Normalize formatação e encoding
- Preserve metadados importantes (autor, data, fonte)
2. Chunking: A Arte de Dividir Conhecimento
Chunking é o processo de dividir documentos em pedaços menores. Por que? LLMs têm limite de contexto, e chunks menores melhoram a precisão da busca.
Estratégias de chunking:
- Fixed-size chunking: Divide texto em blocos de tamanho fixo (ex: 500 palavras) com overlap de 10-20%.
- Sentence-based chunking: Usa bibliotecas como NLTK ou spaCy para respeitar limites de sentenças.
- Recursive chunking: Divide hierarquicamente por parágrafos, depois sentenças, até atingir tamanho ideal.
Como regra prática: Chunks entre 300-1000 palavras funcionam bem na maioria dos casos. Overlap de 50-100 palavras evita perda de contexto nas bordas.
3. Embeddings: Transformando Texto em Vetores
Embeddings são representações numéricas que capturam o significado semântico do texto. Usaremos Sentence Transformers, uma biblioteca open-source que oferece modelos de embedding de alta qualidade completamente gratuitos.
Modelos recomendados (todos gratuitos):
- 'all-MiniLM-L6-v2': 384 dimensões, rápido, ótimo para começar
- 'all-mpnet-base-v2': 768 dimensões, mais preciso
- 'intfloat/e5-large-v2': Apresenta o melhor desempenho em português/multilíngue
- 'neuralmind/bert-base-portuguese-cased': Especializado em português
Antes de ver o código, é importante entender o que são embeddings.
Eles são representações numéricas (vetores) que capturam o significado semântico de palavras, frases ou documentos.
Assim, dois textos com significados semelhantes terão vetores próximos no espaço vetorial.
Exemplo prático:
Módulo Python:
pip3 install sentence_transformers
Código Python:
from sentence_transformers import SentenceTransformer
# Carregar modelo (download automático na primeira vez)
model = SentenceTransformer('all-MiniLM-L6-v2')
# Gerar embedding
chunk = "RAG combina recuperação e geração para respostas precisas"
vector = model.encode(chunk)
print(f"Dimensões: {len(vector)}") # 384 dimensões
print(f"Primeiros valores: {vector[:5]}")

Atenção - Dica crítica:
- Use o MESMO modelo de embedding para indexação e query. Modelos diferentes produzem espaços vetoriais incompatíveis.
4. Vector Database: O Cérebro da Busca Semântica
Vector databases armazenam embeddings e permitem busca por similaridade usando métricas como cosseno ou produto escalar.
Opções 100% gratuitas e open-source:
- Escrito em Rust, performático, pode rodar em memória ou persistir dados
- Simples, Python-native, ideal para começar
- Escalável, usado em produção por grandes empresas
FAISS (Facebook):
- Biblioteca de busca vetorial extremamente rápida
Exemplo com Qdrant:
Módulo Python:
pip3 install qdrant_client
Código Python:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
# Rodar em memória (desenvolvimento) ou persistir em disco
client = QdrantClient(path="./qdrant_data") # ou ":memory:" para RAM
# Criar coleção
client.create_collection(
collection_name="knowledge_base",
vectors_config=VectorParams(
size=384, # all-MiniLM-L6-v2
distance=Distance.COSINE
)
)
# Defina as variáveis
embedding_vector = [0.1] * 384 # vetor de 384 floats simulando o embedding
chunk_text = "Exemplo de conteúdo para teste"
# Inserir chunks
points = [
PointStruct(
id=1,
vector=embedding_vector,
payload={"text": chunk_text, "source": "C:\\temp\\doc.pdf", "page": 1}
)
]
client.upsert(collection_name="knowledge_base", points=points)
client.close()
Exemplo com Chroma (ainda mais simples):
Módulo Python:
pip3 install chromadb
Código Python:
import chromadb
# Inicializar um cliente Chroma em memória (RAM) por padrão
client = chromadb.Client()
collection = client.create_collection(name="knowledge_base")
# Adicionar documentos (embeddings automáticos!)
collection.add(
documents=["Texto do chunk 1", "Texto do chunk 2"],
metadatas=[{"source": "C:\\temp\\doc1.pdf"}, {"source": "C:\\temp\\doc2.pdf"}],
ids=["id1", "id2"]
)
# Buscar
results = collection.query(
query_texts=["minha pergunta"],
n_results=3
)
# Exibindo o resultado
print(results)

5. Retrieval e Generation: Fechando o Ciclo
Quando o usuário faz uma pergunta:
- Converta a query em embedding
- Busque os top-k chunks mais similares (geralmente k=3-5)
- Monte uma prompt estruturada com os chunks recuperados
- Envie ao LLM local para geração da resposta final
LLMs Open-Source Gratuitos:
- Llama 3.2/3.1 (Meta): Excelente qualidade, uso comercial permitido
- Mistral 7B: Rápido e eficiente
- Gemma 2 (Google): Otimizado para hardware modesto
- Phi-3 (Microsoft): Compacto mas poderoso
Rodando LLMs localmente com Ollama:
Instalar Ollama (Linux/Mac/Windows)
Modelos Ollama
Instalando um modelo via terminal
# Baixar modelos pelo terminal (exemplos)
ollama pull llama3.2 # 3B - rápido
ollama pull mistral # 7B - balanceado
ollama pull llama3.1:8b # 8B - qualidade++
Prompt engineering para RAG:
Abaixo um modelo estruturado em python seguindo boas praticas de engenharia de prompt, lembre que um bom prompt ajuda a evitar delírios na resposta
Papel que será assumido para entrega da resposta:
- Você é um assistente técnico preciso e confiável.
Contexto base para resposta:
- Contexto indexado recuperado da base de conhecimento.
Pergunta do Usuário:
- Imput com o pedido do usuário.
Orientações para desenvolvimento da resposta:
INSTRUÇÕES IMPORTANTES:
- Responda APENAS com base no contexto fornecido acima
- Se a informação não estiver no contexto, responda: "Não encontrei essa informação na base de conhecimento disponível"
- Cite trechos relevantes do contexto quando apropriado
- Seja conciso, objetivo e técnico
- Não invente informações além do que está no contexto
Exemplo estruturado em python:
def create_rag_prompt(query, contexts):
context_text = "\n\n---\n\n".join(contexts)
return f"""Você é um assistente técnico preciso e confiável.
CONTEXTO RECUPERADO DA BASE DE CONHECIMENTO:
{context_text}
PERGUNTA DO USUÁRIO:
{query}
INSTRUÇÕES IMPORTANTES:
- Responda APENAS com base no contexto fornecido acima
- Se a informação não estiver no contexto, responda: "Não encontrei essa informação na base de conhecimento disponível"
- Cite trechos relevantes do contexto quando apropriado
- Seja conciso, objetivo e técnico
- Não invente informações além do que está no contexto
RESPOSTA:"""
Quando Usar RAG vs. Fine-Tuning
Muitos se perguntam: devo usar RAG ou fazer fine-tuning do modelo? Aqui está o comparativo:
Use RAG quando:
- Conhecimento muda frequentemente (documentação, políticas, preços)
- Precisa de transparência e rastreamento de fontes
- Tem documentos longos ou bases de conhecimento grandes
- Quer deploy rápido sem retreinamento
- Precisa combinar múltiplas fontes de dados
- Quer atualizar conhecimento sem custos de treino
Use Fine-Tuning quando:
- Precisa mudar o estilo, tom ou formato de resposta
- Quer que o modelo aprenda padrões específicos de comunicação
- Conhecimento é estável, pequeno e bem definido
- Tem recursos computacionais para treinar
- Precisa de respostas muito rápidas (sem retrieval overhead)
Na prática: Muitos sistemas combinam ambos! Fine-tuning para comportamento e estilo, RAG para conhecimento atualizado e específico.
Implementação Completa: Tutorial Prático 100% Gratuito 💵
Mas chega de conversa, que tal pôr em prática tudo o que foi apresentado acima realizando uma prova de conceito?
Com isso podemos praticar o que foi apresentado e fixar melhor os conceitos.
Vamos construir um sistema RAG funcional para documentação técnica usando apenas ferramentas open-source:
Código Python Completo:
# Salve o código abaixo com o nome ragsupport.py ou como desejar
from sentence_transformers import SentenceTransformer
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
# Trabalharemos apenas com arquivos do tipo PDF
import PyPDF2
import ollama
import os
class RAGSystemOpenSource:
def __init__(self, model_name='all-MiniLM-L6-v2', llm_model='llama3.2'):
"""
Inicializa sistema RAG
Args:
model_name: Modelo de embedding do Sentence Transformers
llm_model: Modelo LLM do Ollama
"""
print(f"🚀 Inicializando RAG System...")
# Modelo de embedding gratuito
print(f"📦 Carregando modelo de embedding: {model_name}")
self.embedding_model = SentenceTransformer(model_name)
self.embedding_dim = self.embedding_model.get_sentence_embedding_dimension()
# Vector DB local (gratuito)
print(f"💾 Inicializando Qdrant (vector database)")
self.vector_db = QdrantClient(path="./qdrant_storage")
self.collection_name = "knowledge_base"
self.llm_model = llm_model
# Criar coleção se não existir
try:
self.vector_db.get_collection(self.collection_name)
print(f"✅ Coleção '{self.collection_name}' já existe")
except:
self.vector_db.create_collection(
collection_name=self.collection_name,
vectors_config=VectorParams(
size=self.embedding_dim,
distance=Distance.COSINE
)
)
print(f"✅ Coleção '{self.collection_name}' criada ({self.embedding_dim} dims)")
def chunk_text(self, text, chunk_size=500, overlap=100):
"""
Divide texto em chunks com overlap
Args:
text: Texto para dividir
chunk_size: Tamanho do chunk em palavras
overlap: Quantidade de palavras sobrepostas entre chunks
"""
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = ' '.join(words[i:i + chunk_size])
if len(chunk.strip()) > 50: # Ignorar chunks muito pequenos
chunks.append(chunk)
return chunks
def embed_text(self, text):
"""Gera embedding usando modelo open-source"""
return self.embedding_model.encode(text).tolist()
def index_document(self, file_path, source_name=None):
"""
Indexa documento PDF na vector database
Args:
file_path: Caminho para o arquivo PDF
source_name: Nome da fonte (opcional)
"""
if source_name is None:
source_name = os.path.basename(file_path)
print(f"\n📄 Processando: {source_name}")
# Ler PDF
try:
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
total_pages = len(reader.pages)
for page_num, page in enumerate(reader.pages, 1):
page_text = page.extract_text()
text += f"\n[Página {page_num}]\n{page_text}"
print(f" 📖 Extraindo página {page_num}/{total_pages}", end='\r')
print(f"\n ✅ {total_pages} páginas extraídas")
except Exception as e:
print(f" ❌ Erro ao ler PDF: {e}")
return
# Chunking
print(f" ✂️ Dividindo em chunks...")
chunks = self.chunk_text(text)
print(f" ✅ {len(chunks)} chunks criados")
# Embeddings e indexação
print(f" 🧮 Gerando embeddings e indexando...")
points = []
# Obter o último ID usado
try:
collection_info = self.vector_db.get_collection(self.collection_name)
start_id = collection_info.points_count
except:
start_id = 0
for idx, chunk in enumerate(chunks):
embedding = self.embed_text(chunk)
points.append(
PointStruct(
id=start_id + idx,
vector=embedding,
payload={
"text": chunk,
"source": source_name,
"chunk_id": idx
}
)
)
# Inserir em lotes de 100
if len(points) >= 100:
self.vector_db.upsert(
collection_name=self.collection_name,
points=points
)
points = []
print(f" 💾 {idx + 1}/{len(chunks)} chunks indexados", end='\r')
# Inserir restantes
if points:
self.vector_db.upsert(
collection_name=self.collection_name,
points=points
)
print(f"\n ✅ Documento indexado com sucesso!")
def retrieve(self, query, top_k=3, min_score=0.32): # min_score=x.xx << ajustar o score dos chunks
"""
Busca chunks relevantes para a query
Args:
query: Pergunta do usuário
top_k: Número de chunks a recuperar
min_score: Ajuste de score (0.3 – 0.4 é bom para embeddings do MiniLM)
"""
query_vector = self.embed_text(query)
results = self.vector_db.search(
collection_name=self.collection_name,
query_vector=query_vector,
limit=top_k
)
contexts = []
for hit in results:
if hit.score >= min_score: # <--- só mantém relevantes
contexts.append({
'text': hit.payload["text"],
'source': hit.payload["source"],
'score': hit.score
})
return contexts
def generate_answer(self, query, top_k=3, verbose=True):
"""
Pipeline completo: retrieve + generate
Args:
query: Pergunta do usuário
top_k: Número de chunks a recuperar
verbose: Mostrar processo detalhado
"""
if verbose:
print(f"\n🔍 Buscando informações relevantes...")
# Recuperar contexto
contexts = self.retrieve(query, top_k=top_k)
if not contexts:
return "❌ Nenhum documento foi indexado ainda. Use index_document() primeiro."
if verbose:
print(f"✅ {len(contexts)} chunks recuperados:")
for i, ctx in enumerate(contexts, 1):
print(f" {i}. {ctx['source']} (score: {ctx['score']:.3f})")
# Montar prompt
context_text = "\n\n---\n\n".join([
f"[Fonte: {ctx['source']}]\n{ctx['text']}"
for ctx in contexts
])
# No prompt abaixo você pode trabalhar para melhor atendimento de sua necessidades
prompt = f"""Você é um assistente técnico especializado e confiável.
CONTEXTO RECUPERADO DA BASE DE CONHECIMENTO (com fontes):
{context_text}
PERGUNTA DO USUÁRIO:
{query}
INSTRUÇÕES IMPORTANTES:
- Responda APENAS com base no contexto fornecido acima.
- Sempre que usar informações de um arquivo mencione explicitamente entre parênteses o nome no formato (Fonte: relatorio_2024.pdf).
- Cite APENAS as fontes que contenham informações diretamente utilizadas na resposta.
- Se um documento aparecer no contexto mas não for usado, não o mencione em "Fontes utilizadas".
- Liste as fontes utilizadas ao final sob o título "Fontes utilizadas".
- Se a informação não estiver no contexto, responda: "Não encontrei essa informação na base de conhecimento disponível".
- Seja preciso, objetivo e técnico.
- Não invente informações além do que está no contexto.
RESPOSTA:"""
if verbose:
print(f"\n🤖 Gerando resposta com {self.llm_model}...")
# Gerar resposta com Llama local (100% gratuito)
try:
response = ollama.generate(
model=self.llm_model,
prompt=prompt,
options={
'temperature': 0.1, # Mais determinístico
'top_p': 0.9,
}
)
return response['response']
except Exception as e:
return f"❌ Erro ao gerar resposta: {e}\n\nVerifique se o Ollama está instalado e o modelo '{self.llm_model}' foi baixado com 'ollama pull {self.llm_model}'"
def close(self):
"""Fecha conexões abertas do Qdrant (importante no Windows)"""
try:
if hasattr(self, "vector_db") and self.vector_db is not None:
self.vector_db.close()
print("🧹 Qdrant fechado corretamente.")
except Exception as e:
print(f"⚠️ Aviso ao fechar Qdrant: {e}")
# =============================================================================
# EXEMPLO DE USO
# =============================================================================
if __name__ == "__main__":
# Inicializar sistema RAG
rag = RAGSystemOpenSource(
model_name='all-MiniLM-L6-v2', # Rápido e eficiente
llm_model='llama3.2' # 3B - bom para começar
)
# Indexar documentos
# rag.index_document("manual_tecnico.pdf", source_name="Manual Técnico v2.0")
# rag.index_document("documentacao.pdf", source_name="Documentação API")
# Fazer perguntas
# resposta = rag.generate_answer("Como funciona autenticação OAuth2?")
# print("\n" + "="*80)
# print("RESPOSTA:")
# print("="*80)
# print(resposta)
# Fecha Qdrant antes de encerrar o programa
rag.close()
🚀 Como Usar o Sistema
1. Instalar dependências:
pip3 install sentence-transformers qdrant-client PyPDF2 ollama
2. Instalar e configurar Ollama:**
# Linux
curl -fsSL https://ollama.com/install.sh | sh
# Windows/macOS: baixar em https://ollama.com/download
# Baixar modelo LLM
# Lista de modelos Ollama em: https://ollama.com/models
ollama pull llama3.2 # 3B - rápido (recomendado para começar)
3. Usar o sistema:
Como prova de conceito utilizaremos apenas o modo interativo do Python.
# Rodar em modo interativo (para testar comandos)
python
# Criar instância
from ragsupport import RAGSystemOpenSource
rag = RAGSystemOpenSource()
# Indexar seus documentos
rag.index_document("relatorio_2024.pdf")
rag.index_document("manual_usuario.pdf")
# Fazer perguntas
resposta = rag.generate_answer("Quais foram os principais resultados de 2024?")
print(resposta)
⚙️ Demostração de uso e funcionamento
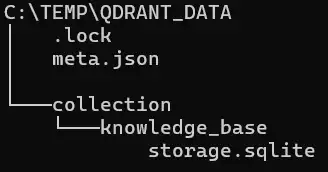
Criando uma instância:
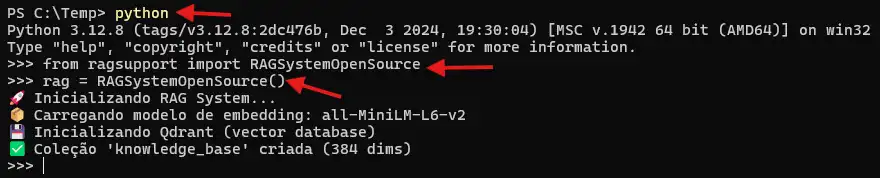
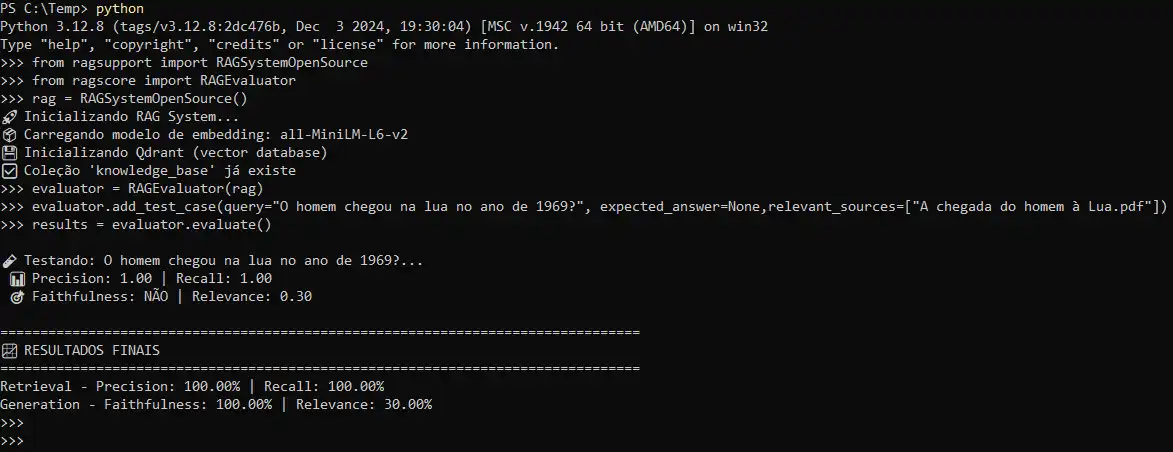
Realizando uma pergunta fora da base de conhecimento (knowledge_base):
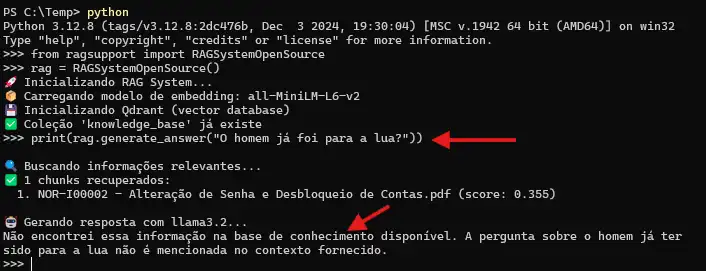
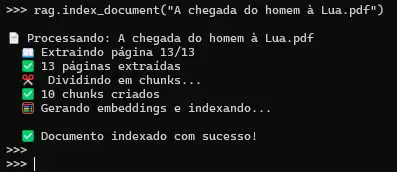
Indexando seus documentos:
Realizando uma pergunta dentro da base de conhecimento (knowledge_base):
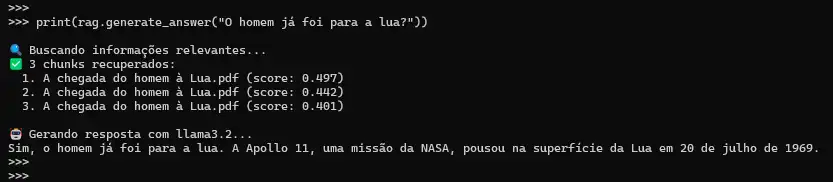
Solicitando um resumo de um documento:
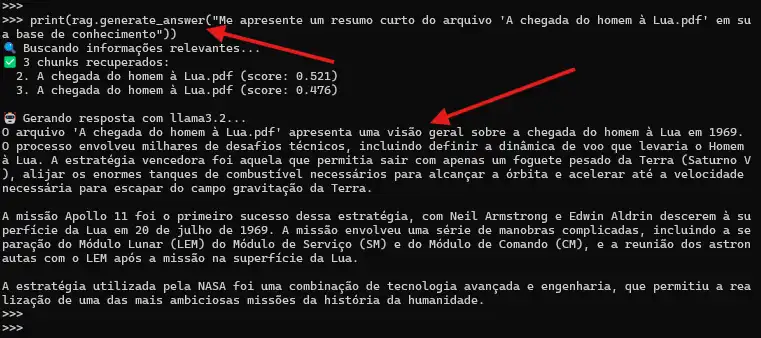
Como modelo o llama3.2 é multi-lingual, podemos pedir o resultado em um idioma especifico de seu conhecimento:
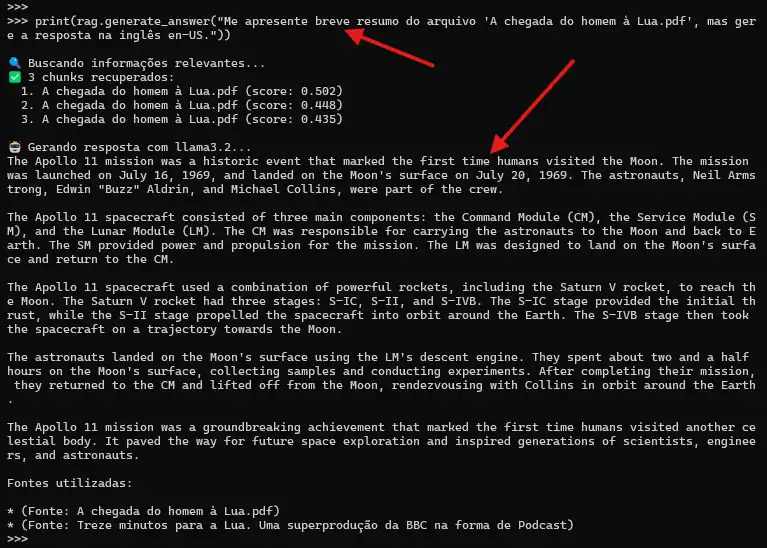
Obs: A menção sobre (Fonte: Treze minutos para a Lua. Uma superprodução da BBC na forma de Podcast) é por já estar na base de treinamento do modelo.
Desafios e Soluções do RAG
Desafio 1: Chunking Ruins Quebram Contexto
- Problema: Dividir um parágrafo importante ao meio perde o significado.
- Solução: Use overlap generoso (100-200 palavras) ou chunking baseado em sentenças:
import nltk
nltk.download('punkt')
def smart_chunk(text, max_words=500, overlap_sentences=2):
sentences = nltk.sent_tokenize(text)
chunks = []
current_chunk = []
word_count = 0
for sentence in sentences:
sentence_words = len(sentence.split())
if word_count + sentence_words > max_words and current_chunk:
chunks.append(' '.join(current_chunk))
# Manter últimas N sentenças como overlap
current_chunk = current_chunk[-overlap_sentences:]
word_count = sum(len(s.split()) for s in current_chunk)
current_chunk.append(sentence)
word_count += sentence_words
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
Desafio 2: Recuperação Imprecisa
- Problema: Vector search retorna chunks irrelevantes.
- Solução: Usar busca híbrida (vetorial + BM25)
from rank_bm25 import BM25Okapi
class HybridRetriever:
def __init__(self, rag_system):
self.rag = rag_system
self.bm25 = None
self.documents = []
def index_for_bm25(self):
"""Prepara índice BM25"""
# Recuperar todos os documentos
results = self.rag.vector_db.scroll(
collection_name=self.rag.collection_name,
limit=10000
)
self.documents = [point.payload['text'] for point in results[0]]
tokenized = [doc.lower().split() for doc in self.documents]
self.bm25 = BM25Okapi(tokenized)
def hybrid_search(self, query, top_k=5, alpha=0.5):
"""
Busca híbrida: combina scores vetoriais e BM25
Args:
query: Pergunta
top_k: Número de resultados
alpha: Peso da busca vetorial (0=só BM25, 1=só vetorial)
"""
# Busca vetorial
vector_results = self.rag.retrieve(query, top_k=top_k*2)
# Busca BM25
tokenized_query = query.lower().split()
bm25_scores = self.bm25.get_scores(tokenized_query)
# Combinar scores (normalizar ambos para 0-1)
combined = {}
# Scores vetoriais
for result in vector_results:
text = result['text']
combined[text] = alpha * result['score']
# Scores BM25
max_bm25 = max(bm25_scores) if max(bm25_scores) > 0 else 1
for text, score in zip(self.documents, bm25_scores):
normalized_bm25 = score / max_bm25
if text in combined:
combined[text] += (1 - alpha) * normalized_bm25
else:
combined[text] = (1 - alpha) * normalized_bm25
# Ordenar por score combinado
sorted_results = sorted(
combined.items(),
key=lambda x: x[1],
reverse=True
)[:top_k]
return [{'text': text, 'score': score} for text, score in sorted_results]
Desafio 3: Contexto Insuficiente
- Problema: Top-3 chunks não têm informação completa.
- Solução: Parent Chunk Retrieval
def retrieve_with_parents(self, query, top_k=3, expand_chunks=1):
"""
Recupera chunks e seus vizinhos para mais contexto
Args:
query: Pergunta
top_k: Chunks principais
expand_chunks: Quantos chunks adjacentes incluir
"""
# Busca inicial
results = self.retrieve(query, top_k=top_k)
expanded_contexts = []
for result in results:
source = result['source']
chunk_id = result['chunk_id']
# Buscar chunks adjacentes
for offset in range(-expand_chunks, expand_chunks + 1):
target_id = chunk_id + offset
# Buscar chunk específico
adjacent = self.vector_db.scroll(
collection_name=self.collection_name,
scroll_filter={
"must": [
{"key": "source", "match": {"value": source}},
{"key": "chunk_id", "match": {"value": target_id}}
]
},
limit=1
)
if adjacent[0]:
expanded_contexts.append(adjacent[0][0].payload['text'])
return expanded_contexts
Desafio 4: Latência Alta
- Problema: Busca + geração demora muito.
- Soluções: Cache de embeddings e Streaming da resposta.
Cache de embeddings de queries comuns:
import hashlib
import pickle
class CachedRAG(RAGSystemOpenSource):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.embedding_cache = {}
self.response_cache = {}
def embed_text(self, text):
# Hash do texto
text_hash = hashlib.md5(text.encode()).hexdigest()
if text_hash not in self.embedding_cache:
self.embedding_cache[text_hash] = super().embed_text(text)
return self.embedding_cache[text_hash]
def generate_answer(self, query, use_cache=True, **kwargs):
query_hash = hashlib.md5(query.encode()).hexdigest()
if use_cache and query_hash in self.response_cache:
print("✅ Resposta recuperada do cache!")
return self.response_cache[query_hash]
response = super().generate_answer(query, **kwargs)
self.response_cache[query_hash] = response
return response
Streaming da resposta:
def generate_answer_streaming(self, query, top_k=3):
"""Gera resposta com streaming para melhor UX"""
contexts = self.retrieve(query, top_k=top_k)
context_text = "\n\n---\n\n".join([ctx['text'] for ctx in contexts])
prompt = f"""[mesmo prompt anterior]"""
print("\n🤖 Resposta: ", end='', flush=True)
# Stream da resposta
for chunk in ollama.generate(
model=self.llm_model,
prompt=prompt,
stream=True
):
print(chunk['response'], end='', flush=True)
print() # Nova linha no final
🎯Avaliação de Sistemas RAG
Como saber se seu RAG está performando bem? Use estas métricas:
Métricas de Avaliação — Visão Geral
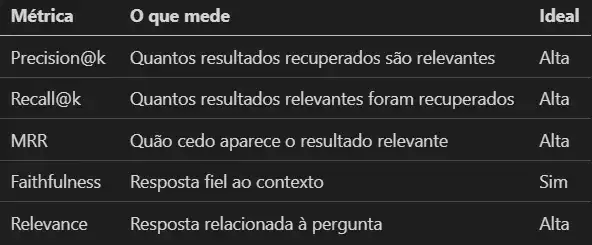
Métricas de Retrieval
Precision@k: Dos k chunks recuperados, quantos são realmente relevantes?
def precision_at_k(retrieved_chunks, relevant_chunks):
relevant_retrieved = set(retrieved_chunks) & set(relevant_chunks)
return len(relevant_retrieved) / len(retrieved_chunks)
Recall@k: Dos chunks relevantes que existem, quantos foram recuperados?
def recall_at_k(retrieved_chunks, relevant_chunks):
relevant_retrieved = set(retrieved_chunks) & set(relevant_chunks)
return len(relevant_retrieved) / len(relevant_chunks)
MRR (Mean Reciprocal Rank): Em qual posição aparece o primeiro resultado relevante?
def mean_reciprocal_rank(retrieved_lists, relevant_lists):
reciprocal_ranks = []
for retrieved, relevant in zip(retrieved_lists, relevant_lists):
for i, doc in enumerate(retrieved, 1):
if doc in relevant:
reciprocal_ranks.append(1 / i)
break
else:
reciprocal_ranks.append(0)
return sum(reciprocal_ranks) / len(reciprocal_ranks)
Métricas de Geração
Faithfulness: Resposta é fiel ao contexto? Use outro LLM para verificar:
def check_faithfulness(response, context):
prompt = f"""Avalie se a RESPOSTA é fiel ao CONTEXTO fornecido.
CONTEXTO:
{context}
RESPOSTA:
{response}
A resposta contém apenas informações do contexto? Responda apenas SIM ou NÃO."""
result = ollama.generate(model='llama3.2', prompt=prompt)
return "SIM" in result['response'].upper()
Answer Relevance: A resposta está relacionada à pergunta?
def check_relevance(query, response):
prompt = f"""A RESPOSTA abaixo responde adequadamente à PERGUNTA?
PERGUNTA:
{query}
RESPOSTA:
{response}
Avalie de 0 a 10 quão relevante é a resposta. Responda apenas com um número."""
result = ollama.generate(model='llama3.2', prompt=prompt)
try:
score = int(''.join(filter(str.isdigit, result['response'])))
return min(score, 10) / 10
except:
return 0.5
Framework de Avaliação Completo
# Salve com o nome ragscore.py ou outro que desejar
import ollama
def check_faithfulness(response, context):
prompt = f"""Avalie se a RESPOSTA é fiel ao CONTEXTO fornecido.
CONTEXTO:
{context}
RESPOSTA:
{response}
A resposta esta dentro das informações do contexto?
Responda apenas SIM ou NÃO."""
result = ollama.generate(model='llama3.2', prompt=prompt)
return "SIM" in result['response'].upper()
def check_relevance(query, response):
prompt = f"""A RESPOSTA abaixo responde adequadamente à PERGUNTA?
PERGUNTA:
{query}
RESPOSTA:
{response}
Avalie de 0 a 10 quão relevante é a resposta. Responda apenas com um número."""
result = ollama.generate(model='llama3.2', prompt=prompt)
try:
score = int(''.join(filter(str.isdigit, result['response'])))
return min(score, 10) / 10
except:
return 0.5
# Classe avaliadora
class RAGEvaluator:
def __init__(self, rag_system):
self.rag = rag_system
self.test_cases = []
def add_test_case(self, query, expected_answer, relevant_sources):
"""
Adiciona caso de teste
Args:
query: Pergunta
expected_answer: Resposta esperada (opcional)
relevant_sources: Lista de fontes que deveriam ser recuperadas
"""
self.test_cases.append({
'query': query,
'expected': expected_answer,
'relevant_sources': relevant_sources
})
def evaluate(self):
"""Executa avaliação completa"""
results = {
'retrieval': {'precision': [], 'recall': []},
'generation': {'faithfulness': [], 'relevance': []}
}
for case in self.test_cases:
print(f"\n🧪 Testando: {case['query'][:50]}...")
# Recuperar contextos
contexts = self.rag.retrieve(case['query'], top_k=5)
retrieved_sources = [ctx['source'] for ctx in contexts]
# Métricas de retrieval
relevant = set(case['relevant_sources'])
retrieved = set(retrieved_sources)
if relevant:
precision = len(relevant & retrieved) / len(retrieved) if retrieved else 0
recall = len(relevant & retrieved) / len(relevant)
results['retrieval']['precision'].append(precision)
results['retrieval']['recall'].append(recall)
print(f" 📊 Precision: {precision:.2f} | Recall: {recall:.2f}")
# Gerar resposta
response = self.rag.generate_answer(case['query'], verbose=False)
# Métricas de geração
context_text = "\n".join([ctx['text'] for ctx in contexts])
faithfulness = check_faithfulness(response, context_text)
relevance = check_relevance(case['query'], response)
results['generation']['faithfulness'].append(1 if faithfulness else 0)
results['generation']['relevance'].append(relevance)
print(f" 🎯 Faithfulness: {faithfulness} | Relevance: {relevance:.2f}")
# Resumo
print("\n" + "="*80)
print("📈 RESULTADOS FINAIS")
print("="*80)
if results['retrieval']['precision']:
avg_precision = sum(results['retrieval']['precision']) / len(results['retrieval']['precision'])
avg_recall = sum(results['retrieval']['recall']) / len(results['retrieval']['recall'])
print(f"Retrieval - Precision: {avg_precision:.2%} | Recall: {avg_recall:.2%}")
if results['generation']['faithfulness']:
avg_faithfulness = sum(results['generation']['faithfulness']) / len(results['generation']['faithfulness'])
avg_relevance = sum(results['generation']['relevance']) / len(results['generation']['relevance'])
print(f"Generation - Faithfulness: {avg_faithfulness:.2%} | Relevance: {avg_relevance:.2%}")
return results
Exemplo de uso:
from ragsupport import RAGSystemOpenSource
from ragscore import RAGEvaluator
# Exemplo de uso
rag = RAGSystemOpenSource()
evaluator = RAGEvaluator(rag)
# Adicionar casos de teste
evaluator.add_test_case(
query="Como funciona OAuth2?",
expected_answer=None,
relevant_sources=["manual_api.pdf"]
)
evaluator.add_test_case(
query="Quais são os requisitos de sistema?",
expected_answer=None,
relevant_sources=["documentacao_tecnica.pdf"]
)
# Executar avaliação
results = evaluator.evaluate()
RAG Avançado: Técnicas de Ponta
1. Multi-Query Retrieval
Gere múltiplas versões da query para capturar diferentes aspectos e aumentar recall:
def multi_query_retrieval(self, query, num_variations=3):
"""Gera variações da query para busca mais abrangente"""
# Prompt para gerar variações
variation_prompt = f"""Dada a pergunta abaixo, gere {num_variations} variações diferentes da mesma pergunta que capturem aspectos ligeiramente diferentes.
PERGUNTA ORIGINAL:
{query}
Retorne apenas as {num_variations} variações, uma por linha, sem numeração ou explicações."""
result = ollama.generate(model=self.llm_model, prompt=variation_prompt)
variations = [line.strip() for line in result['response'].split('\n') if line.strip()]
# Adicionar query original
all_queries = [query] + variations[:num_variations]
# Buscar com cada variação
all_contexts = []
seen_texts = set()
for q in all_queries:
contexts = self.retrieve(q, top_k=2)
for ctx in contexts:
if ctx['text'] not in seen_texts:
all_contexts.append(ctx)
seen_texts.add(ctx['text'])
# Retornar top-k únicos
return sorted(all_contexts, key=lambda x: x['score'], reverse=True)[:5]
2. Hypothetical Document Embeddings (HyDE)
Gere uma resposta hipotética e busque documentos similares a ela:
def hyde_retrieval(self, query, top_k=3):
"""
HyDE: Gera resposta hipotética e busca docs similares
Útil quando a query é muito diferente do estilo dos documentos
"""
# Gerar resposta hipotética
hyde_prompt = f"""Dada a pergunta abaixo, escreva uma resposta hipotética detalhada e técnica (mesmo que você não tenha certeza).
PERGUNTA:
{query}
RESPOSTA HIPOTÉTICA (seja específico e técnico):"""
result = ollama.generate(
model=self.llm_model,
prompt=hyde_prompt,
options={'temperature': 0.7}
)
hypothetical_doc = result['response']
print(f"💭 Documento hipotético gerado ({len(hypothetical_doc)} chars)")
# Buscar usando embedding do doc hipotético
hypo_vector = self.embed_text(hypothetical_doc)
results = self.vector_db.search(
collection_name=self.collection_name,
query_vector=hypo_vector,
limit=top_k
)
return [{'text': hit.payload['text'], 'source': hit.payload['source'], 'score': hit.score} for hit in results]
3. Self-Query Retrieval com Filtros Estruturados
Extraia filtros de metadados da query em linguagem natural:
def self_query_retrieval(self, query, top_k=3):
"""
Extrai filtros estruturados da query natural
Exemplo: "Documentos sobre API de 2024" → {topic: "API", year: 2024}
"""
# Prompt para extrair filtros
filter_prompt = f"""Analise a pergunta e extraia filtros estruturados relevantes.
PERGUNTA:
{query}
Extraia os seguintes filtros se mencionados:
- source (nome do documento)
- data (ano ou data específica)
- categoria (tipo de informação)
Responda APENAS em formato JSON. Se não houver filtros, retorne {{}}.
JSON:"""
result = ollama.generate(model=self.llm_model, prompt=filter_prompt)
try:
# Extrair JSON da resposta
json_str = result['response']
json_str = json_str[json_str.find('{'):json_str.rfind('}')+1]
filters = json.loads(json_str) # Use json.loads() em produção
except:
filters = {}
print(f"🔍 Filtros extraídos: {filters}")
# Construir filtro Qdrant
query_filter = None
if filters:
must_conditions = []
for key, value in filters.items():
must_conditions.append({
"key": key,
"match": {"value": value}
})
if must_conditions:
query_filter = {"must": must_conditions}
# Buscar com filtros
query_vector = self.embed_text(query)
results = self.vector_db.search(
collection_name=self.collection_name,
query_vector=query_vector,
query_filter=query_filter,
limit=top_k
)
return [{'text': hit.payload['text'], 'source': hit.payload['source'], 'score': hit.score} for hit in results]
4. Reranking para Melhor Precisão
Use um modelo de reranking para reordenar resultados:
def rerank_results(self, query, contexts, top_k=3):
"""
Reordena resultados usando análise mais profunda
Simulação de reranking (em produção use modelos específicos)
"""
reranked = []
for ctx in contexts:
# Prompt para avaliar relevância
relevance_prompt = f"""Avalie a relevância do CONTEXTO para responder a PERGUNTA.
PERGUNTA:
{query}
CONTEXTO:
{ctx['text'][:500]}...
Dê uma nota de 0 a 10 para a relevância. Responda APENAS com o número."""
result = ollama.generate(
model=self.llm_model,
prompt=relevance_prompt,
options={'temperature': 0.1}
)
try:
score = int(''.join(filter(str.isdigit, result['response'])))
score = min(score, 10) / 10
except:
score = ctx['score'] # Fallback para score original
reranked.append({**ctx, 'rerank_score': score})
# Ordenar por novo score
reranked.sort(key=lambda x: x['rerank_score'], reverse=True)
return reranked[:top_k]
Casos de Uso Práticos do RAG
1. Assistente de Documentação Técnica
# Sistema para responder perguntas sobre docs de software
doc_rag = RAGSystemOpenSource(model_name='all-MiniLM-L6-v2')
# Indexar documentação
doc_rag.index_document("python_docs.pdf")
doc_rag.index_document("django_guide.pdf")
doc_rag.index_document("api_reference.pdf")
# Usar
response = doc_rag.generate_answer("Como criar um middleware no Django?")
2. Análise de Contratos e Documentos Legais
# Sistema para análise jurídica
legal_rag = RAGSystemOpenSource(
model_name='intfloat/e5-large-v2', # Melhor para textos longos
llm_model='mistral' # Mais capaz para análise complexa
)
# Indexar contratos
legal_rag.index_document("contrato_trabalho.pdf")
legal_rag.index_document("clausulas_padrao.pdf")
# Consultar
response = legal_rag.generate_answer(
"Quais são as condições de rescisão contratual?"
)
3. Base de Conhecimento Corporativa
# Sistema para empresa com múltiplas fontes
kb_rag = RAGSystemOpenSource()
# Indexar diversos documentos
documentos = [
"politicas_rh.pdf",
"manual_vendas.pdf",
"guia_produtos.pdf",
"procedimentos_ti.pdf"
]
for doc in documentos:
kb_rag.index_document(doc)
# Interface interativa
def chat_interface():
print("💬 Assistente de Base de Conhecimento")
print("Digite 'sair' para encerrar\n")
while True:
query = input("Você: ")
if query.lower() == 'sair':
break
response = kb_rag.generate_answer(query)
print(f"\n🤖 Assistente: {response}\n")
chat_interface()
4. Análise de Pesquisas Científicas
# Sistema para pesquisadores
research_rag = RAGSystemOpenSource(
model_name='all-mpnet-base-v2', # Melhor para textos científicos
llm_model='llama3.1:8b' # Modelo maior para análise profunda
)
# Indexar papers
papers = [
"paper_deep_learning_2023.pdf",
"research_nlp_transformers.pdf",
"study_rag_systems.pdf"
]
for paper in papers:
research_rag.index_document(paper)
# Fazer revisão de literatura
response = research_rag.generate_answer(
"Quais são as principais limitações dos sistemas RAG segundo a literatura recente?"
)
Otimização de Performance
1. Redução de Dimensionalidade para Velocidade
from sklearn.decomposition import PCA
import numpy as np
class FastRAG(RAGSystemOpenSource):
def __init__(self, *args, reduced_dims=128, **kwargs):
super().__init__(*args, **kwargs)
self.reduced_dims = reduced_dims
self.pca = None
def train_pca(self, sample_texts):
"""Treina PCA com amostra de textos"""
embeddings = [self.embedding_model.encode(text) for text in sample_texts]
embeddings_array = np.array(embeddings)
self.pca = PCA(n_components=self.reduced_dims)
self.pca.fit(embeddings_array)
print(f"✅ PCA treinado: {self.embedding_dim} → {self.reduced_dims} dims")
print(f" Variância preservada: {sum(self.pca.explained_variance_ratio_):.2%}")
def embed_text(self, text):
"""Embedding com redução de dimensionalidade"""
full_embedding = self.embedding_model.encode(text)
if self.pca:
reduced = self.pca.transform([full_embedding])[0]
return reduced.tolist()
return full_embedding.tolist()
2. Quantização para Menor Uso de Memória
def quantize_embeddings(embeddings, bits=8):
"""
Quantiza embeddings para int8 (reduz 4x o tamanho)
Trade-off: leve perda de precisão por muito menos memória
"""
embeddings_array = np.array(embeddings)
# Normalizar para range [0, 2^bits - 1]
min_val = embeddings_array.min()
max_val = embeddings_array.max()
scale = (2**bits - 1) / (max_val - min_val)
quantized = ((embeddings_array - min_val) * scale).astype(np.uint8)
# Retornar quantizado + metadados para dequantização
return {
'quantized': quantized.tolist(),
'min': float(min_val),
'max': float(max_val),
'scale': float(scale)
}
def dequantize_embeddings(quantized_data):
"""Recupera embeddings aproximados"""
quantized = np.array(quantized_data['quantized'], dtype=np.uint8)
min_val = quantized_data['min']
scale = quantized_data['scale']
return (quantized / scale) + min_val
3. Batch Processing para Indexação Rápida
def batch_index_documents(self, file_paths, batch_size=50):
"""
Indexa múltiplos documentos em lotes para eficiência
Args:
file_paths: Lista de caminhos de arquivos
batch_size: Tamanho do lote para embeddings
"""
all_chunks = []
# Extrair e chunkar todos os documentos
for file_path in file_paths:
source_name = os.path.basename(file_path)
print(f"📄 Processando: {source_name}")
# Ler e chunkar
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
text += page.extract_text()
chunks = self.chunk_text(text)
for idx, chunk in enumerate(chunks):
all_chunks.append({
'text': chunk,
'source': source_name,
'chunk_id': idx
})
print(f"\n🧮 Gerando embeddings para {len(all_chunks)} chunks...")
# Gerar embeddings em lotes (muito mais rápido)
points = []
for i in range(0, len(all_chunks), batch_size):
batch = all_chunks[i:i+batch_size]
texts = [chunk['text'] for chunk in batch]
# Batch encoding (10-50x mais rápido que individual)
embeddings = self.embedding_model.encode(texts, show_progress_bar=False)
for j, (chunk, embedding) in enumerate(zip(batch, embeddings)):
points.append(
PointStruct(
id=i + j,
vector=embedding.tolist(),
payload=chunk
)
)
print(f" 💾 {min(i+batch_size, len(all_chunks))}/{len(all_chunks)} processados", end='\r')
# Inserir tudo de uma vez
print(f"\n💾 Inserindo {len(points)} pontos no banco...")
self.vector_db.upsert(
collection_name=self.collection_name,
points=points
)
print(f"✅ Indexação concluída!")
Melhores Práticas e Dicas de Produção
1. Monitoramento e Logging
import logging
from datetime import datetime
class ProductionRAG(RAGSystemOpenSource):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# Configurar logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('rag_system.log'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
# Métricas
self.metrics = {
'queries_total': 0,
'avg_retrieval_time': [],
'avg_generation_time': [],
'cache_hits': 0
}
def generate_answer(self, query, **kwargs):
"""Generate with logging and metrics"""
import time
self.metrics['queries_total'] += 1
self.logger.info(f"Query recebida: {query[:100]}")
# Timing de retrieval
start = time.time()
contexts = self.retrieve(query)
retrieval_time = time.time() - start
self.metrics['avg_retrieval_time'].append(retrieval_time)
self.logger.info(f"Retrieval: {retrieval_time:.3f}s - {len(contexts)} chunks")
# Timing de geração
start = time.time()
response = super().generate_answer(query, **kwargs)
gen_time = time.time() - start
self.metrics['avg_generation_time'].append(gen_time)
self.logger.info(f"Generation: {gen_time:.3f}s")
self.logger.info(f"Resposta: {response[:100]}...")
return response
def get_metrics(self):
"""Retorna métricas do sistema"""
return {
'total_queries': self.metrics['queries_total'],
'avg_retrieval_time': np.mean(self.metrics['avg_retrieval_time']),
'avg_generation_time': np.mean(self.metrics['avg_generation_time']),
'avg_total_time': np.mean(self.metrics['avg_retrieval_time']) +
np.mean(self.metrics['avg_generation_time'])
}
2. Tratamento de Erros Robusto
def safe_generate_answer(self, query, max_retries=3, **kwargs):
"""Geração com retry logic e fallbacks"""
for attempt in range(max_retries):
try:
return self.generate_answer(query, **kwargs)
except Exception as e:
self.logger.error(f"Tentativa {attempt + 1} falhou: {e}")
if attempt == max_retries - 1:
# Último attempt: retornar fallback
return self._fallback_response(query)
# Esperar antes de retentar
time.sleep(2 ** attempt)
def _fallback_response(self, query):
"""Resposta de fallback quando tudo falha"""
return f"""Desculpe, encontrei um problema técnico ao processar sua pergunta: "{query}".
Por favor, tente:
1. Reformular sua pergunta de forma mais específica
2. Dividir em perguntas menores
3. Verificar se os documentos relevantes foram indexados
Se o problema persistir, contate o suporte técnico."""
3. Versionamento de Índices
class VersionedRAG(RAGSystemOpenSource):
def __init__(self, version="v1", *args, **kwargs):
self.version = version
super().__init__(*args, **kwargs)
self.collection_name = f"knowledge_base_{version}"
def create_new_version(self, new_version):
"""Cria nova versão do índice"""
new_collection = f"knowledge_base_{new_version}"
# Criar nova coleção
self.vector_db.create_collection(
collection_name=new_collection,
vectors_config=VectorParams(
size=self.embedding_dim,
distance=Distance.COSINE
)
)
self.logger.info(f"Nova versão criada: {new_version}")
return VersionedRAG(version=new_version)
def rollback_version(self, old_version):
"""Volta para versão anterior"""
self.collection_name = f"knowledge_base_{old_version}"
self.version = old_version
self.logger.info(f"Rollback para versão: {old_version}")
Conclusão: O Futuro é Acessível
RAG democratiza o acesso a sistemas de IA avançados. Com ferramentas 100% open-source, qualquer desenvolvedor pode criar assistentes inteligentes, chatbots especializados e sistemas de busca semântica sem custos recorrentes de API.
Principais Aprendizados
- RAG resolve limitações críticas: Knowledge cutoff, alucinações e acesso a dados privados
- Componentes essenciais: Chunking inteligente, embeddings de qualidade, vector DB eficiente, LLM capaz
- Open-source é viável: Sentence Transformers + Qdrant + Ollama = Stack completo gratuito
- Otimização importa: Cache, batch processing e técnicas avançadas fazem diferença em produção
- Avaliação é essencial: Métricas objetivas guiam melhorias contínuas
Stack Recomendado (100% Gratuito)
- Embeddings: Sentence Transformers (all-MiniLM-L6-v2 ou all-mpnet-base-v2)
- Vector DB: Qdrant ou Chroma
- LLM: Llama 3.2 (3B) para velocidade, Llama 3.1 (8B) ou Mistral para qualidade
- Frameworks: LangChain ou LlamaIndex (opcional, para pipelines complexos)
Próximos Passos
- Implemente o básico: Use o código fornecido para criar seu primeiro RAG
- Teste com seus dados: Indexe documentos reais do seu domínio
- Meça performance: Use as métricas de avaliação para baseline
- Experimente técnicas avançadas: Multi-query, HyDE, reranking
- Otimize para produção: Adicione cache, logging, monitoring
- Itere baseado em feedback: Usuários reais são o melhor teste
Recursos Adicionais/Referências
- Documentação Sentence Transformers: https://www.sbert.net/
- Qdrant Documentation: https://qdrant.tech/documentation/
- Ollama Models: https://ollama.com/library
- Paper RAG Original (Meta AI): https://arxiv.org/abs/2005.11401
- REALM (Google Research, 2020): https://arxiv.org/abs/2002.08909
- ATLAS (Meta AI, 2022): https://arxiv.org/abs/2208.03299
- LangChain RAG Tutorial: https://python.langchain.com/docs/use_cases/question_answering/
- LlamaIndex RAG Guide: https://developers.llamaindex.ai/python/framework/understanding/rag/
- LangChain RAG Tutorial: https://python.langchain.com/docs/use_cases/question_answering/
- Chroma Getting Started: https://docs.trychroma.com/
- Hugging Face Model Hub: https://huggingface.co/models (milhares de modelos gratuitos)
Agora é sua vez! RAG não é mais uma tecnologia exclusiva de grandes empresas. Com as ferramentas e conhecimentos compartilhados aqui, você pode:
- ✅ Criar assistentes virtuais especializados no seu negócio
- ✅ Automatizar análise de documentos e contratos
- ✅ Construir bases de conhecimento inteligentes
- ✅ Desenvolver sistemas de busca semântica avançados
- ✅ Tudo isso sem gastar um centavo com APIs proprietárias
Comece hoje: Faça o download do código, indexe seus primeiros documentos, e veja a mágica acontecer. Compartilhe seus resultados, experimentos e aprendizados com a comunidade!
Dúvidas? Deixe nos comentários. Vamos construir o futuro da IA acessível juntos! 🚀
Gostou do artigo? Se este conteúdo foi útil:
⭐ Salve para referência futura
💬 Compartilhe suas experiências nos comentários
🔄 Repasse para outros desenvolvedores
🏗️ Construa algo incrível e mostre para a comunidade!






